常见的特征筛选算法
- 方差筛选
- 皮尔逊相关系数筛选
- lasso筛选
- 树模型重要性
- shap重要性
- 递归特征消除REF
作业:对心脏病数据集完成特征筛选,对比精度
面对高维特征的时候常常需要引入特征降维,对于某些特征较多的数据,如基因数据、微生物数据、传感器数据等,特征较多,所以会考虑特征降维。特征降维一般有2种策略:
1. 特征筛选:从n个特征中筛选出m个特征,比如方差筛选,剔除方差过小的特征;利用皮尔逊相关系数筛选;lasso筛选(lasso自带的系数可以理解为重要性)、利用树模型自带的重要性、shap重要性等筛选;特征递归方法
2. 特征组合:从n个特征中组合出m个特征,如pca等
今天这节先说一下特征筛选,!!注意一个点:数据集和训练集划分后分别进行特征筛选,是为了避免数据泄露。测试集的作用是模拟未知数据,如果在整个数据集上先筛选特征,就相当于用了测试集信息"作弊"了,测试集的信息就会"泄露"到训练过程中,导致模型评估结果过于乐观。其次,使用训练集确定的筛选标准应用到测试集是保持处理流程的一致性,所有决策依据都来自训练集这个封闭系统,不会导致数据泄露,区分一下这两个的不同
1.方差筛选
核心逻辑是:特征的方差反映了数据的变化程度,方差很小的特征几乎没有变化,对模型的预测帮助不大。因此,方差筛选会设定一个方差阈值,剔除方差低于这个阈值的特征,保留那些变化较大的特征,从而减少特征数量,提高模型效率(值得注意的是,方差筛选只需要特征数据即可筛选,是无监督筛选,不像其他筛选算法)
这种方法特别适合处理高维数据,能快速去掉不重要的特征,但它不考虑特征与目标变量之间的关系,可能会误删一些低方差但有意义的特征
# 打印标题,表明这是方差筛选的部分
print("--- 方差筛选 (Variance Threshold) ---")
# 导入需要的工具库
from sklearn.feature_selection import VarianceThreshold # 方差筛选工具,用于剔除方差小的特征
import time # 用于记录代码运行时间,方便比较效率
# 记录开始时间,后面会计算整个过程耗时
start_time = time.time()
# 创建方差筛选器,设置方差阈值为0.01
# 阈值是指方差的最小值,低于这个值的特征会被删除(可以根据数据情况调整阈值)
selector = VarianceThreshold(threshold=0.01)
# 对训练数据进行方差筛选,fit_transform会计算每个特征的方差并剔除不满足阈值的特征
# X_train是原始训练数据,X_train_var是筛选后的训练数据
X_train_var = selector.fit_transform(X_train)
# 对测试数据应用同样的筛选规则,transform会直接用训练数据的筛选结果处理测试数据
# X_test是原始测试数据,X_test_var是筛选后的测试数据
X_test_var = selector.transform(X_test)
# 获取被保留下来的特征名称
# selector.get_support()返回一个布尔值数组,表示哪些特征被保留,如 [True, False, True,...]
# X_train.columns是特征的名称,布尔值数组在这里起一个索引的作用,可以提取保留特征的名字
selected_features_var = X_train.columns[selector.get_support()].tolist()
# 打印筛选后保留的特征数量和具体特征名称,方便查看结果
print(f"方差筛选后保留的特征数量: {len(selected_features_var)}")
print(f"保留的特征: {selected_features_var}")
# 创建一个随机森林分类模型,用于在筛选后的数据上进行训练和预测
# random_state=42是为了保证每次运行结果一致,方便教学和对比
rf_model_var = RandomForestClassifier(random_state=42)
# 在筛选后的训练数据上训练模型
# X_train_var是筛选后的特征数据,y_train是对应的目标标签
rf_model_var.fit(X_train_var, y_train)
# 使用训练好的模型对筛选后的测试数据进行预测
# X_test_var是筛选后的测试特征数据,rf_pred_var是预测结果
rf_pred_var = rf_model_var.predict(X_test_var)
# 记录结束时间,计算整个训练和预测过程的耗时
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
# 打印模型在测试集上的分类报告,展示模型的性能
# 分类报告包括精确率、召回率、F1分数等指标,帮助评估模型好坏
print("\n方差筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_var))
# 打印混淆矩阵,展示模型预测的详细结果
# 混淆矩阵显示了真实标签和预测标签的对应情况,比如多少样本被正确分类,多少被错分
print("方差筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_var))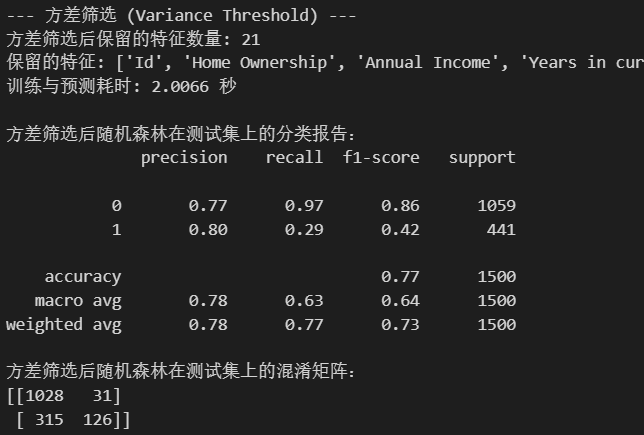
2.皮尔逊相关系数筛选
核心逻辑是:计算每个特征与目标变量之间的相关系数,然后根据相关系数的绝对值大小,选择与目标变量相关性较高的特征,剔除相关性较低的特征。这种方法适用于目标变量是连续型的情况(如果是分类问题,可以先对目标变量编码转换成数值型,用的时候设定参数score_func=f_classif就行,封装好了不需要手动编码)
print("--- 皮尔逊相关系数筛选 ---")
from sklearn.feature_selection import SelectKBest, f_classif
import time
start_time = time.time()
# 计算特征与目标变量的相关性,选择前k个特征(这里设为10个,可调整)
# 注意:皮尔逊相关系数通常用于回归问题(连续型目标变量),但如果目标是分类问题,可以用f_classif
k = 10
selector = SelectKBest(score_func=f_classif, k=k)
X_train_corr = selector.fit_transform(X_train, y_train)
X_test_corr = selector.transform(X_test)
# 获取筛选后的特征名
selected_features_corr = X_train.columns[selector.get_support()].tolist()
print(f"皮尔逊相关系数筛选后保留的特征数量: {len(selected_features_corr)}")
print(f"保留的特征: {selected_features_corr}")
# 训练随机森林模型
rf_model_corr = RandomForestClassifier(random_state=42)
rf_model_corr.fit(X_train_corr, y_train)
rf_pred_corr = rf_model_corr.predict(X_test_corr)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n皮尔逊相关系数筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_corr))
print("皮尔逊相关系数筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_corr))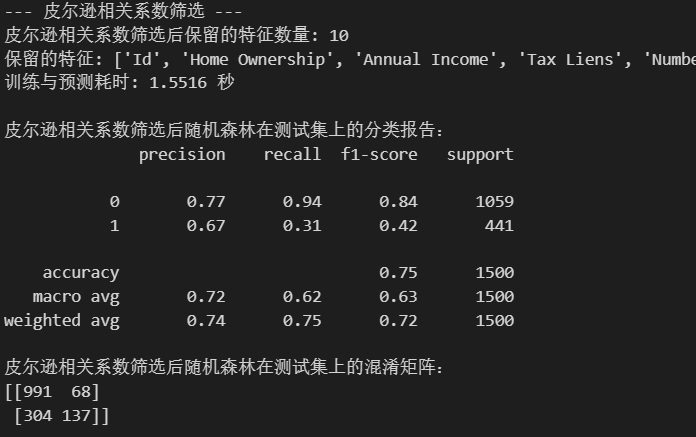
3.lasso筛选(基于L1正则化)
核心逻辑是:在进行线性回归的同时,通过引入L1正则化项(即惩罚项),强制将一些不重要特征的回归系数压缩到0,从而实现特征筛选。换句话说,Lasso会自动“挑选”对预测目标有贡献的特征(系数不为0),而剔除无关或冗余的特征(系数为0)
print("--- Lasso筛选 (L1正则化) ---")
from sklearn.linear_model import Lasso
from sklearn.feature_selection import SelectFromModel
import time
start_time = time.time()
# 使用Lasso回归进行特征筛选
lasso = Lasso(alpha=0.01, random_state=42) # alpha值可调整
selector = SelectFromModel(lasso)
selector.fit(X_train, y_train)
X_train_lasso = selector.transform(X_train)
X_test_lasso = selector.transform(X_test)
# 获取筛选后的特征名
selected_features_lasso = X_train.columns[selector.get_support()].tolist()
print(f"Lasso筛选后保留的特征数量: {len(selected_features_lasso)}")
print(f"保留的特征: {selected_features_lasso}")
# 训练随机森林模型
rf_model_lasso = RandomForestClassifier(random_state=42)
rf_model_lasso.fit(X_train_lasso, y_train)
rf_pred_lasso = rf_model_lasso.predict(X_test_lasso)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\nLasso筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lasso))
print("Lasso筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lasso))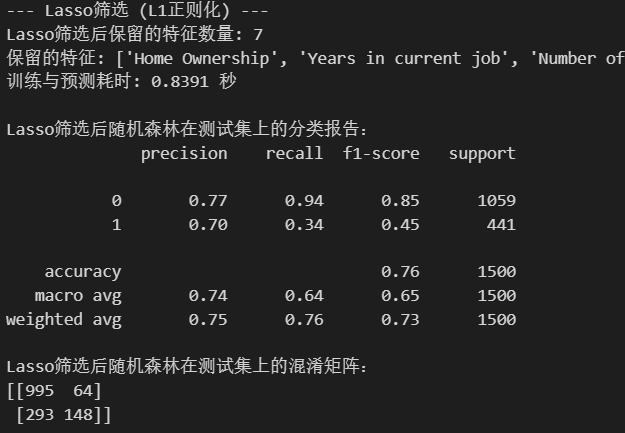
Lasso本质是线性回归模型,要求目标变量是连续值,但分类问题的目标变量是离散类别,强行用回归方法处理分类问题会带来理论缺陷,把类别标签0/1当作连续数值处理,拟合的是"用特征预测0到1之间的数值"的回归问题,虽然确实能计算
4.树模型重要性
依赖于树模型自带的内部评估的特征选择,在训练时让模型自己告诉哪些特征最重要
print("--- 树模型自带的重要性筛选 ---")
from sklearn.feature_selection import SelectFromModel
import time
start_time = time.time()
# 使用随机森林的特征重要性进行筛选
rf_selector = RandomForestClassifier(random_state=42)
rf_selector.fit(X_train, y_train)
selector = SelectFromModel(rf_selector, threshold="mean") # 阈值设为平均重要性,可调整
X_train_rf = selector.transform(X_train)
X_test_rf = selector.transform(X_test)
# 获取筛选后的特征名
selected_features_rf = X_train.columns[selector.get_support()].tolist()
print(f"树模型重要性筛选后保留的特征数量: {len(selected_features_rf)}")
print(f"保留的特征: {selected_features_rf}")
# 训练随机森林模型
rf_model_rf = RandomForestClassifier(random_state=42)
rf_model_rf.fit(X_train_rf, y_train)
rf_pred_rf = rf_model_rf.predict(X_test_rf)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n树模型重要性筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_rf))
print("树模型重要性筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_rf))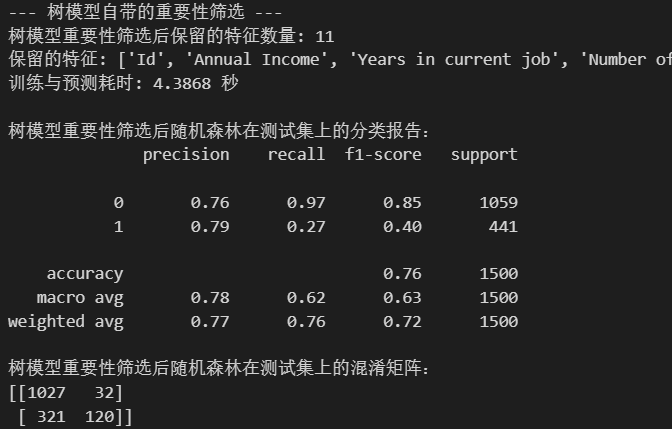
疑问点:为什么创建了两次随机森林分类器?
答:第一次创建 rf_selector 是专门用于特征重要性评估,传入的是原始的 x_train,第二次创建 rf_model_rf 是用筛选后的特征训练最终预测模型,传入的是筛选后的 x_train_rf,让特征选择和最终模型实现了隔离,避免数据泄露
5.shap重要性
通过shap值本来就可以可视化特征的重要程度,这是之前讲过的,不过多赘述了
(从之前的学习来说,shap重要性还是不太适合维度过大的数据,shap值运算很耗时的,比起其他筛选算法不太划算,建议在高维场景下先用快速方法降维,再局部使用SHAP进行精细筛选)
print("--- SHAP重要性筛选 ---")
import shap
from sklearn.feature_selection import SelectKBest
import time
start_time = time.time()
# 使用随机森林模型计算SHAP值
rf_shap = RandomForestClassifier(random_state=42)
rf_shap.fit(X_train, y_train)
explainer = shap.TreeExplainer(rf_shap)
shap_values = explainer.shap_values(X_train)
# 计算每个特征的平均SHAP值(取绝对值的平均,可以只在乎贡献大小而不关心方向)
mean_shap = np.abs(shap_values[1]).mean(axis=0) # shap_values[1]对应正类
k = 10 # 选择前10个特征,可调整
top_k_indices = np.argsort(mean_shap)[-k:] # 返回数值从小到大排序的重要特征列索引位置,取最后K个
X_train_shap = X_train.iloc[:, top_k_indices]
X_test_shap = X_test.iloc[:, top_k_indices]
# 获取筛选后的特征名
selected_features_shap = X_train.columns[top_k_indices].tolist()
print(f"SHAP重要性筛选后保留的特征数量: {len(selected_features_shap)}")
print(f"保留的特征: {selected_features_shap}")
# 训练随机森林模型
rf_model_shap = RandomForestClassifier(random_state=42)
rf_model_shap.fit(X_train_shap, y_train)
rf_pred_shap = rf_model_shap.predict(X_test_shap)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\nSHAP重要性筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_shap))
print("SHAP重要性筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_shap))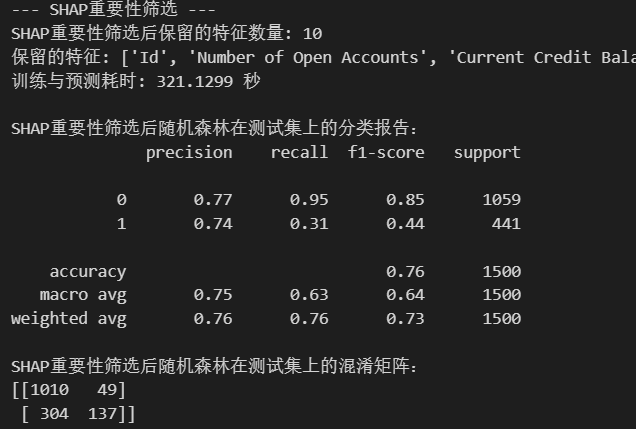
6.递归特征消除REF
核心思想是通过递归地移除最不重要的特征,逐步缩小特征集,直到达到预设的特征数量或满足其他停止条件
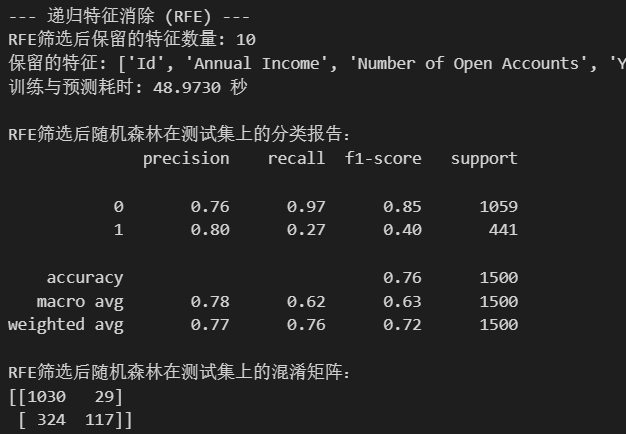
print("--- 递归特征消除 (RFE) ---")
from sklearn.feature_selection import RFE
import time
start_time = time.time()
# 使用随机森林作为基础模型进行RFE
base_model = RandomForestClassifier(random_state=42)
rfe = RFE(base_model, n_features_to_select=10) # 选择10个特征,可调整
rfe.fit(X_train, y_train)
X_train_rfe = rfe.transform(X_train)
X_test_rfe = rfe.transform(X_test)
# 获取筛选后的特征名
selected_features_rfe = X_train.columns[rfe.support_].tolist()
print(f"RFE筛选后保留的特征数量: {len(selected_features_rfe)}")
print(f"保留的特征: {selected_features_rfe}")
# 训练随机森林模型
rf_model_rfe = RandomForestClassifier(random_state=42)
rf_model_rfe.fit(X_train_rfe, y_train)
rf_pred_rfe = rf_model_rfe.predict(X_test_rfe)
end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\nRFE筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_rfe))
print("RFE筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_rfe))