Title
题目
Large-scale benchmarking and boosting transfer learning for medical imageanalysis
医学图像分析中的大规模基准测试与增强迁移学习
01
文献速递介绍
将在大规模摄影数据集(如ImageNet)上预训练的模型微调至医学图像领域(Tajbakhsh等人,2016;Shin等人,2016;Matsoukas等人,2022)仍然是克服医学成像中标注数据稀缺问题的实际主流方法(Tajbakhsh等人,2021)。尽管近年来出现了探索使用医学数据进行替代预训练方法的趋势(Zhou等人,2019;Haghighi等人,2021;Ghesu等人,2022;Mei等人,2022),但在可预见的未来,这一主流趋势仍将持续,主要原因有两点: 首先,针对各种主干网络的摄影预训练模型(尤其是有监督的ImageNet模型)易于获取(Horn等人,2021),且性能优于从头训练的模型(见图1)。 其次,与视觉上通常同质化的医学图像相比,摄影图像固有的形状、纹理和颜色多样性使ImageNet模型能够学习到更丰富的视觉表征,这对于有效识别医学应用中的不同感兴趣对象(即病变或器官)至关重要(Geirhos等人,2019;Matsoukas等人,2022)。正如Zhou等人(2021b)、Ke等人(2021)和Ali等人(2022)的研究所示,在包括胸部疾病识别、肺栓塞、皮肤癌和阿尔茨海默病等多种医学应用中,许多顶尖性能的模型均基于有监督的ImageNet模型微调而来。 近年来,大量采用不同策略在各种数据集上预训练的异构架构模型不断涌现。然而,缺乏对这些模型向医学任务迁移能力的全面评估,导致从业者难以选择最合适的预训练模型,同时遗留了若干关键问题尚未解答。为此,我们在医学视觉任务的迁移学习场景下开展了大规模实证研究(约5000次实验),设计了一系列系统性实验以探索以下研究问题及贡献: ### 问题1:预训练ConvNets与视觉Transformer在医学成像任务中谁的迁移能力更强? 计算机视觉领域关于视觉Transformer与卷积神经网络(ConvNets)优劣的争论近期倾向于认为Transformer是ConvNets的可行替代方案(Xiao等人,2023)。然而,由于缺乏在医学视觉领域对两者效能的广泛比较,我们尚不清楚是否可以直接转向使用Transformer。为填补这一空白,我们开展了一项广泛研究(约1400次实验),在多种医学任务上对众多传统及现代ConvNet和视觉Transformer架构进行基准测试。结果表明,ConvNeXt(Liu等人,2022)这一现代化ConvNet模型不仅超越传统ConvNets,还在多种医学任务中优于Swin(Liu等人,2021)等先进视觉Transformer,凸显了ConvNets在医学成像中的持续价值与有效性(见3.1节、图2和图3)。 ### 问题2:预训练ConvNets与视觉Transformer在医学成像任务中谁的标注效率更高? 近期研究表明,在部分医学应用中,预训练视觉Transformer在使用大量标注数据微调时性能优于ConvNets(Matsoukas等人,2021;Xiao等人,2023)。然而,缺乏针对不同规模微调数据(从小规模到大规模)下ConvNets与Transformer行为的全面基准测试,导致我们对两者在标注数据稀缺的医学任务中的迁移效能理解不足。为此,我们开展了系统性研究(约400次实验),探究微调数据规模(100至36.8万样本)对两类模型性能的影响。结果表明:在医学任务微调中,ConvNets的标注效率显著高于Transformer,而Transformer在数据充足时具备与ConvNets竞争的潜力(见3.2节、图4和图5)。 ### 问题3:与粗粒度数据相比,细粒度数据预训练模型在医学成像迁移学习中有何优势? 现有医学成像研究主要使用ImageNet-1K数据集预训练模型,该数据集面向粗粒度目标分类(Mustafa等人,2021;Azizi等人,2021;Matsoukas等人,2022)。然而,利用大规模细粒度数据集预训练模型在医学成像迁移学习中的潜在优势尚未充分探索。我们通过广泛研究(约500次实验)评估了iNat2021(Horn等人,2021)、ImageNet-22K(Ridnik等人,2021)、Places365(Zhou等人,2017)和COCO(Lin等人,2014)等4个细粒度数据集作为预训练源的效果(见表1)。结果发现:在数据粒度更细、多样性更高的数据集上预训练的模型能学习到更具判别性的局部表征,这对依赖纹理细微变化检测/分割病变和器官的医学任务至关重要(见3.3节和图6)。 ### 问题4:与有监督ImageNet模型相比,自监督ImageNet模型在医学成像任务中的泛化能力如何? 自监督学习(SSL)的快速发展催生了性能超越传统有监督ImageNet模型的新一代自监督模型(Caron等人,2020;Ericsson等人,2021;Zhao等人,2021;Caron等人,2021;Xie等人,2021b)。尽管大量先进自监督模型已公开可用,但缺乏对其在多模态医学成像任务中迁移能力的大规模评估。我们通过深度基准测试(约2000次实验),评估了22种不同训练目标的近期自监督方法在X光、超声、CT和眼底图像等多模态医学任务中的效能。结果表明:自监督ImageNet模型比有监督模型更有效地学习整体特征,在医学任务中展现出更强的泛化能力(见3.4节和图7)。 ### 问题5:医学数据集的专家标注如何增强ImageNet模型捕捉领域相关语义信息的能力? ImageNet预训练模型是医学成像迁移学习的主流选择,但其与医学图像的固有领域差异,以及ImageNet与医学任务在识别目标上的不同,导致模型难以有效捕捉疾病和器官相关的关键语义特征(Raghu等人,2019;Azizi等人,2021;Mei等人,2022)。为此,我们探索了领域自适应预训练(源自自然语言处理,Pan和Yang,2010;Glorot等人,2011)在摄影与医学数据集上的有效性,利用先进Transformer和ConvNet架构开发了多种领域自适应模型,并在广泛医学任务中进行评估(约400次实验)。结果表明:领域自适应模型通过融合ImageNet知识与医学数据集的专家标注信息,显著提升了模型性能(见3.5节、图8和图9)。 ### 论文结构 第2节介绍迁移学习框架,包括下游任务与数据集(2.1节)、预训练模型(2.2节)及微调设置与评估(2.3节); 第3节分专题(3.1-3.5节)详细阐述各研究问题的动机、实验设计、结果与分析; 第4节展开深度讨论,涵盖: (i)RadImageNet与ImageNet预训练效能对比(4.1节); (ii)领域内自监督学习与监督学习效果比较(4.2节); (iii)领域内/外数据预训练的自监督模型迁移能力(4.3节); (iv)ConvNets与Transformer在压力测试下的鲁棒性(4.4节); (v)卷积-Transformer混合模型的迁移能力(4.5节); (vi)分割架构消融研究(4.6节); (vii) pretext任务设计与数据粒度对自监督模型迁移的影响(4.7节); (viii)高性能但高计算成本的Transformer与ConvNets的权衡(4.8节); (ix)研究结果在临床场景的实用价值(4.9节); (x)研究局限性与未来方向(4.10节)。
Aastract
摘要
Transfer learning, particularly fine-tuning models pretrained on photographic images to medical images, hasproven indispensable for medical image analysis. There are numerous models with distinct architecturespretrained on various datasets using different strategies. But, there is a lack of up-to-date large-scale evaluationsof their transferability to medical imaging, posing a challenge for practitioners in selecting the most properpretrained models for their tasks at hand. To fill this gap, we conduct a comprehensive systematic study,focusing on (i) benchmarking numerous conventional and modern convolutional neural network (ConvNet) andvision transformer architectures across various medical tasks; (ii) investigating the impact of fine-tuning datasize on the performance of ConvNets compared with vision transformers in medical imaging; (iii) examiningthe impact of pretraining data granularity on transfer learning performance; (iv) evaluating transferabilityof a wide range of recent self-supervised methods with diverse training objectives to a variety of medicaltasks across different modalities; and (v) delving into the efficacy of domain-adaptive pretraining on bothphotographic and medical datasets to develop high-performance models for medical tasks. Our large-scalestudy (∼5,000 experiments) yields impactful insights: (1) ConvNets demonstrate higher transferability thanvision transformers when fine-tuning for medical tasks; (2) ConvNets prove to be more annotation efficient thanvision transformers when fine-tuning for medical tasks; (3) Fine-grained representations, rather than high-levelsemantic features, prove pivotal for fine-grained medical tasks; (4) Self-supervised models excel in learningholistic features compared with supervised models; and (5) Domain-adaptive pretraining leads to performantmodels via harnessing knowledge acquired from ImageNet and enhancing it through the utilization of readilyaccessible expert annotations associated with medical datasets.
迁移学习,尤其是将在摄影图像上预训练的模型微调至医学图像领域,已被证明在医学图像分析中不可或缺。目前存在许多具有不同架构的模型,这些模型通过不同策略在各种数据集上进行了预训练。然而,缺乏针对其向医学成像领域迁移能力的最新大规模评估,这给从业者为手头任务选择最合适的预训练模型带来了挑战。 为填补这一空白,我们开展了一项全面的系统性研究,重点关注以下方面: (i)在各种医学任务中对众多传统和现代卷积神经网络(ConvNet)与视觉Transformer架构进行基准测试; (ii)研究在医学成像中,微调数据规模对卷积神经网络与视觉Transformer性能的影响; (iii)检验预训练数据粒度对迁移学习性能的影响; (iv)评估具有不同训练目标的近期自监督方法对跨不同模态的各种医学任务的迁移能力; (v)深入探讨在摄影和医学数据集上进行领域自适应预训练的有效性,以开发适用于医学任务的高性能模型。 我们的大规模研究(约5000次实验)得出了以下具有影响力的见解: (1)在针对医学任务进行微调时,卷积神经网络比视觉Transformer表现出更高的迁移能力; (2)在医学任务的微调过程中,卷积神经网络被证明比视觉Transformer具有更高的标注效率; (3)对于细粒度医学任务,细粒度表示(而非高级语义特征)是关键; (4)与监督模型相比,自监督模型在学习整体特征方面表现更优; (5)领域自适应预训练通过利用从ImageNet获取的知识,并通过使用与医学数据集相关的易获取专家标注对其进行增强,从而生成高性能模型。
Conclusion
结论
We provide a fine-grained and up-to-date study on the transferability of various brand-new pretraining techniques for medical imagingtasks, answering central and timely questions on transfer learning inmedical image analysis. We summarize the key findings from our broadsystematic study (∼5000 experiments) as follows:ConvNeXt variants compete favorably against their Swin counterparts in both transfer learning and in training from scratchsettings, emphasizing the continued relevance and effectivenessof ConvNets in medical imaging.ConvNets exhibit greater annotation efficiency than vision transformers when fine-tuned for medical imaging tasks, yet visiontransformers have the potential to surpass ConvNets when substantial data is available for fine-tuning.Fine-grained pretrained models outperform the coarse-grainedsupervised ImageNet model, offering a viable alternative fortransfer learning in fine-grained medical tasks.Self-supervised learning approaches excel in capturing holistic features effectively, leading to higher transferability compared with supervised approaches across diverse medical imaging tasks.Our proposed domain adaptive pretraining approach can harnessknowledge acquired from ImageNet and enhance it by utilizationof readily accessible expert annotations associated with medicaldatasets, leading to the development of more performant modelswith domain-relevant information in their learned embeddings.In closing, we hope that this large-scale open evaluation of transferlearning can direct the future research of deep learning for medicalimaging.
我们针对医学成像任务中各种全新预训练技术的迁移能力进行了细粒度且与时俱进的研究,解答了医学图像分析迁移学习领域的核心及时问题。我们从大规模系统性研究(约5000次实验)中总结出以下关键发现: 1. ConvNeXt变体在迁移学习和从头训练场景中均优于对应的Swin模型,凸显了ConvNets在医学成像中的持续价值与有效性。 2. ConvNets在医学成像任务微调中展现出更高的标注效率,而视觉Transformer在具备大量微调数据时具备超越ConvNets的潜力。 3. 细粒度预训练模型性能优于粗粒度有监督ImageNet模型,为细粒度医学任务的迁移学习提供了可行替代方案。 4. 自监督学习方法更擅长有效捕捉整体特征,在各类医学成像任务中展现出比有监督方法更强的迁移能力。 5. 我们提出的领域自适应预训练方法能够融合ImageNet知识,并通过利用医学数据集的专家标注信息增强模型,使其在学习嵌入中包含领域相关信息,从而构建性能更优的模型。 最后,我们希望这项大规模迁移学习开放评估能够为医学成像深度学习的未来研究提供方向。
Figure
图
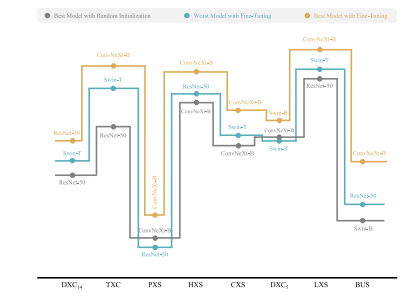
Fig. 1. Fine-tuning various ImageNet pretrained models with popular network architectures yields superior performance over training the target models from randominitialization for a diverse set of medical applications, underscoring the importanceof transfer learning in medical imaging
图1. 对于多种医学应用场景,使用流行网络架构的ImageNet预训练模型进行微调,其性能优于从随机初始化开始训练目标模型,这凸显了迁移学习在医学成像中的重要性。
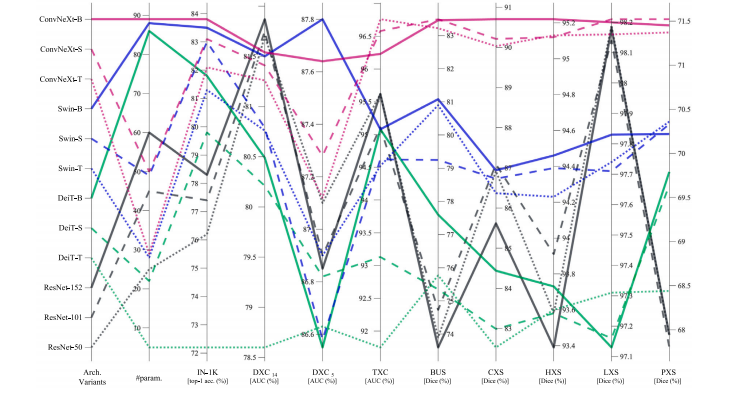
Fig. 2. Comparison of transfer learning from supervised ImageNet models across conventional and modern ConvNet and vision transformer architectures. ConvNext, among allarchitectural designs under study, consistently showcases superior performance within the majority of the target tasks, underscoring its potential for creating high-performancemodels for medical imaging applications. Specifically, the ConvNext-B pretrained model behaves consistently across all tasks, compared with the erratic patterns displayed by otherpretrained models. In this parallel coordinate plot, four variables — architecture variants, the number of parameters in each pretrained model, ImageNet top-1 accuracy, andperformance on various medical downstream tasks — have been covered. ‘‘Arch.’’ and ‘‘IN Acc’’ denote architecture and top-1 accuracy on ImageNet, respectively. Furthermore,to distinguish between model families, consistent color schemes (gray for ResNet-{50, 101, 152}, green for DeiT-{T, S, B}, blue for Swin-{T, S, B}, and purple for ConvNeXt-{T,S, B}) have been used. Within each family, to distinguish different parameter sizes, different patterns have been used: models with fewer parameters have ‘‘dotted lines’’, thosewith a moderate number of parameters have ‘‘dashed lines’’, and those with more parameters have ‘‘solid lines’’.
图2. 有监督ImageNet模型在传统及现代ConvNet与视觉Transformer架构中的迁移学习性能对比。在所有研究的架构设计中,ConvNeXt在大多数目标任务中始终表现出更优性能,突显其在医学成像应用中构建高性能模型的潜力。具体而言,与其他预训练模型表现出的不稳定模式不同,ConvNeXt-B预训练模型在所有任务中性能表现一致。在此平行坐标图中,涵盖了四个变量:架构变体、各预训练模型的参数数量、ImageNet top-1准确率以及在各类医学下游任务上的性能。“Arch.”和“IN Acc”分别表示架构和ImageNet top-1准确率。此外,为区分模型系列,采用了统一的配色方案(灰色代表ResNet-{50, 101, 152},绿色代表DeiT-{T, S, B},蓝色代表Swin-{T, S, B},紫色代表ConvNeXt-{T, S, B})。在每个模型系列中,为区分不同参数规模,使用了不同线型:参数较少的模型用“虚线”表示,参数中等的用“短虚线”表示,参数较多的用“实线”表示。
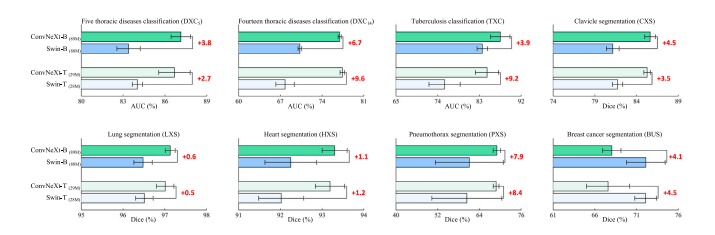
Fig. 3. Comparison of training target models with different architectures from random initialization. ConvNet variants (i.e. ConvNeXt-T and ConvNeXt-B) excel in all tasks exceptBUS, achieving either the best or second-best performance compared with Swin variants. This demonstrates the stronger inductive biases inherent to ConvNets, leading to higherefficacy in medical imaging tasks with limited annotated data compared with vision transformers. The bar charts group architectures with a similar number of parameters: (1)Swin-T and ConvNeXt-T, and (2) Swin-B and ConvNeXt-B. Model names are listed on the 𝑦-axis of the left-most figure in both rows. Different colors are used to distinguish eachmodel, with the same architecture family sharing the same color (green for the ConvNeXt family and blue for the Swin family) but with different hues for their variants (lighterfor models in the first group with fewer parameters and sharper for models in the second group with more parameters). The 𝑥-axis represents the performance metric used forevaluation in each task: AUC for classification tasks and Dice for segmentation tasks.
图3. 不同架构目标模型从随机初始化开始的训练性能对比。除腹部超声(BUS)任务外,ConvNet变体(如ConvNeXt-T和ConvNeXt-B)在所有任务中均表现优异,与Swin变体相比,其性能要么最优,要么次优。这表明ConvNets固有的归纳偏置更强,因此在标注数据有限的医学成像任务中,其效能优于视觉Transformer。条形图按参数规模对架构进行分组:(1)Swin-T和ConvNeXt-T,(2)Swin-B和ConvNeXt-B。每行最左侧图表的y轴列出了模型名称,相同架构家族使用同色系(ConvNeXt家族为绿色,Swin家族为蓝色),但不同变体通过色调区分(第一组参数较少的模型色调较浅,第二组参数较多的模型色调较深)。x轴表示各任务中用于评估的性能指标:分类任务为AUC,分割任务为Dice系数。
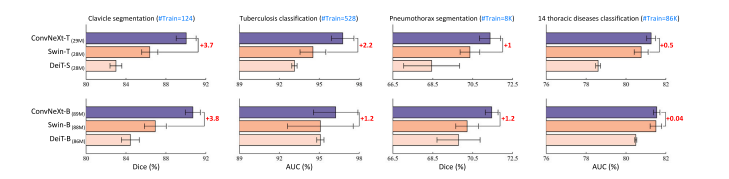
Fig. 4. Fine-tuning data size plays a vital role in bridging the performance gap between ConvNets and vision transformers in medical imaging tasks. As seen, increasing the amountof fine-tuning data from the left most subfigure (clavicle segmentation with a small amount of fine-tuning data) to the right most subfigure (14 thoracic diseases classificationwith a substantially higher amount of fine-tuning data) leads to a decrease in the performance gap between ConvNet (i.e. ConvNeXt) and transformer (i.e. Swin and DeiT) models.Particularly, in the top row of the figure, increasing the amount of fine-tuning data narrows the performance gap between ConvNeXt-T and Swin-T for all tasks. Similarly, in thebottom row of the figure, the performance gap between ConvNeXt-B and the best performing transformer, either Swin-B or DeiT-B, decreases as the amount of fine-tuning dataincreases. These findings highlight the annotation efficiency advantage offered by pretrained ConvNet models in medical imaging tasks
图4. 微调数据规模对弥合医学成像任务中ConvNets与视觉Transformer的性能差距至关重要。如图所示,将微调数据量从最左侧子图(少量数据的锁骨分割任务)增加到最右侧子图(大量数据的14类胸部疾病分类任务)时,ConvNet(如ConvNeXt)与Transformer(如Swin和DeiT)模型之间的性能差距逐渐缩小。具体而言: - 上排子图:随着微调数据量增加,ConvNeXt-T与Swin-T在所有任务中的性能差距均缩小。 - 下排子图:ConvNeXt-B与表现最佳的Transformer模型(Swin-B或DeiT-B)之间的性能差距也随数据量增加而减小。 这些结果凸显了预训练ConvNet模型在医学成像任务中标注效率更高的优势——即在数据有限时性能更优,而数据充足时与Transformer的差距逐渐缩小。
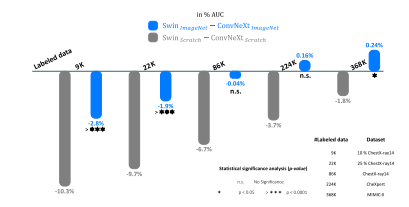
Fig. 5. Size of the training dataset impacts ConvNet and vision transformer modelsin both training from scratch and transfer learning settings. As seen, when trainedfrom scratch, ConvNeXt-B model displays consistent superiority over Swin-B, with theperformance gap narrowing as the dataset size increases. Conversely, in the transferlearning setup, Swin-B initially lags behind ConvNeXt-B but gradually overtakes it as thefine-tuning dataset size grows. These results highlight the superior annotation efficiencyof ConvNets compared with vision transformers, and also underscore the visiontransformers’ potential for medical imaging tasks when abundant data is available.
图5. 训练数据集规模对ConvNet和视觉Transformer模型在从头训练与迁移学习场景下的影响 如图所示: - 从头训练场景:ConvNeXt-B模型始终优于Swin-B,且随着数据集规模增大,两者性能差距逐渐缩小。 - 迁移学习场景:Swin-B在微调数据量较小时落后于ConvNeXt-B,但随着数据量增加,其性能逐渐反超。 这些结果进一步验证了ConvNets相比视觉Transformer标注效率更高的特性(即数据稀缺时表现更优),同时也表明:当医学任务拥有充足标注数据时,视觉Transformer具备超越ConvNets的潜力。
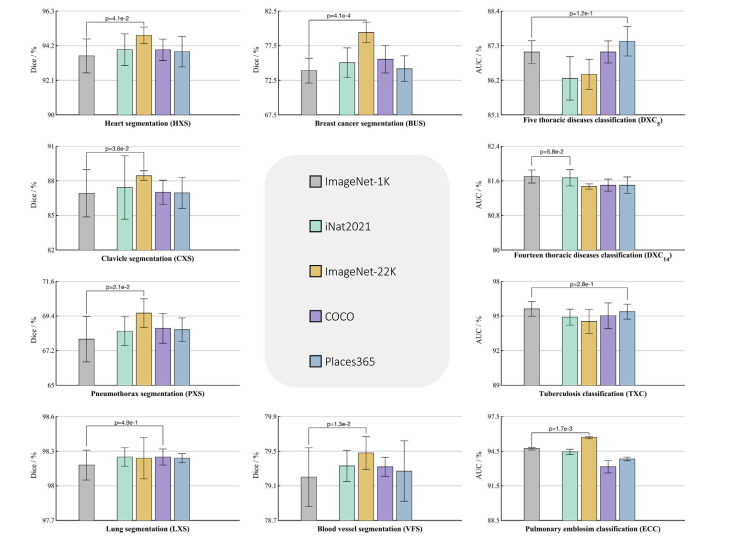
Fig. 6. Fine-tuning the models pretrained on large-scale finer grained datasets, namely iNat2021, ImageNet-22K, COCO, and Places365, offers a promising alternative to thede-facto ImageNet-1K pretrained model for fine-grained medical applications. As seen, all fine-grained models consistently outperform the ImageNet-1K model across all sixsemantic segmentation tasks. Moreover, the top-performing fine-grained models excel in ECC and DXC5 classification tasks, while performing on par with the ImageNet-1K modelin TXC and DXC14 classification tasks. These results highlight that pretrained models on fine-grained data capture subtle features that empower fine-grained medical imaging tasks.
图6. 在大规模细粒度数据集(如iNat2021、ImageNet-22K、COCO和Places365)上预训练的模型进行微调,为细粒度医学应用提供了替代主流ImageNet-1K预训练模型的有效方案。如图所示: - 语义分割任务:所有细粒度预训练模型在全部六项语义分割任务中均一致优于ImageNet-1K模型。 - 分类任务:表现最佳的细粒度模型在ECC(栓塞分类)和DXC5(5类胸部疾病分类)任务中显著领先,而在TXC(胸部分类)和DXC14(14类胸部疾病分类)任务中与ImageNet-1K模型性能相当。 这些结果表明,细粒度数据预训练模型能够捕捉细微特征,显著提升细粒度医学成像任务(如病变检测与器官分割)的性能,凸显了数据粒度对医学迁移学习的关键影响。
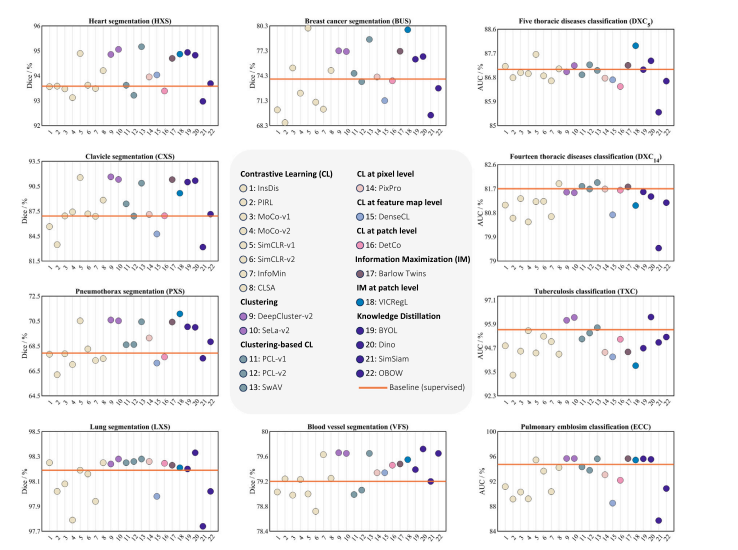
Fig. 7. Self-supervised learners can capture holistic features more effectively than their supervised counterparts, resulting in more generalizable representations for a variety ofmedical imaging tasks. As seen, a majority of self-supervised ImageNet models outperform supervised models in terms of mean performance across at least three target tasks.This underscores the greater transferability of self-supervised representation learning. Notably, recent approaches such as DINO, SwAV, Barlow Twins, SeLa-v2, and DeepCluster-v2consistently outperform the supervised ImageNet model in (almost) all target tasks. For ease of reference, each of the 22 self-supervised methods is now categorized into ninemain groups, with each group represented by a distinct color in the plots. The methods are listed in numerical order from left to right
图7. 自监督学习模型相比有监督模型能够更有效地捕捉整体特征,从而为各种医学成像任务提供更具泛化性的表征。如图所示,大多数自监督ImageNet模型在至少三个目标任务的平均性能上优于有监督模型,这凸显了自监督表征学习更强的迁移能力。值得注意的是,近期方法如DINO、SwAV、Barlow Twins、SeLa-v2和DeepCluster-v2在(几乎)所有目标任务中始终优于有监督ImageNet模型。为便于参考,22种自监督方法被划分为九个主要组,每组在图中以不同颜色表示,方法按从左到右的顺序编号排列。
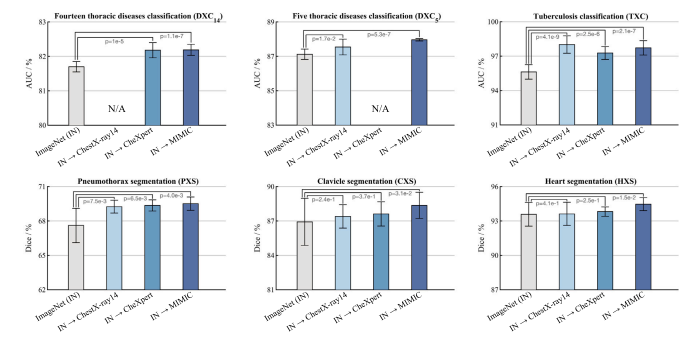
Fig. 8. Domain-adaptive pretraining serves as a vital bridge between the photographic and medical imaging domains, leading to improved performances compared with thestandard ImageNet pretraining in all target tasks. Particularly, ImageNet→ChestX-ray14 and ImageNet→CheXpert domain-adapted models exhibit significantly better performance(𝑝 < 0.05) compared with the standard ImageNet pretrained model in DXC14, DXC5 , TXC, and PXS, and comparable performance in CXS and HXS target tasks. Furthermore,increasing the amount of in-domain data through the utilization of the MIMIC-CXR dataset results in significant gaps (𝑝 < 0.05) between domain-adapted (ImageNet→MIMIC) andImageNet models in all target tasks, highlighting the crucial role of the data scale in effectively bridging the gap between photographic and medical images.
图8. 领域自适应预训练是摄影图像与医学成像领域之间的重要桥梁,与标准ImageNet预训练相比,其在所有目标任务中均提升了性能。具体而言: - ImageNet→ChestX-ray14和ImageNet→CheXpert领域自适应模型在DXC14(14类胸部疾病分类)、DXC5(5类胸部疾病分类)、TXC(胸部分类)和PXS(肺部分割)任务中,性能显著优于标准ImageNet预训练模型(𝑝 < 0.05),在CXS(锁骨分割)和HXS(心脏分割)任务中性能相当。 - 通过利用MIMIC-CXR数据集增加领域内数据量后,ImageNet→MIMIC领域自适应模型与ImageNet模型在所有目标任务中均出现显著性能差距(𝑝 < 0.05),凸显了数据规模在有效弥合摄影图像与医学图像领域差异中的关键作用。
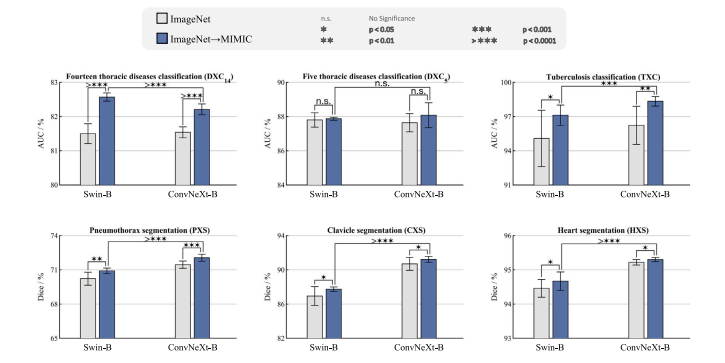
Fig. 9. Domain-adaptive pretraining can boost the performance of ImageNet models with modern ConvNet (i.e. ConvNeXt-B) and vision transformer (i.e. Swin-B) backbones.Particularly, our ImageNet→MIMIC domain-adapted models with ConvNeXt-B and Swin-B backbones consistently demonstrate superior performance (𝑝 < 0.05) compared withtheir corresponding ImageNet counterparts. Moreover, comparing ImageNet→MIMIC domain-adapted models with ConvNeXt-B and Swin-B backbones, the former exhibits superiorperformance in target tasks with relatively smaller datasets (TXC, PXS, CXS, and HXS), while the latter demonstrate equivalent or superior performance in target tasks withlarger datasets (DXC14 and DXC5 ), reiterating the superior annotation efficiency of pretrained models with ConvNets compared with those with vision transformer backbones (seeSection 3.2)
图9. 领域自适应预训练可提升基于现代ConvNet(如ConvNeXt-B)和视觉Transformer(如Swin-B)主干的ImageNet模型性能。具体而言: - 基于ConvNeXt-B和Swin-B主干的ImageNet→MIMIC领域自适应模型,在所有目标任务中均显著优于对应的ImageNet预训练模型(𝑝 < 0.05)。 - 对比两类主干的领域自适应模型: - ConvNeXt-B模型在数据集较小的任务(TXC胸部分类、PXS肺部分割、CXS锁骨分割、HXS心脏分割)中性能更优; - Swin-B模型在数据量较大的任务(DXC14十四类胸部疾病分类、DXC5五类胸部疾病分类)中表现相当或更优。 这一结果进一步印证了ConvNet预训练模型相比视觉Transformer标注效率更高的特性(见3.2节)。
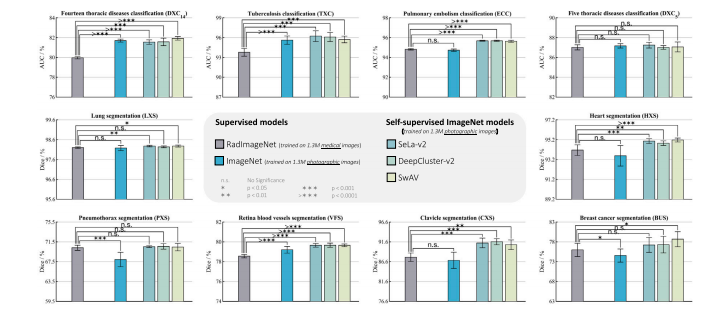
Fig. 10. Fine-tuning ImageNet pretrained models remains a valuable resource for fostering high-performance models in medical imaging. Notably, ImageNet models consistentlydemonstrate superior or comparable performance when compared with supervised RadImageNet models. Specifically, the supervised ImageNet model excels in DXC14, TXC, andVFS, performs at par in DXC5 , ECC, LXS, HXS, and CXS, and lags slightly behind RadImageNet in PXS and BUS. More importantly, the top-performing self-supervised ImageNetmodels, including SeLa-v2, DeepCluster-v2, and SwAV, consistently outperform supervised RadImageNet model across all tasks
图10. 对ImageNet预训练模型进行微调仍是构建医学成像高性能模型的重要途径。值得注意的是,与有监督RadImageNet模型相比,ImageNet模型在多数任务中表现更优或相当: - 分类任务:有监督ImageNet模型在DXC14(14类胸部疾病分类)、TXC(胸部分类)和VFS(玻璃体浮子分类)中显著领先,在DXC5(5类胸部疾病分类)、ECC(栓塞分类)等任务中性能持平,仅在PXS(肺部分割)和BUS(腹部超声)中略逊于RadImageNet。 - 自监督模型优势:表现最佳的自监督ImageNet模型(如SeLa-v2、DeepCluster-v2、SwAV)在所有任务中均超越有监督RadImageNet模型,凸显了自监督学习在跨领域迁移中的潜力。 该结果表明,尽管RadImageNet是医学领域内数据集,但其有监督预训练模型的泛化能力仍不及ImageNet(尤其是自监督版本),进一步支持了利用大规模通用数据集预训练模型进行医学迁移学习的有效性。
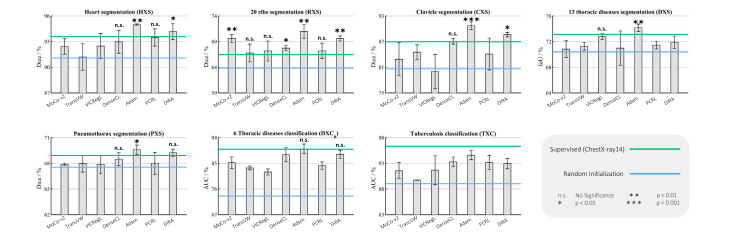
Fig. 11. Self-supervised learning using medical images holds the potential to yield more generalizable representations than those acquired through in-domain supervised learning.As seen, in nearly all tasks, at least two self-supervised learners exhibit comparable or superior performance compared with the supervised in-domain model, highlighting thesignificant potential of SSL in providing more generalizable representations in medical imaging
图11. 与领域内有监督学习相比,使用医学图像的自监督学习有望生成更具泛化性的表征。如图所示,在几乎所有任务中,至少有两种自监督学习模型表现出与领域内有监督模型相当或更优的性能,这凸显了自监督学习(SSL)在医学成像中提供更通用表征的巨大潜力。
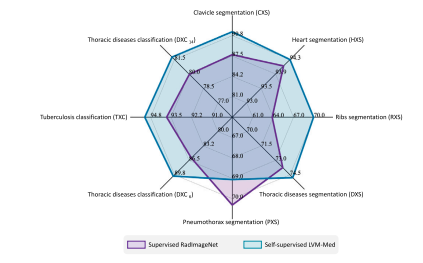
Fig. 12. The self-supervised LVM-Med pretrained model demonstrates superior transferperformance across various target tasks compared with the fully-supervised RadImageNet pretrained model. Particularly, despite both models utilizing an equivalentamount of pretraining data (∼1.3M) and sharing the same backbone, LVM-Medoutperforms RadImageNet in all tasks except PXS. This underscores the efficacy ofself-supervised learning in generating more generalizable and robust representations inmedical imaging, especially when well-designed self-supervised learning strategies arecoupled with large-scale pretraining data.
图12. 与完全有监督的RadImageNet预训练模型相比,自监督LVM-Med预训练模型在各种目标任务中表现出更优的迁移性能。值得注意的是,尽管两个模型使用了等量的预训练数据(约130万样本)并共享相同的主干网络,但LVM-Med除了在PXS(肺部分割)任务外,在所有任务中均优于RadImageNet。这一结果凸显了自监督学习在医学成像中生成更具泛化性和鲁棒性表征的有效性,尤其是当精心设计的自监督学习策略与大规模预训练数据相结合时。
Table
表
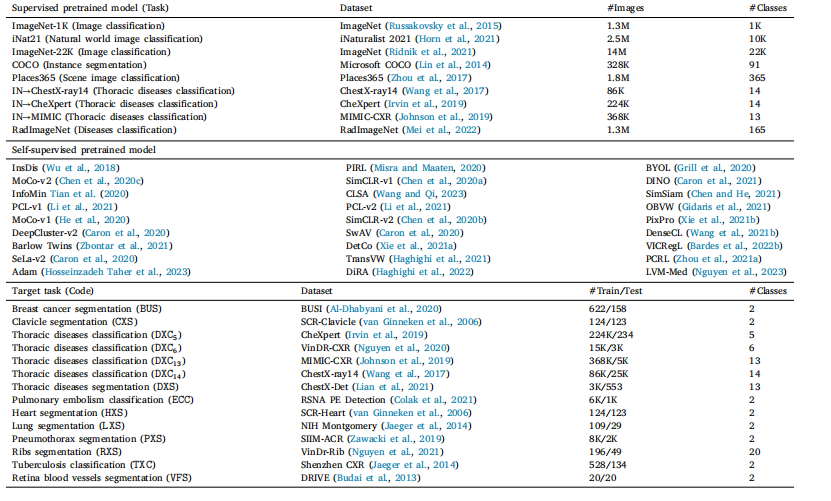
Table 1Pretraining and target tasks and datasets. We evaluate a broad spectrum of models pretrained on large-scale general and in-domain datasets for 14 medical imaging tasks, coveringdifferent label structures (binary classification, multi-label classification, and segmentation), modalities (X-ray, CT, Fundoscopic, and Ultrasound), organs (lung, heart, clavicle, ribs,eye, and breast), diseases, and data size. In the target tasks’ code, the first letter denotes the object of interest (‘‘B’’ for breast cancer, ‘‘C’’ for clavicle, ‘‘E’’ for embolism, ‘‘D’’ forthoracic diseases, etc.); the second letter denotes the modality (‘‘X’’ for X-ray, ‘‘F’’ for Fundoscopic, ‘‘C’’ for CT, and ‘‘U’’ for ultrasound); the last letter denotes the task (‘‘C’’ forclassification, ‘‘S’’ for segmentation). ‘‘IN’’ denotes ImageNet
表1 预训练及目标任务与数据集 我们评估了在大规模通用数据集和领域内数据集上预训练的各类模型,覆盖14项医学成像任务,涉及不同标签结构(二分类、多标签分类、分割)、模态(X光、CT、眼底、超声)、器官(肺、心脏、锁骨、肋骨、眼、乳腺)、疾病类型及数据规模。在目标任务代码中,首字母表示感兴趣对象(“B”为乳腺癌,“C”为锁骨,“E”为栓塞,“D”为胸部疾病等);第二个字母表示模态(“X”为X光,“F”为眼底,“C”为CT,“U”为超声);末字母表示任务类型(“C”为分类,“S”为分割)。“IN”表示ImageNet。
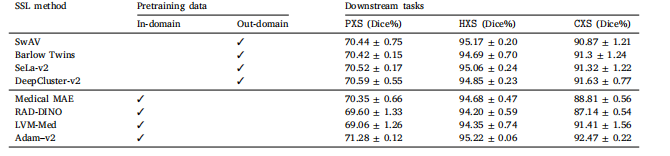
Table 2Comparison results of existing methods on PPMI for Parkinson’s disease classificationbased on FC and SC.
表2 基于功能连接(FC)和结构连接(SC)的现有方法在帕金森病进展标志物倡议(PPMI)数据集上进行帕金森病分类的比较结果。

Table 3We evaluate the robustness of pretrained models with modern ConvNet and vision transformer backbones under stress testing by applying meaningful perturbations to the test imagesand measuring the models’ performances on these out-of-distribution samples in two downstream tasks. ImageNet pretrained model with ConvNeXt-B backbone demonstrate higherrobustness to distorted data over its Swin-B counterpart. Additionally, domain-adapted models demonstrate significantly higher robustness to out-distribution samples comparedwith their corresponding ImageNet models.
表3 我们通过对测试图像施加有意义的扰动,并在两项下游任务中测量模型对这些分布外样本的性能,评估了具有现代ConvNet和视觉Transformer主干的预训练模型在压力测试下的鲁棒性。结果显示: - 基于ConvNeXt-B主干的ImageNet预训练模型相比其Swin-B对应模型,对失真数据表现出更高的鲁棒性。 - 领域自适应模型相比对应的ImageNet模型,对分布外样本展现出显著更高的鲁棒性。
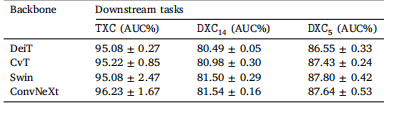
Table 4Comparison of the transferability of hybrid models (CvT and DeiT), hierarchicaltransformer (Swin), and modern ConvNet (ConvNeXt) pretrained models on threemedical imaging tasks: TXC, DXC14, and DXC5 . As seen, the hybrid CvT modeloutperforms DeiT across all tasks, consistent with their ImageNet top-1K accuracy. CvTand DeiT perform competitively with Swin in the TXC task but fall behind Swin in theDXC5 and DXC14 tasks, highlighting the advantages of hierarchical transformers overconventional vision transformers in handling large datasets. CvT lags behind ConvNeXtin the TXC task, but the performance gap narrows as the amount of fine-tuningdata increases in DXC14 and DXC5 . This emphasizes the greater annotation efficiencyof modern ConvNet models like ConvNeXt and demonstrates the potential of visiontransformers to compete favorably with ConvNets when substantial data is available
表4 混合模型(CvT和DeiT)、分层Transformer(Swin)和现代卷积网络(ConvNeXt)预训练模型在三项医学成像任务(TXC、DXC14和DXC5)上的迁移能力比较。如图所示,混合模型CvT在所有任务中均优于DeiT,这与其在ImageNet上的Top-1K准确率一致。在TXC任务中,CvT和DeiT与Swin表现相当,但在DXC5和DXC14任务中落后于Swin,这凸显了分层Transformer在处理大型数据集时相比传统视觉Transformer的优势。在TXC任务中,CvT落后于ConvNeXt,但随着DXC14和DXC5中微调数据量的增加,性能差距缩小。这强调了ConvNeXt等现代卷积网络模型更高的标注效率,并表明当有大量数据可用时,视觉Transformer有潜力与卷积网络竞争。

Table 5We conduct ablation study with two popular segmentation decoders, namely U-Net and UPerNet, on four medical segmentation tasks. U-Net provides significantly better (𝑝 < 0.05)compared with UPerNet in both organ and lesion segmentation tasks.
表5 我们在四项医学分割任务中,使用两种常用分割解码器(U-Net和UPerNet)进行了消融研究。结果显示,在器官和病变分割任务中,U-Net的性能均显著优于UPerNet(𝑝 < 0.05)。

Table 6Comparison of the transferability of self-supervised methods (i.e., SwAV and MoCo-v2) pretrained on fine-grained data (i.e., iNat2021 dataset) and coarse-grained data (ImageNet-1Kdataset). The table shows the fine-tuning performance of SwAV and MoCo-v2 models on three different target tasks: thoracic disease classification (DXC14), tuberculosis classification(TXC), and pneumothorax segmentation (PXS). As seen, regardless of the pretraining data (either ImageNet or iNat2021), SwAV consistently outperforms MoCo-v2 across all tasks,demonstrating the importance of SSL pretext task design in learning generalizable representations. Additionally, both SwAV and MoCo-v2 models pretrained on the ImageNetdataset outperform their counterparts pretrained on the iNat2021 dataset, highlighting the importance of input data diversity in the self-supervised learning paradigm
表6细粒度数据(如iNat2021数据集)与粗粒度数据(ImageNet-1K数据集)预训练的自监督方法(即SwAV和MoCo-v2)迁移能力对比 该表展示了SwAV和MoCo-v2模型在三种不同目标任务上的微调性能:胸部疾病分类(DXC14)、肺结核分类(TXC)和气胸分割(PXS)。结果显示: - 自监督任务设计的影响:无论预训练数据是ImageNet还是iNat2021,SwAV在所有任务中均持续优于MoCo-v2,表明自监督前置任务(pretext task)的设计对学习可泛化表征至关重要。 - 数据多样性的影响:基于ImageNet数据集预训练的SwAV和MoCo-v2模型均优于iNat2021预训练的对应模型,凸显了自监督学习中输入数据多样性的重要性——尽管iNat2021为细粒度数据,但其多样性可能不及ImageNet,导致迁移性能受限。

Table 7Comparison of the number of training epochs required by ConvNeXt and Swin models for different target tasks
表 7 ConvNeXt 与 Swin 模型在不同目标任务中所需训练轮次对比
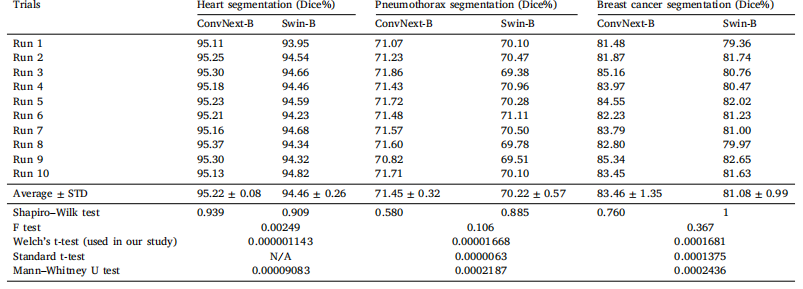
Table 8One-tailed Welch’s t-test has been used for conducting statistical significance analysis. A one-tailed test was chosen because of a specific directional hypothesis (i.e., Model A’smean is greater than Model B’s mean in a task). Welch’s t-test was selected because it does not assume equal variances between groups, making it more robust and reliable in thepresence of heteroscedasticity (unequal variances). Additionally, it helps to reduce the potential for Type I errors, as Welch’s t-test is more conservative than the standard t-test(Derrick et al., 2016; Ergin and Koskan, 2023). As seen, according to the Shapiro–Wilk test results, the performance results for each model in each task follow a normal distribution(𝑝-value > 0.05). Additionally, given that each model was run 10 times independently on each task, both required conditions (i.e., two independent samples and normally distributeddata) (Manfei et al., 2017) for conducting t-tests have been met. According to the F-test results, in the heart segmentation task, the two models have unequal variances (𝑝-value<* 0.05), which necessitates using Welch’s t-test. However, in the pneumothorax and breast cancer segmentation tasks, the two models have equal variances (𝑝-value > 0.05). Evenin these cases, Welch’s t-test provides a higher 𝑝-value compared with the standard t-test, demonstrating the robustness of Welch’s t-test to variances equality and reducing thepotential for Type I errors. According to the Mann–Whitney U Test, which we considered as an alternative statistical methodology to our t-test, the results corroborate the findingsfrom our one-tailed Welch’s t-test, providing further confidence in the robustness and validity of our statistical analysis. In all tests, the significance level (𝛼) is 0.05.
表8 本研究采用单尾韦尔奇t检验(Welch’s t-test)进行统计显著性分析。选择单尾检验是基于特定的方向性假设(即模型A在某任务中的均值大于模型B的均值)。采用韦尔奇t检验是因为其不假设组间方差相等,因此在存在异方差(方差不等)的情况下更具稳健性和可靠性。此外,韦尔奇t检验比标准t检验更为保守(Derrick等人,2016;Ergin和Koskan,2023),有助于降低Ⅰ型错误的可能性。 如图所示,根据夏皮罗-威尔克检验(Shapiro–Wilk test)结果,各模型在每项任务中的性能结果均服从正态分布(p值>0.05)。此外,由于每个模型在每项任务上独立运行10次,满足进行t检验的两个必要条件(即两个独立样本和数据正态分布)(Manfei等人,2017)。根据F检验结果,在心脏分割任务中,两个模型的方差不等(p值<0.05),因此必须使用韦尔奇t检验。然而,在气胸和乳腺癌分割任务中,两个模型的方差相等(p值>0.05)。即使在此类情况下,与标准t检验相比,韦尔奇t检验仍提供了更高的p值,表明韦尔奇t检验对方差齐性的稳健性,并降低了Ⅰ型错误的可能性。 作为t检验的替代统计方法,本研究采用的曼-惠特尼U检验(Mann–Whitney U Test)结果与单尾韦尔奇t检验的结论一致,进一步验证了统计分析的稳健性和有效性。所有检验的显著性水平(α)均为0.05。

Table 9Performance differences between ConvNeXt and Swin variants for clavicle and pneumothorax segmentation tasks using Dice and IoU metrics. Theresults demonstrate that ConvNeXt variants consistently outperform Swin variants across both metrics. This reinforces the annotation efficiencyof ConvNets over vision transformers regardless of the performance metrics used for evaluation.
表9 使用Dice系数和IoU指标评估ConvNeXt与Swin变体在锁骨分割和气胸分割任务中的性能差异。结果表明,在两项指标上,ConvNeXt变体均持续优于Swin变体。这进一步证实了卷积网络(ConvNets)相比视觉Transformer(vision transformers)在标注效率上的优势,且该结论与评估所使用的性能指标无关。