线性表顺序存储结构的优缺点
优点:1.无须为表示表中元素之间的逻辑关系而增加额外的存储空间
2.可以快速的存取表中的任一位置的元素
缺点:1.插入和删除操作需要移动大量的元素
2.当线性表长度变化较大的时候,难以确定存储空间的容量
3.造成存储空间的"碎片"
所以我们有了另外一种线性表的存储结构——链式存储结构
链式存储结构

我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域,指针域中存储的信息称作指针或链.这两部分信息组成数据元素ai的存储映像,称为结点(Node)
链表中只含有一个指针域,所以叫做单链表
对于线性表来说,总得有头有尾,链表也不例外,所以我们把链表中的第一个节点的存储位置叫做头指针,整个链表的存取就必须从头指针开始了
而最后一个结点的指针域因为没有指向任何地方所以我们把其置为空,即(NULL)
有时候,我们为了更加方便的对链表进行操作,会在单链表的第一个结点前附设一个结点,成为头结点,头结点的数据域不存储任何数据
头指针与头结点的异同点
1.头指针是指链表指向第一个结点的指针,若链表有头结点,那头指针就是指向头结点的指针,而头结点是为了操作的统一和方便而设立的,其数据域一般无意义,也可以存放链表的长度
2.头指针具有标志作用,所以常用头指针冠以链表的名字
3.无论链表是否为空,头指针均不为空,头指针是链表的必要元素,但是头结点不是链表的必须要素
单链表的定义
typedef struct Node
{
ElemType data;
struct Node *next;
}Node;
typedef struct Node *LinkList;单链表的读取
Status GetElem(LinkList L,int i,ElemType *e)
{
int j;
LinkList p; //声明一结点p
p=L->next; //让p指向链表L的第一个结点
j=1; //j为计数器
while(p && j<i) //p不为空或者计数器j还没有等一i时,循环继续
{
p=p->next; //让p指向下一个结点
++j;
}
if(!p || j>i)
return ERROR; //第i个元素不存在
*e=p->data; //取第i个元素的数据
return OK;
}说白了就是从头开始找,直到第i个结点为止,因此最坏情况的时间复杂度为O(n)
单链表的插入
Status LinkInsert(LinkList *L,int i,ElemType e)
{
int j;
LinkList p,s;
p=*L;
j=1;
while(p && j<i) //寻找第i个结点
{
p=p->next;
++j;
}
if(!p || j>i)
return ERROR; //第i个元素不存在
s=(LinkList)malloc(sizeof(Node)); //生成新结点
s->data=e;
s->next=p->next; //将p的后继结点赋值给s的后继
p->next=s; //将s赋值给p的后继
return OK;
}单链表的删除
Status LinkDelete(LinkList *L,int i,ElemType *e)
{
int i;
LinkList p,q;
p=*L;
j=1;
while(p->next && j<i) //遍历寻找第i个元素
{
p=p->next;
++j;
}
if(!(p->next) || j>i)
return ERROR; //第i个元素不存在
q=p->next;
p->next=q->next; //将q的后继赋值给p的后继
*e=q->data; //将q结点中的数据给e
free(q); //让系统回收此结点,释放内存
return OK;
}对于插入或删除数据越频繁的操作,单链表的效率优势就越明显
单链表整表创建
头插法

void CreateListHead(LinkList *L,int n)
{
LinkList p;
int i;
srand(time(0)); //初始化随机数种子
*L=(LinkList)malloc(sizeof(Node));
(*L)->next=NULL; //先建立一个带头结点的单链表
for(i=0;i<n;i++)
{
p=(LinkList)malloc(sizeof(Node)); //生成新结点
p->data=rand()%100+1; //随机生成100以内的数字
p->next=(*L)->next;
(*L)->next=p; //插入到表头
}
}尾插法
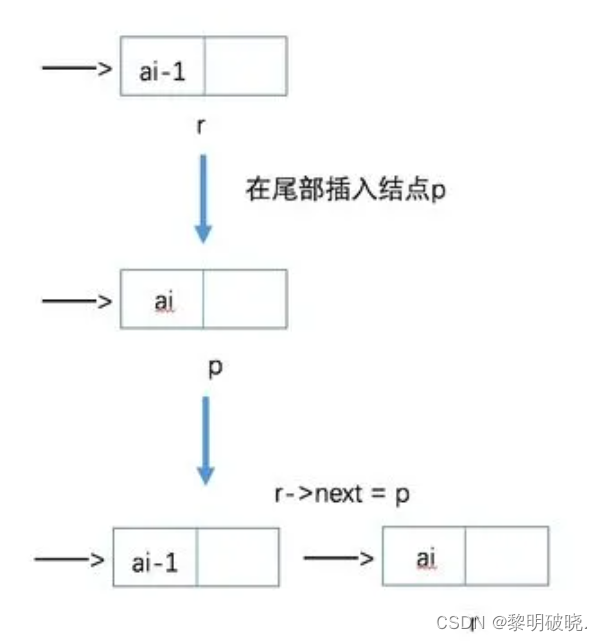
void CreateListTall(LinkList *L,int n)
{
LinkList p,r;
int i;
srand(time(0)); //初始化随机数种子
*L=(LinkList)malloc(sizeof(Node)); //L为整个线性表
r=*L; //r为指向尾部的结点
for(i=0;i<n;i++)
{
p=(Node*)malloc(sizeof(Node)); //生成新结点
p->data=rand()%100+1; //随机生成100以内的数字
r->next=p; //将表尾终端结点的指针指向新结点
r=p; //将当前新结点定义为表尾的终端结点
}
r->next=NULL; //表示当前链表结束
}