一、引言
论文首先阐述了当前大多 AI 系统是被动响应式交互,像 Siri、ChatGPT 等,用户提问后系统回答,接着等待下一个提示,这种基于命令的模式对于基础 AI 助手或许够用,但对于真正自主的机器,与人类交互的丰富动态性相差甚远。自主 AI 应能实时评估环境、预判用户需求,并确定以何种方式互动。例如,当用户在街上行走时,AI 可能会提醒他们注意未察觉的自行车,或者建议在附近一家隐蔽的咖啡馆停留。而语音作为最自然的交互方式,相比文本,语音能自然地进行注意力吸引、对话发起、紧急情况下的打断或重叠说话等,并且包含丰富的语音线索和情感细微差别。接着介绍了语音 AI 的发展历程,从早期的 Bell Labs 的 Audrey 到如今的 ChatGPT-4o 等,传统语音系统采用复杂模块化管道,现在基于大型语言模型(LLM)的简化管道设计虽能实现开放式对话,但也存在高延迟、丢失语音细微差别、交互方式仍为被动等局限。于是引出了 Voila,它旨在克服这些挑战,实现实时、自然、灵活的语音交互。
二、相关工作
(一)管道系统
早期语音助手系统,如 Siri、Alexa 和 Google Assistant,采用复杂的多阶段管道。通常先进行唤醒词检测,接着自动语音识别(ASR)将语音转文本,自然语言理解(NLU)分析文本确定用户意图,再由自然语言生成(NLG)组成回复,最后通过文本转语音(TTS)让助手发声。近期系统集成 LLM 简化管道,但多模块方法会导致延迟大,不适合低延迟实时应用,且音频转文本易丢失关键声学信息。
(二)端到端模型
旨在克服管道系统局限,直接处理音频表征,然后生成音频响应。一些模型用 Whisper 编码器将语音信号转嵌入,但其需完整输入序列才能处理,不适合实时流式场景。还有方法将连续音频信号编码为离散单元(音频令牌),再将这些单元纳入 LLM 词汇表进行训练,但存在需输出完整文本响应后才能生成语音输出导致延迟增加、文本和语音令牌传达相同语义但通常无法逐令牌对齐等问题。
(三)全双工模型
与端到端模型机械式轮流对话不同,全双工模型允许同时双向通信,模仿自然人际互动,可同时收听和说话,为自主互动奠定基础,如 Moshi 模型结合了多种思想,但其内省机制需特定配置支持不同任务,难以单一模型支持所有应用。而 Voila-autonomous 在集成 LLM 文本能力与新音频能力、易于定制化、统一建模多任务等方面具独特优势。
三、Voila 模型
(一)模型架构
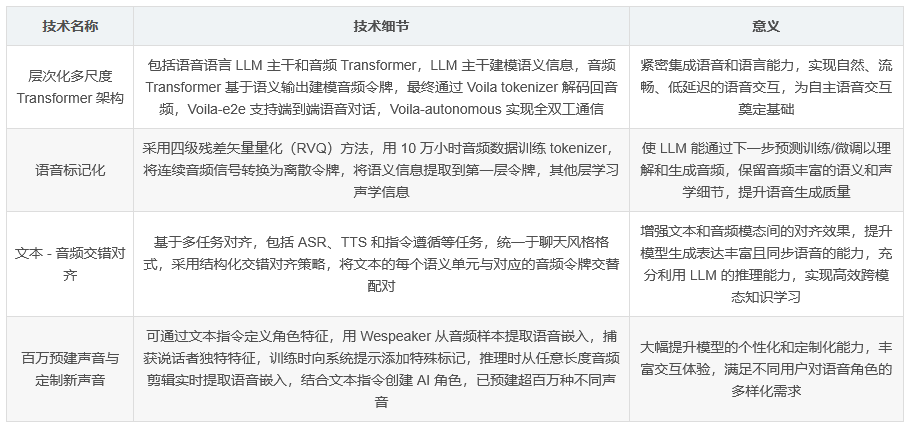
Voila 采用基于层次化多尺度 Transformer 的架构,包括语音语言 LLM 主干和音频 Transformer。其中,LLM 主干用于建模语义信息,音频 Transformer 基于 LLM 的语义输出建模音频令牌,最终由 Voila tokenizer 解码回音频。Voila-e2e 支持端到端语音对话,Voila-autonomous 则进一步扩展为全双工模型,可同时进行监听、推理和说话。
(二)语音标记化
通过将连续音频信号转换为离散令牌,使 LLM 能通过下一步预测进行训练/微调以理解和生成音频。将语义令牌和声学令牌相结合,采用四级残差矢量量化(RVQ)方法,用 10 万小时音频数据训练 tokenizer,其能将语义信息提取到第一层令牌,其他层学习声学信息。
(三)文本和音频对齐
多任务对齐 :将提取的离散音频令牌整合到 LLM 词汇表中,在自动语音识别(ASR)、文本转语音(TTS)和指令遵循等任务上训练模型,统一于聊天风格格式,以下一步预测为训练目标。如 ASR 输入输出序列为 “ 音频输入 文本输出 ”,模型生成对应转录;TTS 格式为 “ 文本输入 音频输出 ”,预测音频令牌。
文本 - 音频交错对齐 :采用结构化交错对齐策略,将文本的每个语义单元与对应的音频令牌交替配对。例如,对于口语输入 “Hello I am Voila”,输入序列编码为 “ ”,便于精细对齐,提升模型生成表达丰富且同步语音的能力。
(四)百万预建声音与定制新声音
Voila 可通过文本指令定义角色特征,还能从音频样本学习语音嵌入,捕获说话者的独特音色、语调和口音等特征,进而生成语音。训练时用 Wespeaker 提取所有带音频输出训练数据的说话者嵌入,对于涉及音频生成的任务,向系统提示添加三个特殊标记。推理时,可从任意长度的音频剪辑实时提取语音嵌入,结合文本指令创建能自然互动的 AI 角色,目前已预建超百万种不同声音。
四、实验
(一)Voila 基准测试
从五个常用 LLM 评估数据集中采样构建 Voila 基准测试,涵盖多领域,将样本转换为语音输入,用于全面评估语音 - 语言模型。如 MMLU 中各学科随机选样,MATH 数据集各主题选样等,共包含 66 个主题、1580 个样本。评估时,先用 Whisper 系统转录模型生成的语音,再用 GPT-4o 根据问题和参考答案给模型输出打分,结果显示 Voila 在与 SpeechGPT 和 Moshi 的对比中表现更优,尤其在数学和代码领域提升显著。
(二)ASR 和 TTS 评估
ASR :在 LibriSpeech test-clean 数据集上,以词错误率(WER)为指标,Voila 无论是否使用 LibriSpeech 训练数据,均展现出与顶尖 ASR 模型相当的性能,未使用时 WER 为 4.8%,使用时达 2.7%。
TTS :遵循 Vall-E 协议,用 HuBERT-Large 转录生成音频,Voila 在两种设置下 WER 分别为 3.2% 和 2.8%,优于其他模型。
五、结论
Voila 是一系列语音 - 语言基础模型,支持口语对话、ASR、TTS 等任务,通过语音标记化、层次化建模和音频 - 文本对齐创新,性能与顶尖模型相当或更优。其基于独特多尺度 Transformer 架构,紧密集成语音和语言能力,允许用户创建多样且富有表现力的语音角色,提升了交互质量,向着能作为人类活动中的主动和富有同理心的伙伴的自主语音 AI 迈进了重要一步,且模型和代码已公开以支持进一步研究。
Voila 论文核心技术汇总