目录
version 4:Advantage Actor-Critic
搜集资料的技巧:Exploration--增加Actor的随机性
RIG(Reinforcement Learning with Imagined Goals)
应用场景
- 当我们给机器一个输入的时候,我们不知道最佳的输出应该是什么;
- 收集有标注的资料很困难的时候
叫机器学习下围棋,最好的下一步可能人类根本就不知道。我们不知道正确答案是什么的情况下,往往就是 RL 可以派上用场的时候,

RL 在学习的时候,虽然不知道正确的答案是什么,但是机器会知道什么是好,什么是不好,机器会跟环境去做互动,得到Reward
强化学习的本质
强化学习的过程和机器学习是一样的,都是寻找函数。不过在强化学习中寻找的函数叫做actor,actor 跟Environment会进行互动,actor能够接受环境给予的observation(观察),做出action去影响 Environment,然后Environment会给这个 Actor 一些 reward(奖励),这个reward说明action是好是坏。我们的目的就是寻找一个用 Observation 当作Input,输出 Action,能将Reward总和最大化的actor。
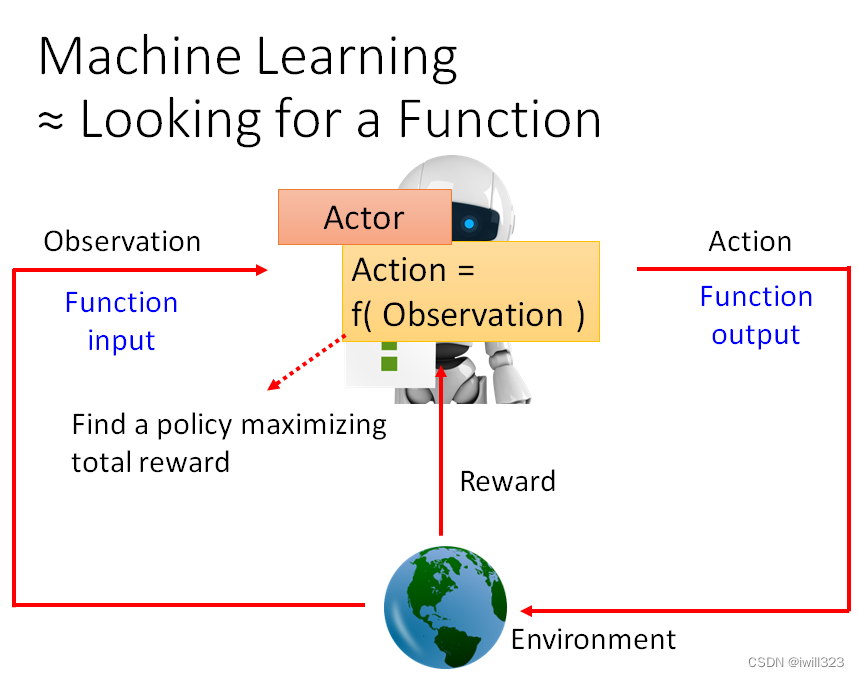
以电脑游戏为例
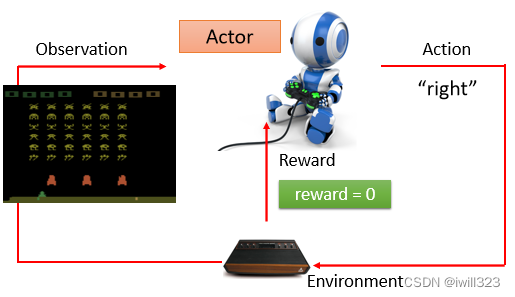
游戏界面就是observation,人即决策者就是actor,向左向右跟开火就是action,游戏机就是Environment,得到的游戏分数就是reward。游戏的画面变的时候就代表了有了新的 Observation 进来,有了新的 Observation 进来,你的 Actor 就会决定採取新的 Action。我们想要 Learn 出一个 Actor,使用它在这个游戏裡面的时候,可以让我们得到的 Reward 的总和会是最大的
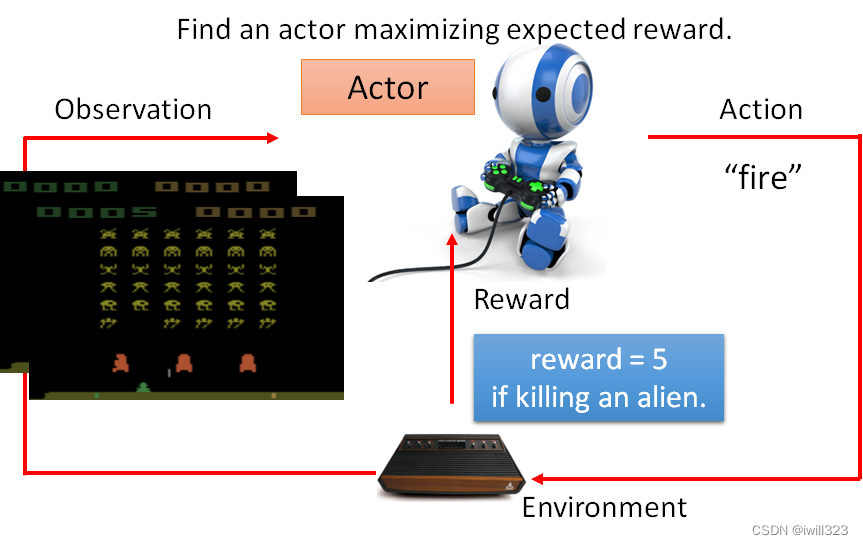
强化学习三个步骤
定义有未知参数的函数;根据训练资料定义loss;找出能够使loss最小化的函数(优化)
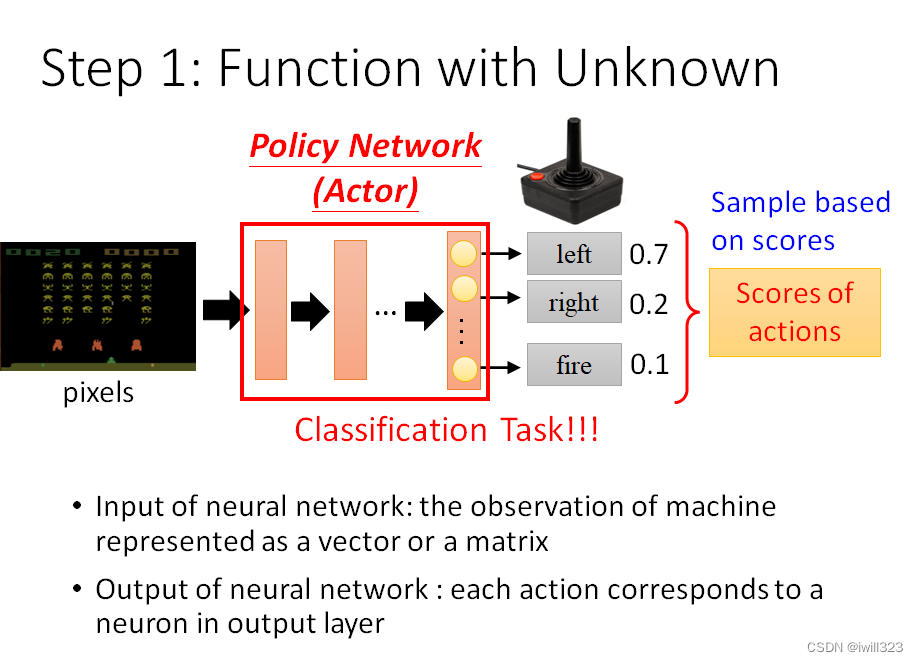
第一步:有未知参数的函数
将机器的观察用向量或矩阵来表示,作为actor的输入;actor输出的每个action对应输出层的每个神经元,每个action会有一个分数。这样看和分类任务是一个东西,不同的点是:强化学习将这些分数作为几率,按照这个几率随机产生输出,也就是sample(采样),而不是将分数最高的那个作为输出。
採取 Sample 有一个好处是说,就算是看到同样的游戏画面,机器每一次採取的行为也会略有不
同,在很多的游戏裡面这种随机性也许是重要的,比如说你在做剪刀石头布的时候如果总是会出石头,就很容易被打爆,如果有一些随机性就比较不容易被打爆。
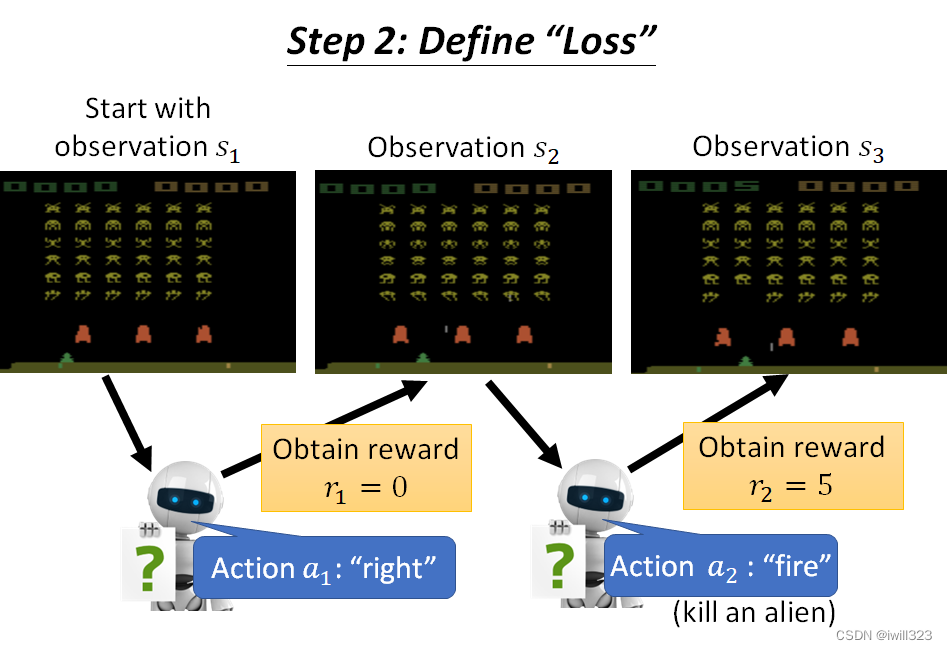
第二步:定义Loss
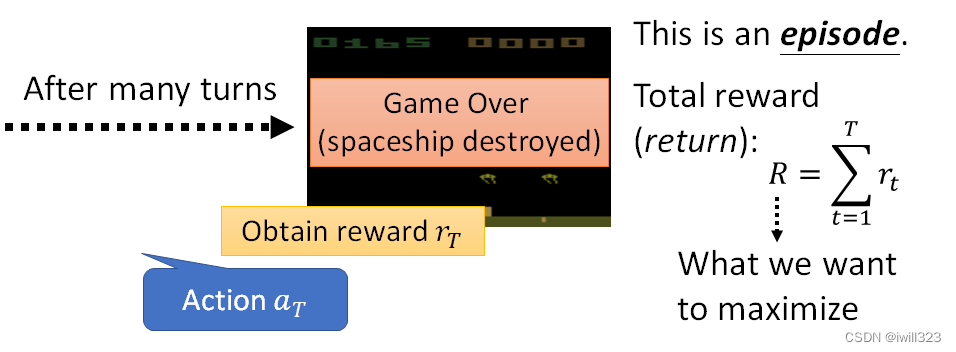
这里定义loss也就是定义分数的获得机制,但是我们最后想要最大化的是整局的全部分数之和,而不是局部某一次的分数。负的 Total Reward当做 Loss
补充:一局游戏就是一个episode;reward是某一个行为能立即得到的奖励,return是所有分数相加(total reward)。
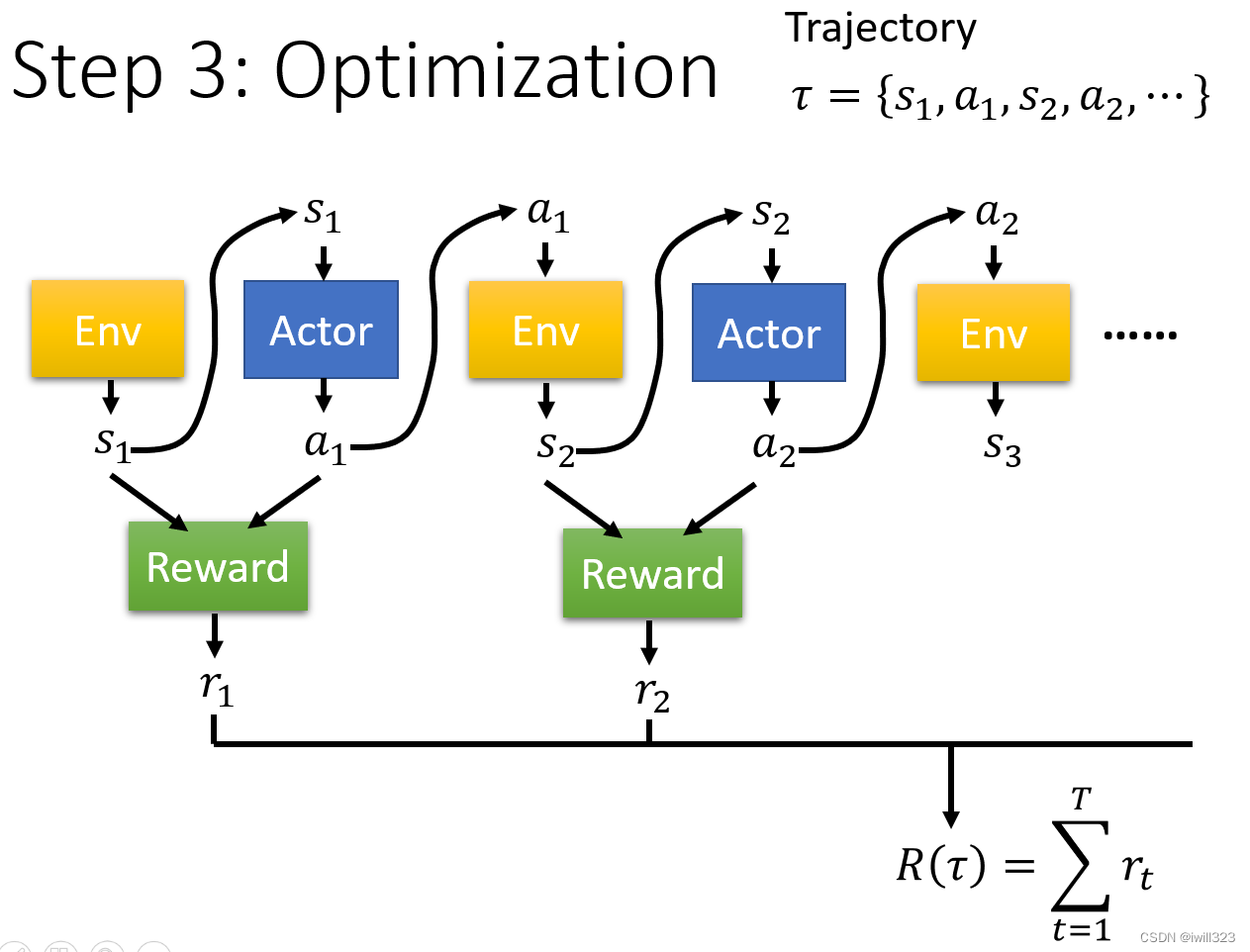
第三步:Optimization
环境产生的Observation s1 进入actor,actor通过采样输出一个a1,a1再进入环境产生s2,如此往复循环,直到满足游戏中止的条件。s 跟 a 所形成的这个 Sequence又叫做 Trajectory,用 𝜏 来表示。
需要注意的是reward不是只看action,还需要看 Observation,所以 Reward 是一个 Function。
优化目标:找到 Actor 的一组参数,让R(𝜏)的值越大越好。
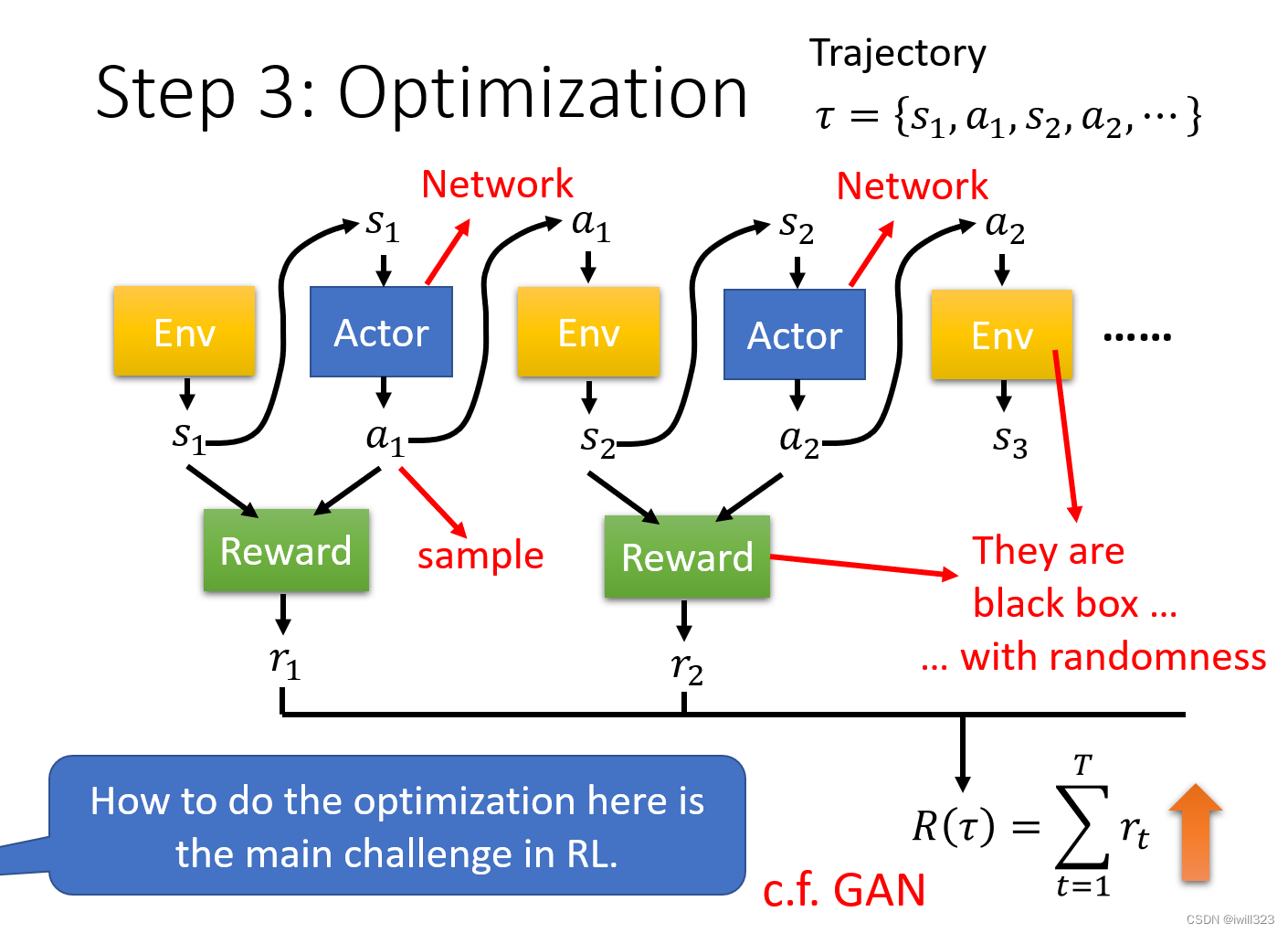
RL的难点
强化学习最主要的难点就是如何做optimizaton:
- action是通过采样产生的,具有很大的随机性,给相同的s,产生的a可能是不一样的。
- 一般的Network在不同的random seed设定下的随机性,是"Training"中的随机性,比如初始化参数随机;但是在Testing中,同样的输入会获得同样的输出。 RL的随机性是在测试时,固定模型参数,同样的输入observation,会有不同的输出action。
- 只有actor是网络,Environment 和 Reward,根本就不是 Network ,只是一个黑盒子而已;Environment与Reward都有随机性。
- 环境是黑箱,採取一个行为环境会有对应的回应,但是不知道到底是怎麽产生这个回应,给定同样的行为,它可能每次的回应也都是不一样,具有随机性。
- Reward就是一个奖励的规则,也不是 Network。
类比GAN
相同点:将actor看成是generator,将环境和reward看成是discriminator,训练出的generator能够使discriminator的corss entropy越大。
不同点:GAN的discriminator是network,而RL的discriminator不是network,无法用梯度下降等方法来调整参数来得到最好的结果。
Policy Gradient(策略梯度)
怎么学出actor中的参数
如果希望Actor在看到某个s时采取某一种行为,只需要把actor输出想成一个分类的问题,为每个Observation设定一个a ̂ (即Ground Truth或label)。针对某一个Observation,a ̂ 是向左移动,如果希望actor采取该行为,则计算Actor跟 Ground Truth 之间的 Cross-entropy,学习让Cross-entropy最小的 θ,就可以让这个 Actor的输出跟Ground Truth 越接近越好;如果不希望actor采取该行为,则L为-e,再学出能够使L最小的actor参数 。
看到这里我有一个疑问:Ground Truth是哪里来的?后文把e当做已知,没有解释Ground Truth来源
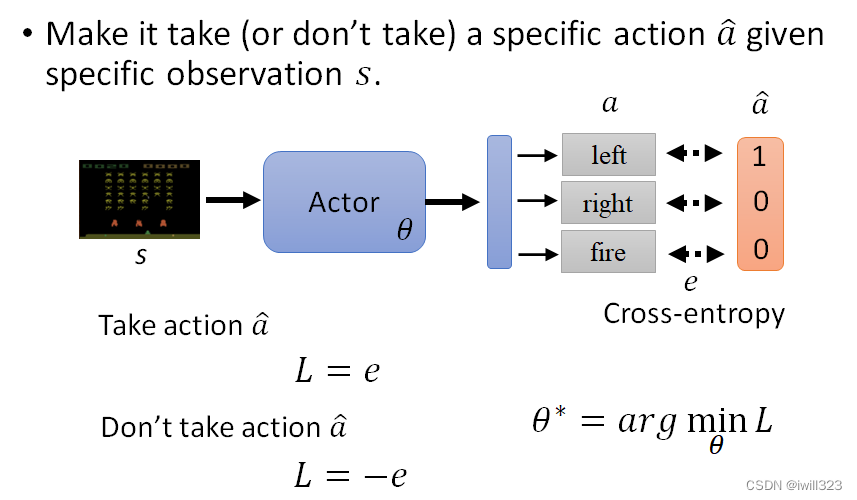
当有很多Observation时,每一个Observation对应一个a ̂,同时会有一个对应的e。假如我们希望在s时,actor做出a ̂的行为;而在s′时,不希望actor做出 a′ ̂ 的行为,那么此时的loss就变成了L=e1-e2,然后去找一个 θ 去 Minimize Loss,得到θ*
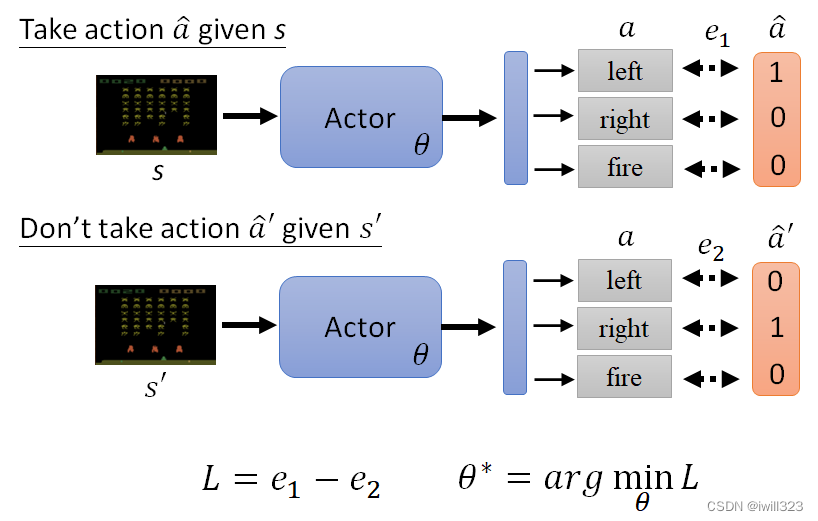
延伸到N个Observation。收集一堆这种资料,定义一个 Loss Function,训练 Actor,Minimize 这个 Loss Function,期待Actor执行我们的行为
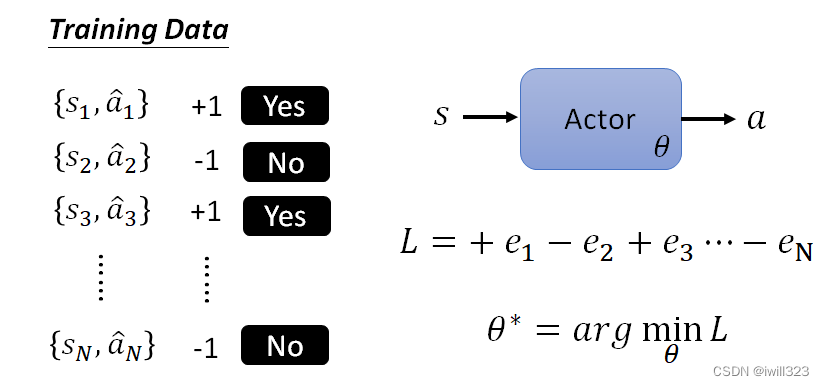
使用权重和影响系数,控制每个行为的重要性,有多希望 Actor 去执行。这样train出来的actor才会更加符合我们的期望。
那么难点有两个(也就是下图画问号的):1、如何产生成对的{s,a ̂ }。2、如何确定我们的A
1、通过随机的actor产生的结果{ }。2、A有很多种表示方法,下面将会介绍。
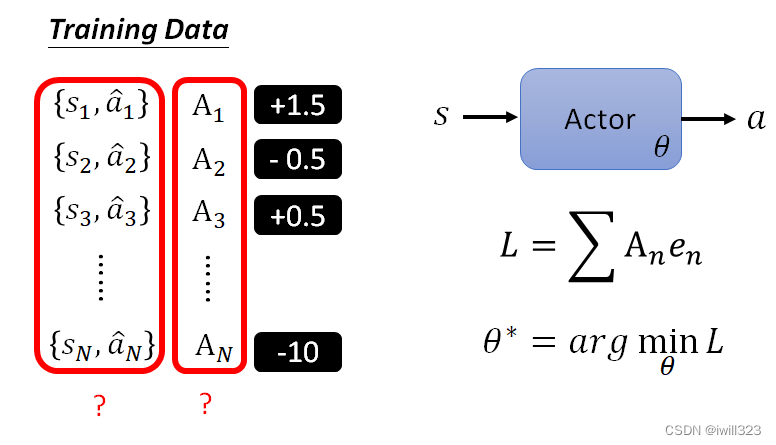
如何定义A
Version 0(最简单但不正确)
让一个(随机的)Actor 去跟环境做互动,把它在每一个Observation执行的行为action都记录下来,每一个行为对应一个奖励Reward,将这个即时的Reward作为每个pair的A值。通常收集资料不会只把 Actor 跟环境做一个 Episode,通常会做多个 Episode,然后期待可以收集到足够的资料
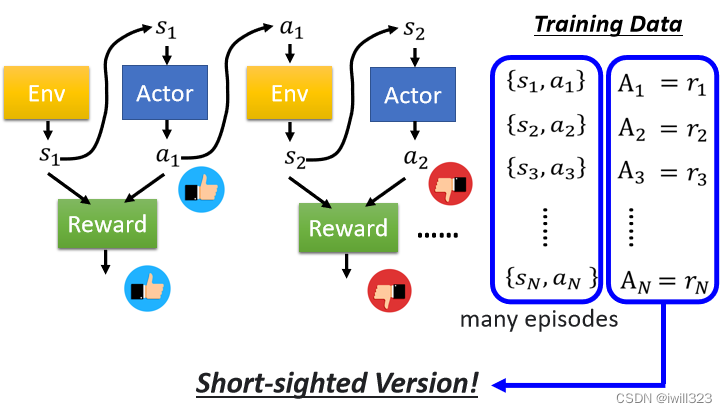
但是这是鼠目寸光的一个版本,没有长程规划的概念:
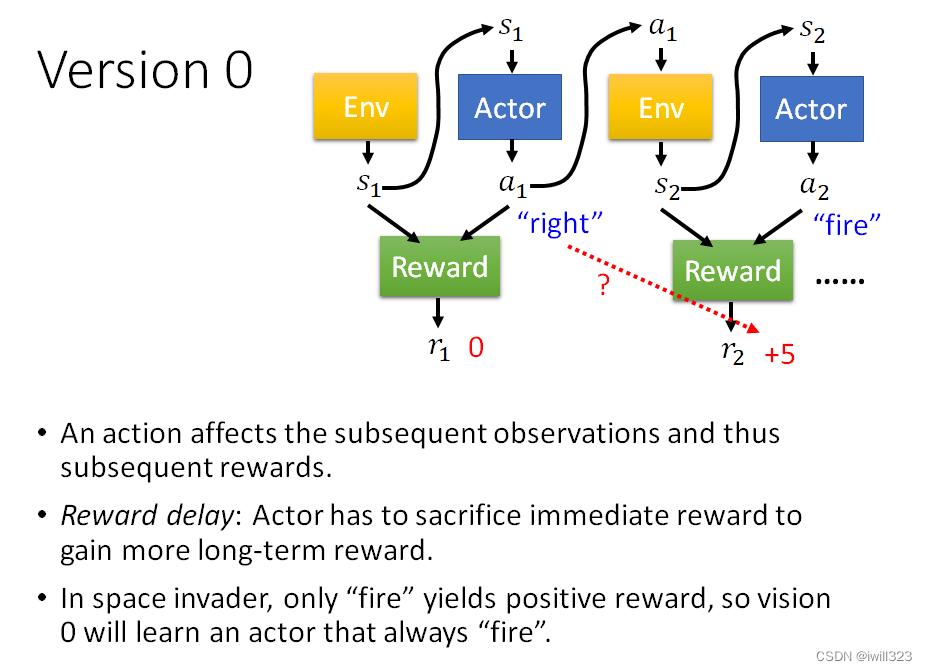
每个行为不是独立的,会影响互动接下来的发展。有些奖励是会有延迟的Reward Delay,需要牺牲短暂的奖励来获得长程的奖励。以太空游戏为例,左右移动是没有奖励的,只有开火会有奖励,采用版本0则会导致actor一直做开火动作,不会左右移动。
Version 1
at有多好,不仅取决于 rt,而是取决于 at 之后所有发生的事情。为了考虑到延迟奖励,将每个行为的后续所有行为的奖励Reward也加入到该批次来得到数值 Gt。这些G称为cumulated reward(累积奖励)。

存在一个问题,某个行为对后续行为产生奖励的影响都是一样的,假设这个过程非常地长的话,因为做a1导致可以得到rN的可能性应该很低。实际上某个行为对后续行为的影响并不是一样的,该行为对越靠近它的后续行为影响越大,越往后影响越小。也就是说越靠近它的后续行为产生的奖励,越能归功于该行为。
Version 2
升级版本1,加入discount factor(折扣系数),一般取0.9,0.99等等。这个折扣系数成幂次增长。这次计算出来的奖励称为discount cumulated reward(折扣累积奖励)。可以给离a1比较近的那些 Reward比较大的权重,比较远的那些 Reward比较小的权重

存在一定问题,就是没有考虑标准化,算出来的奖励是不具备参考性的,因为好的奖励分数和坏的奖励分数是相对的。同样是60分,全班很多人都考了90分,那60分就是差的,全班很多人都不及格,那60分就是好的。如果我们只是单纯的把 G 算出来,可能每一个行为都会给我们正的分数,只是有大有小的不同,有些行为其实是不好的,但是你仍然会鼓励Model去採取这些行为
Version 3
标准化奖励,把所有的 G' 都减掉一个 b(这个 b通常叫做 Baseline),A就有正有负了(采用减去b的方法), 这样就知道这个奖励在整体中到底是好是差,类似于算排名的感觉。

Actor-Critic(行动者-批评者)
Critic介绍
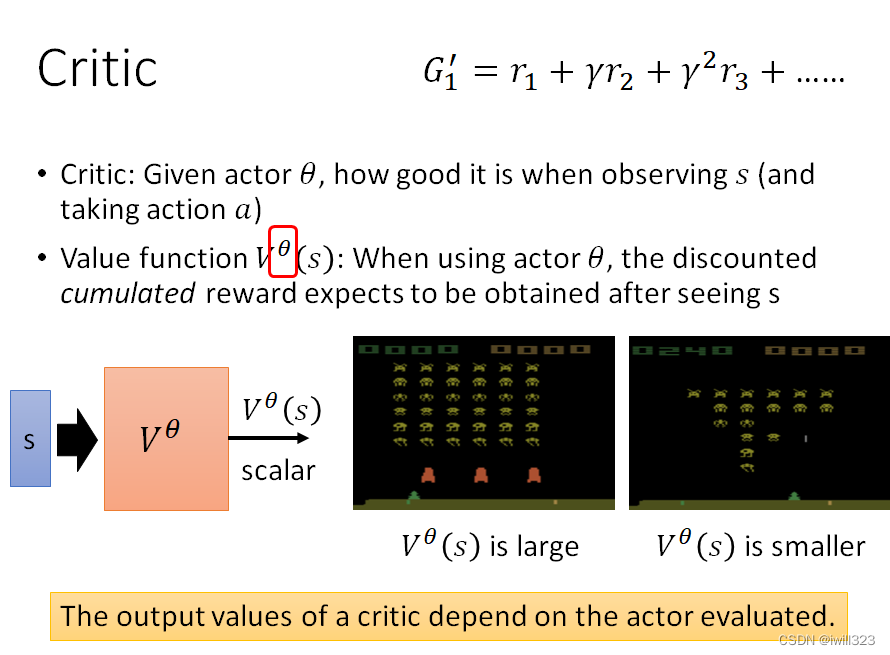
Critic是用来评价actor好坏的,可以用价值函数V^θ (s)来表示,当使用参数为θ的actor时,看到s后预估获得的折扣累积奖励。这个价值函数相当于未卜先知,看到s就知道actor会有什么样的表现。Critic考虑了参数θ下actor的所有可能的action,在面对某一s时,V^θ (s)是所有可能奖励discounted cumulated Reward的平均结果。所以价值函数是与评估的actor相关的,当有相同的observation时,不同的actor有不同的V^θ (s)。
Critic 怎么被训练出来的
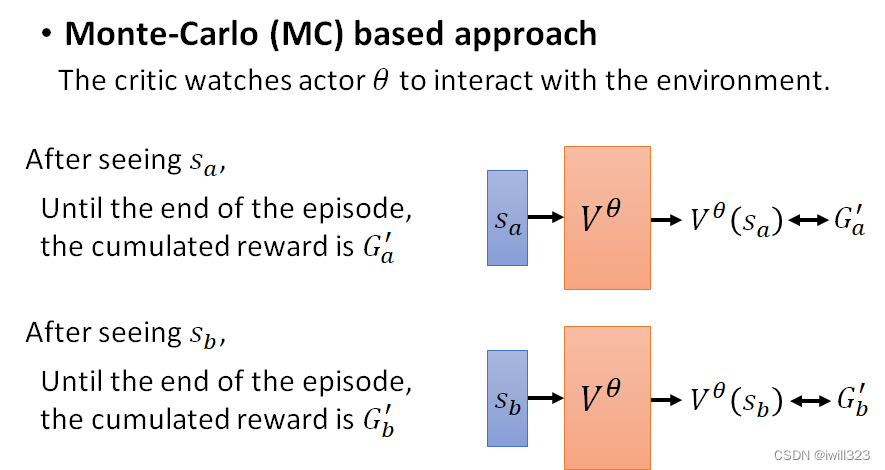
Monte-Carlo (MC)
让actor和环境互动,玩这个游戏以后得到一些记录,在输入sa后,游戏玩完之后就能得到discounted cumulated Reward的值为Ga′。利用这些训练资料,只需要让critic看到某个 s 后输出的值V^θ (s)与对应的G'越接近越好。
问题是,有的游戏其实很长,甚至有的游戏根本就没有不会结束,一直继续下去,那像这样子的游戏,MC 就非常地不适合
Temporal-difference (TD)
不需要玩完游戏就可以开始训练了,只要在看到Observation st, Actor 執行了 at获得rt,接下來再看到st+1 就能夠訓練V^θ (s)了。
V^θ (st)和 V^θ (st+1) 存在数学等式关系:前者减去γ倍后者就等于rt,所以只要训练这个差值接近rt就好。蒐集到 rt 这一笔资料,输入st和st+1,带入前述公式,差值要跟 rt 越接近越好
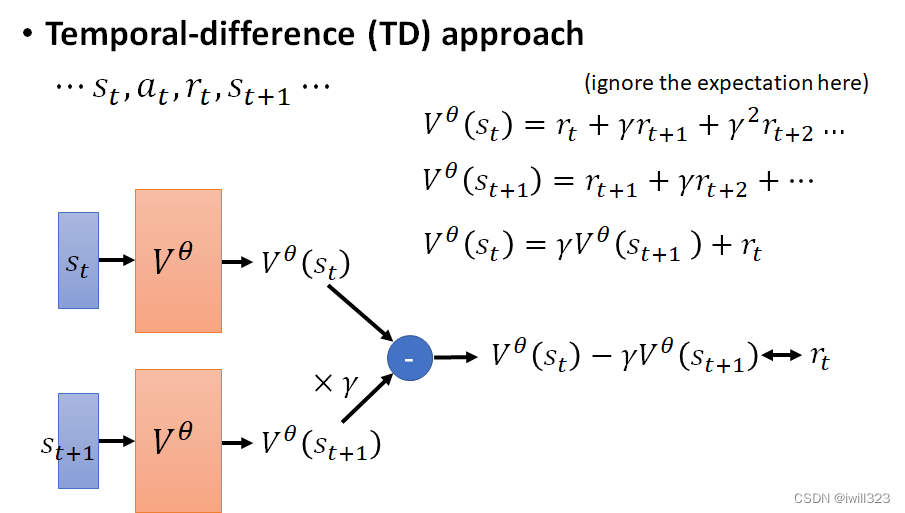
两种方法对比
同样的资料,同样的θ,用 MC 跟 TD 算出来的 Value Function很有可能会是不一样的。
下面代表玩了8次游戏,也就是8个episode。为了简化,无视actor和折扣。
- Actor 第一次玩游戏的时候,它先看到sa这个画面,得到 Reware 0,接下来看到sb这个画面,得到 Reware 0 游戏结束
- 接下来有连续六场游戏,都是看到sb这个画面,得到 Reward 1 就结束了
- 最后一场游戏看到sb这个画面,得到 Reward 0 就结束了
8次游戏中看到8次sb,其中6次是的1分,2次是0分,所以sb的价值函数是3/4。
- MC:sa和sb是有关联的,看到了sa就会让sb的reward=0。只看到一次sa,discounted cumulated Reward值为0。故V^θ (sa)=0
- TD:前后两个state是没有关系的,sa之后看到sb,但sb的reward不会受sa的影响,而sb期望的Reward=3/4,所以计算得到V^θ (sa)=3/4

version 3.5
将价值函数用于训练actor。在version 3中就有提到标准化,是通过减去b来实现的,在这个版本中这个b用V^θ (s)来表示。
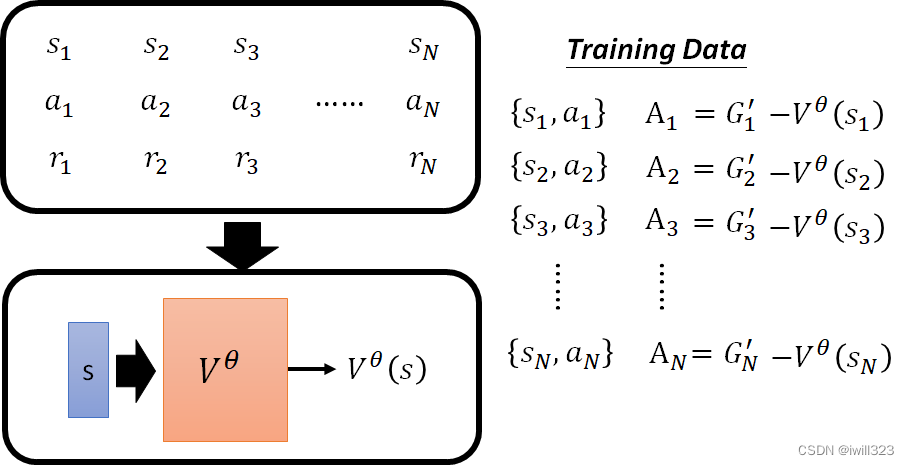
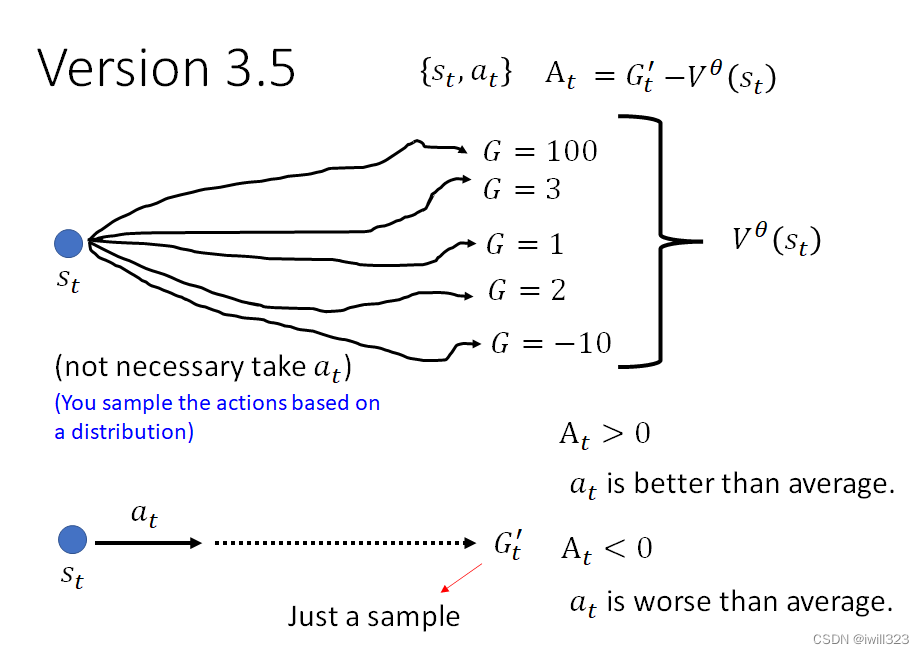
玩完一局游戏产生的资料是{st,at},但我们是基于一个分布来采样行为,即看到st后actor能够做许多种行为,将所有这些可能行为的 Gt' 都算出来并做平均,就得到了V^θ (s),所以V^θ (s)代表平均实力。Gt' 含义是在 st 这个画面下,执行 at 以后,再一路玩下去,会得到的实际 Cumulative Reward。At = Gt′ - V^θ (s)就是把个人分数减去班级平均成绩,这样就能看出个人分数是否过了平均线,也就判断了这个行为是好是坏。假如算出的At大于0,则证明at行为比随便执行的actor要好,其分数是在平均线以上,是个好的行为。
但是这个版本中仍存在问题,就是at之后的所有行为都是采样出来的,我们考察的是at是不是个好行为,不能让后面的特殊情况影响到了对at的判断。Gt′是一次采样,可能存在特殊性。例如at是个差的行为,但是后面sample出来的行为碰巧大部分都有很高的奖励分数,这样就使得判断有失偏颇。
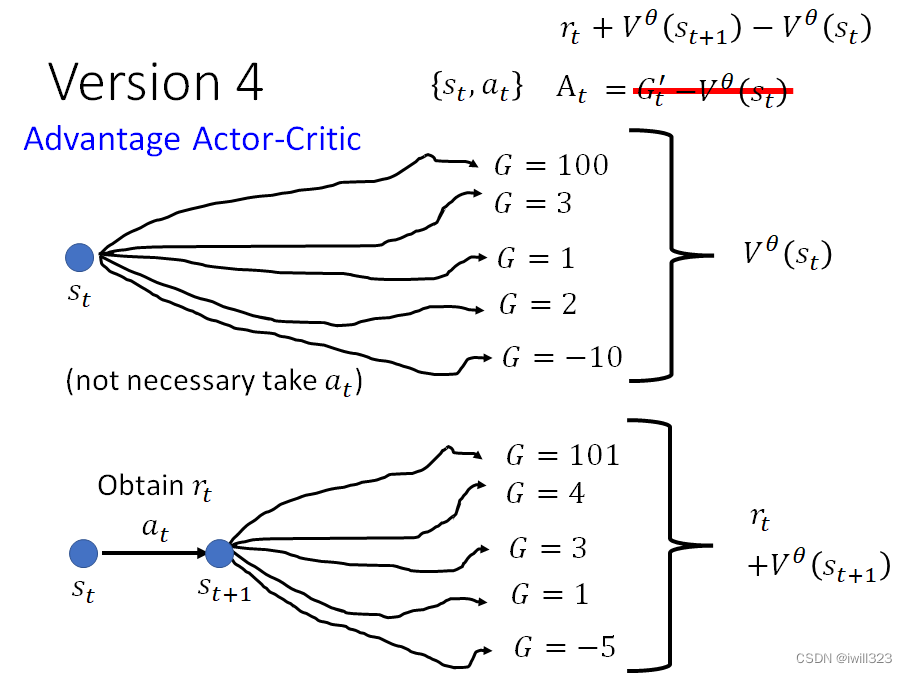
version 4:Advantage Actor-Critic
对于采取at行为后的期望奖励,上个版本是直接用当前采样出的路径,而这个版本是用at产生的即时奖励rt,加上从st+1开始玩所有可能Gt+1′的均值(即V^θ (st+1)),这样才能真正代表at产生的效益有多大。
训练Actor-Critic的小技巧
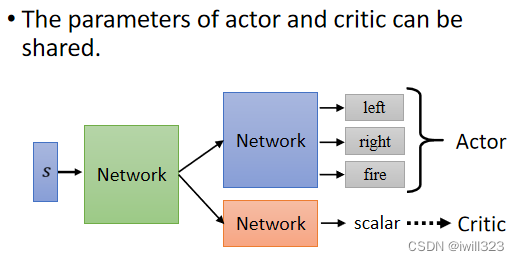
actor和critic的参数是可以共享的。actor是接受s,输出不同的行为并给出分数作为sample的几率;critic是接受s,输出一个数值,这个数字代表接下来的累积奖励。两者都要接受s,对s的处理肯定有相同的做法,所以两者可以共用前几层的layer网络,后面几层网络根据特性分别设计。
Deep Q Network (DQN)
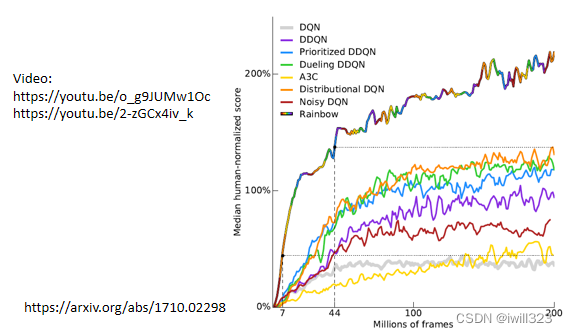
上面讲了actor-critic方法,还有另一个方法叫做DQN,直接用critic就知道用什么actor比较好,DQN也有很多分支方法,详细内容在以往课程中有介绍,参考下面youtube链接。
Policy Gradient
策略梯度的流程
1、随机初始化actor的参数 ;
2、迭代地训练更新Actor:
- actor与环境互动之后获得一堆的{s,a}
- 根据上述{s,a}来计算奖励A
- 计算Loss
- 更新迭代actor的参数(Gradient Descent)
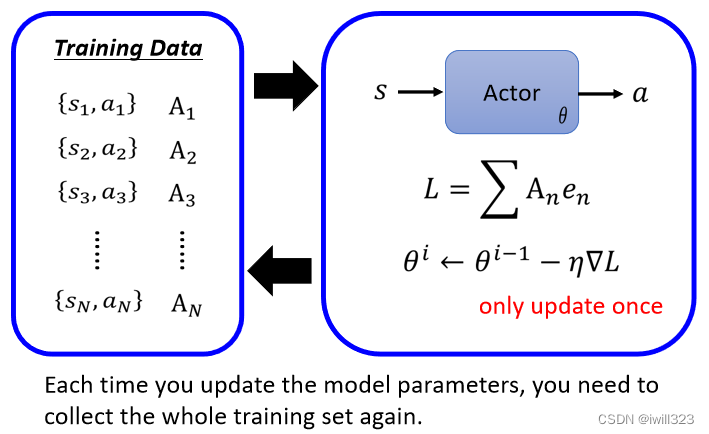
值得注意的是:一般train的数据搜集是在循环圈之外的,而RL的train的数据搜集是在循环圈之内的,actor的参数每更新一次,都需要重新搜集资料,然后再来更新。收集资料的那个 Actor和被训练的那个 Actor要求是同一个
原因是同一个 Action 对于不同的 Actor 而言,它的好是不一样的。θi-1收集到的资料只能用于更新自己的参数,不一定适合更新 θi 的参数,因为参数更新后,actor会采取不一样的行为。可以想象成每更新一次actor就进化一次,拥有更强的能力。这就是为什么 RL往往训练过程非常花时间
没看明白:计算loss的时候,用到的Ground Truth是哪里来的?
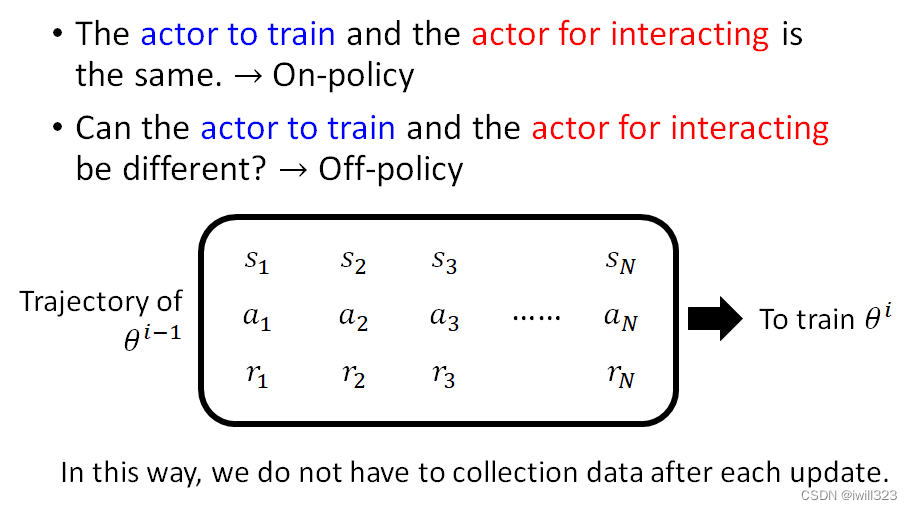
On-policy v.s. Off-policy
On-policy是指:需要更新的actor和与环境互动的actor是一样的。Off-policy就是指不一样的。我们前面讲的是On-policy,而Off-policy的好处是搜集一次资料可以更新多次参数,而不是一笔资料只能更新一次参数。
在训练的那个网络Actor To Train要知道它自己和跟环境互动的Actor To Train是不一样的,所以 Actor To Interact 示范的那些经验有些可以採纳,有些不一定可以採纳。off-policy一个代表性做法是proximal policy optimization(PPO)。
你去问克里斯伊凡怎么追一个女生,然后克里斯伊凡就告诉你说,他只要去告白,从来没有失败过⇒与环境互动的Actor
但是你要知道,你跟克里斯伊凡是不一样的,所以克里斯伊凡可以採取的招数,你不一定能够採取,你可能要打一个折扣⇒真实训练的Actor

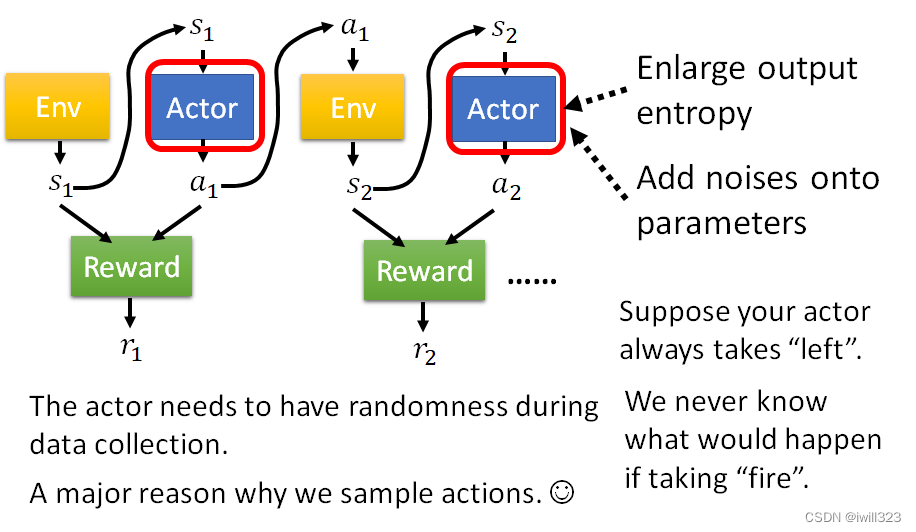
搜集资料的技巧:Exploration--增加Actor的随机性
Actor採取行为的随机性是非常重要的,很多时候随机性不够会训练不起来或训练不出好的结果。如果没有随机性,可能一些 Action 从来没被执行过,那就根本无从知道这个 Action 好或不好。就是要尽力遍历各种可能性,这样才能更加全面地考虑和做决策。
在训练的时候会刻意加大 Actor 的随机性,使输出更加混乱,尽可能让小概率的时间也会有输出。一是放大输出分布的熵,让它在训练的时候比较容易 Sample 到那些几率比较低的行为,二是给actor的参数中添加杂讯,让它每一次採取的行为都不一样。
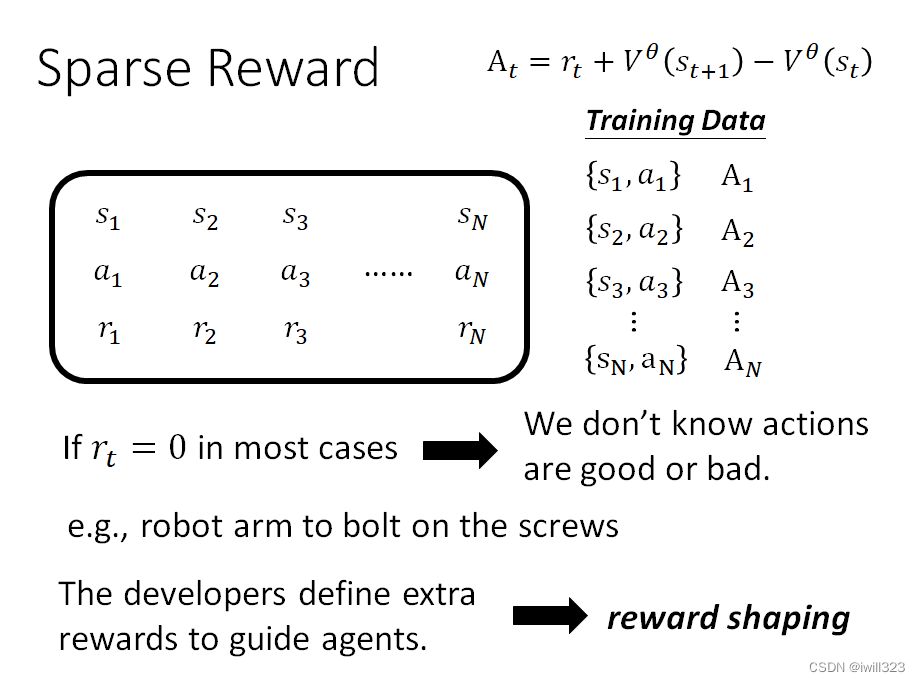
Reward Shaping(sparse reward)
Reward大多数时候都是0,只有在少数时候是一个非常大的数值,这意味着很多action无从判断是好是坏,例如机器臂拧螺丝,初始化时它就在空中隨便揮舞怎麼揮舞 Reward 都是 0,除非它正好非常巧合的拿起一個螺絲,再把它拴進去,才得到正向的 Reward。这时就需要我们提供额外的reward来帮助机器学习,自定义奖励的方法就叫reward shaping。
以vizdoom游戏为例,这个游戏只有最后胜负这一个奖励,所以需要参赛队给自己的机器设置自定义奖励机制。例如扣血了就减分,捡到血包就加分,站着不动扣分,活着也扣分(防止边缘OB)

Curiosity(给机器加上好奇心)
看到“有意义的”“新”东西时,获得reward shaping。特别地,不应看到“噪声”——无意义的“新”

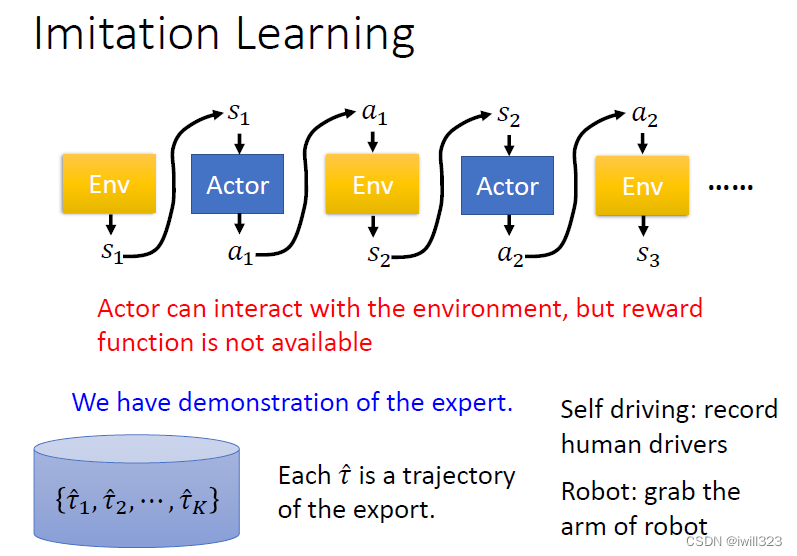
No Reward: Imitation Learning
无奖励的场景
有了自定义奖励,我们为什么还要研究无奖励的情况呢?第一是因为在某些任务中不知道怎么去定义reward。第二是因为有些人为定义的奖励(reward-shaping),如果你的 Reward 沒想好,Machine 可能會產生非常奇怪、無法預期的行為。比如,利用强化学习学习自动驾驶,如何给礼让行人、闯红灯定reward?
actor可以和环境互动但是却没有reward,这种情况就适合使用示范学习,就是先让人类去示范一下怎么跟環境互動,把人類跟環境的互動記錄下來记作τ^,然后用这些示范行为去训练机器。例如自动驾驶:记录人类的驾驶行为,机器臂:拉着机器臂做一次。
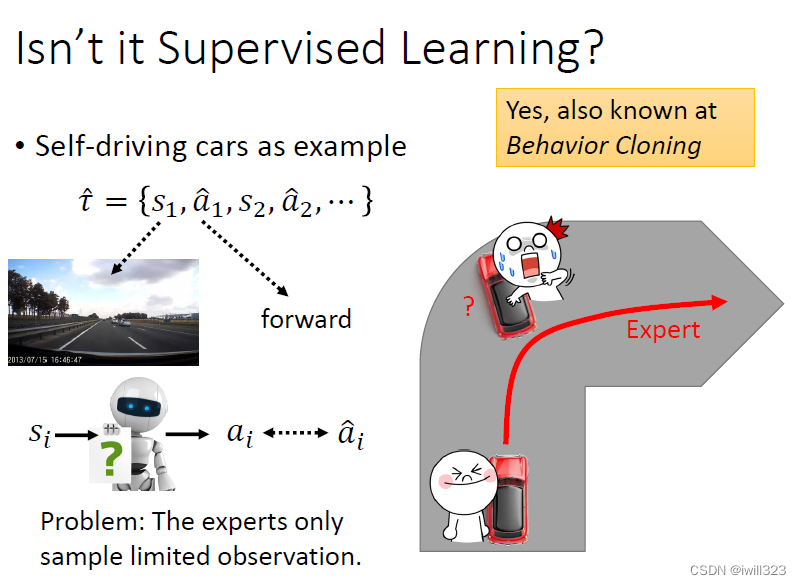
示范学习和监督学习的不同
假如自动驾驶使用监督学习来实现,存在的一个最大问题就是专家示范只是众多可能性中sample出来的,机器碰到不是示范的场景时,机器就不知道做出正确的判断。路口左转是对的,但是如果快要撞到墙了呢,可能车子就撞上去了,因为他没有见过车子还能快要撞到墙。所以supervised learning学出来的行为就是克隆行为了,实用性很差。
另一方面,experts的一些行为,actor是不需要模仿的;actor能力有限,可能无法模仿所有行为,而模仿的行为可能并不能带来好的结果。
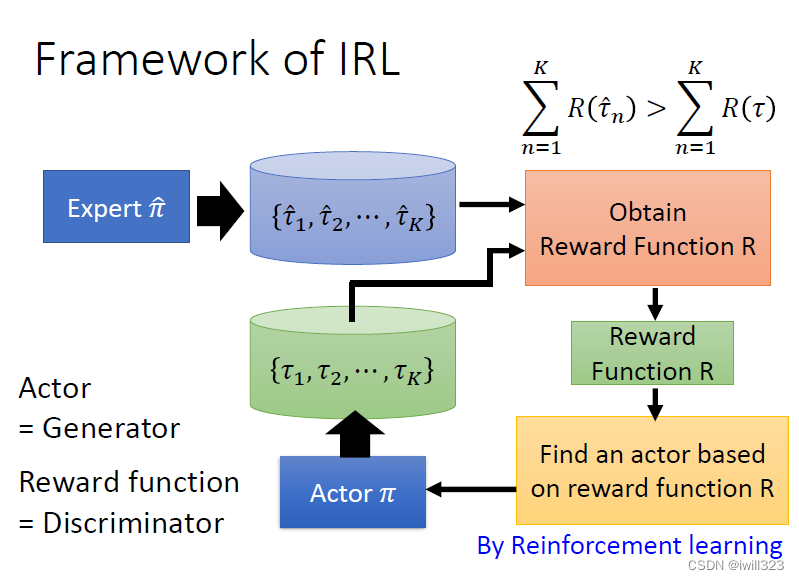
逆向强化学习
原则:老师的行为总是最好的,老师的行为总是能够得到最高的reward,而不是说需要亦步亦趋地模仿。机器自己定reward,即使reward很简单,机器也可能自己衍生出各种复杂的action
從 Expert 的 Demonstration和 Environment,去反推 Reward 應該長什麼樣子。學出一個 Reward Funtion 以後,再直接用一般的 Reinforcement Learning來學你的 Actor。
算法:
- 初始化一个actor。
- 多次迭代
- actor和环境互动,得到一些行为轨迹trajectory τ
- 定义一个reward函数,这个函数能判断老师的行为比actor的行为好
- 基于新的reward函数,actor学习如何最大化reward,以接近老师的行为。(这部分是RL)
- 输出reward函数和学到的actor。

框架如下图:
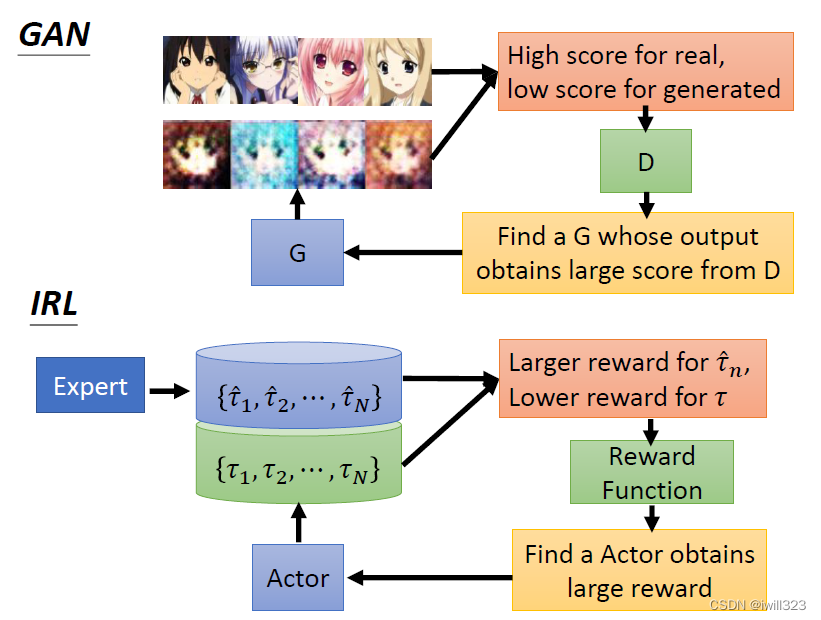
GAN VS IRL
逆向强化学习和GAN的思想一样,可以把actor看成generator,把reward函数看成discriminator。generator是尽可能产生真实的图片来获得高分数以骗过discriminator,actor是尽可能生成和专家轨迹一样的轨迹来获得高的奖励分数。discriminator是监督者,努力去分辨真实图片和生成的图片,而reward function则是努力去给专家轨迹打高分而给actor行为打低分。。
RIG(Reinforcement Learning with Imagined Goals)
让器械臂看到图片,做出图片中的动作。
训练:自己想象目标、自己达到目标。
