本文作者:桂陈
我们常说的数据分析时效性,是指数据从产生到执行分析的时间差,例如本月产生的数据,在经过清洗和处理后,在下月初提供给业务方进行分析。过低的时效性可能无法满足业务需求,例如某企业的服务部署在多个云平台上,由于云平台的账单数据多而杂,该企业每月手动统计汇总并分析一次云成本数据,这种情况下,可能出现云上账单金额激增企业却感知不到的情况。
在之前的《通过图形化界面,两步创建一个指标_Kyligence的博客-CSDN博客》中,我们知道可以通过 Kyligence Zen 快速搭建一站式云端指标中台,实现实时的云成本管理,那么在这篇博客中,我们将介绍如何结合 S3 存储桶和 Kyligence Zen 对增量数据的支持特性,将数据分析时效性从月提升至天。

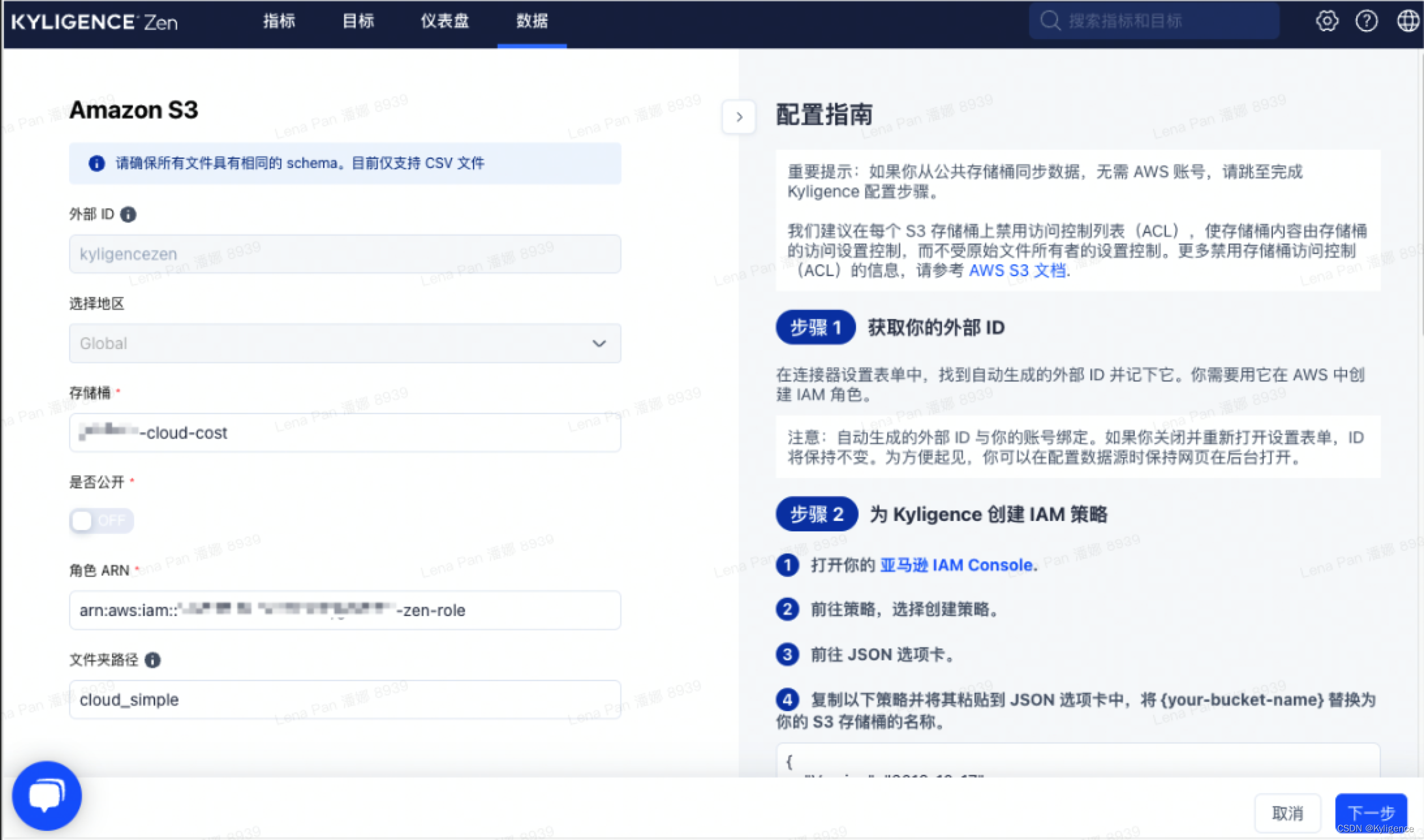
首先,我们在 Kyligence 的数据页面中,选择数据源为 Amazon S3,根据右侧配置向导完成授权并填写存储桶、文件路径等信息。
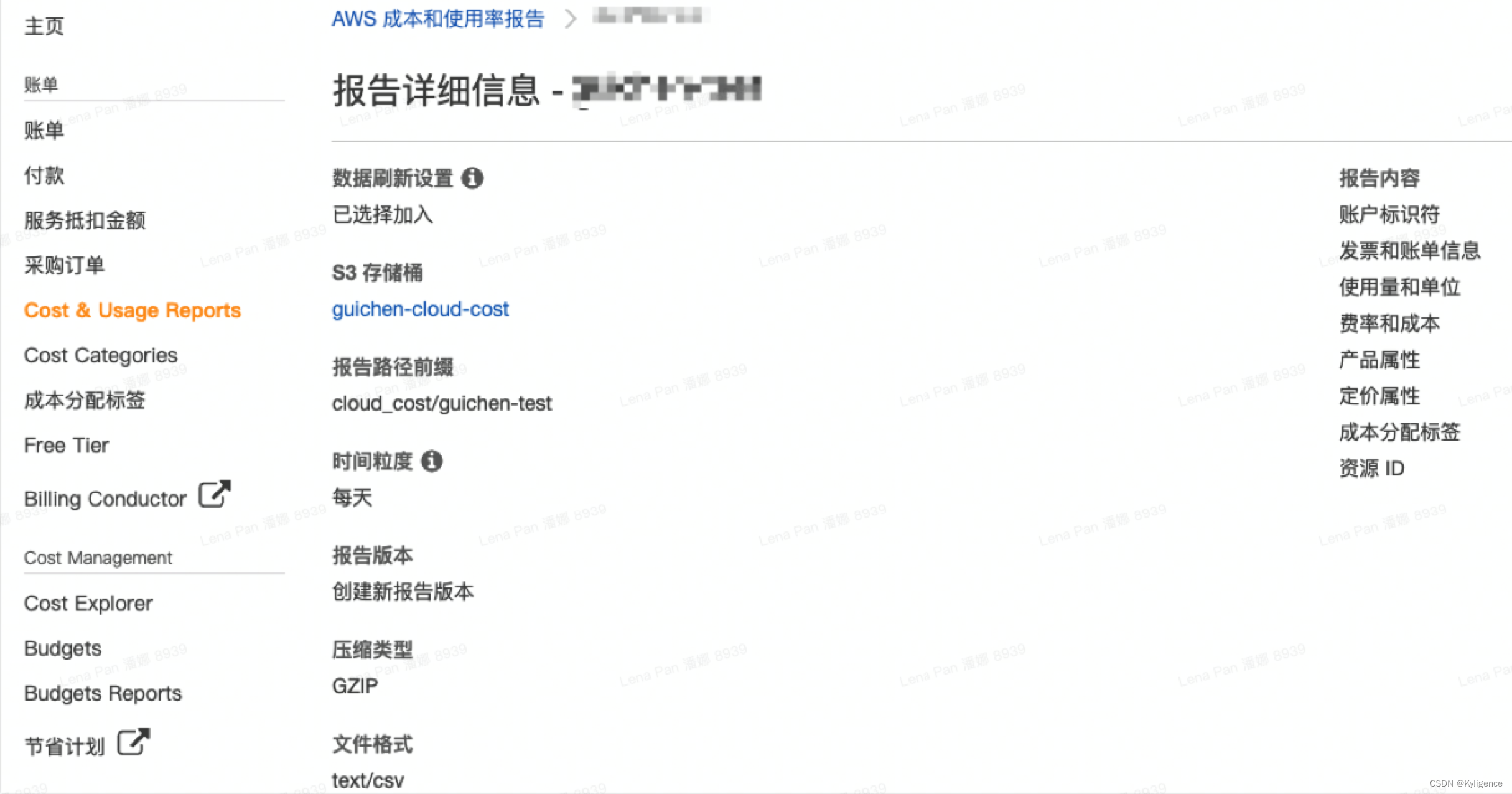
接下来,我们需要前往云平台中创建每天自动生成云账单的任务,以亚马逊云平台为例,我们可以创建云成本和使用率报告,让云平台每天生成云账单数据并存储为 CSV 文件。此处填写的存储桶可以和上一步的一致,同时推荐采用不同的文件路径来存储原始账单文件。
由于原生的云账单数据包含数据非常繁杂,我们可以利用 Amazon Glue 或者开源工具 Byzer 对数据进行清洗和处理(受限于篇幅不展开介绍),保留我们关心的业务数据,然后将加工好的数据保存为一个新文件,将其每天定时上传至作为 Kyligence Zen 数据源的 Amazon S3 对应路径中,整体的数据流转流程如下图所示。

至此,我们已经搭建好了数据流转流程,云账单数据每天会定期存放至 Amazon S3 中,而在执行数据分析时,Kyligence Zen 会自动检索 S3 存储桶路径中的 CSV 文件,并将其视为一个整体执行查询,从而将数据分析的时效性从月提升至天,当然更高的时效性(如小时)也可以参照此流程实现。
Kyligence Zen 提供了免费试用,欢迎前往 Kyligence Zen 官网试用,如您有任何疑问或者有好的想法,欢迎留言交流!
点击下载文中提到的数据集 csv 文件和指标定义文件。