前面我介绍了单元测试和基准测试,它们是基于代码层面的测试,需要对代码逻辑比较熟悉。这一讲,我将为你介绍下基于 API 层面的性能分析。
为什么要做基于 API 的性能分析呢?这是因为单元测试和基准测试偏向于测试单个函数,缺乏对整个链路做性能测试的能力,而针对 API 的性能分析则可以分析出 API 的性能瓶颈在哪,该如何优化。
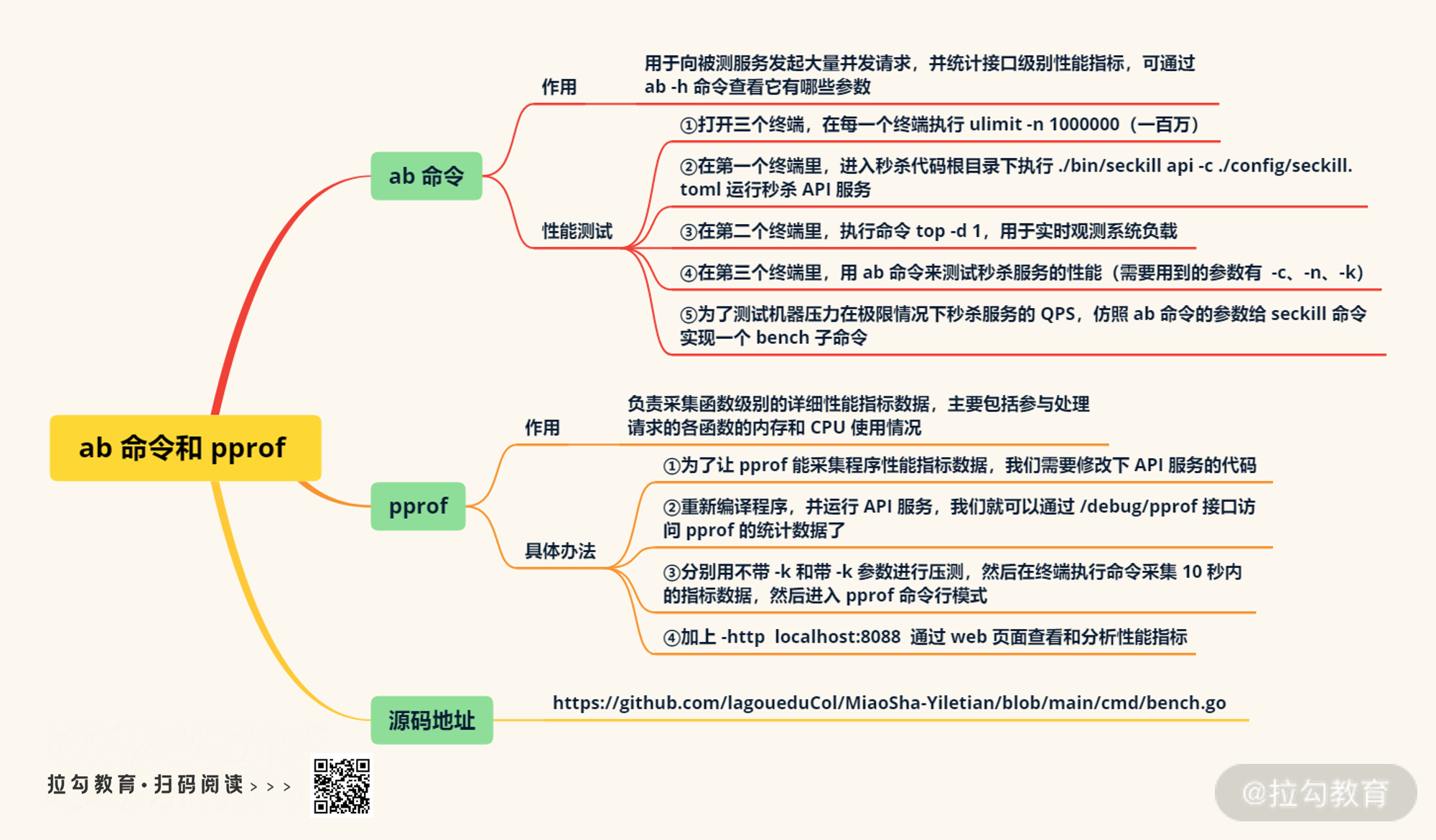
当我们做 API 性能分析的时候,程序对于我们来说是个黑盒子,此时需要借助两个工具:ab 命令和 pprof。其中 ab 命令主要用于向被测服务发起大量并发请求,并统计接口级别性能指标;而 pprof 负责采集函数级别的详细性能指标数据,它主要包括参与处理请求的各函数的内存和 CPU 使用情况。就这样,根据大量请求的性能指标数据,我们可以分析出程序的性能瓶颈。
具体怎么做呢?接下来我给你详细介绍下。
ab 命令
ab 命令是 Linux 系统下常用的压测命令,它的用法非常简单,你可以通过 ab -h 命令查看它有哪些参数。如下图所示:
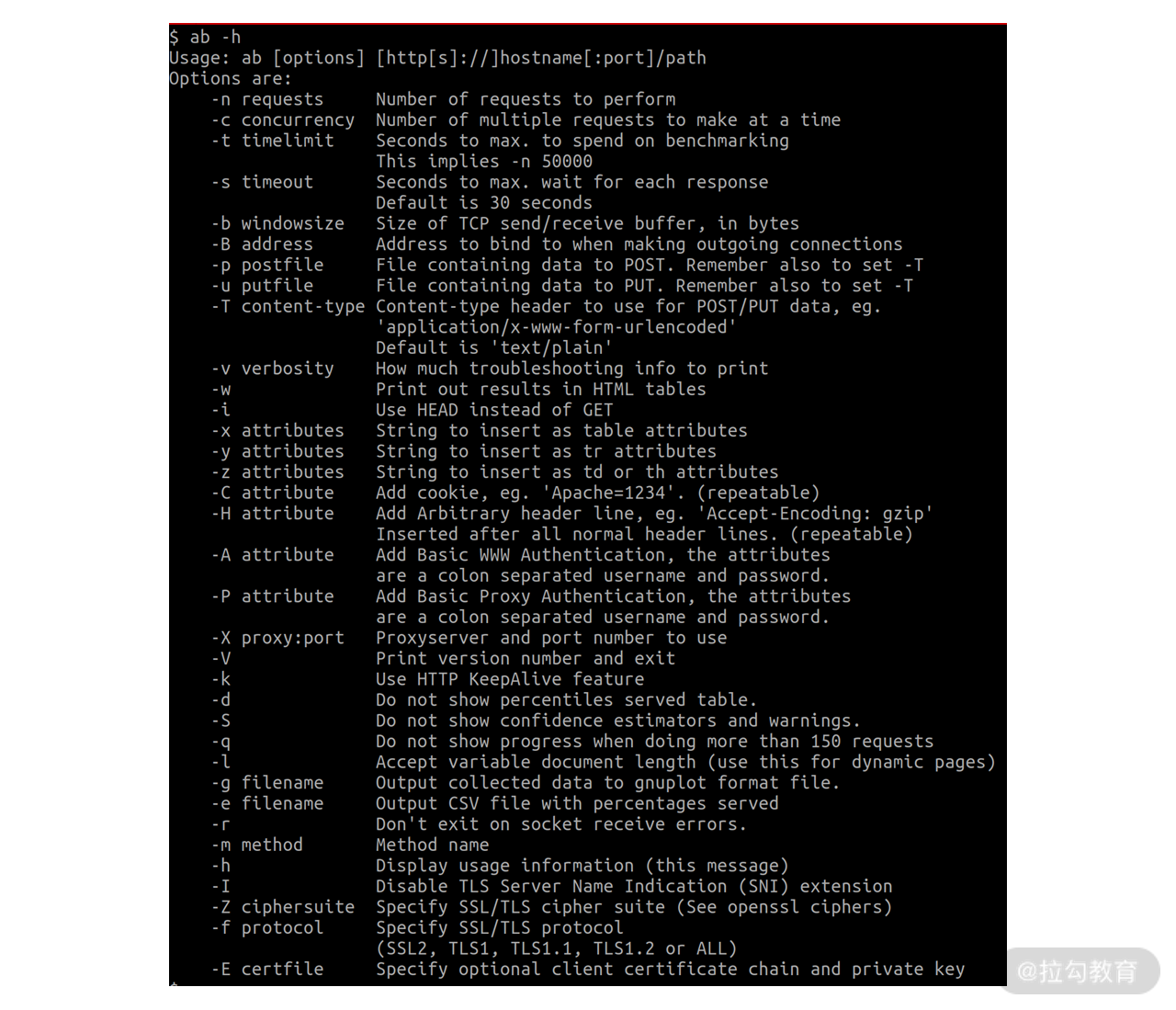
这些参数有许多,其中常用的参数主要有:
-n 用于指定总共发起多少请求;
-c 用于指定同时发起的请求数,也就是并发数;
-T 用于指定请求数据格式;
-k 表示保持连接,也就是每次请求复用前面建立的连接;
-m 用于指定请求方法名称,如 GET、POST 等。
接下来,我们看下如何用上面这些参数来给秒杀系统做性能测试。
第一步,打开三个终端,在每一个终端执行 ulimit -n 1000000(一百万)。这是做什么呢?其实操作系统对资源的使用是有默认限制的,比如最大打开文件数通常默认是 1024。当我们进行并发测试的时候,会瞬间建立大量连接。如果系统默认限制是 1024,很容易成为测试的瓶颈,无法测出服务的准确性能。
第二步,在第一个终端里,进入秒杀代码根目录下执行 ./bin/seckill api -c ./config/seckill.toml 运行秒杀 API 服务。
第三步,在第二个终端里,执行命令 top -d 1,用于实时观测系统负载。
第四步,在第三个终端里,我们需要用 ab 命令来测试秒杀服务的性能。
具体参数该怎么定呢?比如我的电脑是 8 核,这代表硬件层面能同时处理 8 个任务,也就是能同时发起 8 个请求,因此我用 -c8 来指定并发数为 8。
除了并发数,还有个比较重要的参数 -n 需要合理设置。对于秒杀服务来说,它的性能很高,需要将总请求数设置的足够大,才能让测试过程持续时间足够长,以便我们能有时间观测到电脑的实际负载。比如在我电脑上测试时,-n 指定为 1000000(一百万),不超过 ulimit -n 设置的大小。
此外,为了测试复用连接和不复用连接时的性能差异,我们还需要测试在设置和不设置**-k 参数**两种情况下的性能表现。
为了尽量模拟业务场景,我在 /event/list 接口的代码中添加了测试数据,用于测试接口性能。我在该接口里返回了 10 场活动的数据,每场活动 10 个商品,总共 100 个商品,json 编码后的数据大概在 8KB 左右。
为了方便执行命令,我将命令添加到了 Makefile 中,然后执行 make runApi 将启动秒杀系统 API 服务,执行 make ab 将开始不带 -k 参数的测试,执行 make ab-k 则开始带 -k 参数的测试。如下所示:
runApi:
ulimit -n 1000000
./bin/seckill api -c ./config/seckill.toml
ab:
ulimit -n 1000000
ab -n 1000000 -c 8 http://localhost:8080/event/list
ab-k:
ulimit -n 1000000
ab -n 1000000 -c 8 -k http://localhost:8080/event/list
最终,执行 make ab 的结果如下:
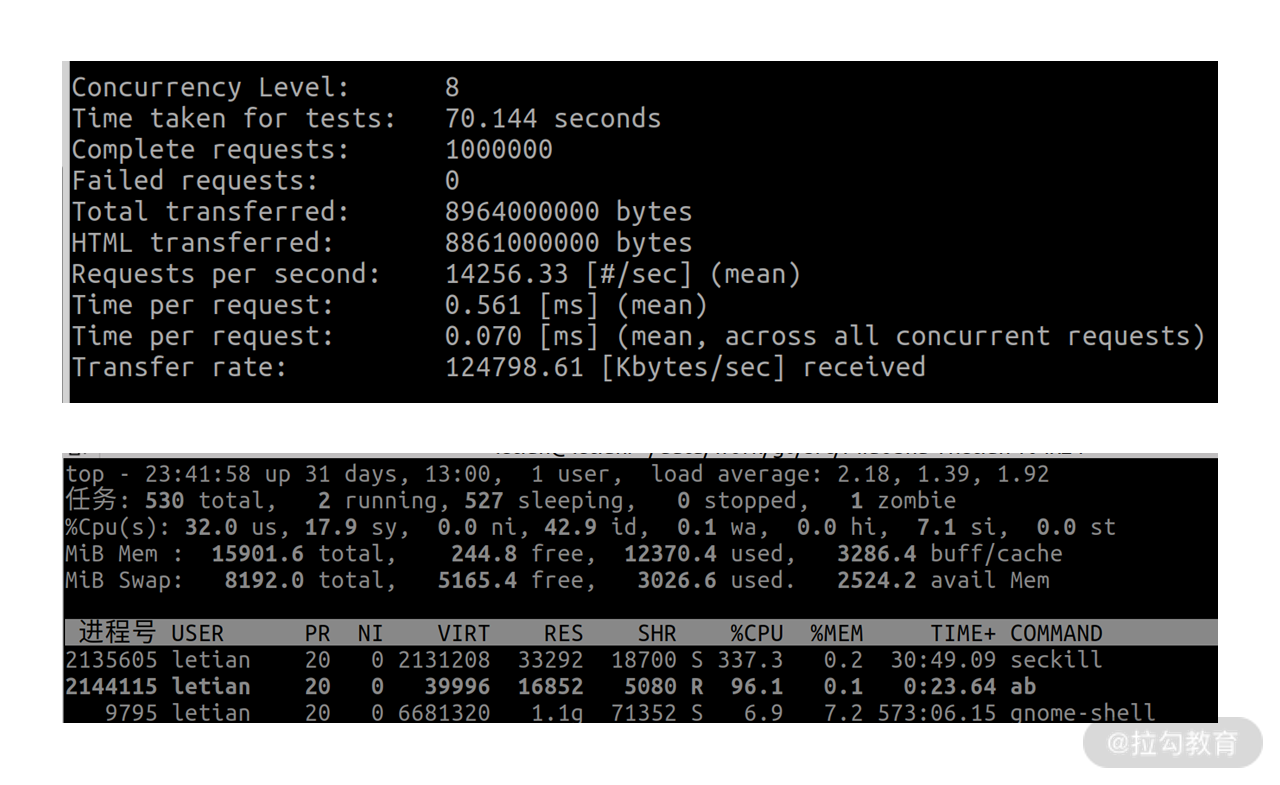
我们可以看到 Requests per second 也就是 QPS 为 14256.33, seckill 的 CPU 占用为 337.3%。
make ab-k 的结果如下:
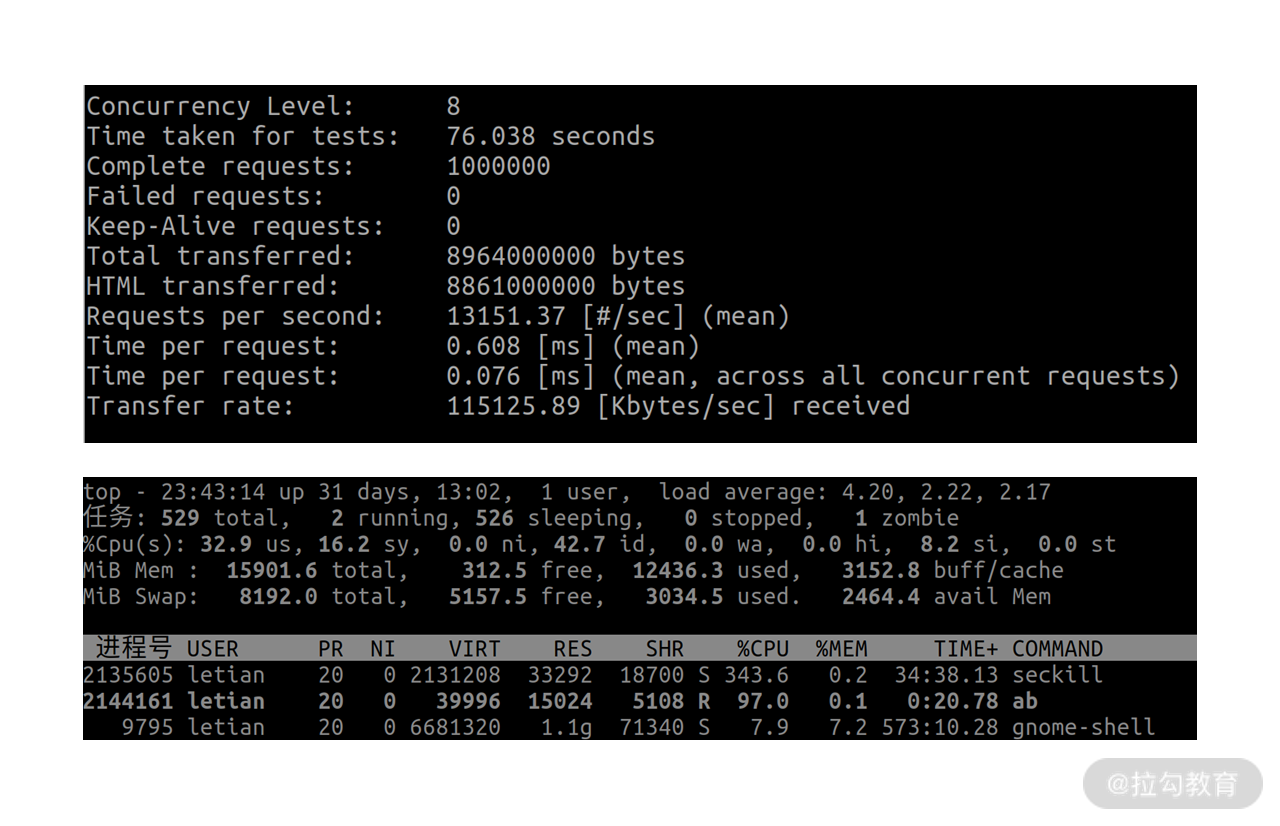
其中 QPS 为 13151.37,seckill CPU 占用为 343.6%。
由于电脑上还运行了其他程序,结果可能会存在一些偏差,但还是具有参考意义。你可以看到,请求 QPS 在 13000 ~ 14000 左右,seckill CPU 使用率在 340% 左右,也就是占用了 3.4 个 CPU 核,也就能推算出来 1 个 CPU 核能扛 4000 左右 QPS 。但是 ab 命令的 CPU 使用率一直都没超过 100%,这是为什么呢?原因在于ab 命令是单线程模型。
为了测试机器压力在极限情况下秒杀服务的 QPS,我仿照 ab 命令的参数给 seckill 命令实现了一个 bench 子命令。代码如下:
func doBench() {
runtime.GOMAXPROCS(4)
wg := &sync.WaitGroup{}
startCh := make(chan struct{})
success := int32(0)
failed := int32(0)
reqs := requests
wg.Add(concurrency)
wg1 := &sync.WaitGroup{}
wg1.Add(concurrency)
for i := 0; i < concurrency; i++ {
go func() {
cli := &http.Client{
Transport: &http.Transport{
TLSClientConfig: &tls.Config{},
},
Timeout: 10 * time.Second,
}
wg1.Done()
<-startCh
for atomic.AddInt32(&reqs, -1) >= 0 {
if !keepalive {
cli = &http.Client{
Transport: &http.Transport{
TLSClientConfig: &tls.Config{},
DisableKeepAlives: true,
},
Timeout: 10 * time.Second,
}
}
resp, err := cli.Get(url)
if err != nil || resp.StatusCode > 404 {
logrus.Error(err)
atomic.AddInt32(&failed, 1)
} else {
atomic.AddInt32(&success, 1)
}
if resp != nil {
ioutil.ReadAll(resp.Body)
resp.Body.Close()
}
if !keepalive {
cli.CloseIdleConnections()
}
}
wg.Done()
}()
}
wg1.Wait()
close(startCh)
start := time.Now().Unix()
wg.Wait()
end := time.Now().Unix()
fmt.Printf("total: %d, cost: %d, success: %d, failed: %d, qps: %d\n", requests, end-start, success, failed, requests/int32(end-start))
}
总的思路是这样:
限制 bench 命令只使用 3 个 CPU 核,另外 5 个 CPU 核留给秒杀 API 服务和其他程序用;
根据并发数参数创建多个 Go 协程,它们内部接收一个统一的 channel 通知后开始发起请求,所有请求执行完毕后通过一个统一的 sync.WaitGroup 同步状态;
在每个协程中,根据 keepalive 参数控制是否复用连接,并且统计请求的成功数和失败数;
在主协程中,先用 sync.WaitGroup 等待所有协程就绪,然后通过关闭 channel 的方式给每个协程发送开始通知并开始计时;
主协程等待所有协程处理完,并输出统计信息。
同样地,我也在 Makefile 中加上了它的命令。执行 make bench 将执行不带 -k 参数的命令,make bench-k 则是带 -k 参数的。如下所示:
bench:
ulimit -n 1000000
./bin/seckill bench -C 16 -r 1000000 -u http://localhost:8080/event/list
bench-k:
ulimit -n 1000000
./bin/seckill bench -C 16 -k -r 1000000 -u http://localhost:8080/event/list
不带 -k 参数结果如下:
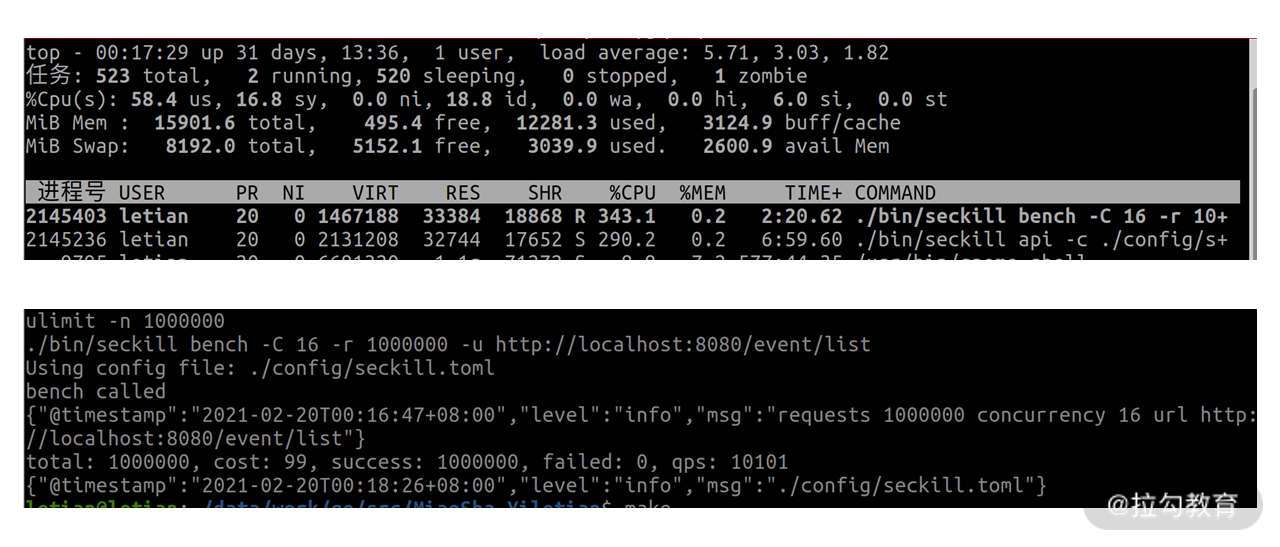
其中 API 服务 CPU 占用为 290.2%,QPS 为 10101。
带 -k 参数结果如下:
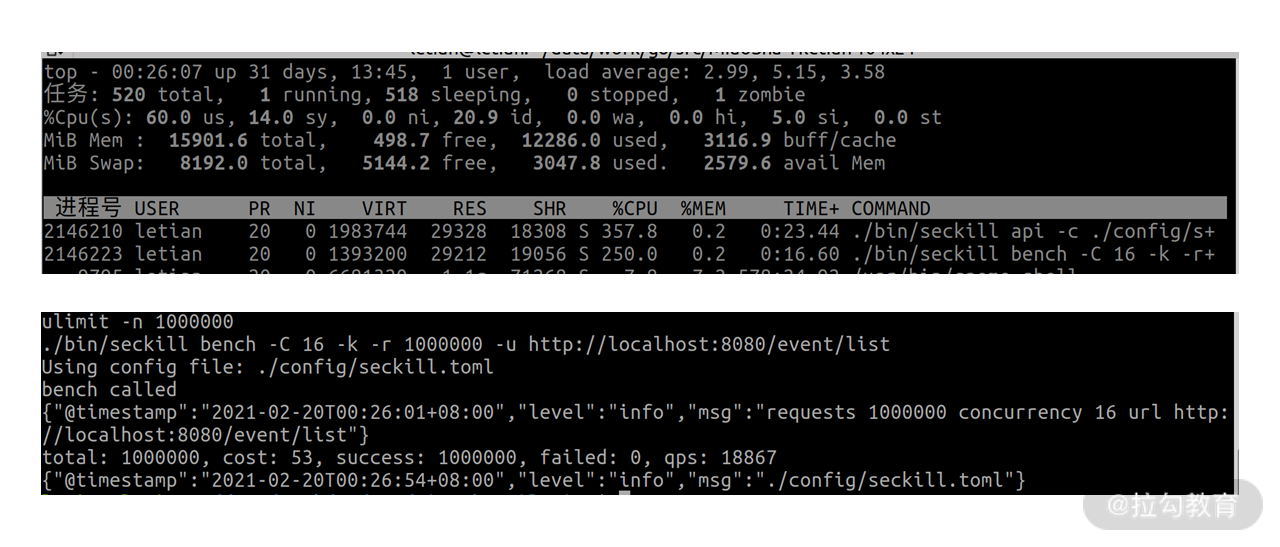
其中 API 服务 CPU 占用为 357.8%,QPS 为 18867。
你可以看到,不加 -k 参数的时候,bench 命令要比 API 服务 CPU 高,那是因为它要频繁发起新的连接。加了 -k 参数后,QPS 从 10101 提升到了 18867,API 服务的 CPU 占用也上来了,达到了 357%。根据测试结果就可以算出来,不加 -k 参数时,一个 CPU 核能扛 3500 左右 QPS;加上 -k 参数后,一个 CPU 核能扛超过 5000 QPS,达到了 5284。
pprof
通过前面的测试,我们发现:QPS 提升后,CPU 占用也高了。那么,具体是哪些函数占用了 CPU 呢?这就需要借助 Go 自带的性能分析大杀器 pprof 了。
为了让 pprof 能采集程序性能指标数据,我们需要修改下 API 服务的代码。假如你用的是 Go 标准库的 Web 框架,只需要在代码中引入标准库中的 "net/http/pprof" 包即可。但咱们用的是 gin 框架,需要在 interfaces/api/api.go 文件中引入针对 gin 框架封装的 pprof 包 "github.com/gin-contrib/pprof",然后在 Run 函数中调用 pprof.Register 函数将 gin 实例注册到 pprof。
接下来,我们重新编译程序,并运行 API 服务,我们就可以通过 /debug/pprof 接口访问 pprof 的统计数据了。比如我在浏览器中访问后得到如下信息:
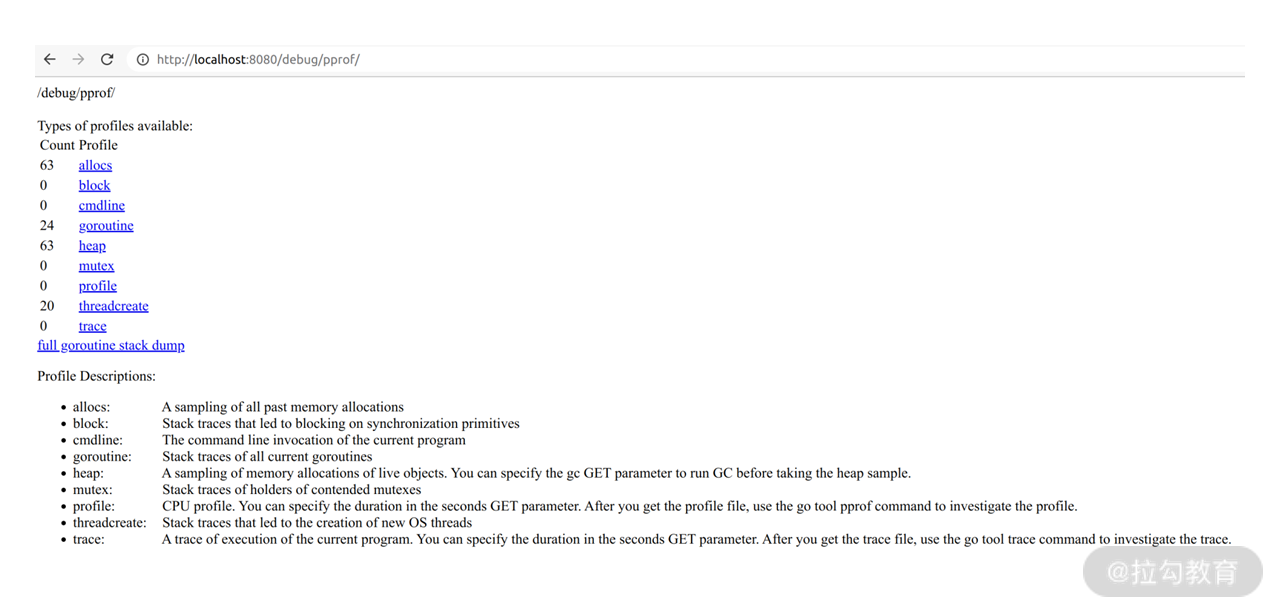
通常我们需要关注的主要是 allocs、goroutines、heap 这几个指标,点击相应的连接还能看到详细的堆栈信息。不过这些信息不是很直观,因此 pprof 还提供了 profile 这个数据,不过它是二进制数据,需要借助 go tool pprof 命令来解析,它有两种查看方式:命令行和网页。
接下来我们按照前面的方式,分别用不带 -k 和带 -k 参数进行压测,然后在终端执行 go tool pprofhttp://localhost:8080/debug/pprof/profile?seconds=10将采集 10 秒内的指标数据,然后进入 pprof 命令行模式。
pprof 功能非常强大,有很多子命令。比如你可以通过 top N 命令查看占用 CPU 资源排名前 N 的函数。下面是使用不带 -k 参数压测时,pprof 效果如下:
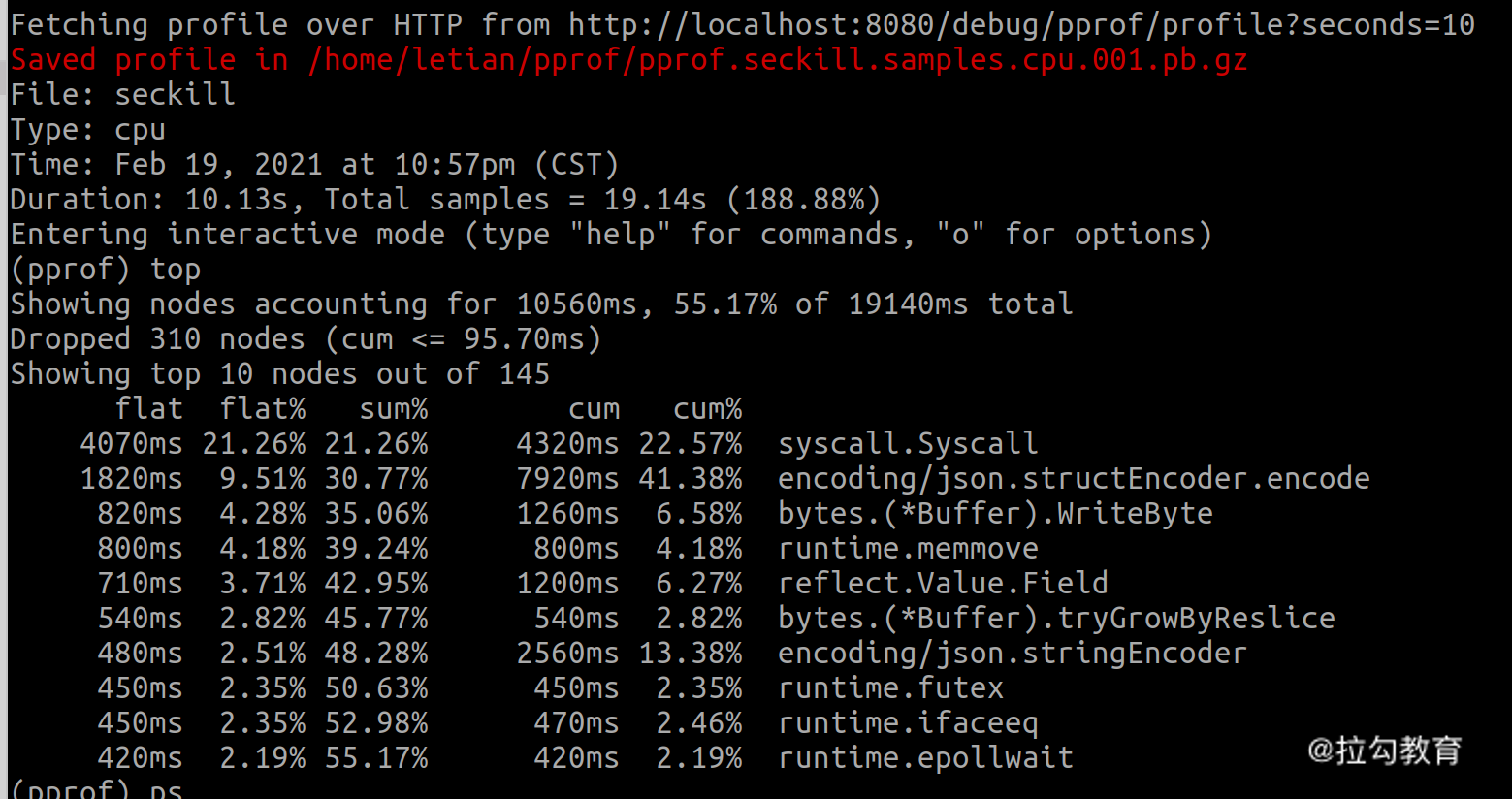
可以看到主要是 syscall 占用 CPU 较高,达到了 21.26%,主要是因为要频繁处理连接的建立和关闭。
带 -k 参数时,pprof 效果如下:
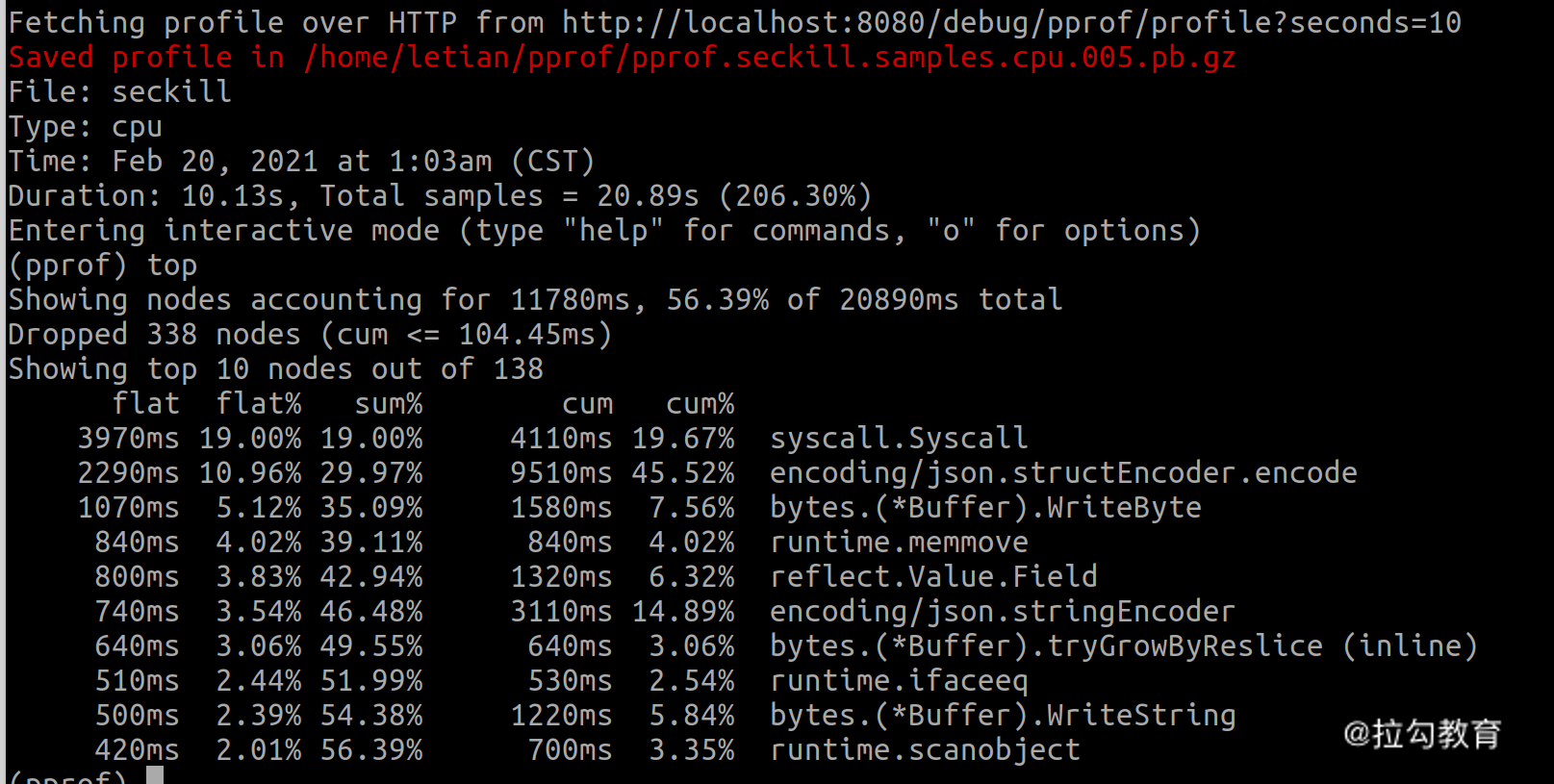
可以看到 syscall 的占比从 21.26%下降到了 19%,而 encoding/json 的占比从 9.51% 上升到了 10.96%。
不过,**pprof 更强大的是它的可视化能力,也就是通过 web 页面查看和分析性能指标。**比如我们在前面的命令里加上 -http localhost:8088 就可以通过 http://localhost:8088 访问页面查看可视化后的性能指标。它的首页展示了每个函数调用在 10 秒内耗费的时间,以及用粗箭头表示的关键路径,效果如下:
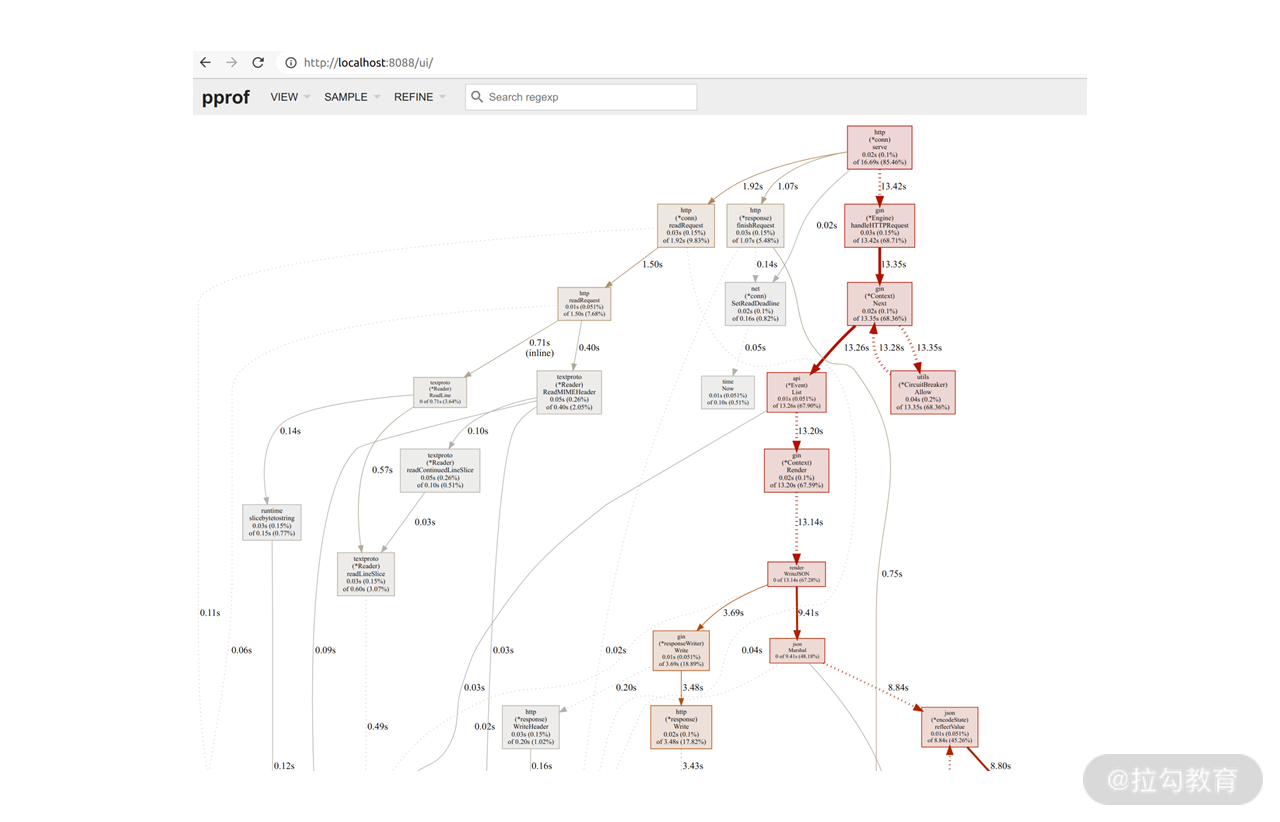
不过,有了具体的耗时还不够直观,我们还可以通过火焰图来分析。具体做法是点击左上角的 VIEW 菜单,切到 Flame Graph 模式,效果如下:
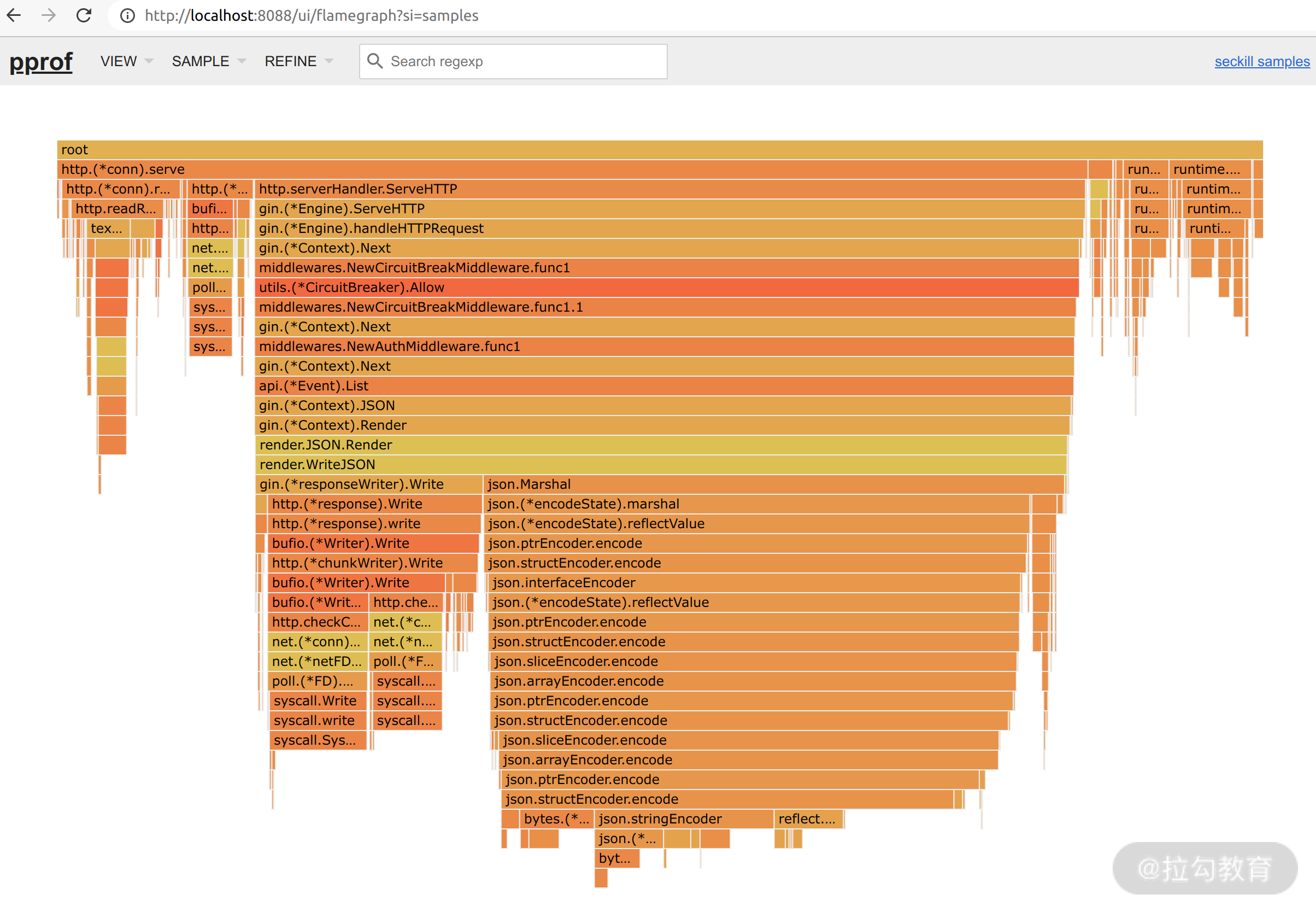
你会看到一个个或橙色或黄色的横条,每个横条上都标记有对应的函数,鼠标放上去还能看到 CPU 占用百分比。这个图就描述了函数调用栈中每个函数所耗费的时间占比,横条越宽表示占比越高,每个横条的占比一般是它下一层所有横条之和再加上它自身的实际占比。
这里我们需要关注的是:从下往上看时,横条宽度变化最大的,优化的潜力最大。比如 json.structEncoder.encode 这个函数相比它下一层各函数的宽度之和,要多出很大一截。它的具体实现如下:
func (se structEncoder) encode(e *encodeState, v reflect.Value, opts encOpts) {
next := byte('{')
FieldLoop:
for i := range se.fields.list {
f := &se.fields.list[i]
// Find the nested struct field by following f.index.
fv := v
for _, i := range f.index {
if fv.Kind() == reflect.Ptr {
if fv.IsNil() {
continue FieldLoop
}
fv = fv.Elem()
}
fv = fv.Field(i)
}
if f.omitEmpty && isEmptyValue(fv) {
continue
}
e.WriteByte(next)
next = ','
if opts.escapeHTML {
e.WriteString(f.nameEscHTML)
} else {
e.WriteString(f.nameNonEsc)
}
opts.quoted = f.quoted
f.encoder(e, fv, opts)
}
if next == '{' {
e.WriteString("{}")
} else {
e.WriteByte('}')
}
}
你可以看到,该函数中有两层循环,其中内循环中都是反射调用,而 Go 的反射性能不是很好,因此该函数性能会较差。
但是,json 这个包是标准库的包,我们不大可能去改它。不过我们可以采用第三方库来代替它,比如 ffjson。它通过结构体定义生成特定的序列化、反序列化代码,尽量避免了反射调用。
小结
这一讲我介绍了如何用 ab 命令以及自己开发的 bench 命令做接口性能测试,还介绍了 Go 语言强大的性能分析工具 pprof 的用法,希望对你有所帮助。除了 pprof 工具外,Go 自带的静态代码分析工具也能在一定程度上给出一些性能优化建议,比如内存逃逸分析工具可以分析代码中哪些变量是在堆上分配内存的,你可以根据分析结果优化代码提升性能。
接下来给你出个思考题:如何将 bench 命令打造成一个分布式压测工具?期待你在留言区讨论哦!
好了,这一讲就到这里了。下一讲我将给你介绍“SLB 预热和压测的意义及方法”。到时见!
源码地址:
https://github.com/lagoueduCol/MiaoSha-Yiletian/blob/main/cmd/bench.go