目录
spark SQL语言:
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。使用Spark SQL有两种方式,包括SQL语句以及Dataset API。Spark SQL的一个主要的功能就是执行SQL查询语句。Spark SQL也可以用来从Hive中查询数据。当我们使用某种编程语言开发的Spark作业来执行SQL时,返回的结果是Dataframe/Dataset类型的。当然,我们也可以通过Spark SQL的shell命令行工具,或者是JDBC/ODBC接口来访问。
Dataframe的常用方法,具体如下如示。
1.show():
查看DataFrame中的具体内容信息,这将会打印DataFrame df的前20行数据
基础代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object Y1{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local")
val sc = new SparkContext(conf)
val spark = SparkSession.builder
.appName("Spark SQL show example")
.master("local[*]") // 或者你的Spark集群 URL
.getOrCreate()
import spark.implicits._
// 示例数据
val people = Seq(
(1, "Alice", 34),
(2, "Bob", 42),
(3, "Charlie", 51)
)
// 将示例数据转换为DataFrame
val df = people.toDF("id", "name", "age")
df.show()
sc.stop()
}
}
效果展示:

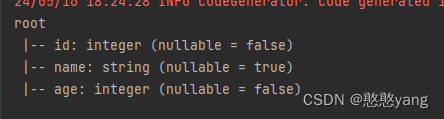
2.printSchema()
查看DataFrame的Schema信息
基础代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object Y1{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local")
val sc = new SparkContext(conf)
val spark = SparkSession.builder
.appName("Spark SQL show example")
.master("local[*]") // 或者你的Spark集群 URL
.getOrCreate()
import spark.implicits._
// 示例数据
val people = Seq(
(1, "Alice", 34),
(2, "Bob", 42),
(3, "Charlie", 51)
)
// 将示例数据转换为DataFrame
val df = people.toDF("id", "name", "age")
df.printSchema()
sc.stop()
}
}
效果展示:
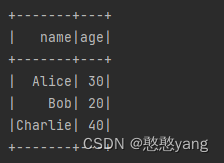
3.select()
查看DataFrame中选取部分列的数据及进行重命名
基础代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object Y1{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local")
val sc = new SparkContext(conf)
val spark = SparkSession.builder
.appName("Spark SQL show example")
.master("local[*]") // 或者你的Spark集群 URL
.getOrCreate()
import spark.implicits._
// 示例数据
val peopleDF = Seq(
("Alice", 30, "USA"),
("Bob", 20, "Canada"),
("Charlie", 40, "UK")
).toDF("name", "age", "country")
val selectedDF = peopleDF.select("name", "age")
// 显示结果
selectedDF.show()
sc.stop()
}
}
效果展示:
4.filter()
实现条件查询,过滤出想要的结果
基础代码:
import org.apache.spark.sql.SparkSession
object Y1 {
case class Person(name: String, age: Int)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Spark SQL Demo")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// 创建Person案例类的DataFrame对象
val personsDF = Seq(
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 35)
).toDF()
// 使用filter()方法过滤出年龄大于等于30的人
val filteredDF = personsDF.filter($"age" >= 30)
// 显示结果
filteredDF.show()
// 关闭SparkSession
spark.stop()
}
}
效果展示:

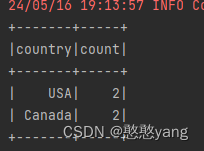
5.groupBy()
对记录进行分组
基础代码:
import org.apache.spark.sql.SparkSession
object SparkSQLDemo {
case class Person(name: String, age: Int, country: String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Spark SQL Demo")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// 创建Person案例类的DataFrame对象
val personsDF = Seq(
Person("Alice", 25, "USA"),
Person("Bob", 30, "Canada"),
Person("Charlie", 35, "USA"),
Person("Dave", 40, "Canada")
).toDF()
// 使用groupBy()方法按照国家分组,并计算每个国家的人数
val groupedDF = personsDF.groupBy($"country").count()
// 显示结果
groupedDF.show()
// 关闭SparkSession
spark.stop()
}
}
效果展示:
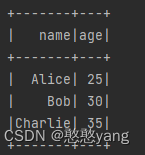
6.sort()
对特定字段进行排序操作
基础代码:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object Y1 {
case class Person(name: String, age: Int)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Spark SQL Demo")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// 创建Person案例类的DataFrame对象
val personsDF = Seq(
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 35)
).toDF()
// 使用sort()方法按照年龄升序排序
val sortedDF = personsDF.sort(asc("age"))
// 显示结果
sortedDF.show()
// 关闭SparkSession
spark.stop()
}
}
效果展示:
新人作者,如果有什么需要改进的地方,请多多指教!