1、锁的可重入
一个不可重入的锁,抢占该锁的方法递归调用自己,或者两个持有该锁的方法之间发生调用,都会发生死锁。以之前实现的显式独占锁为例,在递归调用时会发生死锁:
public class MyLock implements Lock {
/* 仅需要将操作代理到Sync上即可*/
private final Sync sync = new Sync();
private final static class Sync extends AbstractQueuedSynchronizer {
// 判断处于独占状态
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 获得锁
@Override
protected boolean tryAcquire(int i) {
if (compareAndSetState(0, 1)) {
// 设置占有独占锁的线程
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 释放锁
@Override
protected boolean tryRelease(int i) {
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// 返回一个Condition,每个condition都包含了一个condition队列
public Condition newCondition() {
return new ConditionObject();
}
}
@Override
public void lock() {
System.out.println(Thread.currentThread().getName() + " ready get lock");
sync.acquire(1);
System.out.println(Thread.currentThread().getName() + " already got lock");
}
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return sync.tryAcquire(1);
}
@Override
public boolean tryLock(long timeout, TimeUnit timeUnit) throws InterruptedException {
return sync.tryAcquireNanos(1, timeUnit.toNanos(timeout));
}
@Override
public void unlock() {
System.out.println(Thread.currentThread().getName() + " ready release lock");
sync.release(1);
System.out.println(Thread.currentThread().getName() + " already released lock");
}
@Override
public Condition newCondition() {
return sync.newCondition();
}
}
测试代码:
public class Test {
private static MyLock lock = new MyLock();
private static class TestThread implements Runnable {
public TestThread() {
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
reenter(3);
}
public void reenter(int level) {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + ":递归层级:" + level);
if (level == 0) return;
reenter(level - 1);
} finally {
lock.unlock();
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
Thread thread = new Thread(new TestThread(new JavaBean(0)));
thread.start();
}
}
}
输出结果:
Thread-2 ready get lock
Thread-0 ready get lock
Thread-2 already got lock
Thread-1 ready get lock
Thread-2:递归层级:3
Thread-2 ready get lock
代码停在这里发生死锁,原因是 Thread-2 已经拿到了锁,在递归到下一层时,还要获取 lock,但是 MyLock 没实现可重入,使得它在执行 tryAcquire() 的原子操作 compareAndSetState(0,1) 时一直不成功,因为期望值此时已经由 0 变成了 1。所以这里需要实现可重入锁。
想要实现可重入的锁,需要让 state 作为锁的计数器:
// 获得锁
@Override
protected boolean tryAcquire(int i) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
} else if (getExclusiveOwnerThread() == Thread.currentThread()) {
setState(getState() + 1);
return true;
}
return false;
}
// 释放锁
@Override
protected boolean tryRelease(int i) {
if (getExclusiveOwnerThread() != Thread.currentThread()) {
throw new IllegalMonitorStateException();
}
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setState(getState() - 1);
if (getState() == 0) {
setExclusiveOwnerThread(null);
}
return true;
}
state 作为持有这个锁的线程的数量,锁被持有了几次,就要相应的释放几次。
2、Java 内存模型(JMM)
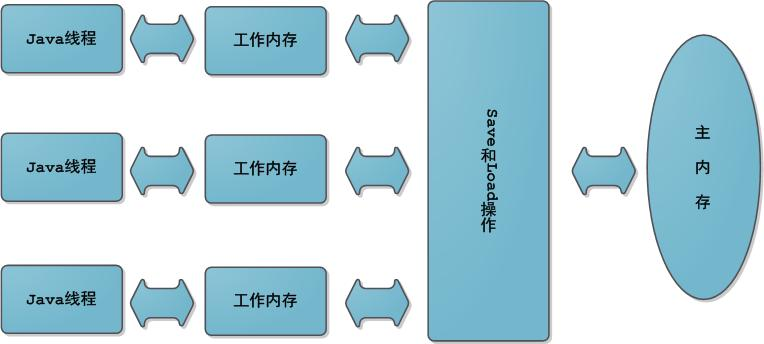
上图中工作内存和主内存是两个抽象的概念,不是真实存在的实体,它们可以是 CPU 寄存器、CPU 中的高速缓存,甚至是主内存 RAM 的一部分。
线程在执行计算工作时,会把需要用到的变量从主内存拷贝到自己的工作内存中。线程不能直接操作主内存中的数据,也不能访问其它线程工作内存。这样的内存模型使得线程执行过程中面临两个问题:可见性与原子性。
2.1 可见性与原子性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
线程对变量的所有操作都必须在工作内存中进行,不能直接读写主内存中的变量。对于共享变量 V,多个线程先是在自己的工作内存,之后再同步到主内存。但同步动作并不会及时的刷到主存中,而是会有一定时间差。这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。
要解决共享对象可见性这个问题,可以使 用volatile 关键字或者是加锁。
原子性即一个操作或者多个操作要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
CPU 资源的分配都是以线程为单位的。任务切换大多数是在时间片段结束以后,当然也可以在任何一条 CPU 指令执行完之后(是 CPU 指令而不是某种高级语言的一个语句,如 Java 中的 count++ 至少需要三条 CPU 指令才能完成),这也可能导致线程安全问题。
举个例子,假如两个线程都执行语句 count = count + 1,如图所示:
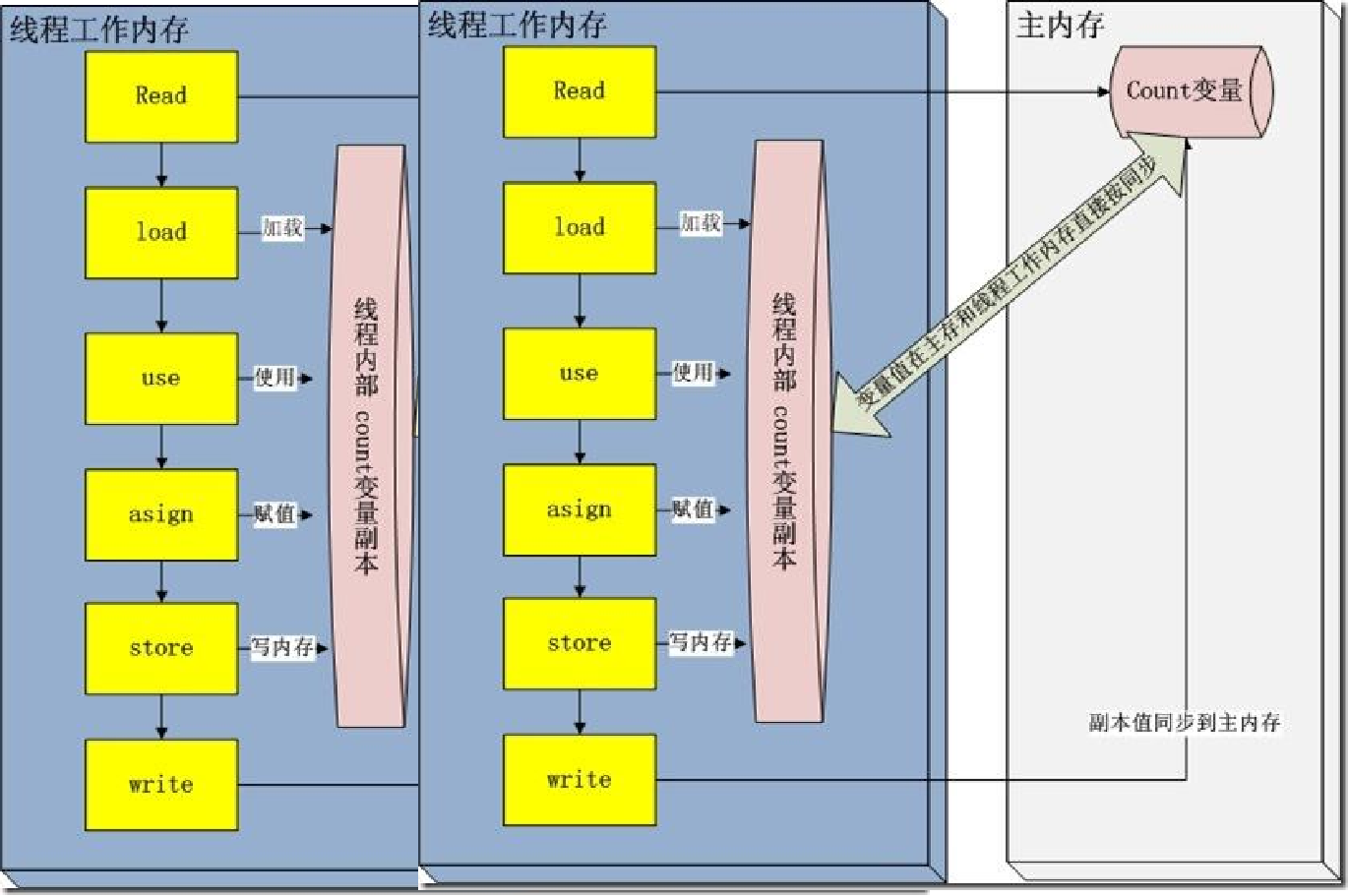
线程 A、B 都把 count 的初值 0 从主内存拷贝到自己的工作内存中开始执行 count + 1 的操作,都得到结果 1 再把副本值同步到主内存中。明明进行了两次计算,但是得到的却是计算了一次的结果,这是因为两个线程对于 count 的操作是互不可见的,彼此不知道对 count 的操作。
上述问题发生的原因是未能保证线程操作的可见性,可以使用 volatile 关键字或者是加锁解决可见性问题。
但是使用 volatile 修饰 count 后问题仍没有解决,原因就是 count = count + 1 并不是一个原子操作,完全有可能在执行完 count + 1 之后,赋值给 count 之前,CPU 进行上下文切换到其它线程执行完整个 count = count + 1 并将结果同步回内存,最后切换会原线程继续执行的情况,这就是原子性问题。
2.2 volatile 关键字
volatile 是 Java 并发编程包中最轻量级的一个同步工具。
使用 volatile 关键字修饰一个变量,会强迫线程每次在计算该变量之前从主内存中拿最新的变量值,并且要求计算完成后立即将新的变量值同步到主内存中。
可以把对 volatile 变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步。如:
public class Volatile {
volatile int i;
// 单个 volatile 变量的读
public int getI() {
return i;
}
// 单个 volatile 变量的写
public void setI(int i) {
this.i = i;
}
private void inc() {
// Non-atomic operation on volatile field 'i'
i++; // 复合(多个)volatile 变量的读/写
}
}
等价于:
public class Volatile {
int i;
// 单个 volatile 变量的读
public synchronized int getI() {
return i;
}
// 单个 volatile 变量的写
public synchronized void setI(int i) {
this.i = i;
}
private void inc() {
// 调用同步读
int temp = getI();
// 普通写,可能在执行这一步之前发生线程切换导致 volatile 修饰的变量发生线程安全问题
temp = temp + 1;
// 调用同步写
setI(temp);
}
}
可见 volatile 只能保证对变量的单个操作的线程安全,但像 i++ 这种复合操作,volatile 则不能保证其线程安全。
因此 volatile 变量自身具有以下特性:
- 可见性:对一个 volatile 变量的读,总是能看到任意线程对这个 volatile 变量最后的写入。
- 原子性:对任意单个 volatile 变量的读/写具有原子性,但类似于 i++ 这种复合操作不具有原子性。
volatile 适用的场景有:
- 一个线程写,多个线程读。(写线程能立即将结果写回内存,而读线程能拿到变量在内存中最新的值。否则写线程的结果可能并不是立即写回内存的,导致读线程拿到的变量不是最新)
- 多个线程写,但是各个线程写的值没有关联(count = 5 这种直接赋值是没有关联的,但是像 count = count +1 这种基于 count 原始值的认为是有关联)。
volatile 还有一个功能就是抑制重排序。
重排序是指在现代 CPU 中同一时刻可以执行多条指令,可能会造成实际执行的代码顺序与编写的顺序不同的情况。例如:
do(...) {
int a = 5; // 1
int b = 10; // 2
int t;
if (b == 5) {
t = b;
}
}
指令重排后可能后编写的语句会先被执行,即便 b == 5 的条件还未满足,也先执行 t = b,只不过对于这种条件语句可能会先存入重排序缓冲区中,等到 b == 5 满足时再从缓冲中取出执行。重排序在单线程中是不会出现乱序问题的,但是多线程则可能会出现。如果用 volatile 修饰某个变量,就不会对其进行重排序。
Intel CPU 可以有十级流水线(即 CPU 可以在同一时刻执行十条指令),Android 芯片的 ARM 架构也可达到三级流水线。
volatile 的实现原理是被 volatile 修饰的共享变量进行读写操作的时候会使用 CPU 提供的 Lock 前缀指令。该指令的作用是:
- 将当前处理器缓存行的数据写回到系统内存。
- 写回内存的操作会使其它 CPU 里缓存了该内存地址的数据无效。
以上是对 volatile 关键字的介绍。最后我们再回头看下 count = count + 1 的问题的解决方案:
- 使用 volatile 关键字搭配 CAS 操作,前者保证可见性,后者保证原子性。实际上 JDK 中很多同步操作都是使用 volatile + CAS 来代替 synchronized。
- 直接用锁,synchronized、Lock…
3、synchronized 实现原理
3.1 monitorenter 和 monitorexit 指令
底层是使用 monitorenter 和 monitorexit 指令实现的。对于使用了 synchronized 同步代码块的代码:
public class IncTest {
private int count;
// public 才能被 javap 反编译出来
public int inc() {
synchronized (this) {
return count++;
}
}
}
编译后使用 javap -v IncTest.class 命令反编译,会看到 inc 方法的汇编指令:
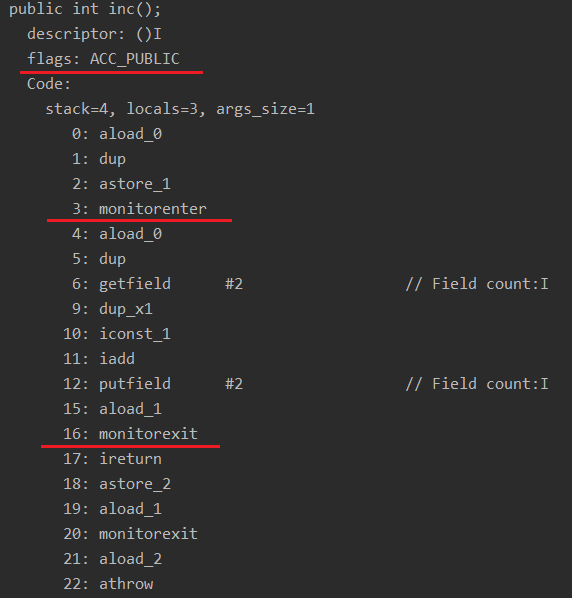
真正执行 count++ 操作的指令是在第4行~第15行,而第3行的 monitorenter 与第16行的 monitorexit 则分别是获取锁和释放锁的指令。这两条指令是由编译器插入的。而使用同步方法时:
public class IncTest {
private int count;
// public 才能被 javap 反编译出来
public synchronized int inc() {
return count++;
}
}
其汇编指令为:
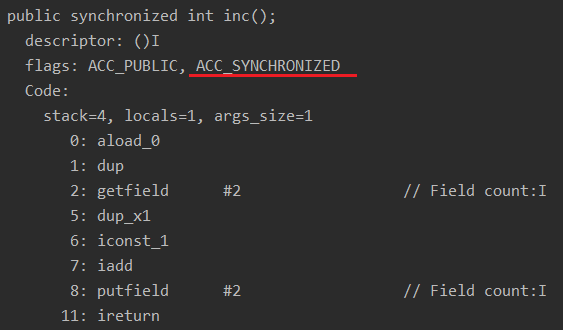
同步方法的汇编指令没有显式的 monitorenter 和 monitorexit 指令,但是在方法的 flags 上能看到多出了一个 ACC_SYNCHRONIZED,在运行时还是用到了 monitorenter 和 monitorexit 指令,只不过无法在字节码指令上体现出来。
总结一下:
- monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处。
- 每个 monitorenter 必须有对应的 monitorexit 与之配对。
- 任何对象都有一个 monitor 与之关联。
3.2 锁的存放位置与锁升级
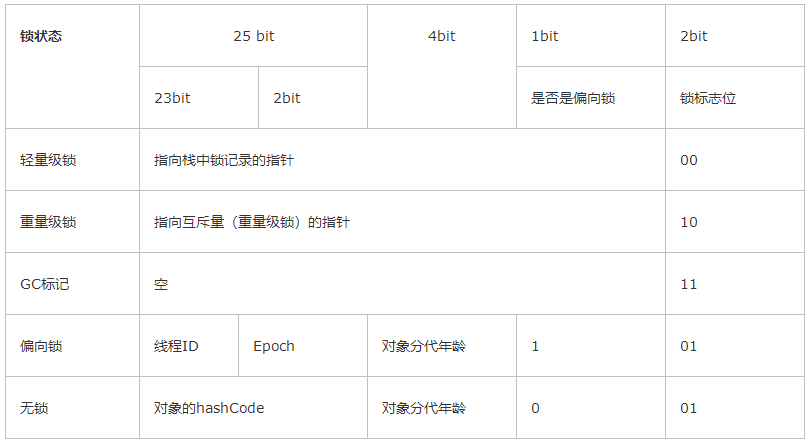
Java 对象在内存中由三部分组成:对象头、实例数据和对齐填充字节。synchronized 锁就存放在对象头中,它由三部分组成:Mark Word、指向类的指针(也称 KlassPoint)和数组长度(只有数组对象才有):

它们的长度与虚拟机位数保持一致,以 32 位为例,Mark Word 的存储内容是这样的:

分代年龄是指对象经历过 GC 的次数。堆内存至少会被划分成两部分,一部分存放新生代对象,一部分存放老年代对象。JVM 默认一个新生代对象经历过15次 GC 还没有被回收,就认为该对象是一个需要长期储存的对象,于是就把它移入堆内存的老年代存放区。
我们都知道 synchronized 同步锁是一个重量级的锁,拿锁失败的线程会发生上下文切换被阻塞,直到拿到锁后又发生上下文切换由阻塞状态变成运行状态。因为上下文切换的耗时相对于 CPU 执行指令的时间是非常耗时的,一次上下文切换需要大概5000~20000个单位时间,在3~5毫秒左右,而一个1.6G的 CPU 执行一条指令耗时0.6纳秒,对于一个100条指令的任务,CPU 的执行时间也就仅仅在0.6毫秒左右。因此,如果使用 synchronized 执行一个较轻量级的任务,被阻塞等待的时间远远超过了执行任务本身所需的时间。
为了对上述情况做出优化,从 JDK 1.6 开始出现了锁升级的概念,意思是说,一个 synchronized 锁在 Mark Word 中的状态不是一成不变的,会根据任务的量级对锁的量级逐步提升,即无锁状态->偏向锁状态->轻量级锁状态->重量级锁状态(锁的四种状态):
3.2.1 偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得(统计发现),为了让线程获得锁的代价更低而引入了偏向锁(锁总是会倾向于分配给第一次拿到这个锁的线程)。无竞争时不需要进行 CAS 操作来加锁和解锁,而是直接把锁给到当前线程。但是一旦发生多个线程间的资源竞争,就要把偏向锁升级为轻量级锁,在升级之前,要先撤销偏向锁。
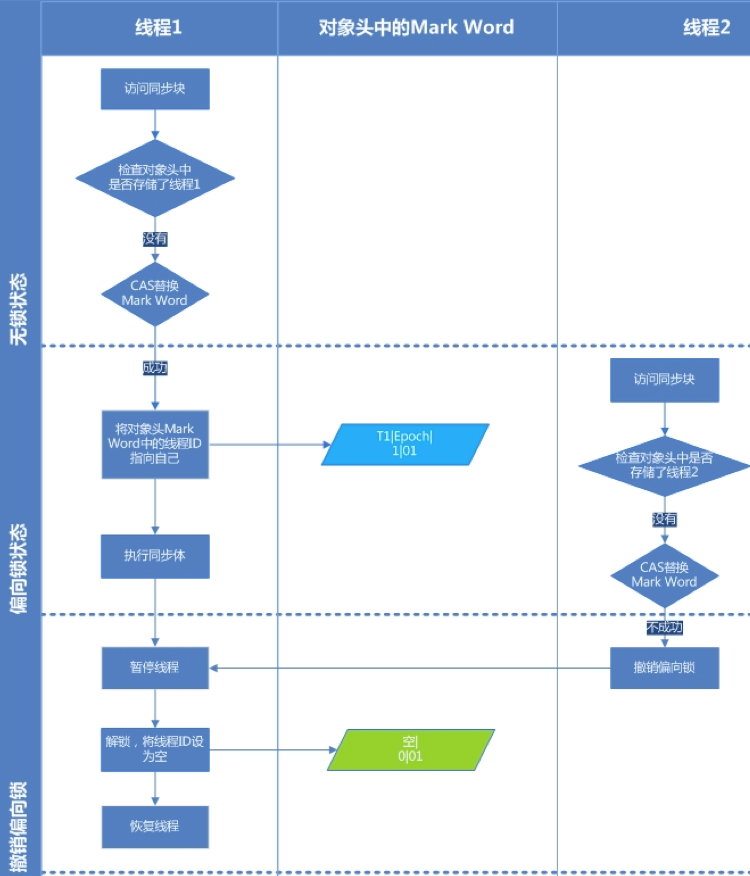
偏向锁撤销时中有一个 Stop the World 现象。Stop the World 是指:
在新生代进行的GC叫做minor GC,在老年代进行的GC都叫major GC,Full GC同时作用于新生代和老年代。在垃圾回收过程中经常涉及到对对象的挪动(比如上文提到的对象在Survivor 0和Survivor 1之间的复制),进而导致需要对对象引用进行更新。为了保证引用更新的正确性,Java将暂停所有其他的线程,这种情况被称为“Stop-The-World”,导致系统全局停顿。Stop-The-World对系统性能存在影响,因此垃圾回收的一个原则是尽量减少“Stop-The-World”的时间。
引用自 JVM学习(7)Stop-The-World
看上图,线程2在撤销线程1的偏向锁时,需要修改线程1工作内存中的相关数据,在修改之前要停止线程1的执行,否则线程2无法修改。因此这里也是发生了 Stop the World 现象,由于它会停止其它线程,因此在有多个线程竞争资源时,是不推荐使用偏向锁的。
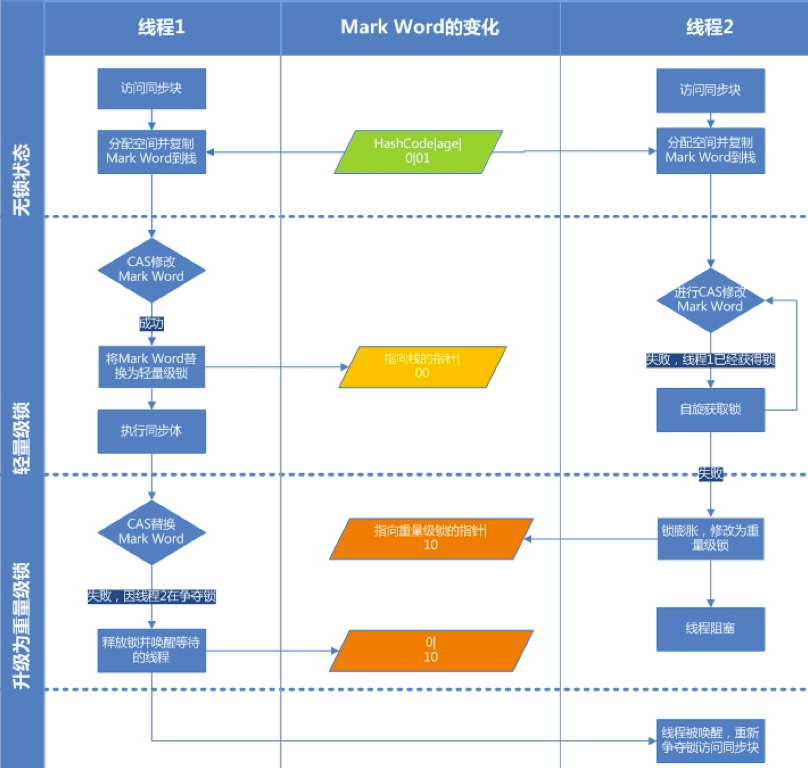
3.2.2 轻量级锁
轻量级锁通过 CAS 操作来加锁和解锁。其中的自旋锁借鉴了 CAS 的思想,不会阻塞没有拿到锁的线程,而是让其自旋。假如获取到锁的那个线程执行速度很快,那么自旋中的线程也可能很快就拿到了锁,这样能节省出两次上下文切换的时间。
但是自旋是占用 CPU 在不停的循环执行检测的,倘若线程任务中有访问服务器之类的重量级操作,如果还是一直不停的自旋,就使得 CPU 不能充分的利用。因此又产生了适应性自旋锁,它会根据算法决定自旋的时间/次数,一般这个时间就是一次上下文切换的时间。因为引入轻量级锁的目的就是通过自旋节省掉使用重量级锁时产生的上下文切换的时间,如果自旋时间已经超过上下文切换时间,那么自旋也就没有意义了,此时就要把轻量级锁膨胀为重量级锁。
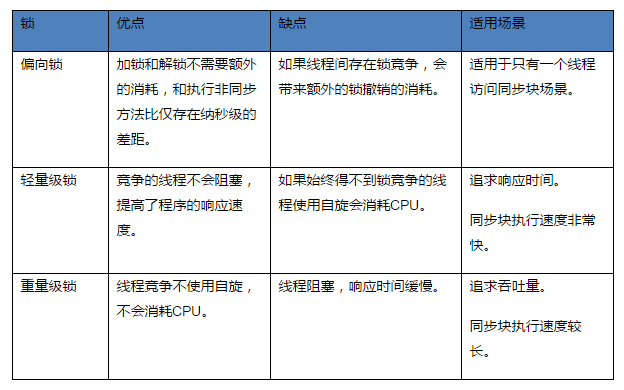
锁只能升级,不能降级。