论文地址:arxiv.org/abs/2410.16687
代码开源:github.com/marmotlab/DARE
1. 简介
自主机器人探索任务要求机器人在未知环境中高效地构建地图。传统方法多依赖于当前认知状态进行路径优化,难以充分利用历史经验。新加坡国立大学提出的DARE(Diffusion Policy for Autonomous Robot Exploration)是一种基于扩散模型的生成式探索方法,通过专家演示数据训练,能够一次性生成高效的探索路径,并在模拟与现实环境中展现出优异的泛化能力。
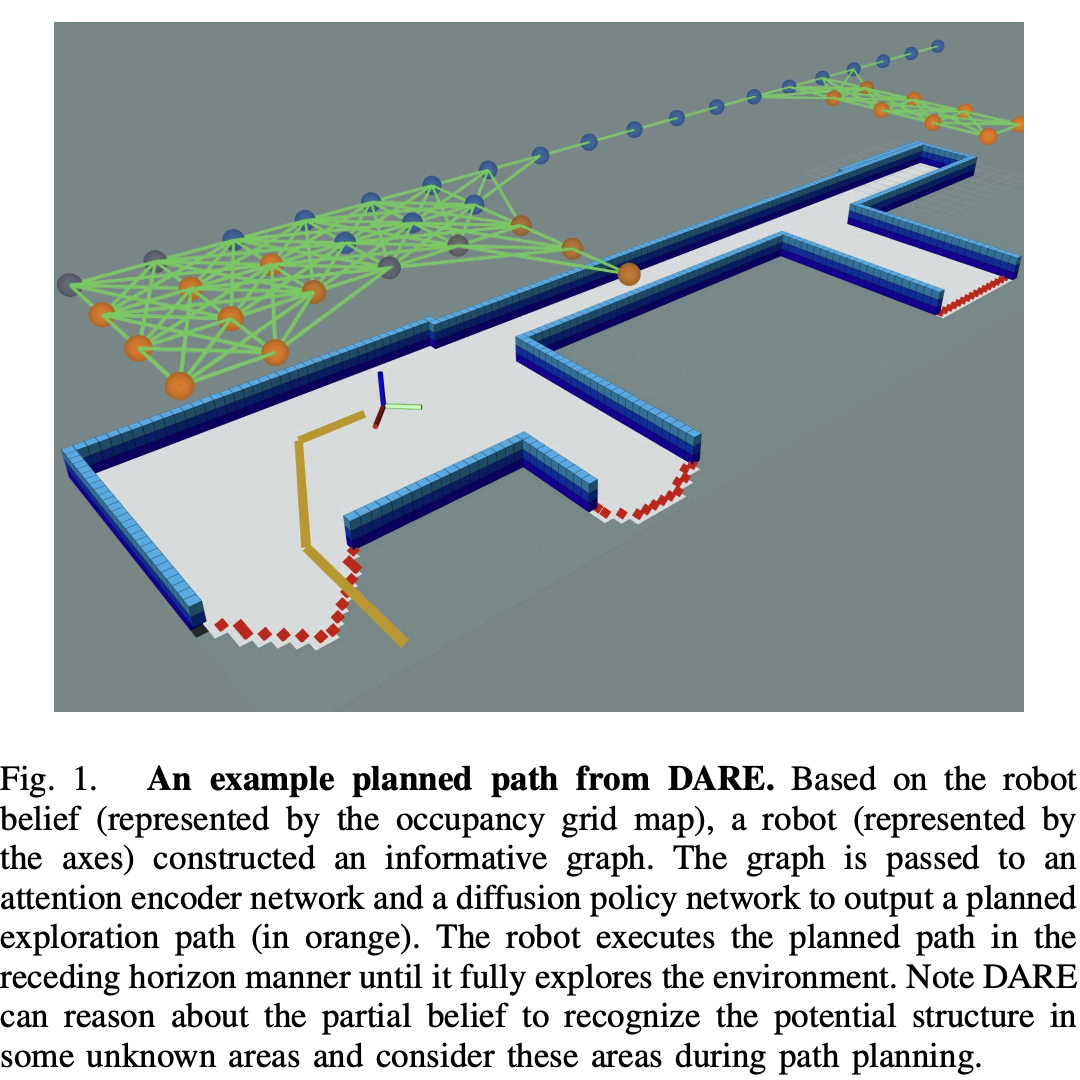
图1:来自DARE的示意路径。基于机器人对环境的认知(以占用栅格图表示),机器人(由坐标轴表示)构建了一个信息丰富的图谱。该图谱被输入到注意力编码网络和扩散策略网络,生成一条规划的探索路径(用橙色标出)。机器人按照递归视野方式执行该路径,直至完全探索完环境。值得注意的是,DARE能够利用部分认知信息推理,识别某些未知区域的潜在结构,并在路径规划时考虑这些区域。
2. 主要贡献
- 提出DARE探索框架:首次将扩散模型引入自主机器人探索,结合图结构编码与扩散策略,生成可解释的长期探索路径。
- 专家最优演示训练:利用已知地图和覆盖路径算法,获得近似最优探索路径,显著提升模型性能。
- 强泛化能力:在模拟和真实环境中均取得与最优规划器相当的表现,缩小了仿真与现实的差距。
3. 相关工作
3.1 传统探索方法
所谓“前沿驱动”探索方法,是指每次选择一个前沿(即已知自由空间与未知空间的边界)作为导航目标,驱动机器人进行探索。这类方法已被研究数十年,针对简单场景提出了多种贪心策略以提升探索效率。常见的前沿选择标准包括:
- 距离/代价:优先选择距离最近的前沿(如最近点法)。
- 效用:综合考虑前沿处可观测信息量(信息增益)与到达代价。
- 混合策略:将距离和效用加权组合,动态调整目标选择。
近年来,部分工作通过规划非贪心的长期路径,即在一次规划中覆盖更多前沿,显著提升了探索效率。这类方法通常依赖于精心设计的采样策略,在规划质量与计算效率之间取得平衡,并采用滚动时域(receding-horizon)方式分步执行长路径。
3.2 基于学习的方法
随着深度学习的发展,越来越多的研究尝试用深度强化学习(DRL)解决探索问题,通过训练策略最大化长期回报。早期的DRL探索器多基于卷积神经网络(CNN),在小规模环境中取得了一定效果,但由于输入尺寸固定,难以适应大规模或任意形状的环境,泛化能力有限,且实际表现往往不及先进的传统方法。
为克服上述局限,近期工作(包括作者团队的前作)提出基于图结构的注意力网络,将机器人认知状态编码为图,利用注意力机制捕捉长期依赖关系。实验表明,这类方法在性能和泛化性上均可媲美甚至超越传统规划器,并能较好地迁移到真实场景。
3.3 扩散模型在机器人领域的应用
扩散模型最初用于图像生成,近年来在多种生成任务中取得了突破性进展。其核心思想是对数据逐步加噪声,并训练神经网络逆向去噪,实现新数据的生成。为提升机器人学习能力,扩散模型已被应用于机械臂运动规划、视觉导航、避障等任务。
这些扩散式规划器通常以机器人的状态(如位姿、编码观测等)为条件,采样动作序列并迭代去噪,生成时序一致的高维动作序列。相比传统逐步决策,扩散模型能直接生成完整的未来动作序列,有助于提升动作的连贯性和长期规划能力。训练方式包括离线强化学习和行为克隆。其中,Diffusion Policy 通过建模条件动作分布,支持端到端训练与高效推理,满足机器人实时部署需求。
DARE的创新点在于:首次将扩散模型与图结构注意力编码结合,针对自主探索任务设计了高效的路径生成策略,并通过专家最优演示实现高质量模仿学习,兼顾了传统方法的高效性与学习方法的泛化。
4. 核心算法
4.1 基于图的环境建模
节点采样与图构建:在每个决策时刻,DARE会在当前已知的自由空间内,按照固定间隔均匀采样节点。这些节点代表机器人可能的候选位置。每个节点与其5x5邻域内的其他节点相连,前提是两节点之间存在无碰撞的直线路径。这样可以高效离散化动作空间,并通过边明确表示节点间的可达性。
图的作用:该无碰撞图不仅为路径规划提供了可行的轨迹空间,还能灵活适应任意形状和大小的环境。每个节点都可以作为机器人的候选视点或路点,机器人当前位置也总是对应于图中的某个节点。
动态更新:随着机器人探索的推进,环境认知不断扩展,图结构也会动态更新,始终反映机器人对环境的最新认知。
4.2 注意力编码器
多属性节点特征:每个节点不仅包含坐标信息,还包括信息增益(如可观测前沿数量)、路标(指示是否可达高效用节点)、占用情况(机器人是否在该节点)等属性。这些特征共同描述了节点在探索任务中的价值和作用。
自注意力机制:所有节点特征首先被投影到高维空间,然后输入到6层堆叠的自注意力网络。每一层都能捕捉节点与其邻居之间的依赖关系,充分建模图的连通性和空间结构。
交叉注意力融合:编码器最后将当前节点(即机器人当前位置)的特征与全局所有节点特征进行交叉注意力融合,得到一个综合反映机器人当前认知和环境结构的“置信特征”。这个特征作为扩散策略网络的输入,确保后续路径生成与环境状态紧密相关。
这种基于图的注意力编码方式,突破了传统CNN对输入尺寸的限制,能适应任意大小和形状的环境,并具备良好的仿真到现实泛化能力。
4.3 扩散策略生成路径
扩散模型生成动作序列:DARE采用扩散模型作为核心策略生成器。具体来说,模型首先从一个高斯噪声初始化的动作序列出发,通过多步去噪过程,逐步将噪声动作还原为合理的探索路径。每一步去噪都基于当前环境的编码特征进行条件生成,确保路径与当前认知状态高度相关。
动作定义与执行方式:在DARE中,机器人的每一步动作被定义为从当前位置出发,选择5x5邻域内的一个相邻节点(包括自身),用独热编码表示。每个动作序列对应未来若干步的节点跳转。模型会检查所选节点间是否存在无碰撞边,确保路径安全。
滚动时域执行与动态 replanning:虽然扩散模型一次可生成多步路径,但实际执行时,机器人只会执行前几步(如1步或少数几步),然后根据新的观测信息重新规划。这种“滚动时域”机制保证了机器人能灵活应对环境变化,提升了探索的实时性和鲁棒性。
路径映射与累积:去噪后的动作序列会被映射为节点间的实际位置变化,结合当前机器人位姿,累积得到完整的未来路径点序列。这样,机器人能获得一条明确的、可解释的探索轨迹。
避障机制:为防止生成路径出现碰撞,DARE在动作执行前会对路径进行碰撞检测,并在必要时进行简单的避障处理,确保至少当前要执行的动作段是安全的。
训练方式:扩散策略网络采用行为克隆(模仿学习)方式训练,目标是最大程度还原专家演示的最优路径。损失函数采用均方误差(MSE),鼓励模型生成的动作序列与专家路径尽量接近。
这种设计思路的优势在于:一方面,扩散模型能够一次性生成长时序的动作序列,具备全局规划能力;另一方面,滚动时域执行和动态 replanning 保证了局部的灵活性和对新信息的快速响应。结合图结构的环境编码,DARE能够在复杂、动态的未知环境中高效、智能地完成探索任务。
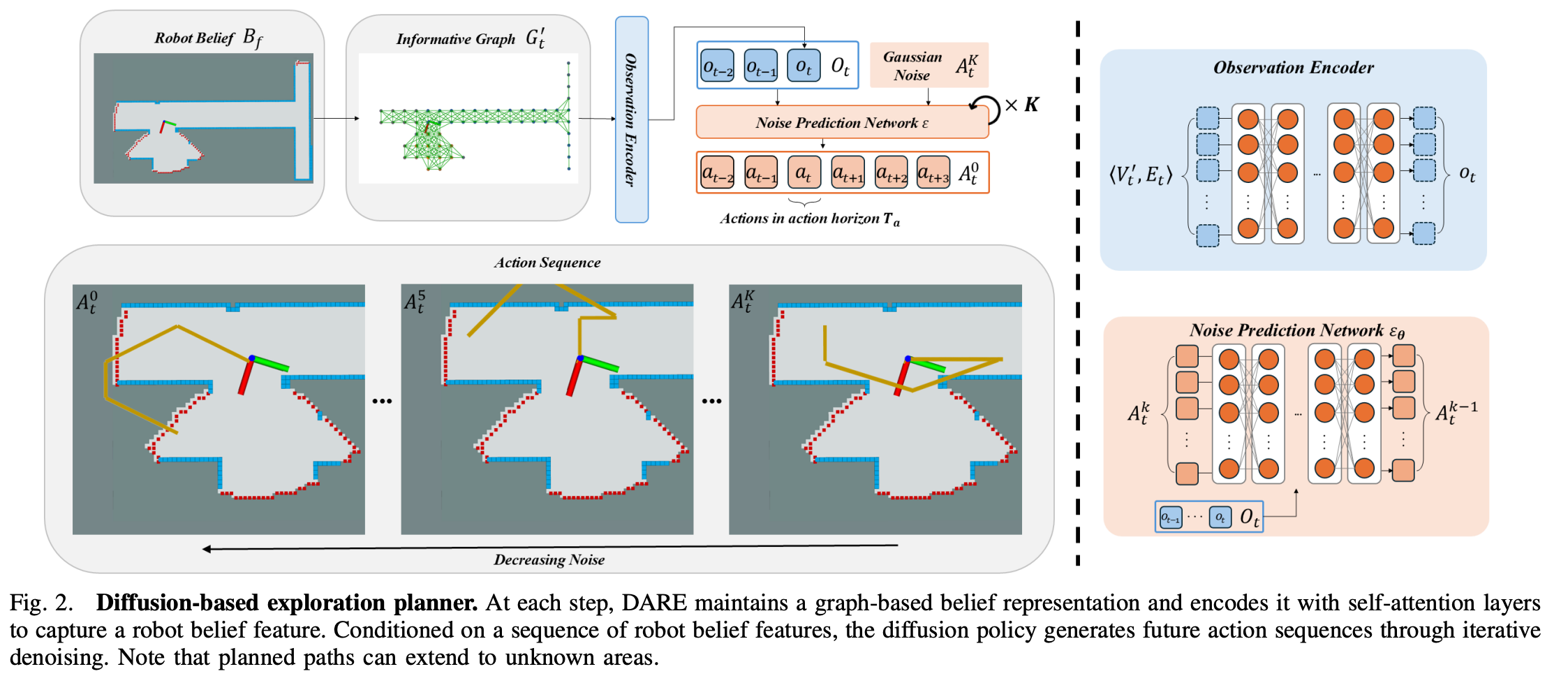
图2. 基于扩散的探索规划器。在每一步中,DARE 维护一个基于图的信念表示,并通过自注意力层对其进行编码,以捕捉机器人信念特征。在一系列机器人信念特征的条件下,扩散策略通过迭代去噪生成未来的动作序列。请注意,规划的路径可以延伸到未知区域。
4.4 专家最优演示
专家规划器设计:为获得高质量训练数据,DARE采用了基于真实地图的专家规划器。该规划器能够访问完整环境信息,将探索问题转化为覆盖问题,即寻找一条能覆盖所有未知区域边界(前沿)的最短路径。
覆盖路径生成流程:首先,在真实自由空间内构建无碰撞图,并识别所有需要观测的前沿节点。然后,采用约束采样方法,选取一组节点,保证机器人访问这些节点即可覆盖全部前沿。接着,通过求解旅行商问题(TSP),获得访问所有目标节点的最短路径。为提升路径质量,采样和TSP过程会多次迭代,最终选择最短的一条作为专家演示。
训练数据生成:通过上述流程,批量生成大量近似最优的探索路径,作为扩散模型的训练样本。这样,DARE能够学习到接近全局最优的探索策略,而不仅仅是模仿传统次优规划器。
优势与意义:这种专家演示方式不仅提升了模型的上限,还让扩散模型具备了推理未知区域结构的能力,有助于在实际复杂环境中实现高效探索。
5. 实验
5.1 与基线方法对比
- 测试集:100个未见过的模拟环境。
- 对比方法:最近点法、效用法、NBVP、TARE、Ariadne(DRL)、最优路径。
- 结果:DARE行进距离优于大多数基线,与TARE相当,且能准确预测未知区域结构。
| 方法 | 距离(米) | 与最优差距 |
|---|---|---|
| 最近点法 | 652(±76) | 30.6% |
| 效用法 | 585(±79) | 17.2% |
| NBVP | 645(±109) | 29.2% |
| TARE | 558(±67) | 11.8% |
| Ariadne | 579(±82) | 16.0% |
| DARE | 563(±71 ) | 12.8% |
| 最优 | 499(±61) | 0% |
表1. 各方法探索距离对比,DARE接近最优。
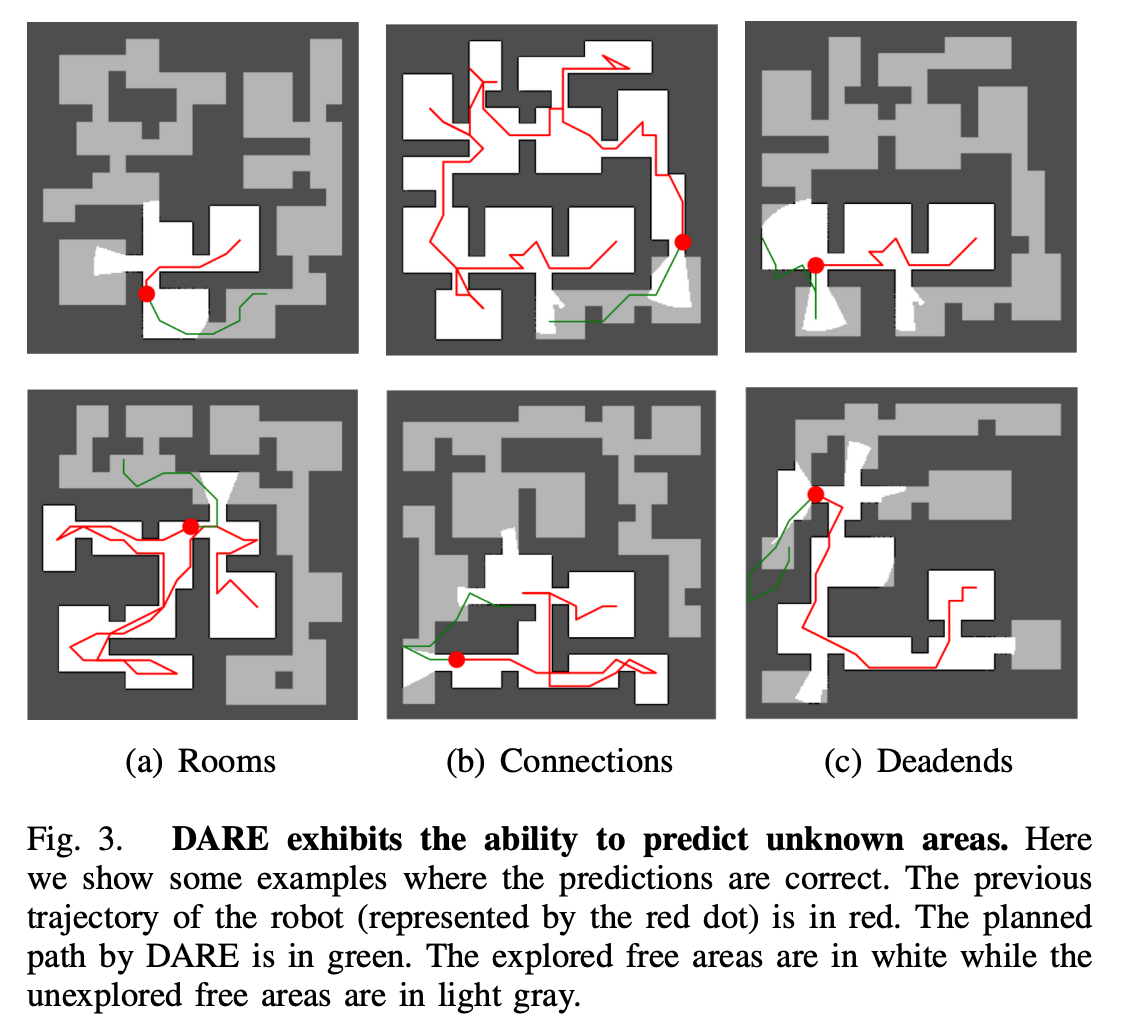
图3. DARE 展现了预测未知区域的能力。在这里,我们展示了一些预测正确的示例。机器人之前的轨迹(用红点表示)为红色。DARE 计划的路径为绿色。已探索的自由区域为白色,而未探索的自由区域为浅灰色。
5.2 Gazebo仿真与硬件实验
- 仿真环境:Gazebo+ROS,DARE与TARE对比,DARE探索速度更快。
- 真实机器人:Agilex Scout+16线激光雷达,DARE成功完成实验室探索任务,验证了现实可用性。
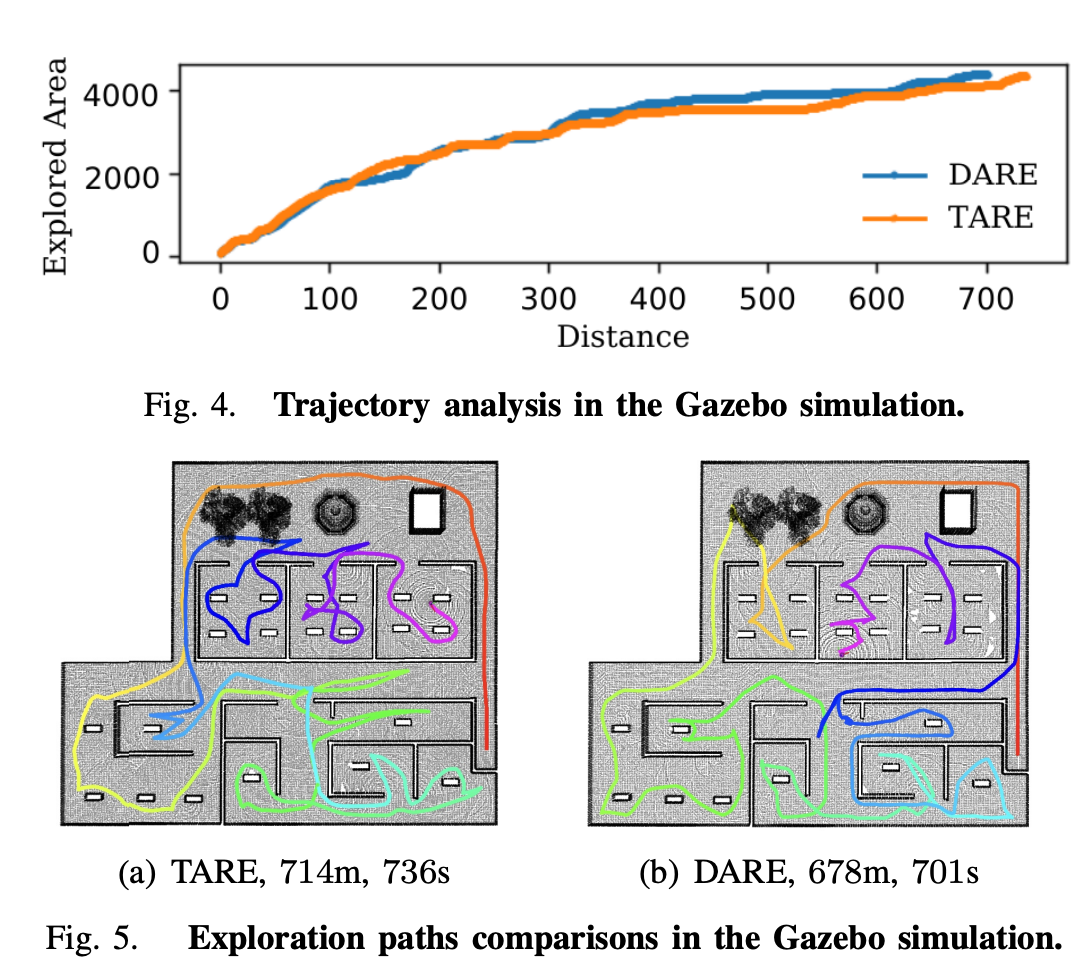
图4. Gazebo仿真轨迹分析。
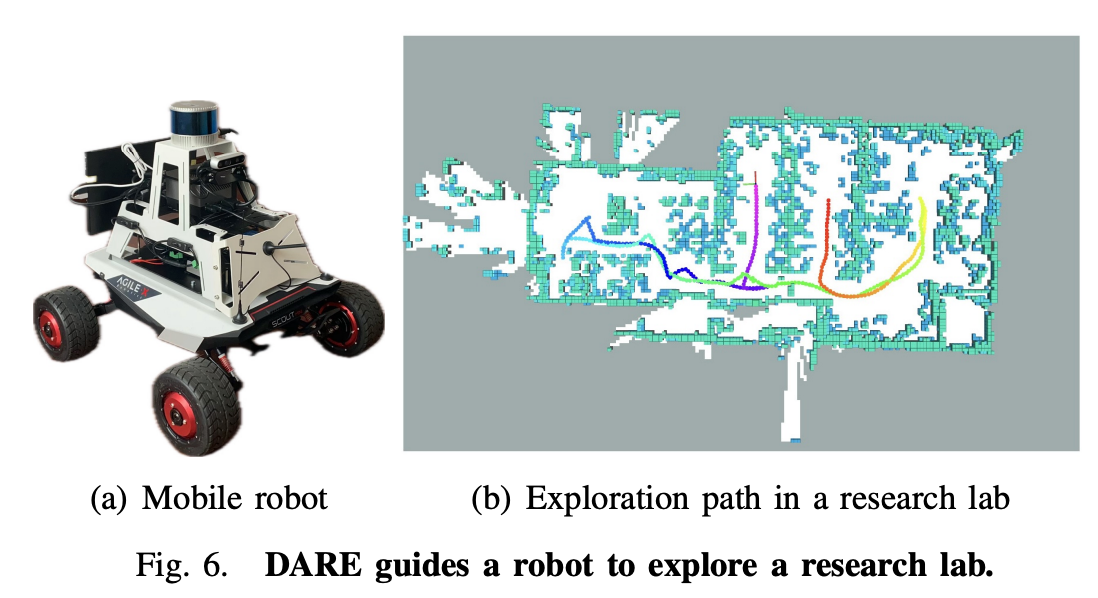
图6. DARE引导机器人探索实验室。
6. 结论
DARE首次将扩散模型引入自主机器人探索,结合图结构编码和专家最优演示,显著提升了探索效率和泛化能力。实验表明,DARE在模拟和现实环境中均表现优异,具备实际部署潜力。未来将进一步提升推理速度,并探索扩散模型在未知区域结构预测等方向的应用。