探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(二)
RoPE(旋转位置编码)
在深入研究 RoPE 之前,了解绝对位置编码和相对编码之间的区别非常重要。
绝对位置编码是添加到标记嵌入中以表示其在句子中的绝对位置的固定向量。因此,它一次处理一个标记。可以将其视为地图上的对(纬度、经度):地球上的每个点都有一个唯一的对。
另一方面,相对位置编码一次处理两个标记,在计算注意力时涉及到:由于注意力机制捕获了两个单词彼此相关的“强度”,因此相对位置编码告诉我们注意机制涉及其中的单词之间的距离。因此,给定两个标记,创建一个表示它们距离的向量。
旋转位置编码可以被认为是绝对位置嵌入和相对位置嵌入之间的中间地带,因为每个标记确实具有固定或绝对嵌入值,并与其极坐标形式(相对于向量的旋转)乘以内部点积在二维平面上。
注意力机制中使用的点积是内积的一种,可以通过作为点积的推广。
能否找到注意力机制中使用的两个向量q(查询)和k (键)的内积,该内积仅取决于这两个向量以及它们所代表的标记的相对距离?

可以定义一个如下所示的函数g,它仅取决于两个嵌入向量q和k以及它们的相对距离。
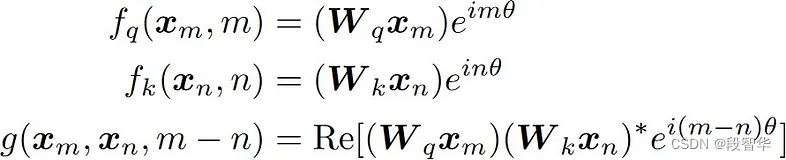
利用欧拉公式, 可以将其写成矩阵形式。
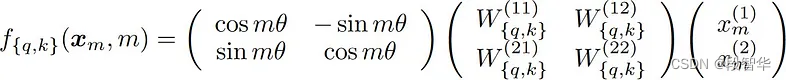
二维空间中的旋转矩阵,因此称为旋转位置嵌入
旋转位置嵌入仅应用于查询和键,而不应用于值。
在注意力机制中,旋转位置嵌入是在向量q和k乘以W矩阵之后应用的,而在普通Transformer中,它们是在之前应用的。
def precomputed_theta_pos_frequencies(head_dim: int, seq_len: int, device: str, theta: float = 10000.0):
# As written in the paper, the dimentions o the embedding must be even
assert head_dim % 2 == 0, "The head_dim must be even"
# Built the theta parameters
# According to the formula theta_i = 10000 ^ (-2(i-1)/dim) for i = [1,2,3,..dim/2]
# Shape: (head_dim / 2)
theta_numerator = torch.arange(0, head_dim, 2).float()
# Shape : (head_dim / 2)
theta = 1.0 / (theta ** (theta_numerator / head_dim)).to(device)
# Construct the positions (the "m" parameter)
# shape: (seq_len)
m = torch.arange(seq_len, device=device)
# multiply each theta by each position using the outer product
# shape : (seq_len) outer_product * (head_dim / 2) -> (seq_len, head_dim / 2)
freq = torch.outer(m, theta).float()
# we can computer complex numbers in the polar form c = R * exp(i * m * theta), where R = 1 as follow
# shape: (seq_len, head_dim/2) -> (seq-len, head_dim/2)
freq_complex = torch.polar(torch.ones_like(freq), freq)
return freq_complex
def apply_rotary_embeddings(x: torch.Tensor, freq_complex: torch.Tensor, device: str):
# We transform the each subsequent pair of tokens into a pair of complex numbers
# shape : (B, seq_len, head_dim) -> (B, seq_len, h, head_dim / 2)
x_complex = torch.view_as_complex(x.float().reshape(*x.shape[:-1], -1, 2))
# shape : (seq_len, head_dim / 2) -> (1, seq_len, 1, head_dim / 2)
freq_complex = freq_complex.unsqueeze(0).unsqueeze(2)
# shape : (B, seq_len, h, head_dim / 2) * (1, seq_len, 1, head_dim / 2) = (B, seq_len, h, head_dim / 2)
x_rotate = x_complex * freq_complex
# (B, seq_len, h, head_dim / 2) -> (B, seq_len, h, head_dim/2 ,2)
x_out = torch.view_as_real(x_rotate)
# (B, seq_len, h, head_dim/2, 2) -> (B, seq_len, h * head_dim / 2 * 2)
x_out = x_out.reshape(*x.shape)
return x_out.type_as(x).to(device)
系列博客
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(一)
https://duanzhihua.blog.csdn.net/article/details/138208650

