机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
机器学习之深度学习神经网络入门
在人工智能技术浪潮席卷全球的今天,深度学习神经网络作为其核心驱动力,正以前所未有的速度重塑各行业格局。本文将以学习笔记的视角,系统梳理神经网络的基础概念与核心架构,为深入探索深度学习打下坚实基础。
一、神经网络的起源与发展
神经网络的理论雏形可追溯至 1943 年 McCulloch 和 Pitts 提出的MP 神经元模型,该模型首次将生物神经元的工作机制抽象为数学计算单元。在 20 世纪 80 年代,反向传播算法(Backpropagation)的提出推动神经网络进入第一次发展高峰,在光学字符识别(OCR)等领域取得显著成果。但受制于当时有限的计算资源和梯度消失问题,90 年代后期神经网络逐渐陷入发展瓶颈。
转折点出现在 2006 年,Hinton 等人提出深度信念网络(DBN)和预训练 - 微调策略,结合 GPU 算力的爆发式增长,神经网络迎来复兴。如今,基于 Transformer 架构的大语言模型(如 GPT 系列)、计算机视觉领域的卷积神经网络(CNN),以及自动驾驶中的端到端神经网络系统,都印证了其强大的泛化能力与应用潜力。
二、神经元模型
(一)生物神经元与数学模型对比
| 对比维度 | 生物神经元 | 数学神经元模型 |
|---|---|---|
| 结构特征 | 由树突(接收信号)、细胞体(整合信号)、轴突(输出信号)构成 | 由权重矩阵、偏置向量和激活函数组成计算单元 |
| 信号传输 | 通过电信号与化学递质传递脉冲信号 | 通过矩阵乘法和非线性变换传递数值信号 |
| 信息处理 | 非线性加权求和并阈值化输出 | 通过 z = ∑ i = 1 n w i x i + b z = \sum_{i=1}^{n}w_ix_i + b z=∑i=1nwixi+b 计算加权和,再经激活函数处理 |
(二)数学模型示例
以电商平台商品需求预测为例,构建单神经元模型:
输入层:接收商品价格 x x x(如 x = 99 x = 99 x=99 元)
计算过程:
加权求和: z = w x + b z = wx + b z=wx+b,假设 w = 0.3 w = 0.3 w=0.3, b = − 5 b = -5 b=−5,则 z = 0.3 × 99 − 5 = 24.7 z = 0.3 \times 99 - 5 = 24.7 z=0.3×99−5=24.7
激活函数:采用 sigmoid 函数 a = 1 1 + e − z = 1 1 + e − 24.7 ≈ 1 a = \frac{1}{1 + e^{-z}} = \frac{1}{1 + e^{-24.7}} \approx 1 a=1+e−z1=1+e−24.71≈1
输出层:输出值 a a a 代表商品成为爆款的概率(接近 1 表明高可能性)
该过程通过调整权重 w w w 和偏置 b b b(训练过程),使模型预测与实际销售数据匹配,从而实现需求预测。
三、神经网络性能与数据量、硬件的关系
| 模型类型 | 数据需求特征 | 性能曲线特点 | 典型应用场景 |
|---|---|---|---|
| 传统 AI 算法 | 依赖人工特征工程,数据规模 < 1 万条 | 线性增长后趋于饱和 | 规则明确的结构化数据处理 |
| 小型神经网络 | 数据规模 1 万 - 10 万条 | 初期提升快,后期出现过拟合 | 简单图像分类(MNIST 数据集) |
| 中型神经网络 | 数据规模 10 万 - 100 万条 | 保持稳定性能提升 | 医疗影像辅助诊断 |
| 大型神经网络 | 数据规模 > 100 万条 | 呈指数级性能提升 | 自然语言处理(BERT 模型) |
硬件层面,GPU 的并行计算能力使神经网络训练效率提升数百倍。以 ResNet - 50 模型为例,在 CPU 上训练 ImageNet 数据集需耗时数周,而使用 NVIDIA A100 GPU 仅需 1 - 2 天。
四、神经网络架构
(一)基本架构
每个神经元通过连接权重与下一层交互,如输入层到隐藏层的连接可表示为:
[ a 1 ( 1 ) a 2 ( 1 ) ] = [ σ ( w 11 ( 0 ) x 1 + w 12 ( 0 ) x 2 + b 1 ( 0 ) ) σ ( w 21 ( 0 ) x 1 + w 22 ( 0 ) x 2 + b 2 ( 0 ) ) ] \begin{bmatrix} a_1^{(1)} \\ a_2^{(1)} \\ \end{bmatrix} = \begin{bmatrix} \sigma(w_{11}^{(0)}x_1 + w_{12}^{(0)}x_2 + b_1^{(0)}) \\ \sigma(w_{21}^{(0)}x_1 + w_{22}^{(0)}x_2 + b_2^{(0)}) \\ \end{bmatrix} [a1(1)a2(1)]=[σ(w11(0)x1+w12(0)x2+b1(0))σ(w21(0)x1+w22(0)x2+b2(0))]
其中, σ \sigma σ 为激活函数, w ( l ) w^{(l)} w(l) 为第 l l l 层权重, b ( l ) b^{(l)} b(l) 为偏置。
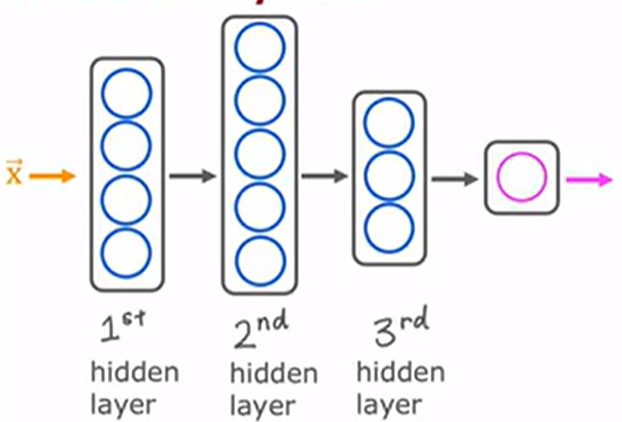
(二)多层隐藏层
随着隐藏层增加,网络表达能力呈指数级增长:
2 层隐藏层:可拟合复杂非线性边界,如手写数字识别
3 - 5 层隐藏层:适用于图像语义分析(识别图片中的多物体)
10 层以上:在 Transformer 架构中实现长距离依赖建模(如机器翻译)
但层数增加会引入梯度消失 / 爆炸问题,需通过残差连接(Residual Connection)、批量归一化(Batch Normalization)等技术优化。
深度学习神经网络通过模拟人类大脑的信息处理机制,在理论与实践的双重驱动下不断进化。后续学习将聚焦于网络训练的优化算法(如 Adam、Adagrad)、正则化技术(Dropout、L1/L2 范数)以及经典网络架构(CNN、RNN、Transformer)的具体实现,进一步解锁其在复杂任务中的应用潜力。
continue…