本节我们一起学习有关干预(intervention)的概念。首先,我们介绍一种更加完善而正规的因果图模型——结构因果模型(Structural Causal Model, SCM),然后引入干预的概念,介绍do运算的操作。最后,我们用干预的方式来解释一个非常令人困惑的混杂现象——辛普森悖论。
结构因果模型
首先,我们给出结构因果模型的定义:结构因果模型包含两个变量集合 U 和 V ,以及一组函数 f ,该函数对变量集 V 中的每一个变量进行赋值。
进一步地,因果关系也可以更加正式的被定义:变量 X 是变量 Y 的直接原因(direct cause),如果 X 出现在对 Y 进行赋值的函数中。如果,X 是 Y 的直接原因,或者是 Y 的任何一个原因的原因,那么 X 就是 Y 的原因(cause)。
集合 U 中的变量被称为外生变量(exogenous variables),意思是这些变量是在模型外部存在的,我们不关心它们的因是什么。集合 V 中的变量被称为内生变量(endogenous variables)。模型中的每一个内生变量都是至少一个外生变量的后代。外生变量不能是其他变量的后代,特别是不能是内生变量的后代,它们没有祖先,在图中外生变量就是根节点。如果我们知道每一个外生变量的值,那么利用 f 中的函数,我们就可以完全确定每一个内生变量的值。
每一个SCM都有一个图模型与之对应。图模型中的节点就代表SCM的集合 U 和 V 中的变量,图模型中的边就代表SCM中的函数 f 。一个SCM M 的图模型 G 中每一个节点表示 M 中的每一个变量,如果 M 中有关变量 X 的函数 fX 包含了变量 Y (也即 X 依赖于 Y 的值),那么在图模型 G 中 Y 与 X 之间就有一条边。在一个图形模型中,如果一个变量 X 是另一个变量 Y 的子节点,那么 Y 就是 X 的一个直接原因;如果 X 是 Y 的后代节点,那么 Y 就是 X 的潜在原因。
【例1】图1所示的SCM模型反应了“工资”Z 与“教育背景”X 和“工作经验”Y 的关系。
U={X,Y},V={Z},F={fZ}
fZ:Z=2X+3Y
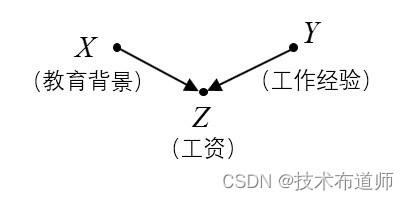
图1:例1
与之前几节的例子不同,我们假设这里的三个变量都是连续变量。例如这个模型中, Z 代表了雇主付给一个员工的工资, X 代表这个人接受教育的年限, Y 代表这个人的工作年限。 X 和 Y 都出现在 fZ 中,所以 X 和 Y 都是 Z 的直接原因。如果 X 和 Y 有祖先,那么这些祖先就是 Z 的潜在原因。
由于 Z 和 X 、 Z 和 Y 之间有边连接,所以我们仅通过观察图模型就可以得出结论:有某个函数 fZ 基于 X 和 Y 来对 Z 进行赋值。因此, X 和 Y 是 Z 的原因。然而,不给出完整的SCM模型,仅通过图模型,我们无法确定定义 Z 的函数,也就无法确定 X 和 Y 到底怎样影响 Z 。
在很多情况下,我们无法测量每一个变量的值,但这些无法测量的变量(误差项)却影响其它我们希望知道的变量。比如下面的例子。
【例2】图2所示的SCM模型反映了“补助金”X、“发表论文数”Y和“考博录取率”Z 的关系。
V={X,Y,Z},U={UX,UY,UZ},F={fX,fY,fZ}fX:X=UXfY:Y=x2000+UYfZ:Z=y5+UZ
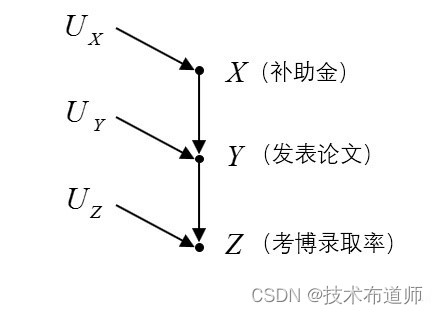
图2:例2
在这个模型中,外生变量 (UX,UY,UZ) 代表任何能够影响内生变量之间关系的位置或随机效应。按照本系列第二节、第三节介绍的方法,我们可以不看SCM,仅通过图模型的结构分析变量之间的独立性或条件独立性。在此进行一个回顾:
- Z 和 Y 是相关的: P(Z=z|Y=y)≠P(Z=z)
- Y 和 X 是相关的: P(Y=y|X=x)≠P(Y=y)
- Z 和 X 是(似然,likely)相关的: P(Z=z|X=x)≠P(Z=z)
- 以 Y 为条件,Z 和 X 是独立的: P(Z=z|X=x,Y=y)=P(Z=z|Y=y)
以上的SCM是一个链接合的图模型,对于叉接合和对撞接合也同样类似。
【例3】图3所示的SCM模型反映了“天气温度”X、“冰激凌销量”Y和“犯罪事件数”Z 的关系。
V={X,Y,Z},U={UX,UY,UZ},F={fX,fY,fZ}fX:X=UXfY:Y=4x+UYfZ:Z=x10+UZ
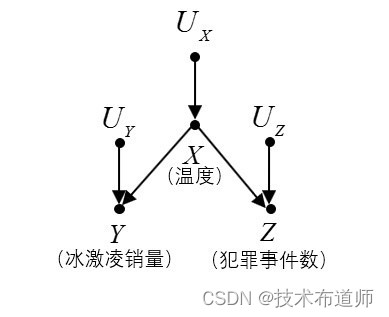
图3:例3
同样也可分析变量之间的独立性或条件独立性。在此不做解释,仅提供结论:
- X 和 Y 是相关的: P(X=x|Y=y)≠P(X=x)
- X 和 Z 是相关的: P(X=x|Z=z)≠P(X=x)
- Z 和 Y 是(似然,likely)相关的: P(Z=z|Y=y)≠P(Z=z)
- 以 X 为条件,Y 和Z 是独立的: P(Y=y|Z=z,X=x)=P(Y=y|X=x)
干预和do运算
就目前为止,我们提到的操作仍然只属于因果关系之梯的第一层级——关联。即便是“以某个变量为条件(conditioning on)”的操作,也只是依据现有观测到的数据进行统计,并没有改变数据的分布。回想第一节巧克力与诺贝尔奖的例子,我们从数据中得出的巧克力与诺贝尔奖之间有相关性,这便是关联。而要进行干预,我们就得改变现有的数据分布,给原来没吃巧克力的国家的人吃巧克力,或者给吃了很多巧克力的国家的人停止吃巧克力。
在实际应用中,干预也非常重要。比如,当我们对一种新的抗癌药物进行研究时,我们试图确定当我们对病人进行药物干预时,病人的病情如何变化。当我们研究暴力电视节目和儿童的攻击行为之间的关系时,我们希望知道,干预减少儿童接触暴力电视节目是否会减少他们的攻击性。
干预(intervention)和以变量为条件(conditioning on)有着本质的区别。当我们在模型中对一个变量进行干预时,我们将固定这个变量的值。其他变量的值也随之改变。当我们以一个变量为条件时,我们什么也不会改变;我们只是将关注的范围缩小到样本的子集,选取其中我们感兴趣的变量的值。因此,以变量为条件改变的是我们看世界的角度,而干预则改变了世界本身。
当我们进行干预以确定一个变量的值时,我们就限制了该变量随其他自然变量而变化的自然趋势。在图模型中,干预的操作将删除所有指向该变量的边。以图3为例,如果我们要进行干预以降低冰激凌销量(比如,关闭所有冰激凌店),那么我们就去掉所有指向冰激凌销量 Y 的边,并得到如图4所示的图模型。当我们在这个新的图模型中检验相关性时,我们发现犯罪率当然是与冰激凌销量完全独立的,因为冰激凌销量已经与天气温度无关了。换句话说,即使我们将 Y 的值调整为另一个不变的值,这种变化也不会传递给可变的犯罪率 Z 。我们看到,与以某个变量为条件不同,干预一个变量会导致一种完全不同的相关性关系,以某个变量为条件可以完全从数据中获得,但干预却会影响图模型结构的变化。
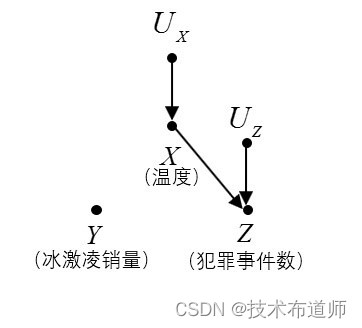
图4:对冰激凌销量进行干预的结果
在符号的表达上,我们使用do算子来表达这种干预。比如,当我们固定 Y 的值为 y 时,我们用 do(Y=y) 来表示这种干预行为。所以 P(Z=z|Y=y) 表示当以Y=y 为条件时 Z=z 的概率,而 P(Z=z|do(Y=y)) 表示当我们干预 Y 的值使其为 y 时,Z=z 的概率。从概率分布的角度来说,P(Z=z|Y=y) 表示的是在 Y 可取的所有值中,Y=y 那部分样本对应的 Z=z 的概率,而P(Z=z|do(Y=y)) 表示的是将每一个样本的 Y 的值全部固定为 y 后 Z=z 的概率。
这两者是完全不同的,干预改变了原始数据的分布,而以变量为条件不改变原始数据的分布。
这里需要指明一点,我们默认假设对某一个变量进行干预操作不会产生“副作用”,即不会对其他变量的关系产生影响。
为了更好地探究do运算的干预方式能够怎样解决混杂的问题,我们引入一个著名的混杂问题:辛普森悖论。
辛普森悖论
辛普森医生发现了一种新药,这种新药可以降低心脏病发作的风险,于是他开始查找历史的实验数据。他注意到,如果男性患者服用了这种药,心脏病发作的风险反而变高了。然后他再转向女性患者,结果大吃一惊:女性患者服用这种药以后心脏病发作的风险也变高了。但是这种药从数据上来说,对人类是有益的呀。为什么对女性有害、对男性有害,但对人类有益?这是怎么搞的。
让辛普森医生疑惑的数据如下表所示。这个数据是虚拟的,但足够说明问题。辛普森医生发现,对于男性来说,吃药的人心脏病不发作的概率是93%,不吃药的人心脏病不发作的概率是87%,这看起来吃药比不吃药好。对于女性来说,吃药的人心脏病不发作的概率是73%,不吃药的人心脏病不发作的概率是69%,这看起来也是吃药比不吃药好。但是神奇的事情是,如果把男性和女性合起来考虑,那吃药的人心脏病不发作的概率是78%,不吃药的人心脏病不发作的概率是83%,反而是不吃药更好了!
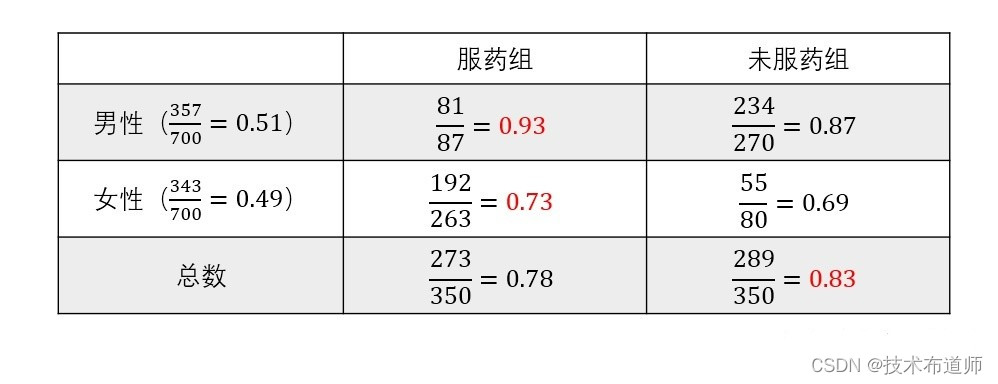
图5:辛普森悖论虚构数据
那到底是吃药好还是不吃药好呢?难道说在知道病人性别的情况下吃药好,在不知道病人性别的情况下,不吃药好吗?这显然是个荒谬的悖论问题。这个问题很长时间把人们弄糊涂。后来人们就把这种分组看相对频率与合并起来看相对频率出现反转的例子,叫做辛普森悖论。但其实,这是一个非常正常的数学现象。上过小学的人都知道:如果 A/B>a/b 且 C/D>c/d ,那么我们不能推出 (A+C)/(B+D)>(a+c)/(b+d) 。这很简单的数学道理但是人们总是转不过弯来。其实这就是一个简单的混杂问题:男性和女性服药与不服药的比例是不同的,男性服药的人数远远小于不服药的人数,而女性服药的人数远远大于不服药的人数,因此性别是服用药物和心脏病发作的一个混杂因子,它的因果图如下所示(我们假设存在三个外生变量):
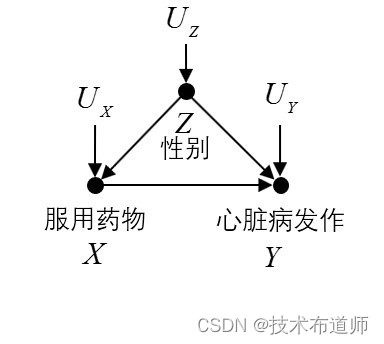
图6:辛普森悖论因果图
为了找出这种药物在人群中到底是有效还是有害,我们构造一种假设的干预方法,我们假设给所有人都服用药物,即 do(X=1) ;然后我们假设给所有人都不服用药物,即 do(X=0) ,然后我们对两次干预的结果进行比较(比较心脏病发作的概率),即我们计算:
P(Y=1|do(X=1))−P(Y=1|do(X=0))
由于在这个例子中, X 和 Y 的取值只有0和1两种情况,所以我们的干预只会进行两种情况。如果 X 和 Y 的值是连续值而不是二元变量,那么我们其实应该计算的是 P(Y=y|do(X=x)) 的值,其中 x 和 y 分别是 X 和 Y 可取的值,比如 x 表示药的剂量, y 表示受试者的血压值等等。
那么按照之前的规定,为了进行do运算,我们需要修改因果图,对谁进行干预就把指向谁的箭头去掉。于是我们去掉 Z→X 这条边。因果图变成了图7的样子。
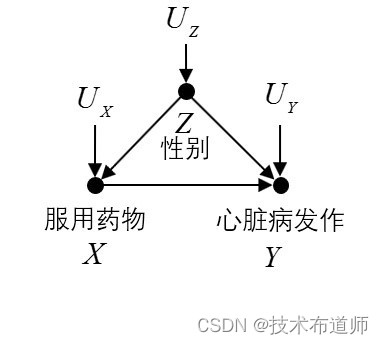
图7:干预后的辛普森悖论因果图
我们用下标m表示修改后的概率分布,那么我们想要通过干预知道的是 P(Y=y|do(X=x)) 的值,也即是 Pm(Y=y|X=x) 。我们知道,经过干预, Z 的边缘分布是不变的,也即有:
Pm(Z=z)=P(Z=z)
同时,我们还知道,经过干预,以 Z 和 X 为条件的 Y 的条件概率是不变的,也即
Pm(Y=y|Z=z,X=x)=P(Y=y|Z=z,X=x)
把以上几个关系连在一起就有了:
P(Y=y|do(X=x))=Pm(Y=y|X=x)=∑zPm(Y=y|X=x,Z=z)Pm(Z=z|X=x)=∑zPm(Y=y|X=x,Z=z)Pm(Z=z)=∑zP(Y=y|X=x,Z=z)P(Z=z)
第一个等号是do运算的定义决定的。第二个等号是根据全概率公式。第三个等号是因为经过干预后 Z 和 X 是相互独立的。最后第四个等号则是之前已经得出的两个不变的分布。最终得到的这个公式也就叫做调整公式(adjustment formula),这个运算过程也叫作调整 Z (adjusting for Z )或者控制 Z (controlling for Z):
P(Y=y|do(X=x))=∑zP(Y=y|X=x,Z=z)P(Z=z)
调整公式的等号右边全部都是干预操作之前的概率分布,也就是说全部是可以从观测数据中获得的概率分布,这意味着我们可以用观测数据来进行干预。
因此,我们就可以对辛普森悖论的例子进行干预操作,从而得知到底是吃药好还是不吃药好。具体计算如下:
P(Y=1|do(X=1))=P(Y=1|X=1,Z=1)P(Z=1)+P(Y=1|X=1,Z=0)P(Z=0)
而从数据中我们可知
P(Y=1|do(X=1))=0.93×(87+270)700+0.73×(263+80)700=0.832
P(Y=1|do(X=0))=0.87×(87+270)700+0.69×(263+80)700=0.781
从以上结果不难得知,吃药还是比不吃药,对心脏病的帮助要好那么一点点。而通过图5的表,我们知道 P(Y=1|X=1)=0.78, P(Y=1|X=0)=0.83 。可见如果不加干预仅从原始数据归纳出的条件概率我们是无法得出正确的结论的。
在本节中,我们爬上了因果关系之梯的第二层级——干预。本节主要内容来源于《Causal Inference in Statistics: A Primer》[1]一书第2章、第3章。大部分为原文内容精选后的翻译。标题图片来源于Youtube视频截图。
参考
- ^ Judea Pearl, Madelyn Glymour, and Nicholas Jewell, "Causal Inference in Statistics: A Primer",Wiley