具体的学习资料可以参考王喆老师的《深度学习推荐系统》,已经梳理好了知识体系,我也将按照这个路线再次梳理一遍,同时做一些拓展和加深理解
一、前言
系统过滤曾是多年前推荐系统领域的应用最广泛的模型,也是基石一样的存在,重要!重要!
这里推出两篇论文,我们将简单看下论文,并进行代码复现 ,这里主要讲两部分
(1)基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
(2)基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
2001年 Item-Based Collaborative Filtering Recommendation Algorithms
2003年 Amazon.com Recommendations Item-to-Item Collaborative Filtering
二、协同过滤
1、什么是协同过滤
就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息这样一个推荐过程
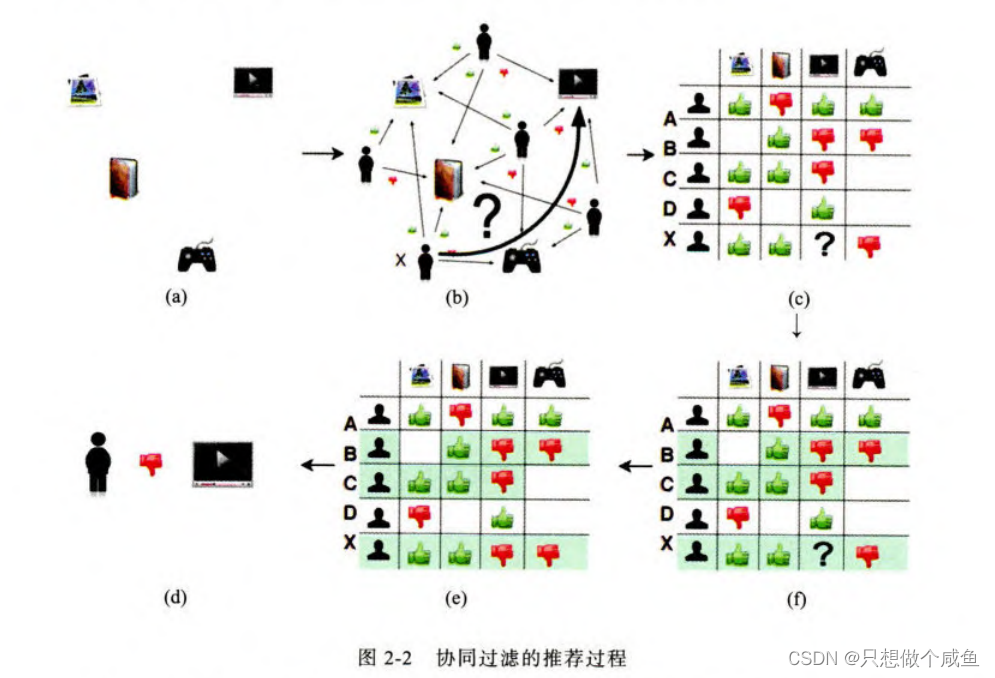
简而言之,我们要判断目标用户是否喜欢某物品,就是将所有用户交互的物品,生成共现矩阵(这里就是指用户对于物品的评分,存成矩阵方便后面的计算),然后通过找到相似用户(或相似物品),看相似用户的评价,进而估计出目标用户的评价
2、用户的相似度计算
计算相似度需要根据特点的不同选择不同的相似度计算方法, 比较常用的有下面几种,
(1)余弦相似度
余弦相似度( Cosine Similarity ) 衡量 了用户向量i和用户向量J之间的向量夹角大小。显然,夹角越小,证明余弦相似 度越大,两个用户越相似。
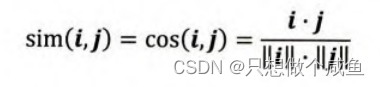
对于某些用户喜欢普遍低分或者普遍打高分,所以对于这种用户评分偏置的情况, 余弦相似度就不是那么好了, 可以考虑使用下面的皮尔逊相关系数。
(2)皮尔逊相关系数
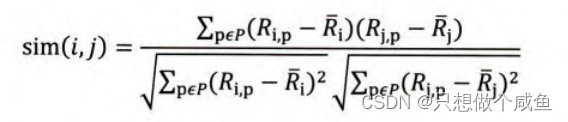
(3)物品平均分的方式
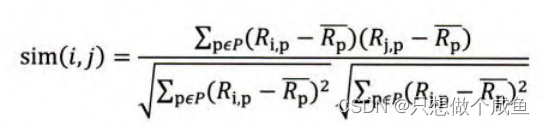
3、最终的结果排序
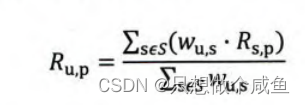
(2)还有一种方式如下, 而是该物品的评分与此用户的所有评分的差值进行加权平均, 这时候考虑到了有的用户内心的评分标准不一的情况, 即有的用户喜欢打高分, 有的用户喜欢打低分的情况。
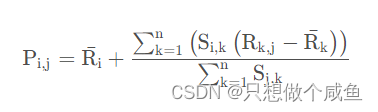
至此, 基于用户的协同过滤算法的推荐过程完成。
三、算法实现
1、userCF概念
1.1 UserCF代码实现
(1)数据集加载
依次对应用户ID、物品ID、评分、时间戳
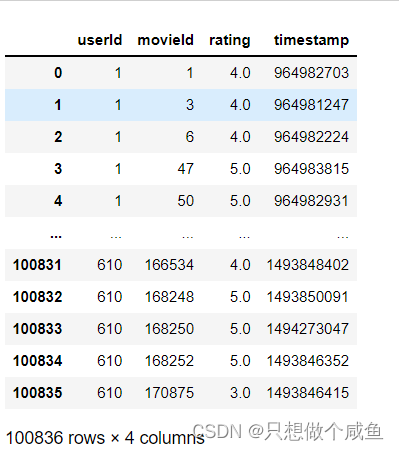
划分训练集和测试集
# 声明两个字典, 分别是训练集和测试集
trainSet, testSet = {}, {}
trainSet_len, testSet_len = 0, 0
pivot = 0.75 # 训练集的比例
# 遍历data的每一行, 把userId, movidId, rating按照{user: {movidId: rating}}的方式存储, 当然定义一个随机种子进行数据集划分
for ele in data.itertuples(): # 遍历行这里推荐用itertuples, 比iterrows会高效很多
user, movie, rating = getattr(ele, 'userId'), getattr(ele, 'movieId'), getattr(ele, 'rating')
if random.random() < pivot:
trainSet.setdefault(user, {})
trainSet[user][movie] = rating
trainSet_len += 1
else:
testSet.setdefault(user, {})
testSet[user][movie] = rating
testSet_len += 1例如:将用户1所交互的物品随机分3:1 Split trainingSet and testSet success! TrainSet = 75657 TestSet = 25179
(2)计算用户间的相似度
user_sim_matrix = {}
# 构建“电影-用户”倒排索引 # key = movidID, value=list of userIDs who have seen this move
print('Building movie-user table ...')
movie_user = {}
for user, movies in trainSet.items(): # 这里的user就是每个用户, movies还是个字典, {movieID: rating}
for movie in movies: # 这里的movie就是movieID了
if movie not in movie_user: # 如果movidID没在倒排索引里面
movie_user[movie] = set() # 声明这个键的值是set, 保证用户不重复
movie_user[movie].add(user) # 把用户加进去,
print('Build movie-user table success!')
# 下面建立用户相似矩阵
movie_count = len(movie_user)
print('Total movie number = %d' % movie_count)
print('Build user co-rated users matrix ...')
for movie, users in movie_user.items(): # movid是movieID, users是set集合
for u in users: # 对于每个用户, 都得双层遍历
for v in users:
if u == v:
continue
user_sim_matrix.setdefault(u, {}) # 把字典的值设置为字典的形式
user_sim_matrix[u].setdefault(v, 0)
user_sim_matrix[u][v] += 1 # 这里统计两个用户对同一部电影产生行为的次数, 这个就是余弦相似度的分子
print('Build user co-rated users matrix success!')
# 下面计算用户之间的相似性
print('Calculating user similarity matrix ...')
for u, related_users in user_sim_matrix.items():
for v, count in related_users.items(): # 这里面v是相关用户, count是共同对同一部电影打分的次数
user_sim_matrix[u][v] = count / math.sqrt(len(trainSet[u]) * len(trainSet[v])) # len 后面的就是用户对电影产生过行为的个数
print('Calculate user similarity matrix success!')Building movie-user table ... Build movie-user table success! Total movie number = 8765 Build user co-rated movies matrix ... Build user co-rated movies matrix success! Calculating user similarity matrix ... Calculate user similarity matrix success!
(3)产生推荐
# 找到最相似的20个用户, 产生10个推荐
k = 20
n = 10
aim_user = 3 # 目标用户ID
rank ={}
watched_movies = trainSet[aim_user] # 找出目标用户看到电影
# 下面从相似性矩阵中找到与aim_user最相近的K个用户
# v 表示相似用户, wuv表示相似程度
for v, wuv in sorted(user_sim_matrix[aim_user].items(), key=lambda x: x[1], reverse=True)[0:k]: # 字典按值从大到小排序, 相关性高到第
# 把v用户看过的电影推荐给目标用户
for movie in trainSet[v]:
if movie in watched_movies:
continue
rank.setdefault(movie, 0)
rank[movie] += wuv
# 产生最后的推荐列表
rec_movies = sorted(rank.items(), key=itemgetter(1), reverse=True)[:n] # itemgetter(1) 是简洁写法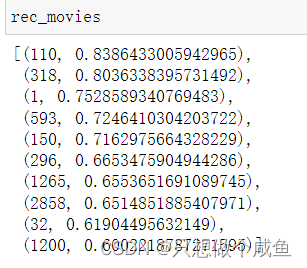
(4)评价指标
# 准确率、召回率和覆盖率
hit = 0
rec_count = 0 # 统计推荐的影片数量, 计算查准率
test_count = 0 # 统计测试集的影片数量, 计算查全率
all_rec_movies = set() # 统计被推荐出来的影片个数, 无重复了, 为了计算覆盖率
item_populatity = dict() # 计算新颖度
# 先计算每部影片的流行程度
for user, items in trainSet.items():
for item in items.keys():
if item not in item_populatity:
item_populatity[item] = 0
item_populatity[item] += 1 # 这里统计训练集中每部影片用户观看的总次数, 代表每部影片的流行程度
# 计算评测指标
ret = 0
ret_cou = 0
for user, items in trainSet.items(): # 这里得保证测试集里面的用户在训练集里面才能推荐
test_movies = testSet.get(user, {})
rec_movies = recommend(user)
for movie, w in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
ret += math.log(1+item_populatity[movie])
ret_cou += 1
rec_count += n
test_count += len(test_movies)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / movie_count
ret /= ret_cou*1.0
print('precisioin = %.4f\nrecall = %.4f\ncoverage = %.4f\npopularity = %.4f' % (precision, recall, coverage, ret))
四、总结
协同过滤的头部效应较为明显、泛化能力较弱
所以后续被加以改进,提出矩阵分解在系统过滤的基础上加入隐向量的概念,加强模型处理稀疏矩阵的能力,后续将会出矩阵分解(MF)的论文及复现代码