1.搜寻时使用大括号设定比对次数
正则表达式——2.正则表达式的基础_笨小古的博客-CSDN博客中已使用过大括号,大括号的数字设定的是重复次数。
将这个概念应用在搜寻一般字符串,例如,(son){3}代表所搜寻的字符串是'sonsonson',如果有一字符串是'sonson',则搜寻结果是不符。大括号除了可以设定重复次数,也可以设定指定范围,例如,(son){3, 5}代表所搜寻的字符串如果是'sonsonson' 'sonsonsonson'或'sonsonsonsonsonson'都算是相符合的字符串。(son){3, 5}正则表达式相当于下列表达式:
((son)(son)(son)) | ((son)(son)(son)(son)) | ((son)(son)(son)(son)(son)(son))
设定搜寻son字符串重复3~5次皆算搜寻成功。
# 贪婪与非贪婪搜寻
import re
def searchStr(pattern, msg):
txt = re.search(pattern, msg)
if txt == None: # 搜寻失败
print("搜寻失败", txt)
else:
print("搜寻成功", txt.group())
msg1 = 'son'
msg2 = 'sonson'
msg3 = 'sonsonson'
msg4 = 'sonsonsonson'
msg5 = 'sonsonsonsonson'
pattern = '(son){3,5}'
searchStr(pattern, msg1)
searchStr(pattern, msg2)
searchStr(pattern, msg3)
searchStr(pattern, msg4)
searchStr(pattern, msg5)
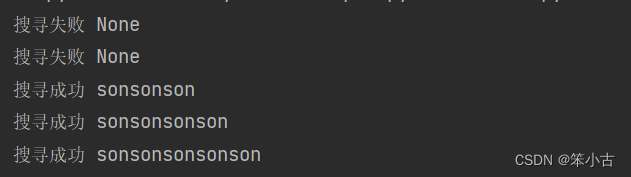
使用大括号时,也可以省略第一或第二个数字,这相当于不设定最小或最大重复次数。例如:(son){3,}代表重复3次以上皆符合,(son){10,}代表重复10次以下皆符合。
2.贪婪与非贪婪搜寻
在讲解贪婪与非贪婪搜寻前,先简化上例,使用相同的搜寻模式'(son){3,5})' ,搜寻字符串是'sonsonsonsonson'。
# 贪婪与非贪婪搜寻
import re
def searchStr(pattern, msg):
txt = re.search(pattern, msg)
if txt == None: # 搜寻失败
print("搜寻失败", txt)
else:
print("搜寻成功", txt.group())
msg = 'sonsonsonsonson'
pattern = '(son){3,5}'
searchStr(pattern, msg)
结果:
![]()
其实由上述程序所设定的搜寻模式可知3、4、5个son重复就算找到了,但是在Python里面执行结果是列出了最多重复的字符串,5次重复,这是Python的默认模式,这种模式又称贪婪(greedy)模式。
另一种是列出最少重复的字符串,以这个实例而言是重复3次,这称为贪婪模式,方法是在正则表达式的搜寻模式右边增加问号。
以非贪婪模式设计以上程序。
# 与上例代码不同的是
pattern = '(son){3,5}?' 
3.特殊字符表
| 字符 | 使用说明 |
| \d | 0~9的整数字元 |
| \D | 除了0~9的整数字元以外的其他字符 |
| \s | 空白、定位、Tab键、换行、换页字符 |
| \S | 除了空白、定位、Tab键、换行、换页字符以外的字符 |
| \w | 数字、字母和下划线_字符,[A-Za-z0-9_] |
| \W | 除了数字、字母和下划线_字符,[A-Za-z0-9_]以外的其他字符 |
下面用实例说明上述表格概念的正则表达式的使用。
将一段英文句子的单词分离,同时将英文单词前4个字母是"John"的单词筛选出来。
pattern = '\w+' # 意见是把不限长度的数字、字母和下划线当作符合搜寻
pattern = 'John\w' # John开头后面接0~多个数字、字母和下划线字符import re
# 测试1将字符串从句子分离
msg1 = 'John, Johnson, Johnnason and Johnnathan will attend my party tonight.'
pattern1 = '\w+' # 不限字符的单字
txt1 = re.findall(pattern1, msg1) # 回传搜寻的结果
print(txt1)
# 测试2将John开始的字符串分离
msg2 = 'John, Johnson, Johnnason and Johnnathan will attend my party tonight.'
pattern2 = 'John\w' # John开头的单词
txt2 = re.findall(pattern2, msg2)
print(txt2)

继续展示正则表达式的应用,下列程序重点是第5行。
\d+: 表示不限长度的数字。
\s: 表示空格。
\w+: 表示不限长度的数字、字母和下划线字符连续字符。import re
msg = '1 cat, 2 dogs, 3 pigs, 4 swans'
pattern = '\d+\s\w+'
txt = re.findall(pattern, msg)
print(txt)
4.字符分类
Python可以使用中括号来设定字符,可参考下列实例。
[a-z]: 代表a~z的小写字符。
[A~Z]: 代表A~Z的大写字符。
[aeiouAEIOU]: 代表英文发音的元音字符。
[2-5]: 代表2~5的数字。
在字符分类中,中括号内可以不同放上正则表示法的发斜杠\执行 .、?、*、(、)等字符的转译。例如,[2-5.]会搜寻2~5的数字和句点,这个语法不用写成[2-5\.]。
下面看一个搜寻字符的应用实例,首先将搜寻[aeiouAEIOU],然后将搜寻[2-5.]。
import re
# 测试1搜寻[aeiouAEIOU]
msg1 = 'John, Johnson, Johnnason and Johnnathan will attend my party tonight.'
pattern1 = '[aeiouAEIOU]'
txt1 = re.findall(pattern1, msg1)
print(txt1)
# 测试2搜寻[2-5.]字符
msg2 = '1. cat, 2. dogs, 3. pigs, 4. swans'
pattern2 = '[2-5.]'
txt2 = re.findall(pattern2, msg2)
print(txt2)

5.所有字符使用通配符“.*”
字符" . " 与 " * "组合,可以搜寻所有的字符,意义是搜寻0到多个通配符(换行字符除外)。
搜寻所有字符" .* "的组合应用。
import re
msg = 'Name: Jiin-Kweo Hung Address: 8F, Nan-Jing E, Rd, Taipei'
pattern = 'Name: (.*) Address: (.*)'
txt = re.search(pattern, msg)
Name, Address = txt.groups()
print("Name: ", Name)
print("Address: ", Address)

6.换行字符的处理
使用知识点5中的概念用" .* " 搜寻时碰上换行字符,搜寻就会停止。Python的re模块提供参数re.DOTALL,功能时包括搜寻换行字符,可以将参数放在search()、findall()或compile()。
实例6:测试1是搜寻除换行符以外的字符,测试2是搜寻含换行字符的所有字符。由于测试2包含换行字符,所以输出时,换行字符主导2行输出。
import re
# 测试1搜寻除换行字符以外的字符
msg1 = 'Name: Jiin-Kweo Hung \nAddress: 8F, Nan-Jing E, Rd, Taipei'
pattern1 = '.*'
txt1 = re.search(pattern1, msg1)
print("测试1输出:", txt1.group())
# 测试2搜寻包括换行字符
msg2 = 'Name: Jiin-Kweo Hung Address: 8F, Nan-Jing E, Rd, Taipei'
pattern2 = '.*'
txt2 = re.search(pattern2, msg2, re.DOTALL)
print("测试2输出:", txt2.group())

另外还有:
字符分类的^字符;(在中括号内的左方加上^字符,是指搜寻不在这些字符内的所有字符)
正则表示法的^字符;(与字符分类的^字符完全相同但是用法不同:在起始位置加上^字符,表示正则表示法的字符串必须出现在被搜寻字符串的起始位置,这样搜寻成功才算成功)
正则表示法的$字符;(正则表示法的末端放置$字符时,表示正则表示法的字符串必须出现在被搜寻字符串的最后位置,这样搜寻成功才算成功)
单一字符使用通配符".";(通配符" . "表示可以搜寻除了换行字符以外的所有字符,但是只限定一个字符)