NeRF神经辐射场学习笔记(三)——Point-NeRF论文解读
声明
本人书写本系列博客目的是为了记录我学习三维重建领域相关知识的过程和心得,不涉及任何商业意图,欢迎互相交流,批评指正。
论文概述
Point-NeRF结合了NeRF利用体素渲染合成高质量视图的方法,以及MVS中通过卷积神经网络快速重建场景的思路,先通过MVSNet得到初始神经点云场景,然后利用神经3D点云和神经特征来构建一个基于Point的辐射场,来渲染场景;在速度上面,其重建的时间要比NeRF提高了30倍。
Point-NeRF Representation
传统NeRF的体素渲染和辐射场方法

基于物理的体素渲染可以通过沿着可微光线(differentiable ray matching)计算来预测结果,即一个像素的渲染结果(颜色和不透明度)可以通过以下公式来计算:
c = ∑ M τ j ( 1 − e x p ( − σ j Δ j ) ) r j τ j = e x p ( − ∑ t = 1 j − 1 σ t Δ t ) c =\sum_M \tau_j (1-exp(-\sigma_j \Delta_j))r_j \\ \tau_j = exp(-\sum^{j-1}_{t=1}\sigma_t\Delta_t) c=M∑τj(1−exp(−σjΔj))rjτj=exp(−t=1∑j−1σtΔt)其中 τ \tau τ表示体积透过率(volume transmittance), σ j \sigma_j σj和 r j r_j rj分别表示射线上每个点 x j x_j xj的体密度(不透明度)和颜色(辐射度), Δ \Delta Δ表示相邻采样点的距离差;
一个辐射场的作用是利用每个点的3D坐标和方向信息来表示该点的不透明度 σ \sigma σ和颜色 r r r,而NeRF则是用一个MLP网络结构来回归这种辐射场;本文则提出了新的观点,利用Point-NeRF——使用神经点云(a neural point cloud)来计算体积要素,使得拥有更快、更高质量的渲染结果。
基于Point的辐射场方法
首先定义一个点云: P = ( p i , f i , γ i ) ∣ i = 1 , … , N P={(p_i, f_i, \gamma_i)|i=1,\dots, N} P=(pi,fi,γi)∣i=1,…,N,其中每个点 i i i位于 p i p_i pi处,并且与编码了局部场景信息的神经特征向量 f i f_i fi(a neural feature vector that encodes the local scene content)相关联。并且为每个点配置了一个尺度置信值 γ i ∈ [ 0 , 1 ] \gamma_i\in [0,1] γi∈[0,1](a scale confidence value),用来表示一个点有多大的可能性位于实际的场景表面。而文章就将要利用该点云来回归一个辐射场;
给定任意的3D位置x,查询其周围在一定半径R内的K个邻近神经点;基于Point的辐射场可以抽象为一个神经模块(a neural module)——任意点沿任意方向从邻近点回归出的体密度 σ \sigma σ和基于视觉的辐射度 r r r: ( σ , r ) = Point-NeRF ( x , d , p 1 , f 1 , γ 1 , … , p K , f K , γ K ) (\sigma, r)=\text{Point-NeRF}(x, d, p_1,f_1,\gamma_1,\dots, p_K,f_K,\gamma_K) (σ,r)=Point-NeRF(x,d,p1,f1,γ1,…,pK,fK,γK)
文章采用了类似于PointNet的,拥有多个子MLP的神经网络来做回归,即首先对每个神经点进行处理,然后将多点信息进行聚合,得到最终的预测值。具体网络结构如图所示:
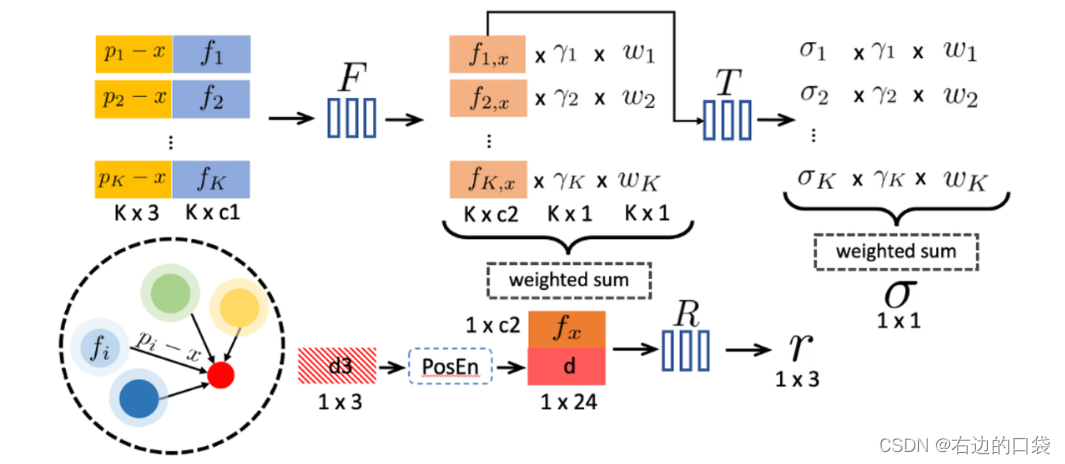
1.逐点处理(Per-point processing)
文章用一个MLP F F F来处理每个邻近的神经电,用以预测 x x x处的一个新的特征向量:
f i , x = F ( f i , x − p i ) f_{i,x}=F(f_i,x-p_i) fi,x=F(fi,x−pi)本质上来讲,原始特征 f i f_i fi围绕 p i p_i pi对局部3D场景内容进行编码,该MLP网络表示一个局部3D函数,该函数在 x x x处输出特定的神经场景描述(the specific neural scene description) f i , x f_{i,x} fi,x,该描述由其局部帧中的神经点建模。 相对位置 x − p x-p x−p的使用令网络不变量对点的平移具有更好的泛化作用。
2.基于视觉的辐射度回归(View-dependent radiance regression)
首先利用标准的逆距离加权(standard inverse distance weighting)来聚合从 F F F中回归得到的 f i , x f_{i,x} fi,x,以此来得到一个用来描述x处场景表示的简单特征值 f x f_x fx: f x = ∑ i γ i w i ∑ w i f i , x , 其中 w i = 1 ∣ ∣ p i − x ∣ ∣ f_x=\sum_i \gamma_i \frac{w_i}{\sum w_i}f_{i,x}, \text{其中}w_i=\frac{1}{||p_i-x||} fx=i∑γi∑wiwifi,x,其中wi=∣∣pi−x∣∣1紧接着,定义一个MLP R R R,用来从给定观测方向d回归r: r = R ( f x , d ) r=R(f_x, d) r=R(fx,d)逆距离加权被广泛应用于稀疏数据的插值,文章使用它来聚合神经特征,使得更近的神经点为渲染计算贡献更多;
3.体密度回归(Density regression)
同理,运用逆距离加权方式和定义的MLP T T T来计算 σ \sigma σ:
σ i = T ( f i , x ) σ = ∑ i σ i γ i w i ∑ w i , w i = 1 ∣ ∣ p i − x ∣ ∣ \sigma_i=T(f_{i,x}) \\ \sigma = \sum_i\sigma_i\gamma_i\frac{w_i}{\sum w_i},w_i=\frac{1}{||p_i-x||} σi=T(fi,x)σ=i∑σiγi∑wiwi,wi=∣∣pi−x∣∣1如此一来,每个神经点直接对体密度作出贡献,置信度也显式地与贡献关联,这一点在后续的除点操作中很有用。
Point-NeRF Reconstruction
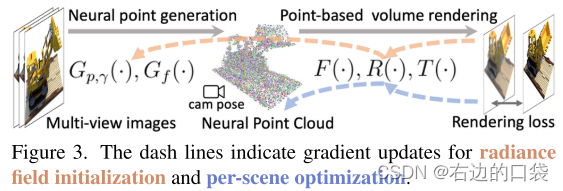
具体的基于Point-NeRF三维重建分为两大步骤:生成初始神经点云和基于Point的体素渲染逐帧优化;其主要的思路就是先利用MVSNet方法快速得到一个初始点云,然后在基于Point的辐射场上对点云进行进一步的渲染,而渲染的流程和理论分析在上一小节已经表明,但是来自外部重建方法所得到的初始点云通常会包含降低渲染质量的空洞河离群点,所以作者又提出了两种能够提升渲染效果和质量的方法;
生成基于Point的初始辐射场(Generating initial point-based radiance fields)
1.获取点的位置与置信度
对于位于点q的带有相机参数 Φ q \Phi_q Φq的输入图像 I q I_q Iq,文章中运用MVSNet网络的多步操作处理得到了每个视角q下的点云 { p 1 , … , p N q } \{p_1,\dots,p_{N_q}\} {p1,…,pNq},以及位于每个点 p i p_i pi的置信度 γ i \gamma_i γi: { p i , γ i } = G p , γ ( I q , Φ q , I q 1 , Φ q 1 , I q 2 , Φ q 2 , … ) \{p_i,\gamma_i\}=G_{p,\gamma}(I_{q},\Phi_{q},I_{q_1},\Phi_{q_1},I_{q_2},\Phi_{q_2},\dots) {pi,γi}=Gp,γ(Iq,Φq,Iq1,Φq1,Iq2,Φq2,…)其中 G p , γ G_{p,\gamma} Gp,γ是基于MVSNet网络的, I q n I_{q_n} Iqn和 Φ q n \Phi_{q_n} Φqn是MVS重建过程中使用的图片的邻域帧,一般两个就足够。
we follow MVSNet to first build a plane-swept cost volume by warping 2D image features from neighboring viewpoints and then regress depth probability volume using deep 3D CNNs. A depth map is computed by linearly combining per-plane depth values weighted by the probabilities. We unprojected the depth map to 3D space to get a point cloud { p 1 , … , p N q } \{p_1,\dots,p_{N_q}\} {p1,…,pNq} per view q q q.
Since the depth probabilities describe the likelihood of the point being on the surface, we tri-linearly sample the depth probability volume to obtain the point confidence γ i \gamma_i γi at each point p i p_i pi.
2.获取点的特征信息
文章采用带有3个下采样层的VGG网络 G f G_f Gf来从每个图像 I q I_q Iq中提取特征图: { f i } = G f ( I q ) \{f_i\}=G_f(I_q) {fi}=Gf(Iq)
优化基于Point体素渲染效果的两种方法(Optimizing point-based radiance fields)
1.Point pruning
点置信度 γ i \gamma_i γi表明了神经点是否靠近场景表面,所以文章利用这些置信度来prune不必要的离群值;根据体密度回归的公式定义以及逆距离加权的运用使得神经点的距离与渲染计算贡献相关联,故低置信度反映了一个点的局部区域的低体密度,即表明它是空的。 因此,每10k次迭代就prune γ i < 0.1 \gamma_i <0.1 γi<0.1的点。下图为有无Point pruning和Point growing两种方法所带来的效果展示:

同时文章还用置信度定义了一种稀疏损失函数,该损失函数会在优化的过程中强制置信度值接近0或1: L s p a r s e = 1 γ ∑ γ i [ l o g ( γ i ) + l o g ( 1 − γ i ) ] \mathcal{L}_{sparse}=\frac{1}{\gamma}\sum_{\gamma_i}[log(\gamma_i)+log(1-\gamma_i)] Lsparse=γ1γi∑[log(γi)+log(1−γi)]
2.Point growing
该方法是用来生成新的点来覆盖原始点云中缺失的场景,即在射线采样的过程中利用NeRF所提出的公式来识别不透明度最高的点 x j g x_{j_g} xjg,(其中 α j = 1 − e x p ( − σ j Δ j ) , j g = arg max j α j \alpha_j=1-exp(-\sigma_j\Delta_j),j_g=\argmax_j \alpha_j αj=1−exp(−σjΔj),jg=argmaxjαj),如果 α j g > T o p a c i t y \alpha_{j_g}>T_{opacity} αjg>Topacity并且 ϵ j g > T d i s t \epsilon_{j_g}>T_{dist} ϵjg>Tdist( ϵ j g \epsilon_{j_g} ϵjg是 x j g x_{j_g} xjg到其最近的神经点的距离),则grow一个新的神经点,这意味着该位置位于表面附近,但远离其他神经点。通过重复这种grow策略,我们的辐射场可以扩展到覆盖初始点云中缺失的区域。下图表明即使在只有1000个初始点的极端情况下,该grow技术也能够逐步生成新的点并合理地覆盖物体表面:

损失函数定义
L o p t = L r e n d e r + a L s p a r s e \mathcal{L}_{opt}=\mathcal{L}_{render}+a\mathcal{L}_{sparse} Lopt=Lrender+aLsparse其中 L r e n d e r \mathcal{L}_{render} Lrender是渲染过程中的损失函数, a a a取 2 e − 3 2e^{-3} 2e−3。
参考文献和资料
[1]:【论文精读】Point-NeRF:Point-based Neural Radiance Fields
[2]:论文阅读笔记—CVPR2022—Point-NeRF
[3]:Point-NeRF: Point-based Neural Radiance Fields