最近在看有关webpack分包的知识,搜索了很多资料,感觉这一块很是迷惑,网上的资料讲的也迷迷糊糊,这里简单总结分享一下,也当个笔记。 如有错误请指出。
为什么需要分包
我们知道,webpack的作用,是将各种类型的资源,统一转换成浏览器可以直接识别的 Js Css Html 图片 等等,正如其官网图描述的一样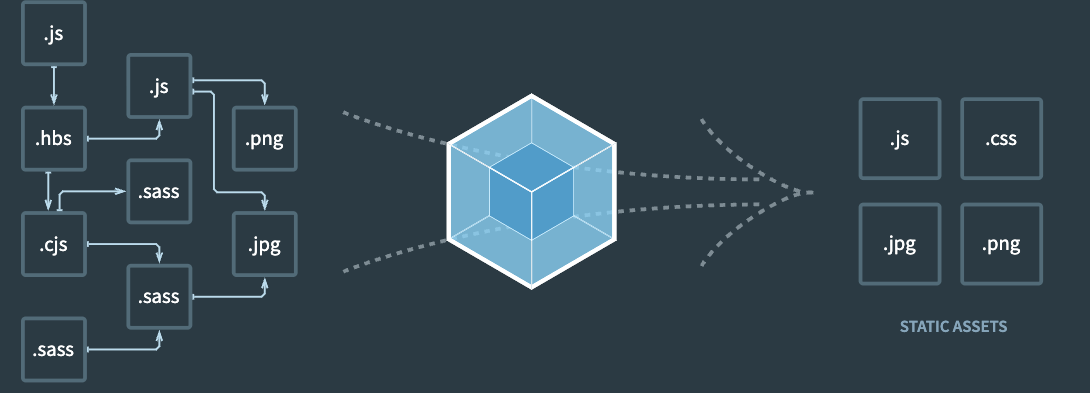
在这个过程中,webpack需要兼容各种模块化标准 (CommonJs & ESModule),将各种模块化标准实现的各个模块,统一打包成一个bundle.js文件,这个文件可以直接被script标签引用, 被浏览器直接识别。
如果你了解webpack的实现原理,就可以知道,其打包结果本质上是一个自执行函数。 各个模块被封装成一个 路径 => 代码 的Map,通过入参传入。 自执行函数内部,有一套逻辑可以读取,执行这些模块代码,并且兼容统一了各种模块化标准。
说了这么多,webpack给我们的印象是一个 多 归 一 的构建工具,无论我们有多少的模块,最后输出的结果只有bundle.js一个。这就带来一个问题,如果我们的模块体积很大,其中可能还包含了图片等信息,那么从服务端将其下载到本地就需要很大的开销,可能导致用户浏览器出现长时间白屏的现象。我们需要将逻辑上一个大的bundle.js拆散,根据用户的需求,动态的下载,保证用户的体验。
完成这个拆分工作,就需要用到分包相关的技术。
分包的工作,通常由SplitChunksPlugin完成,其是webpack内部提供的一个插件,我们不需要额外的从NPM上下载这个插件,只需要在 optimization中配置splitChunks属性即可。
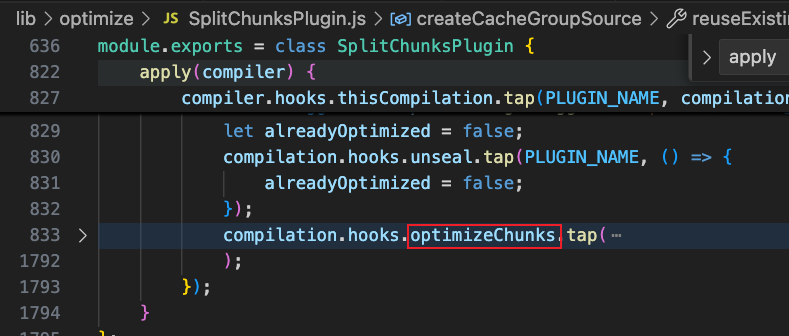
我们可以看到,SplitChunksPlugin是在optimize阶段通过钩入 optimizeChunks钩子实现分包的
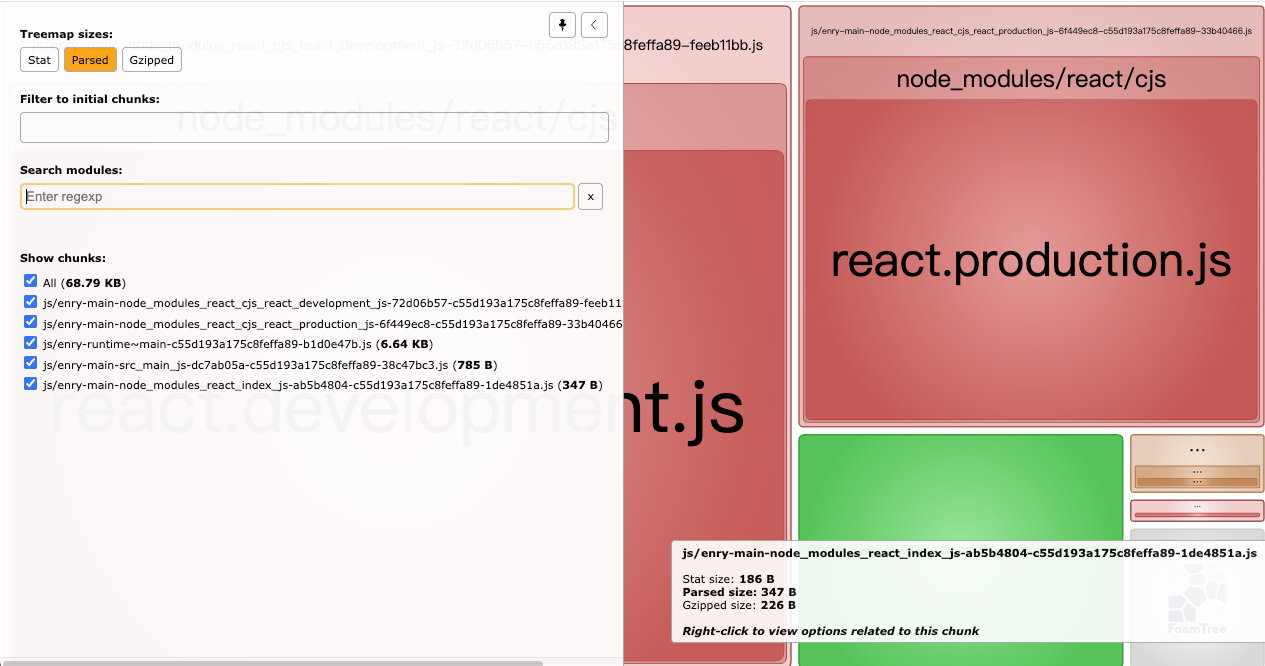
chunks属性
很多介绍splitchunks的文章都是从 chunks开始介绍的,说这个属性有三个值
async(默认)| initial | all
分别对应,拆分异步模块,拆分同步模块,拆分同步和异步模块
由于默认值是 async 所以通过 import() 动态导入的模块会被单独拆分!
现象如此,但是这个理解完全是错误的!
webpack默认行为
首先你需要知道,webpack对异步模块的拆分是webpack的默认行为,和splitChunks无关。
我们很容易验证,设置splitChunk: false 关闭拆包,对于如下例子:
webpack.config.js
// 单一入口
entry: {
main: "./src/main.js",
},
main.js
// 通过 import动态导入add模块
import("@utils/add").then((module) => {
console.log(module.add(100, 200));
});
add.js
// 导出一个简单的 add 函数
export function add(x,y){
return x + y
}
入口main.js动态引入了一个 add函数,由于关闭了拆包优化,最后应该只有一个js文件被输出,但是最终的结果为:

可以观察到,无论开不开分包优化,webpack对于异步导入的模块,都会将其单独作为一个chunk拆分出去,这样也确保了请求资源的时候不把异步模块同主模块一同加载进来,这个是默认行为
add.js
import './commonUtils'
export function add(x,y){
return x + y
}我们改动一下,在add.js中同步引入 commonUtils模块,打包结果如下:

可以发现,commonUtils模块被打入了 add.js一起。
对于webpack来说,被异步模块引入的模块,如果这个模块没有被同步模块引用过,那么在异步模块中无论如何被引用,都是异步模块。
如果我们在 main.js中同步引入 commonUtils
main.js
import '@utils/commonUtils'
import("@utils/add").then((module) => {
console.log(module.add(100, 200));
});
可以看到,最终的打包结果中,commonUtils被和main这个同步模块打包到一起了,如下:

其实这也好理解,如果一个模块都已经被同步载入过了,那么就没必要再费网络资源去异步请求了,直接复用即可。
虽然同步模块和异步模块在默认状态下可以直接复用,但是这种复用仅仅存在于 同一入口的情况下,看下面例子: 我们增加一个app模块,在app中异步引入commonUtils模块,在main中同步引入commonUtils模块
webpack.config.js
entry: {
app: "./src/app.js",
main: "./src/main.js",
},
app.js
import("@utils/commonUtils").then((module) => {
console.log(module);
});
main.js
import '@utils/commonUtils'可以看到,在多入口的情况下,commonUtils被打包了两次

为什么多入口之间不能复用,因为webpack要保证每一个入口都是独立可用的,对于main.js 其单独使用的时候如果要获取commonUtils.js 需要将整个main.js完整下载下来,无法保证每个入口的独立性,所以会单独打包一份出来。
我们把main.js中的同步引入commonUtils也改成异步,可以发现最终结果中只有一个commonUtils模块,也就是说异步模块在不同入口之间是可以复用的

这也符合逻辑,对于每个入口,由于对于commonUtils的载入都是异步的,在一开始载入的时候都不需要同步载入commonUtils,所以自然使用一个独立模块即可。
说完了这些,我们做个小总结 避免混乱
首先,这些都是在不进行任何分包优化下的情况,一定要明确前提
- webpack在默认情况下,会 并且 仅仅会对异步载入的模块进行独立分包处理
- 对于同步的模块,webpack默认情况下都会打入主包中同步引入,不会独立拆包
- 异步模块中无论同步,还是异步的模块引入 都算成是异步引入
- 在相同入口的情况下,同步引入和异步引入会共享同步引入的模块,不会单独异步拆包
- 在不同入口下,同步和异步引入相对独立,无法共用,会打两份,但是异步模块之间可以互相共用。
我认为,了解webpack默认行为会对后面的学习减少很多的"弯路",在理解分包现象的时候需要理解到底是splitChunk的优化结果,还是webpack的默认行为。
比方说chunks: async虽然是默认值,但是造成分包的并不是这个属性的作用,属于webpack的默认行为!
chunks属性的真正含义
chunks属性的真正含义如下
- async: 仅仅对异步导入的模块进行splitChunks优化,同步导入的模块会被忽略,也是chunks的默认值 (默认情况下,splitChunks只对webpack默认拆分出来的异步模块生效)
- initial: initial即初始化的意思,浏览器初始化加载模块的时候,会将引用的所有同步模块都载入,所以initial的含义是,对于同步导入的模块(即 初始化阶段会被载入的模块) 进行splitChunks优化,对于异步导入的模块,会被忽略。 我们知道webpack的默认状态下不会对同步模块单独拆包,所以initial就是用来增强其处理同步模块的功能
浏览器初始化的时候,会将同步模块一口气都载入,那么分包的意义何在呢?
其实主要目的是对于打包多入口时,在默认情况下,如果两个如果都引用了某个同步模块, 为了保证两个入口的独立性,这个模块会被重复两次打包。initial的作用就是可以把这个共同引用的同步模块拆分出来,减小打包文件的总体积。
- all: 对于同步,异步引入的模块,都会进行splitChunks的优化,这个也是被官方推荐的方式。
很多教程中,说把chunks设置为 all 的作用是除了拆分async 还能拆分第三方vendor(即 node_modules)模块 这个也是不对的,只是all很强大,开启之后可以达到拆分第三方模块的效果,但是绝对不是其作用就是为了拆分第三方模块。 具体实现原理下面会说
我们看一些例子,如下,我们简单的设置splitChunks的chunks: async 为了不影响我们观察打包结果,我们先将minSize minChunks分别设置为 0 和 1 也就是让拆包大小和引用chunks数不影响chunks本身的效果。
// webpack.config.js
entry: {
app1: "./src/app1.js",
app: "./src/app.js",
main: "./src/main.js",
},
splitChunks: {
chunks: "async",
minSize: 0,
minChunks: 1,
}
// app1.js
import"@utils/commonUtils"
// app.js
import("@utils/commonUtils").then((module) => {
console.log(module);
});
// main.js
import"@utils/commonUtils"未开启splitChunks优化

开启 chunks: async 优化异步模块

可以看到,打包结果和不设置 splitChunk没什么两样,但是这并不代表其未生效,我们来分析一下
首先,在进行拆包优化之前,由于在三个入口分别同步和异步引入了 commonUtils模块。 由于在两个不同入口中,同步异步引用无法复用,webpack的默认行为会把异步的commonUtils拆分出来,并且把同步引入的commonUtils合并到主包中。
优化开始,由于chunks: async 此时只对拆分出来的commonUtils进行拆分,忽略同步的commonUtils 所以此时没什么可优化拆分的,splitChunks不会对打包结果有什么改变。
我们把chunks改成 initial 即 只对同步模块进行优化, 可以看到,此时,两个commonUtils被拆分出来了,由于有两个入口同步引用了commonUtils,initial模式下,会把这个同步模块单独拆分进行复用。但是由于initial模式会忽略异步模块,所以会导致异步的commonUtils和同步的commonUtils无法复用。

为了解决同步异步的commonUtils不能复用的问题,我们把chunks设置为 all 即 对同步引入和异步引入的模块都开启分包优化,此时的打包结果如下:

可以看到,由于对于同步异步的模块splitChunk都会识别处理,所以commonUtils会被单独拆分成一个chunk,供同步和异步的引入使用,这样就达到了对commonUtils的最小化拆分。
再看一个例子,我们引入两个入口,其中:
app1.js引入一个node_modules下的 lodash模块
main中引入我们自己定义的 utils/commonUtils.js模块
webpack.config.js
entry: {
app1: "./src/app1.js",
main: "./src/main.js",
},
chunks: all
// app1.js
import "lodash";
// main.js
import"@utils/commonUtils"打包结果如下:

你会发现,同样是被一个入口引用1次,为什么lodash就被单独拆分了,我们自己定义的包就没被拆分,而我们已经设置了minSize: 0 也就是模块大小不会影响拆包,那么为什么第三方模块就被拆分了,我们自定义的模块就不会? 这个就要引入我们下面要说的 cacheGroup 缓存组的概念了
cacheGroups缓存组
缓存组用来定义哪些模块被拆分成一组,拆分成一组的模块可以被浏览器单独的缓存,不用在每次更新的时候重新从服务器获取。
cacheGroups需要配置一个对象,key未缓存组的名称,value为一个配置对象,其中使用 test属性匹配模块的名称,我们举个例子:
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
cacheGroups: {
MyUtils: {
test: /\/utils\//,
minSize: 0,
minChunks: 1,
name: 'MyUtils'
}
}
}上述例子,我们设置一个MyUtils缓存组,其中test匹配路径中包含 utils的模块,并且设置其单独分包名称为 MyUtils。 其含义是,需要webpack对路径中包含 utils的模块单独拆出来并且合并到一个包里,这个包的名称为 MyUtils.
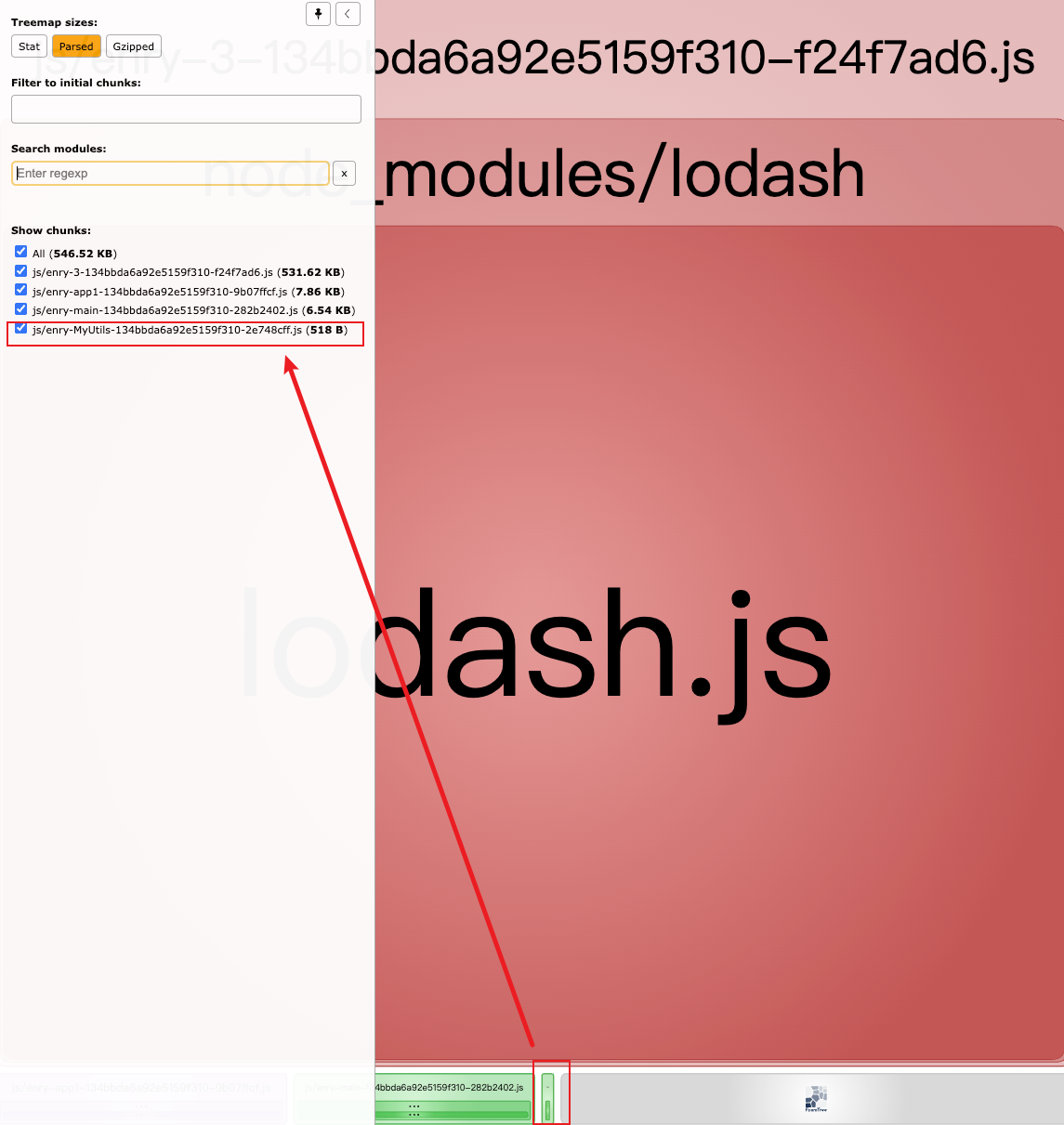
可以看到,这时我们自己定义的 utils/commonUtils.js被单独打包了。
那么回到上面的问题,为什么node_modules的模块就会被单独拆分,我们自己写的模块就需要我们自定义一个缓存组才能实现拆分? 这是因为webpack内置了两个 defaultVendors和default两个缓存组 如下:
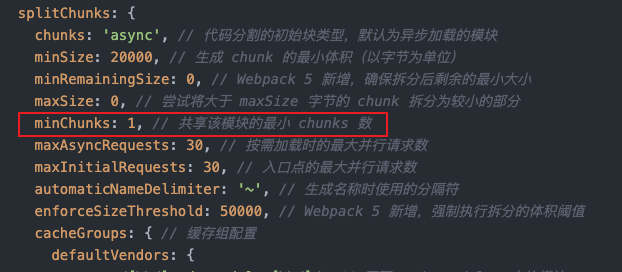
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'async', // 代码分割的初始块类型,默认为异步加载的模块
minSize: 20000, // 生成 chunk 的最小体积(以字节为单位)
minRemainingSize: 0, // Webpack 5 新增,确保拆分后剩余的最小大小
maxSize: 0, // 尝试将大于 maxSize 字节的 chunk 拆分为较小的部分
minChunks: 1, // 共享该模块的最小 chunks 数
maxAsyncRequests: 30, // 按需加载时的最大并行请求数
maxInitialRequests: 30, // 入口点的最大并行请求数
automaticNameDelimiter: '~', // 生成名称时使用的分隔符
enforceSizeThreshold: 50000, // Webpack 5 新增,强制执行拆分的体积阈值
cacheGroups: { // 缓存组配置
defaultVendors: {
test: /[\\/]node_modules[\\/]/, // 匹配 node_modules 中的模块
priority: -10, // 优先级
reuseExistingChunk: true // 如果当前 chunk 包含已从主 bundle 中拆分出的模块,则重用该模块
},
default: {
minChunks: 2, // 被至少两个 chunks 共享的模块
priority: -20, // 优先级低于 vendors
reuseExistingChunk: true // 重用已存在的 chunk
}
}
}
}
};可以看到,对于路径包含 /node_modules/的模块,splitChunks插件会默认将其分到一个缓存组中去,而对于default缓存组,其没有设置test属性,意味着没有匹配到任何缓存组的模块都会被default缓存组匹配,其优先级priority: -20 低于defaultVendors的-10 为最低优先级的缓存组,可以被当成是一组兜底的缓存策略。
这也就解释了为什么我们自己定义的commonUtils模块没有被单独拆包,虽然其匹配到了默认的default缓存组,但是由于其内部配置了 minChunks: 2 也就是说当前模块必须被至少两个chunk匹配到,才会单独拆包,而上述例子commUtils只被引用了一次,所以没有被单独划分。
你也许会问? lodash也只被匹配了一次啊? 为什么也被单独拆包了? 这时因为defaultVendors缓存组没有配置minChunks,那么会直接使用顶层的minChunks配置,也就是minChunks:1 任何模块只要被一个chunk引用,就会被单独拆包 (注意这里是chunks 不是 modules)
注意,cacheGroups这个名字很容易误导人,其并不是把test匹配到的模块都合并到一个chunk,还要考虑其中的 minSize minChunks name等等属性的作用
你可以将其理解为 缓存规则组 把一组决定模块是否缓存 如何缓存的规则 放到一个组里面,test匹配到某个group就使用这个group的规则。
cacheGroups的作用原理 & 如何禁用cacheGroups
回忆一下我们上面的例子,当我们设置cacheGroups时,如果cacheGroups的名称和默认的 defaultVendors / default 不重复,那么不会覆盖默认的cacheGroups配置
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
cacheGroups: {
MyUtils: {
test: /\/utils\//,
minSize: 0,
minChunks: 1,
name: 'MyUtils'
}
}
}
等价于
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
cacheGroups: {
MyUtils: {
test: /\/utils\//,
minSize: 0,
minChunks: 1,
name: 'MyUtils'
},
defaultVendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10,
reuseExistingChunk: true
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}所以,如果我们不想使用默认配置,不能直接 cacheGroups: {} 而是需要
// 关闭默认cacheGroups
cacheGroups: {
default: false,
defaultVendors: false
}
禁用缓存组之后,我们再来看分包结果

可以看到,lodash和commonUtils都没有被拆分。你也许会疑问了? 即便什么缓存组都没匹配到 那顶层的默认配置不是还写着 minChunks:1 呢么?
你可以简单的理解为,cacheGroups是拆包的 “引擎” 只有匹配到了cacheGroups才会启动分包流程,如果任何的缓存组都没匹配到,光有顶层的那些配置是没有任何意义的。
所以你需要记住,在没有匹配到任何缓存组的情况下,splitChunk不会对模块进行拆包优化!
所以,回到前面的问题,有些博客说,把chunks设置为all就开启了对第三方模块的分包优化 这是不严谨的,很可能让人误认为拆分第三方模块是chunks all的效果,但是其实不是的。
由于我们引用第三方模块大多是同步引入,而chunks默认值为 async,所以默认情况下,我们不会对同步引入的第三方模块进行分包优化。
当开启了all的时候,第三方模块也会被纳入分包优化的范围,而splitChunks又内置了defaultVendors的缓存组,并且没有设置其minChunks
所以才会拆分出第三方内容,设置chunks: all仅仅是整个拆分流程中的一个环节而已。
minSize
设置chunk的最小尺寸,单位字节(Byte),只有在模块尺寸大于这个属性值的时候,才会拆包
commonUtils的尺寸约为40B 当设置顶层minSize: 40 / 50 时,拆分结果如图
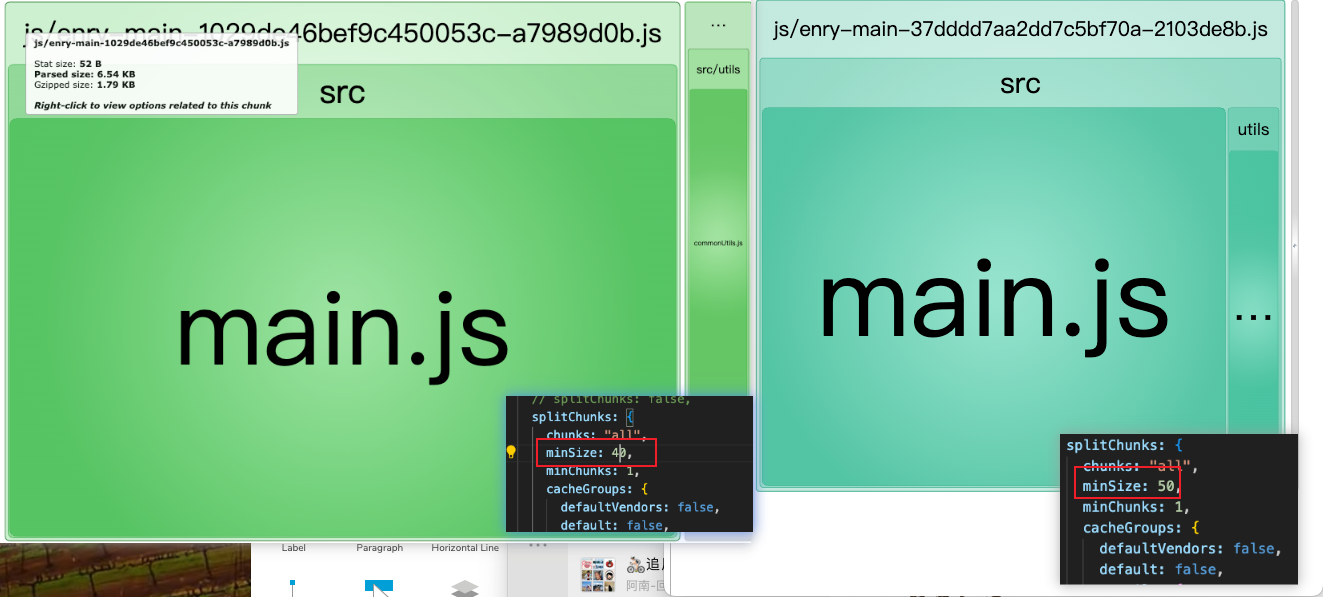
同时,我们还可以在缓存组的内部设置minSize,其会覆盖顶层的minSize配置

minChunks
minChunks限制了模块的最小chunks引用数,也就是模块被至少 minChunks 个chunk引用,才会被分割出去。
这里的chunk计数,取决于chunks的配置,如果chunks配置为 async 那么只有异步模块会进来匹配这个minChunks 如果是inital 那么只有同步模块会被计算进chunks 如果是all则都被计算。我们看例子
webpack.config.js
splitChunks: {
chunks: "initial",
minSize: 0,
minChunks: 1,
cacheGroups: {
// 关闭默认缓存组
defaultVendors: false,
default: false,
utils: {
test: /\/utils\/commonUtils.js/,
minChunks: 3,
name: 'MY_UTILS'
}
}
}
entry: {
app1: "./src/app1.js",
app: "./src/app.js",
main: "./src/main.js",
},
// main.js
import"@utils/commonUtils"
//app.js
import("@utils/commonUtils").then((module) => {
console.log(module);
});
// app1.js
import"@utils/commonUtils"
main和app1 同步引用了commonUtils模块,app异步引入commonUtils
我们设置commonUtils的缓存组minChunks: 3 chunks: initial 此时打包如下

可以看到 commonUtils被打包了3份 为什么?
1. webpack默认情况下,会把异步app.js中的common模块单独拆分
2. 由于chunks为initial 所以只会统计同步引入common模块的chunks数 只有app和main两个,所以不满足minChunks: 3的配置,不分包,会对app1 main 两个chunk都生成一份commonUtils
当我们设置minChunks: 2

可以看到,main和app1中的common模块被抽取出来了,但是由于chunks为initial 没有app中异步分离出来的commonUtils复用。 由于异步模块会被忽略,splitChunks不知道有一份可以被复用的commonUtils已经被生成了。
为了解决,我们设置chunks为all,并且设置minChunks:3 如下:
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
cacheGroups: {
defaultVendors: false,
default: false,
utils: {
test: /\/utils\/commonUtils.js/,
minChunks: 3,
},
},}此时,只有一份common被抽取,如下:

其过程为
1. webpack默认抽取app中的异步common模块
2. 分包优化的时候 由于同步异步模块都会被记入minChunks统计,满足minChunks: 3的条件 所以commonUtils会被单独拆包,但是发现webpack默认已经拆了一份common出来 就直接复用即可。
而对于chunks initial的情况下,由于忽略了异步的common模块,所以无法对已经拆出来的模块进行复用。
enforce 强制拆分
enforce通常用在缓存组内,如果某个缓存组内设置了enforce: true 那么这个缓存组会忽略全局的 minSize minChunks等等这些限制,仅以缓存组内部的配置为准
需要注意的是 enforce是用来忽略全局的配置的,无法忽略缓存组内部的配置
看以下例子
// webpack.config.js
splitChunks: {
chunks: "all",
minSize: 999999,
minChunks: 999999,
cacheGroups: {
defaultVendors: false,
default: false,
utils: {
test: /\/utils\/commonUtils.js/,
},
},
}
// 入口
import"@utils/commonUtils"
由于外层的 minChunks minSize设置的非常大,所以打包出来的结果是不进行任何拆分

此时,如果我们设置了enforce: true 如下
splitChunks: {
chunks: "all",
minSize: 999999,
minChunks: 999999999,
cacheGroups: {
defaultVendors: false,
default: false,
utils: {
test: /\/utils\/commonUtils.js/,
enforce: true,
},
},外层的配置将会被直接忽略,可以看到 common模块还是被正常分离出来了。这就是enforce直接忽略了外层的配置。

但是,如果我们对缓存组内部设置minChunks: 2 此时enforce就无法对内部的限制产生效果了。
所以,当你想忽略掉顶层配置强制拆分某个模块的时候,可以尝试使用enforce属性!
maxInitialRequests
maxInitialRequest代表最大同步并发数量,也就是限制了单个entry下加载的最大initial chunk数量
需要注意 maxInitialRequests 默认包含入口chunk,当对某个缓存组做更精细化的配置时,要减去1
在看例子之前,需要先将全局的 enforceSizeThreshold设置为0,即没有强制尺寸分包上限,方便我们观察
webpack.config.js
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
maxInitialRequests: 1,
enforceSizeThreshold: 0,
cacheGroups: {
defaultVendors: false,
default: false,
react: {
test: /react/,
minSize: 0,
minChunks: 1,
}
}
// 入口
import react from 'react'maxInitialRequest默认包含了入口chunk,所以在某个缓存组内分析时要先减去入口chunk
比如对于react缓存组,其没设置maxInitialRequests 所以继承全局的为 1 也就是说,对于react缓存组,其最多可以分出 maxInitialRequest - 入口chunk(1) = 0 个chunk,也就是说react不能被单独分包,哪怕满足minSize minChunks这些, 最终分包结果如下:

可以看到,react收到maxInitialRequests的限制,被合并到了入口chunk中。
若修改react缓存组内的maxInitialRequests: 2 那么其会覆盖全局的配置,将react单独分包 如下:

如果无法满足 maxInitialRequest的要求,那么会尽可能把大的模块拆分出来,小的合并,看下面例子
// webpack.config.js
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
maxInitialRequests: 2,
enforceSizeThreshold: 0,
}
entry: {
app1: "./src/app1.js",
app: "./src/app.js",
main: "./src/main.js",
}
// app.js
import 'lodash'
// app1.js
import 'lodash'
import 'react'
//main.js
import"react"其引用关系如下图:
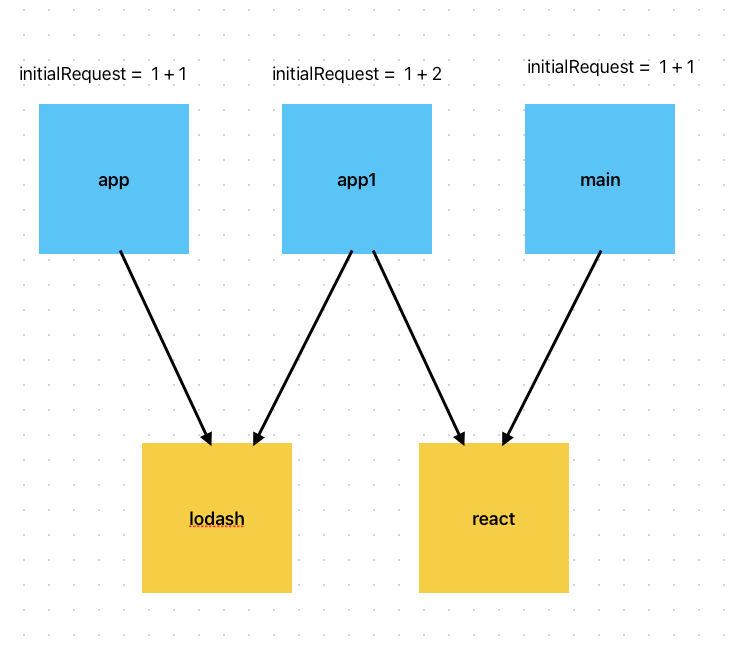
可以看到,app1模块的initialRequest为 = app1入口chunk + lodash + react = 3 不满足 maxInitialRequest = 2
webpack会把其中更大的lodash模块拆分出来,更小的react模块合并到入口chunk内, 如下
可以看到,对于 app 和 main 由于只引用了一个模块 满足maxInitialRequest: 2
但是对于 app1 更大的lodash被拆出来共用 ,更小的react被合并进app入口了。

注意!在
webpack中,runtimeChunk: true并不包含在maxInitialRequests的限制内。
maxAsyncRequest
maxAsyncRequest和maxInitialRequest类似,区别在于,其限制的是 对于每个 import() 动态导入 最大并发的可以下载的模块数, 其中 import() 本身算一个并行请求
有点绕,举个例子
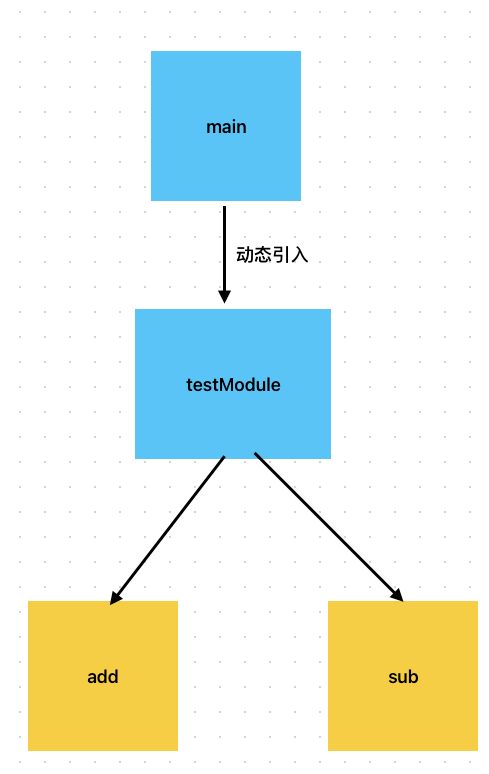
我们在入口动态引入一个 testModule.js 其中同步引入add sub两个模块 如下
// main.js
import ('@utils/testModule')
// testModule.js
import "./add";
import "./sub";
// add.js
export function add(x,y){
return x + y
}
//sub.js
export function sub(x,y){
return x - y
}
其依赖图为
我们设置缓存组,让各个模块之间都相互独立
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
enforceSizeThreshold: 0,
cacheGroups: {
utils: {
test: /\/utils\//,
minChunks: 1,
minSize: 0,
priority: 10,
name: ()=>'UTILS'+Math.random()
},
},打包结果如下

全局设置 maxAsyncRequests: 1 结果如下:

为什么三个模块被打包到一起了? 因为在main中动态引入testModule 由于需要满足maxAsyncRequest 此时 如果把add sub单独拆分,那么asyncRequest = 动态导入testModule + add + sub = 3 不满足限制。
maxAsyncRequest设置为 2 可以看到打包结果为

add和sub被单独拆分,和testModule分离,此时的asyncRequest刚好为 2
设置maxAsyncRequests = 3 可以看到三个模块都被独立分割了

我们修改 testModule 动态引入add 并且设置maxAsyncRequests为1
// testModule.js
import("./add");
import "./sub";
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
maxAsyncRequests: 1,
enforceSizeThreshold: 0,
cacheGroups: {
utils: {
test: /\/utils\//,
minChunks: 1,
minSize: 0,
priority: 10,
name: ()=>'UTILS'+Math.random()
},
},
此时可以看到,结果为

为什么add被单独拆分了? 这是不是不满足maxAsyncRequest: 1 的限制了? 其实不是
我们前面说了,splitChunks无法改变webpack的默认行为,由于add模块属于异步引入,对其拆分成一个单独的模块属于webpack的默认行为,所以splitChunks只能在add被拆分的基础上进行限制。
但是请你仔细考虑,maxAsyncRequests本身是不是就不包括异步引入的模块呢?
对于一个import动态引入的模块 其形式为
import SyncModuleA. // 预解析 import SyncModuleB // 预解析 import (AsyncModuleC) // 运行时对于同步引入的SyncModuleA & B 在整个模块被import的时候就会同步的下载这两个模块,但是对于动态引入的ModuleC 只有在运行到此的时候才会真正去加载,由此可见,异步引入模块是不包含在maxAsyncRequest中的 其本意是 在动态引入一个模块时,同步加载进来的模块数量,而其中的异步模块,并不属于 "同步加载进来的"
我们继续修改maxAsyncRequest = 2 你可以猜到打包结果了
 其中,add.js是webpack默认行为拆分的,不包含在maxAsyncRequests的计算中,所以maxAsyncRequests = import(TestModule) + import 'add.js' = 2 满足约束
其中,add.js是webpack默认行为拆分的,不包含在maxAsyncRequests的计算中,所以maxAsyncRequests = import(TestModule) + import 'add.js' = 2 满足约束
优化建议maxSize
maxSize表示,拆分的chunk最大值,当拆分出的chunk超过这个值的时候,webpack会尝试将其拆分成更小的chunks
maxSize是个 "建议性质"的限制,也就是webpack如果没有找到合适的切分点,maxSize将不起作用, 官方描述如下

maxSize的优先级 高于maxAsyncRequest / maxInitialRequest
看一个例子,
// main.js
import'react'
//webpack.config.js
optimization: {
runtimeChunk: true,
// splitChunks: false,
splitChunks: {
chunks: "all",
minSize: 0,
minChunks: 1,
maxInitialRequests: 1,
maxSize: 200,
enforceSizeThreshold: 0,
}}此时,react依旧会被拆分成小块,即便不满足maxInitialRequests,如下: