1、创建虚拟环境
conda create -n myenv python=3.12 -y
2、激活虚拟环境
conda activate myenv
3、安装相关库
pip install vllm fastapi uvicorn
4、编写脚本(test.py)
from fastapi import FastAPI, Request
from vllm import LLM, SamplingParams
import uvicorn
app = FastAPI()
model_path = "/home/zhengyihan/.cache/modelscope/hub/LLM-Research/Llama-3___2-3B-Instruct"
llm = LLM(
model=model_path,
max_model_len=8192,
gpu_memory_utilization=0.95
)
@app.post("/generate")
async def generate(request: Request):
body = await request.json()
prompt = body.get("prompt", "")
temperature = body.get("temperature", 0.7)
top_p = body.get("top_p", 0.95)
max_tokens = body.get("max_tokens", 512)
sampling_params = SamplingParams(
temperature=temperature,
top_p=top_p,
max_tokens=max_tokens
)
outputs = llm.generate(prompt, sampling_params)
results = []
for output in outputs:
results.append({
"generated_text": output.outputs[0].text,
"prompt": output.prompt
})
return {"results": results}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
调用脚本
python test.py
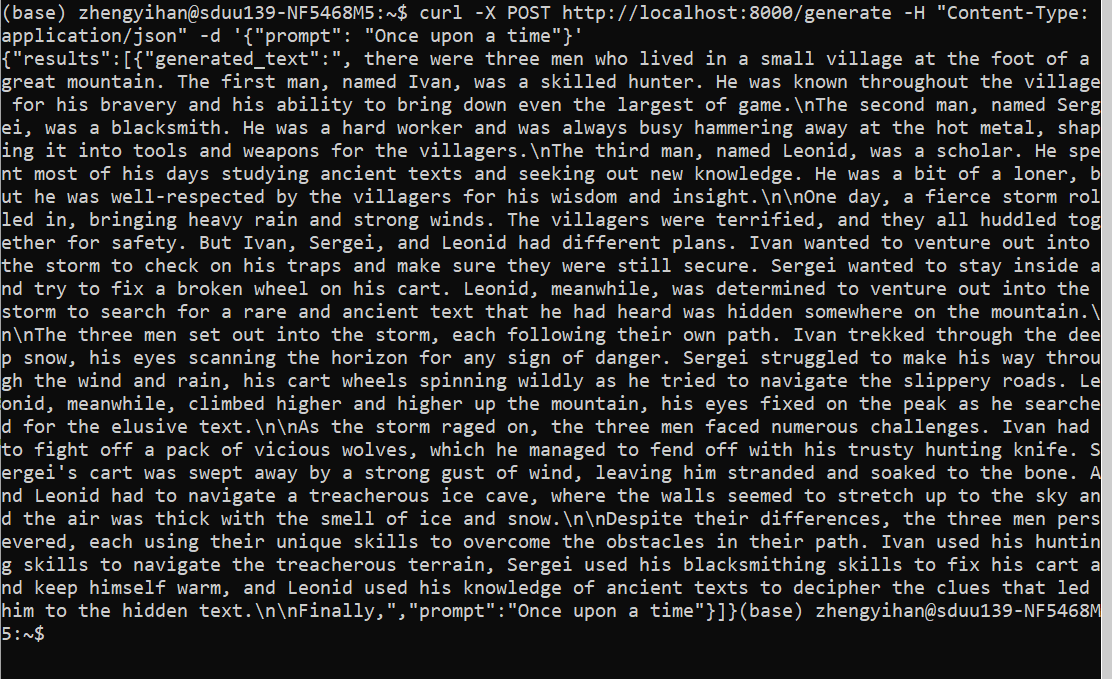
5、bash中测试通信
curl -X POST http://localhost:8000/generate -H "Content-Type: application/json" -d '{"prompt": "Once upon a time"}'
完美结果