一、Pandas框架概述
1、Pandas介绍
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
- Pandas是Python的一个第三方包,也是商业和工程领域最流行的
结构化数据工具集,用于数据清洗、处理以及分析
- Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
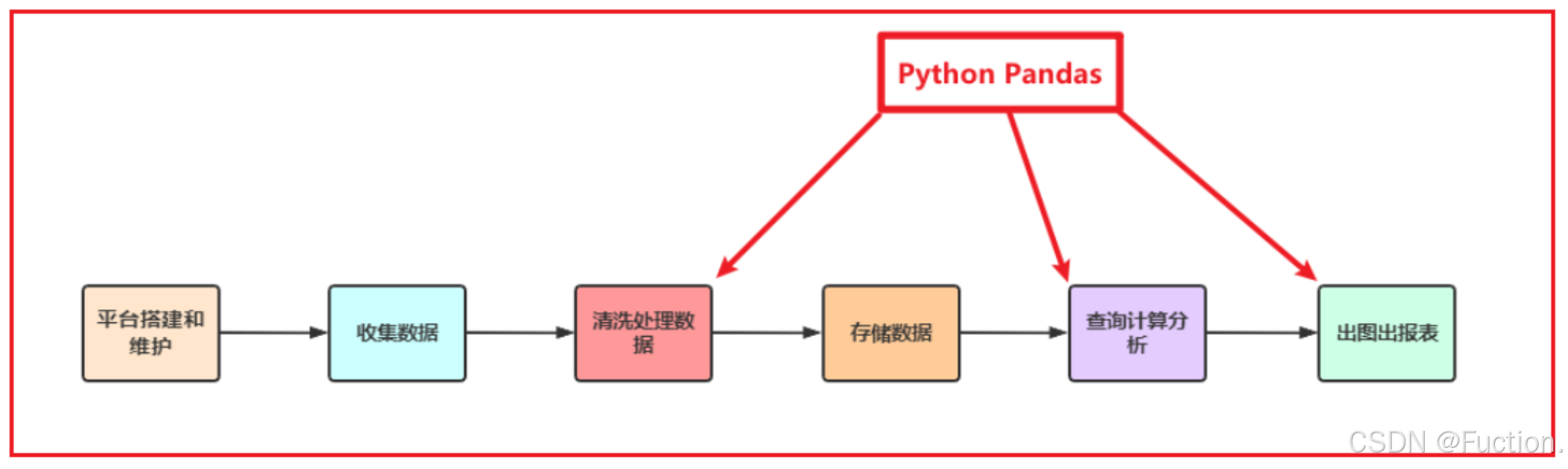
适用场景:
- 数据量大到Excel严重卡顿,且又都是单机数据的时候,我们使用Pandas
- Pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用Pandas
2、安装Pandas
打开cmd窗口,输入如下命令:
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
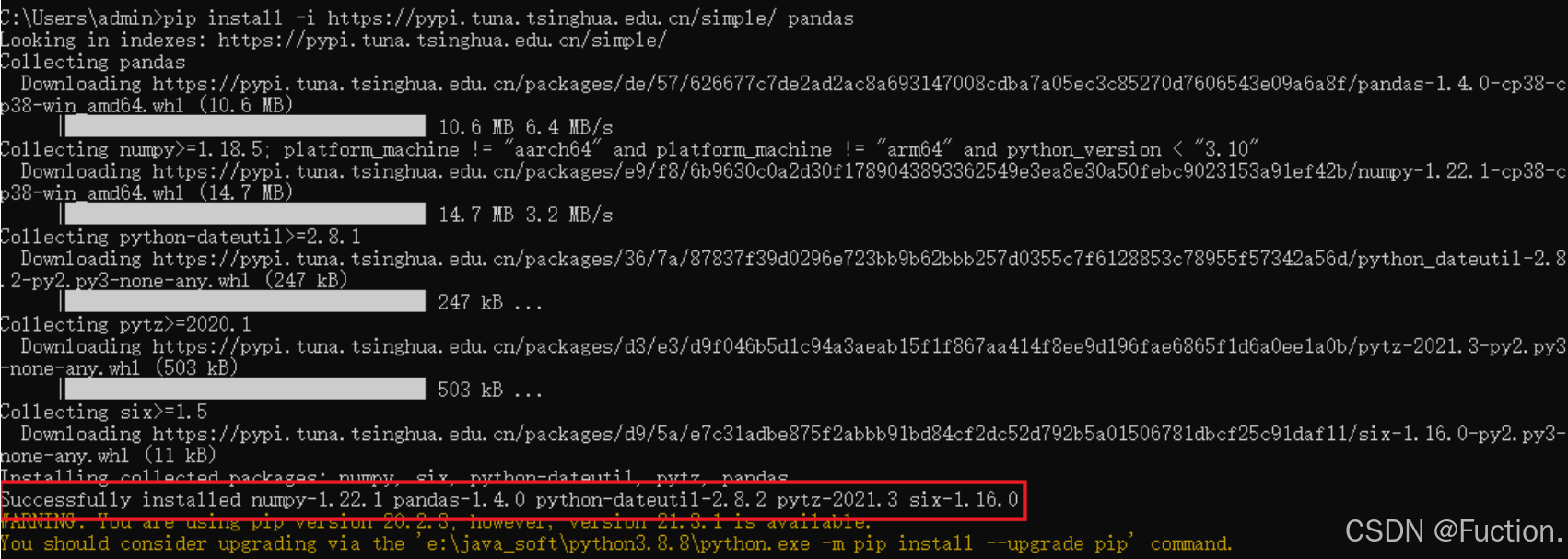
注意:Anaconda默认已经安装了Pandas以及Numpy等内容
导入Pandas
import pandas as pd
二、Pandas数据结构与数据类型
1、Pandas数据结构和数据类型

Pandas的核心概念,以及这些概念的层级关系:
- DataFrame
- Series
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
- 索引列
- Series
其中最核心的就是Pandas中的两个数据结构:DataFrame和Series
1、Series对象
导入pandas
import pandas as pd
通过list列表来创建
# 使用默认自增索引
s2 = pd.Series([1, 2, 3])
print(s2)
# 自定义索引
s3 = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
s3
结果为:
0 1
1 2
2 3
dtype: int64
A 1
B 2
C 3
dtype: int64
使用字典或元组创建series对象
#使用元组
tst = (1,2,3,4,5,6)
pd.Series(tst)
#使用字典:
dst = {'A':1,'B':2,'C':3,'D':4,'E':5,'F':6}
pd.Series(dst)
使用numpy创建series对象
pd.Series(np.arange(10))
# 运行结果
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int642、Series对象属性
sdata.index
- sdata.values
sdata = pd.Series([i for i in range(6)], index=[i for i in 'ABCDEF']) print(sdata) print(sdata.index) print(sdata.values) # 返回结果如下 A 0 B 1 C 2 D 3 E 4 F 5 dtype: int64 Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') [0 1 2 3 4 5]
方法
序号 |
方法名 |
解释 |
1 |
mean() |
计算平均值 |
2 |
max() |
计算最大值 |
3 |
min() |
计算最小值 |
4 |
std() |
计算标准差 |
sdata = pd.Series([i for i in range(6)], index=[i for i in 'ABCDEF'])
print(sdata)
print("计算最小值:", sdata.min())
print("计算最大值:", sdata.max())
print("计算平均值:", sdata.mean())
print("计算标准差值:", sdata.std())
"""
A 0
B 1
C 2
D 3
E 4
F 5
dtype: int64
计算最小值: 0
计算最大值: 5
计算平均值: 2.5
计算标准差值: 1.8708286933869707
"""3、获取Series 对象的值
- 切片与索引
import pandas as pd
data = pd.Series([4, 3, 25, 2, 3], index=list('abcde'))
print(data)
print('根据 key 获取:', data['c']) # 行 c
print('切片获取:', data['a':'c']) # a 到 c 的行
# print('索引获取:', data[0]) # 在 pandas 的 Series 对象中,索引是基于标签的,而不是基于位置的。
print('索引切片:', data[2:3]) # 行 c
'''
运行结果
a 4
b 3
c 25
d 2
e 3
dtype: int64
根据 key 获取: 25
切片获取: a 4
b 3
c 25
dtype: int64
索引切片: c 25
dtype: int64
'''- loc 表示的是标签索引,
- iloc 表示的是位置索引。
位置索引与标签索引有相同值 1,这时候 data[1]就不知道是按哪个来获取,此时要使用 loc、iloc
import pandas as pd
data = pd.Series([5, 3, 2, 5, 9], index=list('abcde'))
print(data)
print(data.loc['b']) # 标签索引
print(data.iloc[1]) # 位置索引
'''
运行结果
a 5
b 3
c 2
d 5
e 9
dtype: int64
3
3
'''
import pandas as pd
data = pd.Series([5, 3, 2, 5, 9], index=[1, 2, 3, 4,5])
print(data)
print(data[1])
print(data.loc[1]) # 标签索引
print(data.iloc[1]) # 位置索引
'''
运行结果
1 5
2 3
3 2
4 5
5 9
dtype: int64
5
5
3
'''4、条件过滤
Series 对象指定条件来过滤数据
import pandas as pd
from IPython.display import display
data = pd.DataFrame({
'Name': ['zs', 'lisi', 'ww'],
'Sno': ['1001', '1002', '1003'],
'Sex': ['man', 'woman', 'man'],
'Age': [17, 18, 19],
'Score': [80, 97, 95]
}, columns=['Sno', 'Sex', 'Age', 'Score'], index=['zs', 'lisi', 'ww'])
display('数据集\r\n', data)
scores = data['Score']
display('筛选出成绩大于平均值的数据:\r\n', scores[scores > scores.mean()])
'''
运行结果
数据集
Sno Sex Age Score
zs 1001 man 17 80
lisi 1002 woman 18 97
ww 1003 man 19 95
筛选出成绩大于平均值的数据:
lisi 97
ww 95
Name: Score, dtype: int64
'''
排序
sort_values(ascending=False) 默认降序排列
import pandas as pd
data = pd.DataFrame({
'Name': ['zs', 'lisi', 'ww'],
'Sno': ['1001', '1002', '1003'],
'Sex': ['man', 'woman', 'man'],
'Age': [17, 18, 19],
'Score': [80, 97, 95]
}, columns=['Sno', 'Sex', 'Age', 'Score'], index=['zs', 'lisi', 'ww'])
print('数据集\r\n', data)
ages = data['Age']
print('对 Age 进行降序排序:\r\n', ages.sort_values(ascending=False))
'''
运行结果
数据集
Sno Sex Age Score
zs 1001 man 17 80
lisi 1002 woman 18 97
ww 1003 man 19 95
获取数据集中 Age 列的所有
zs 17
lisi 18
ww 19
Name: Age, dtype: int64
对 Age 进行降序排序:
ww 19
lisi 18
zs 17
Name: Age, dtype: int64
'''5、去重
series.drop_duplicates()
- 返回一个新的 Series,其中重复的值被删除。如果 inplace=True,则不返回新的 Series,而是直接修改原始 Series。
import pandas as pd
# 创建一个包含重复值的 Series
s = pd.Series([1, 2, 2, 3, 4, 4, 4, 5, 6, 6])
# 删除重复值,只保留第一次出现的值
s_unique = s.drop_duplicates()
print(s_unique)2、DataFrame对象
1- 字典创建df
使用字典加列表创建df,使默认自增索引
df1_data = {
'日期': ['2021-08-21', '2021-08-22', '2021-08-23'],
'温度': [25, 26, 50],
'湿度': [81, 50, 56]
}
df1 = pd.DataFrame(data=df1_data)
df1
# 返回结果如下
日期 温度 湿度
0 2021-08-21 25 81
1 2021-08-22 26 50
2 2021-08-23 50 562- 列表创建df
使用列表加元组创建df,并自定义索引
df2_data = [
('2021-08-21', 25, 81),
('2021-08-22', 26, 50),
('2021-08-23', 27, 56)
]
df2 = pd.DataFrame(
data=df2_data,
columns=['日期', '温度', '湿度'],
index = ['row_1','row_2','row_3'] # 手动指定索引
)
df2
# 返回结果如下
日期 温度 湿度
row_1 2021-08-21 25 81
row_2 2021-08-22 26 50
row_3 2021-08-23 27 563- numpy创建df
使用numpy创建df
通过已有数据创建
pd.DataFrame(np.random.randn(2,3)) # 2行3列
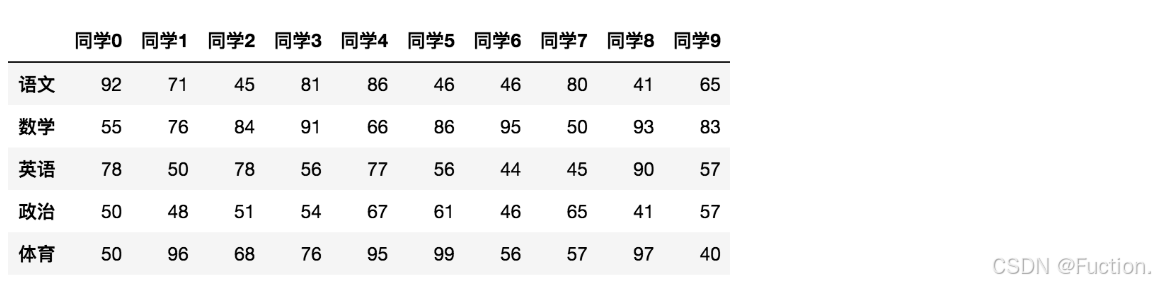
创建学生成绩表
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))
# 结果
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
但是这样的数据形式很难看到存储的是什么的样的数据,可读性比较差!
问题:如何让数据更有意义的显示?
# 使用Pandas中的数据结构
score_df = pd.DataFrame(score)
给分数数据增加行列索引,显示效果更佳效果:

增加行、列索引
# 构造行索引序列
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列索引序列
stu = ['同学' + str(i) for i in range(score_df.shape[0])]
# 添加行索引
data = pd.DataFrame(score, columns=subjects, index=stu)2、属性
1- shape属性
data.shape
# 结果
(10, 5)2- index属性
DataFrame的行索引列表
data.index
# 结果
Index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object')3- columns
data.columns
# 结果
Index(['语文', '数学', '英语', '政治', '体育'], dtype='object')4- values
直接获取其中array的值
data.values
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])5- T转置
data.T
结果
3、方法
1- head(n)
显示前n行内容
data.head(5)
2- tail(n)
显示后n行内容
如果不补充参数,默认5行。填入参数n则显示后n行
data.tail(5)
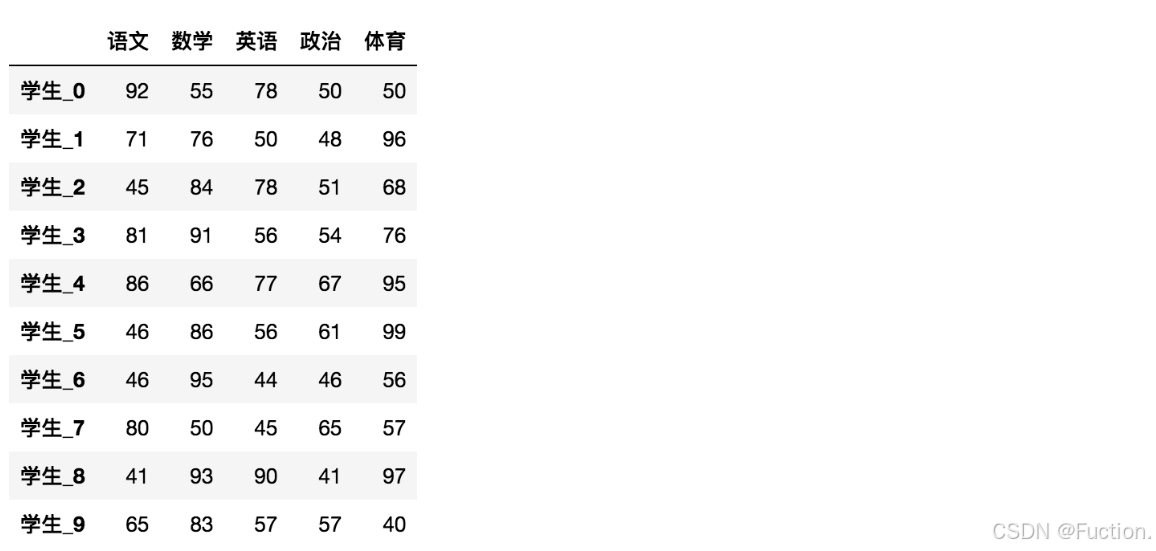
3- 修改行列索引值
stu = ["学生_" + str(i) for i in range(score_df.shape[0])]
# 必须整体全部修改
data.index = stu4、 df索引的设置
需求:
- 1- 修改行列索引值
stu = ["学生_" + str(i) for i in range(score_df.shape[0])]
# 必须整体全部修改
data.index = stu
注意:以下修改方式是错误的
# 错误修改方式
- 2- 重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
- reset_index(drop=False)
# 重置索引,drop=False
data.reset_index()
# 重置索引,drop=True data.reset_index(drop=True)
- 3- 以某列值设置为新的索引
- set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列设置新索引案例
- set_index(keys, drop=True)
第一步:创建
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
month sale year
0 1 55 2012
1 4 40 2014
2 7 84 2013
3 10 31 2014
第二步:以月份设置新的索引
df.set_index('month')
sale year
month
1 55 2012
4 40 2014
7 84 2013
10 31 2014
第三步:设置多个索引,以年和月份
df = df.set_index(['year', 'month']) df sale year month 2012 1 55 2014 4 40 2013 7 84 2014 10 31
5、Pandas的数据类型
df或s对象中具体每一个值的数据类型有很多,如下表所示
Pandas数据类型 |
说明 |
对应的Python类型 |
Object |
字符串类型 |
string |
int |
整数类型 |
int |
float |
浮点数类型 |
float |
datetime |
日期时间类型 |
datetime包中的datetime类型 |
timedelta |
时间差类型 |
datetime包中的timedelta类型 |
category |
分类类型 |
无原生类型,可以自定义 |
bool |
布尔类型 |
bool(True,False) |
nan |
空值类型 |
None |
- 可以通过下列API查看s对象或df对象中数据的类型
s1.dtypes
df1.dtypes
df1.info() # s对象没有info()方法- 几个特殊类型演示
- datetime类型
import pandas as pd
# 创建一个datetime类型的Series
dates = pd.to_datetime(['2024-09-01', '2024-09-02', '2024-09-03'])
print(dates)
类型用于表示分类数据,通常用于有限集合中的数据类型,例如性别、颜色、产品类型等。这种类型的优点在于占用更少的内存,并且对分类数据的操作更快。
import pandas as pd
# 创建一个category类型的Series
categories = pd.Series(['apple', 'banana', 'apple', 'orange'], dtype='category')
print(categories)6、修改
1- 修改列名
修改某一列列名
df = pd.DataFrame({
"电视广告数(x)": [1,3,2,1,3],
"汽车销售数(y)": [14,24,18,17,27]
})
df = df.rename(columns={'电视广告数(x)':'x'})
print(df)
"""
x 汽车销售数(y)
0 1 14
1 3 24
2 2 18
3 1 17
4 3 27
"""
修改所有列名
df = pd.DataFrame({
"电视广告数(x)": [1,3,2,1,3],
"汽车销售数(y)": [14,24,18,17,27]
})
df.columns =['x','y']
print(df)
"""
x y
0 1 14
1 3 24
2 2 18
3 1 17
4 3 27
"""2- 修改行索引
将某一个列作为行索引
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df = df.set_index(df['y'])
print(df)
指定所有行的索引
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df.index= [11,22,33,44,55]
print(df)
"""
x y
11 1 14
22 3 24
33 2 18
44 1 17
55 3 27
"""3- 修改列值
修改某列的值
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df['x'] =1
df.y=2 # 点列名 注意这里的列名不能有空格
print(df)
"""
x y
0 1 2
1 1 2
2 1 2
3 1 2
4 1 2
"""
通过assign设置多列
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df = df.assign(x= [1,3,2,1,3], y =[14,24,18,17,27] )
print(df)4- 修改列类型
df = pd.DataFrame({
"x": [1,3,2,1,3], # 这里是int64
"y": [14,24,18,17,27]
})
df['x'] = df['x'].astype('float') #转成float64
print(df.info())
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 5 non-null float64
1 y 5 non-null int64
dtypes: float64(1), int64(1)
memory usage: 212.0 bytes
"""5- replace(替换)
- 但列的替换
- 整个的替换
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# 把 x列的1改成14
df['x'] = df['x'].replace(1,14)
# 把所有的14改成41
df = df.replace(14,41)
print(df)7、增加
- 增加一列固定值
- 根据已有列得到列数据
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# 直接写某个值
df['l'] = 1
# 添加z列,z列的值是x列值+1
df['z'] = df['x']+1
print(df)
"""
x y z l
0 1 14 2 1
1 3 24 4 1
2 2 18 3 1
3 1 17 2 1
4 3 27 4 1
"""- 根据已有列添加
根据已有列信息添加新列
指定多分类填充
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df.loc[df['x']==1,'评价'] = '差'
df.loc[df['x']==2,'评价'] = '中'
df.loc[df['x']==3,'评价'] = '好'
print(df)
"""
x y 评价
0 1 14 差
1 3 24 好
2 2 18 中
3 1 17 差
4 3 27 好
"""
使用np.where二分类填充
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df['评价'] = np.where(df['x']==3,'优秀', '普通')
print(df)
"""
x y 评价
0 1 14 普通
1 3 24 优秀
2 2 18 普通
3 1 17 普通
4 3 27 优秀
"""
使用assign添加列
- 添加1列
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# z 为新列名
df = df.assign(z = df.x)
print(df)
"""
x y z
0 1 14 1
1 3 24 3
2 2 18 2
3 1 17 1
4 3 27 3
"""- 添加多列
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
kwargs = {"new col1":1, "new col2" : df.y}
df = df.assign(**kwargs)
print(df)
"""
x y new col1 new col2
0 1 14 1 14
1 3 24 1 24
2 2 18 1 18
3 1 17 1 17
4 3 27 1 27
"""df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# kwargs = {"new col1":1, "new col2" : df.y}
# 注意这里列明不能带空格
kwargs = dict(newcol1 =1, newcol2 = df.y)
df = df.assign(**kwargs)
print(df)
"""
x y newcol1 newcol2
0 1 14 1 14
1 3 24 1 24
2 2 18 1 18
3 1 17 1 17
4 3 27 1 27
"""8、删除
1- 删除列
- drop(['列名1','列名2'...], axis=1)
- axis = 1表示删除列
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# kwargs = {"new col1":1, "new col2" : df.y}
kwargs = dict(newcol1 =1, newcol2 = df.y)
df = df.assign(**kwargs)
df = df.drop(['newcol1', 'newcol2'],axis=1)
print(df)
"""
x y
0 1 14
1 3 24
2 2 18
3 1 17
4 3 27
"""- del 删除列
注意:这里的是删除是直接修改源数据
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# kwargs = {"new col1":1, "new col2" : df.y}
kwargs = dict(newcol1 =1, newcol2 = df.y)
df = df.assign(**kwargs)
del df['newcol1']
del df['newcol2']
print(df)2- 删除行
- drop([行索引1,行索引2...], axis=0)
- axis = 0表示删除行(默认就是行删除)
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
# 删除前两行
df = df.drop([0,1])
print(df)- 指定行索引的删除
注意这里航索引是字符串
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df.index= ['1','2','3','4','5']
# 删除前两行
df = df.drop(['1','2'])
print(df)9- 排序
- 按索引排序
sort_index()
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df.index= [1,3,5,2,7]
df = df.sort_index()
print(df)
"""
x y
1 1 14
2 1 17
3 3 24
5 2 18
7 3 27
"""- 按内容排序
sort_value(by ='列名', ascending = True)
ascending True:升序,False:降序(默认)
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df = df.sort_values(by='x', ascending=True)
print(df)
"""
x y
0 1 14
3 1 17
2 2 18
1 3 24
4 3 27
"""10、去重
- drop_duplicates
df = pd.DataFrame({
"x": [1,3,2,1,3],
"y": [14,24,18,17,27]
})
df['x'] = df['x'].drop_duplicates()
print(df)
"""
x y
0 1.0 14
1 3.0 24
2 2.0 18
3 NaN 17
4 NaN 27
"""11、获取
获取DataFrame对象的值
数据
data = pd.DataFrame(np.arange(12).reshape(3, 4), index=list('abc'), columns=list('ABCD'))
df点列名获取
data.B
获取'B'列
切片获取
data['B']
获取 'B '列
data[ ['A', 'C'] ]
'获取 'A ' 'C '两列 注意:这里是两个方括号
loc
data.loc['a']
获取 a 行,标签获取
data.loc['a':'b']
选择 a 行 b 行 按标签获取,注意这里是冒号
data.loc[ ['a', 'c'] ]
获取 a c 行,按标签获取,注意这里是逗号
data.loc[ : , 'B':'D' ]
获取 B C D 三列,使用普通索引获取
data.loc[ 'a':'b', 'A':'B' ]
同时获取 a b 行,A B 列 按标签获取
data.loc[ ['a', 'c'], ['A', 'B', 'D'] ]
同时获取 a c 行,ABD 列 按标签获取
iloc
data.iloc[ 0 ]
获取第 1 行,位置索引获取
data.iloc[ 0:2 ]
选择第 1 行 第 2 行,使用位置索引
data.iloc[ [0, 2] ]
获取第 1 行第 3 行,位置索引获取
data.iloc[ : , 0 ]
获取第 1 列
data.iloc[ : , 1:4 ]
获取 B C D 三列,使用位置索引获取
data.iloc[ : , [ 0, 2 ] ]
获取第 1 列和第 3 列
data.iloc[ 0:2, 0:2 ]
同时获取 a b 行,A B 列 按标签获取
data.iloc[ [0, 2], [0, 1, 3] ]
同时获取 a c 行,ABD 列,使用位置索引