Parts2Whole,它可以从任何数量和不同来源的参考人体部位图像中生成逼真的、高质量的各种姿势的人体人物。我们的方法保持了与相应条件语义区域的高度一致性,同时保证了整体之间的多样性和协调性。

(a)以不同人的参考图像为条件生成人的图像。每对包括4个人体部位输入(第一列)和生成的图像(第二列)。

(b)从不同数量的参考图像生成人的图像。每对包括1或2个人体部位输入(第一行)和生成的图像(第二行)。
相关链接
项⽬主⻚:https://huanngzh.github.io/Parts2Whole/
Github链接:https://github.com/huanngzh/Parts2Whole
论文:https://arxiv.org/pdf/2404.15267
论文阅读

摘要
最近在可控人类图像生成方面的进展导致了使用结构信号(例如,姿势,深度)或面部外观的零拍摄生成。然而,以人类外表的多个部分为条件生成人类图像仍然具有挑战性
为了解决这个问题,我们介绍了Parts2Whole,这是一个新的框架,用于从多个参考图像(包括姿势图像和人体外观的各个方面)生成定制肖像。为了实现这一点,我们首先开发了一个语义感知的外观编码器,以保留不同人体部位的细节。将一个基于文本标签将每张图像处理成一系列多尺度特征图,而不是一个图像标记,以保持图像的维度。
其次,我们的框架通过在扩散过程中跨越参考和目标特征的共享自关注机制支持多图像条件生成。我们通过结合来自参考人类图像的掩模信息来增强香草注意力机制,允许精确选择任何部分。大量的实验证明了我们的方法优于现有的替代方法,为多部分可控的人体图像定制提供了先进的功能。
方法
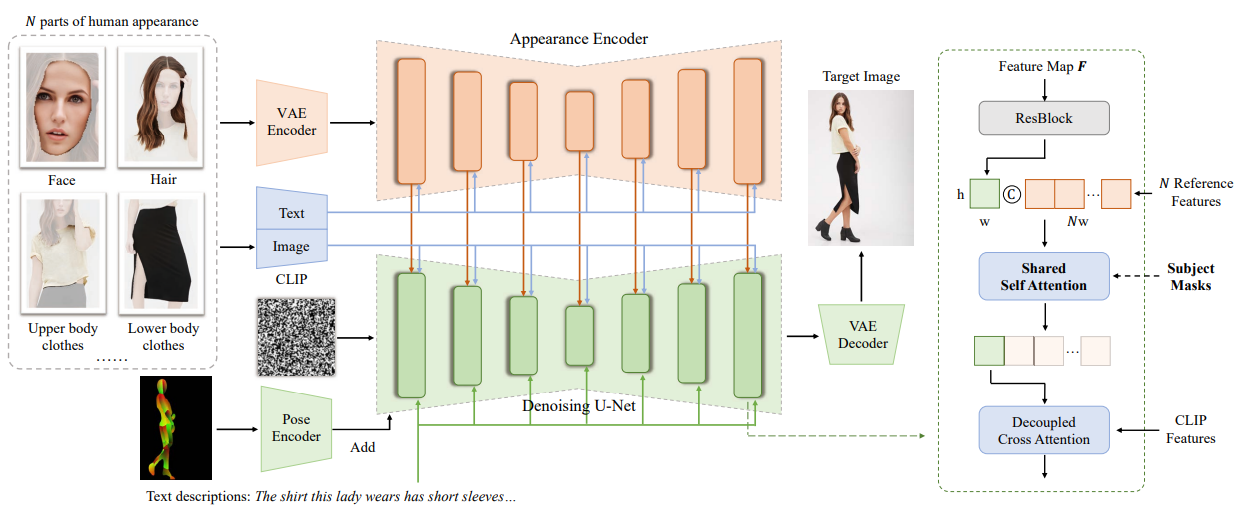
part2whole概述。该方法基于文本到图像扩散模型,设计了一种外观编码器,用于将人体外观的各个部分编码成多尺度特征图。我们通过复制U-Net去噪的网络结构和预训练的权重来构建这个编码器。
通过共享注意机制,逐层将参考图像的特征及其文本标签注入到生成过程中。为了从参考图像中精确地选择指定的部位,我们通过在参考图像中加入主题掩模来增强香草自注意机制。U-Net中的一个块的插图显示在右侧。
实验
parts2-whole和现有备选方案在我们的分区测试集上生成的定性结果。我们没有在图中显示文本条件,但值得注意的是,当我们将参考图像输入到我们提出的外观编码器时,我们将传递短标签,如面部、头发或头饰、上身衣服、下半身衣服、全身衣服、鞋子等。


定性分析了采用不同主干的外观编码器,并提出了相应的方法。


生成的结果来自不同数量条件的组合。

结论
在这项工作中,我们提出了Parts2Whole,这是一个基于多个参考图像的可控人类图像生成的新框架,包括人类外观的各个方面(例如,头发,脸,衣服,鞋子等)和姿势地图。
基于双U-Net设计,我们开发了语义感知的外观编码器来处理基于双U-Net设计的每个条件图像,我们开发了语义感知的外观编码器来处理每个条件。
大量的实验表明,我们的Parts2Whole在图像质量和条件对齐方面表现良好。