目录
一、前言
集成算法(Enseamable learning)
集成算法一般考虑树模型,KNN就不太适合
目的:让机器学习效果更好,单个不好,一起干,三个诸葛亮
Bagging:训练多个分类器取平均,,其中
表示分类器的个数,
表示单个训练器。
Boosting:从弱学习器开始加强,通过加权的方式来进行训练
公式:
可以看出这种方法的最终结果是在上个结果的基础上加上一个补充值(个人理解)
表示在上个结果加上此次补充后结果的损失函数,看是否让其变小了。
Stacking:聚合多个分类或者回归模型(可以分阶段来做);堆叠算法
二、Bagging模型
全称:Boostrap aggregation
其实就是并行训练一堆分类器
最典型代表就是随机森林
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起了

上图就可以很直观的表示出,并行的概念了。
其中最难的就是随机这个概念,大家想一想如果树模型是一样的,输入数据一样,那么结果也是一样的,这样随机森林做出来就没得啥子意义了。要让它们不一样,模型不能改变,就只能从数据入手了。
要数据采样随机,特征选择随机。意思是第一个模型只用数据样本的70%,特征也只用70%,第二个模型只用数据样本的70%,特征也只用70%,第三个,第四个......。要保证这二重随机性(个人自创),大家可以想想,可以把这两个随机性,当作随机森林参数。之所以要保证随机性是要保证模型的泛化能力。

随机森林的优势:
可解释性强,它内部的情况是可以看见的包括走势,中间结果,相当于软件测试中的白盒测试,而深度学习神经网络就相当于黑盒,不可以看见。
它能够处理很高维度(feature)的数据,并且不用做特征选择
在训练完后,它可以给出哪些feature比较重要
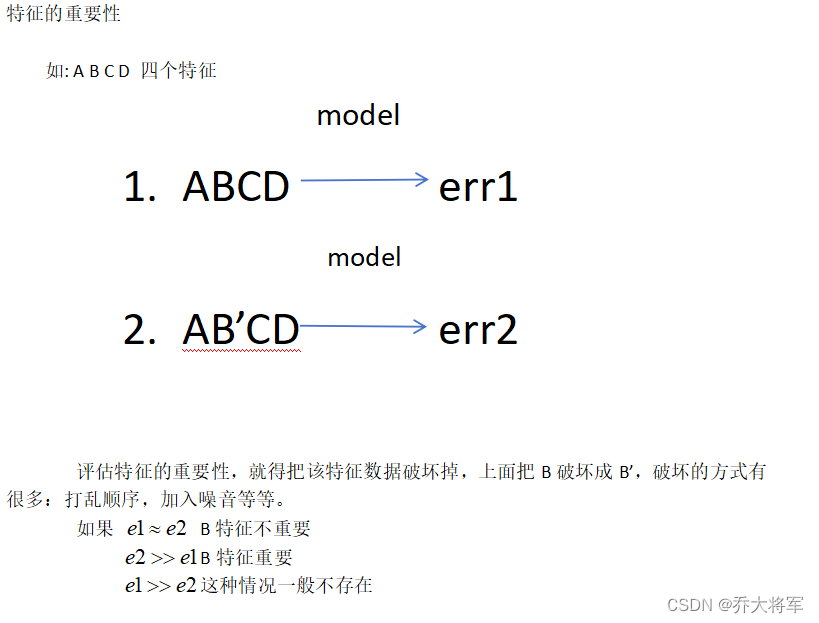
理论上越多的树效果会越好,但实际上树超过一定的数量就差不多上下浮动了。

三、Boosting模型
典型代表:AdaBoost,Xgboost
AdaBoost会根据前一次的分类效果调整数据权重
解释:如果某一个数据在这次分错了,那么在下一次就会给它更大的权重(调整权重)

最终的结果:每个分类器根据自身的准确性来确定各自的权重,在合体
AdaBoost工作流程:

四、Stacking模型
堆叠模型:很暴力,拿来一堆直接上(各种分类器都有)
可以堆叠各种各样的分类器(KNN,SVM,RF等)
分阶段:第一阶段得出各自的结果,第二阶段再用前一阶段的结果训练
为了刷结果,不择手段!!!

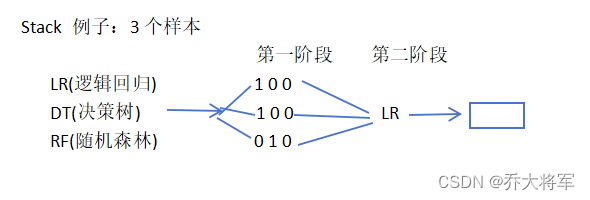
堆叠在一起确实能够使得准确率提升,但是速度是个问题,所以用的不是很多,竞赛可以试试。
五、总结
集成算法是论文与竞赛神器,当我们更关注于结果时不妨试试!!!!