3DV
Two focus : predicting 3d shapes from image and processing 3d input data
Representations of 3D shape
Depth map
gives distance from the camera to the object in the world at that pixel
RGB image + Depth image = RGB-D Image (2.5D)
We can use Fully Convolutional network to predict the depth
problem : Scale / Depth Ambiguity
-> Use Scale invariant loss
Surface Normals
give a vector giving normal vector to the object in the world for that pixel
We can use Fully Convolutional network to predict Surface Normals
loss: x y ∣ x ∣ ∣ y ∣ \frac{x y}{|x||y|} ∣x∣∣y∣xy
Also can’t represent the occluded objects
Voxel Grid
Represent a shape with a V × V × V V \times V \times V V×V×V grid of occupancies (just like minecraft 😃
Problems: Need high spatial resolution to capture fine structures, scaling to high resolutions in not trival
Use 3D convolution to do classification
We can have the following architecture :
image -> 2D CNN -> fully connected layer -> 3D CNN -> Voxels
but it’s expensive
we can use “Voxel Tubes”:
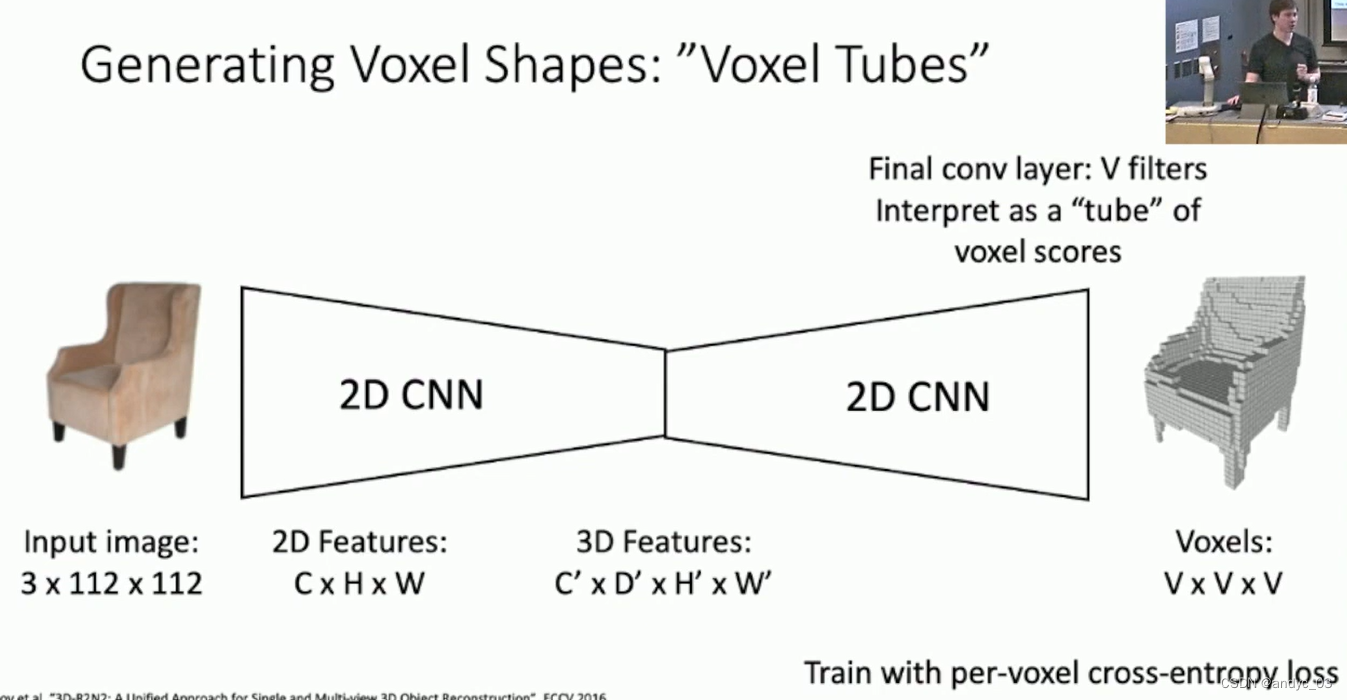
We have sacrifice the z-dim spatial information, and the memory usage of Voxel is not affordable.
Solution : Oct-Trees
use voxel grids with heterogenous resolution
Nested Shape Layers
Predict shape as a composition of positive and negative grids
Implicit Surface
learn a function o : R 3 → { 0 , 1 } o: \R^3 \rightarrow \{0,1\} o:R3→{0,1}
to classify arbitrary 3D points as inside / outside the shape
same idea: signed distance function gives Euclidean distance to the surface of the shape
Point Cloud
represent shape as a set of P points in 3D space
nice property: can represent fine structure without huge number of points
bad property: doesn’t explicitly represent the surface of the shape
PointNet
Input pointcloud --MLP on each points-> point features --max pooling -> pooled vector --FC-> class score
We want to process pointclouds as sets : order should not matter
Generating Pointcloud Outputs
Loss function (new):
Chamfer distance: sum of L2 distance to each point’s nearest neighbor in the other set
Mesh
Triangle Mesh
represent a 3D shape as a set of triangles
Vertices: Set of V points in 3D shape
Faces: Set of triangles over the vertices
We can attach data on verts and interpolate over the whole surface
However, nontrivial to process with neural nets
Pixel2Mesh
key ideas:
- iterative mesh refinement
Start from initial ellipsoid mesh
- Graph Convolution
input : Graph with a feature vector attached to every vertex of the graph
output : a new feature vector to every vertex
f i ′ = W 0 f i + ∑ j ∈ N ( i ) W 1 f j f_i' = W_0f_i + \sum_{j \in N(i)} W_1f_j fi′=W0fi+∑j∈N(i)W1fj
- Vertex-Aligned Features
For each vertex of the mesh : use camera information to project onto image plane
use bilinear interpolation to sample a CNN feature
- Loss function
Invert meshes to pointclouds then compute loss -> avoid different representation of same graphs causing different loss
Metrics
Chamfer distance on pointclouds
sensitive to outliers
F1 score on pointclouds
Precision @t = fraction of predicted points within t of some groud-truth point
Recall @t = fraction of groud-truth points within t of some predicted ponit
F 1 @ t = 2 P r e c i s i o n @ t ∗ R e c a l l @ t P r e c i s i o n @ t + R e c a l l @ t F1@t = 2\frac{Precision @t * Recall @t}{Precision @t + Recall @t} F1@t=2Precision@t+Recall@tPrecision@t∗Recall@t
Cameras: Canonical vs View Coordinates
Problem : Canonical views overfits more often
Dataset
ShapeNet: synthetic, no context
Pix3D: Real image but small
Mesh R-CNN
Mesh deformation gives good results but the topology is fixed by the initial mesh
Approach: Use voxel predictions to create initial mesh prediction
help predict things with holes
add L2 norm as well
Amodal completion: predict occluded parts of the objects