索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构
二叉树
在数据库或数据结构中,使用二叉树(尤其是普通二叉树)作为索引会存在以下几个关键问题,这些问题导致它在实际索引场景中很少被直接使用:
1. 查询效率不稳定(最坏情况)
- 问题:普通二叉树的查询时间复杂度为 O(h)(h 为树的高度)。在最坏情况下(如数据有序插入时形成链表),高度 h 等于节点数 n,查询效率退化为 O(n),远低于索引所需的高效查询要求(如 O (log n))。
- 示例:插入有序数据
1,2,3,4,5会形成单边树(链表),查询效率极差。
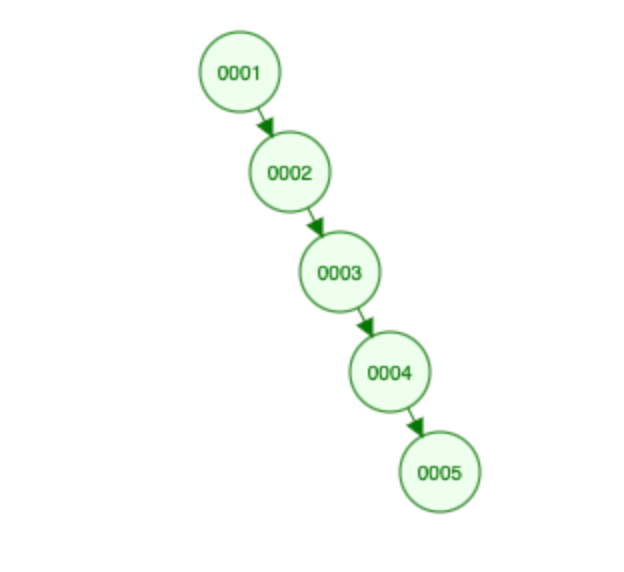
2. 频繁插入 / 删除导致树失衡
- 问题:普通二叉树不具备自平衡机制,频繁的插入和删除操作会导致树的高度增加,查询性能下降。
- 对比:平衡二叉树(如 AVL 树、红黑树)通过旋转操作维持树的平衡,但插入 / 删除开销较大,仍不适用于大规模数据。
3. 磁盘 I/O 效率低
- 问题:数据库索引通常存储在磁盘上,而二叉树每个节点的子节点数少(仅 2 个),导致树的高度高。每次查询需要多次磁盘 I/O(每次访问一个节点),效率低下。
- 对比:B 树 / B+ 树通过增加每个节点的子节点数(如几十到上千),显著降低树的高度,减少磁盘 I/O 次数。
4. 范围查询效率差
- 问题:二叉树的结构不适合范围查询。例如,查询某个区间
[a, b]的数据时,需要遍历多个不连续的节点,时间复杂度高。 - 对比:B+ 树的叶子节点形成有序链表,范围查询只需遍历链表,效率高(O (k),k 为结果集大小)。
5. 不适合高并发场景
- 问题:二叉树的插入 / 删除操作可能需要全局调整(如平衡旋转),导致锁粒度大,并发性能差。
- 对比:B+ 树通过分层锁机制(如行锁、页锁)支持更高的并发访问。
6. 空间利用率低
- 问题:二叉树每个节点仅存储少量数据(1~2 个键值),而磁盘 I/O 通常以页为单位(如 4KB),导致空间利用率不足。
- 对比:B 树 / B+ 树每个节点存储多个键值,充分利用磁盘页空间,减少 I/O 次数。
红黑树
红黑树是一种自平衡的二叉搜索树,它在普通二叉树的基础上增加了额外的颜色标记和平衡规则,以确保树的高度始终保持在对数级别,从而保证高效的插入、删除和查询操作。以下是红黑树与普通二叉树的核心区别:
特性 |
二叉树 |
红黑树 |
节点结构 |
每个节点包含:键值、左右子节点指针 |
每个节点额外包含:颜色标记(红 / 黑) |
平衡性 |
不保证平衡,最坏情况下退化为链表 |
通过颜色规则强制自平衡 |
树高 |
平均 O (log n),最坏 O (n) |
最长路径 ≤ 最短路径的 2 倍,O (log n) |
红黑树(插入 1,2,3,4,5 后的可能结构)
2(B)
/ \
1(B) 4(R)
/ \
3(B) 5(B)- 树高:3
- 查询效率:O(log 5) ≈ O(2.32)
应用场景
二叉树
- 简单数据存储:适用于数据量小且插入 / 删除不频繁的场景。
- 算法基础结构:作为其他复杂数据结构的基础(如 BST、AVL 树)。
红黑树
- 需要高效动态操作的场景:
- 数据库索引(如 MongoDB 的 B-tree 变种)。
- 编程语言标准库(如 C++ 的
std::map、Java 的TreeMap)。 - 操作系统(如 Linux 的进程调度、内存管理)。
- 需要稳定性能的场景:避免普通二叉树的最坏情况。
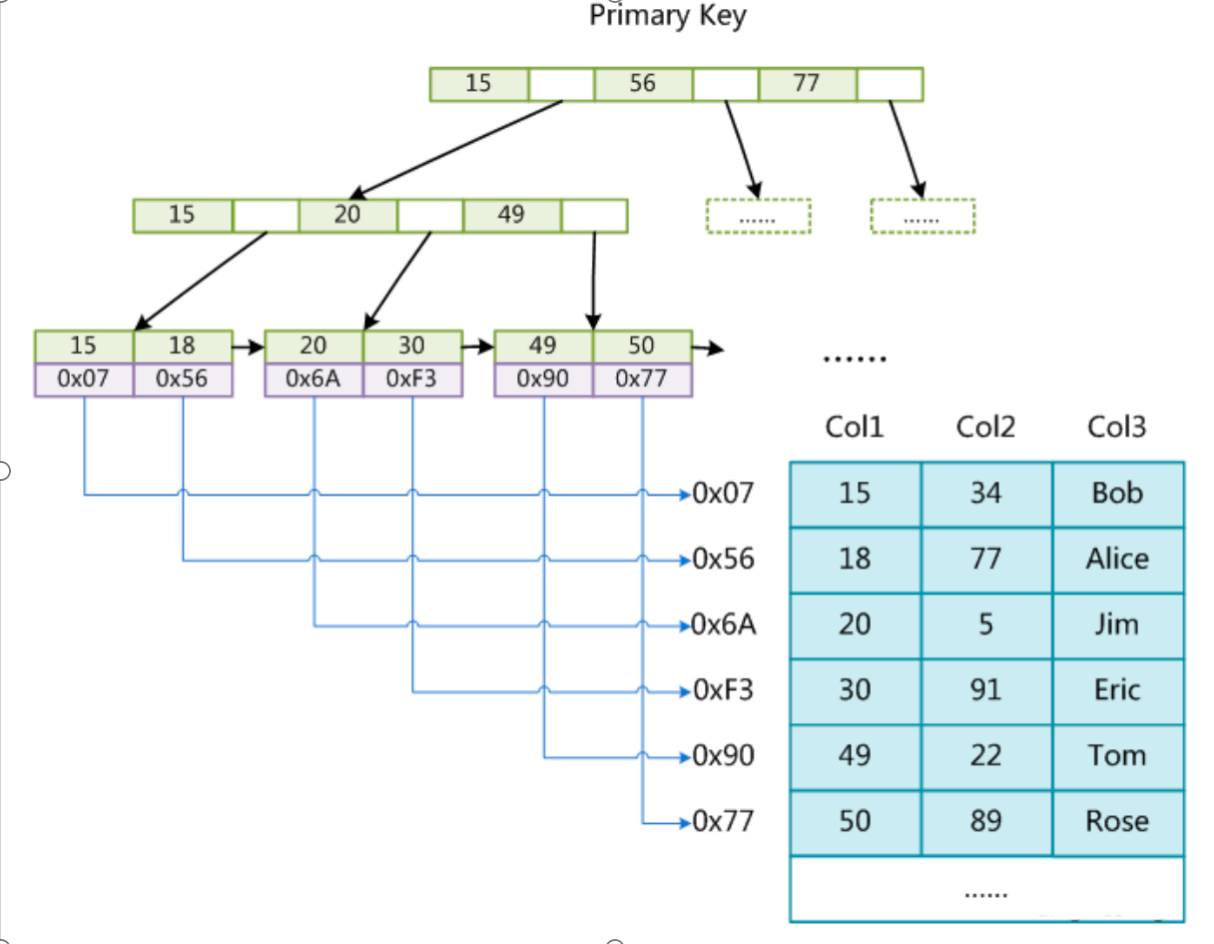
B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复:相同的索引值对应的记录指针保存在这个元素下面,如果重复记录特别多从会用链表存储,只存储首地址
- 节点中的数据索引从左到右递增排列:节点内部元索是有充的,节点之间整体也是有序的
- B-树一般是带数据保存的
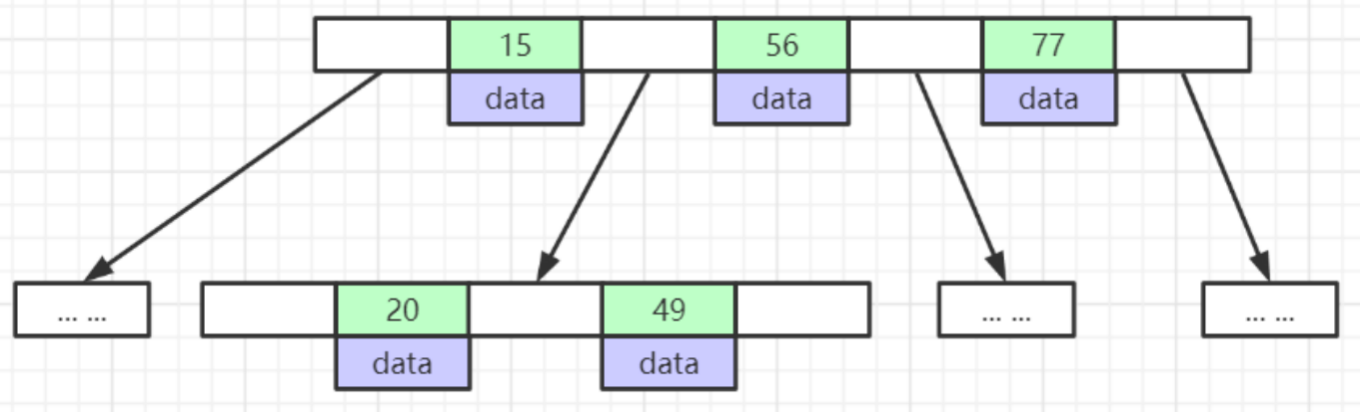
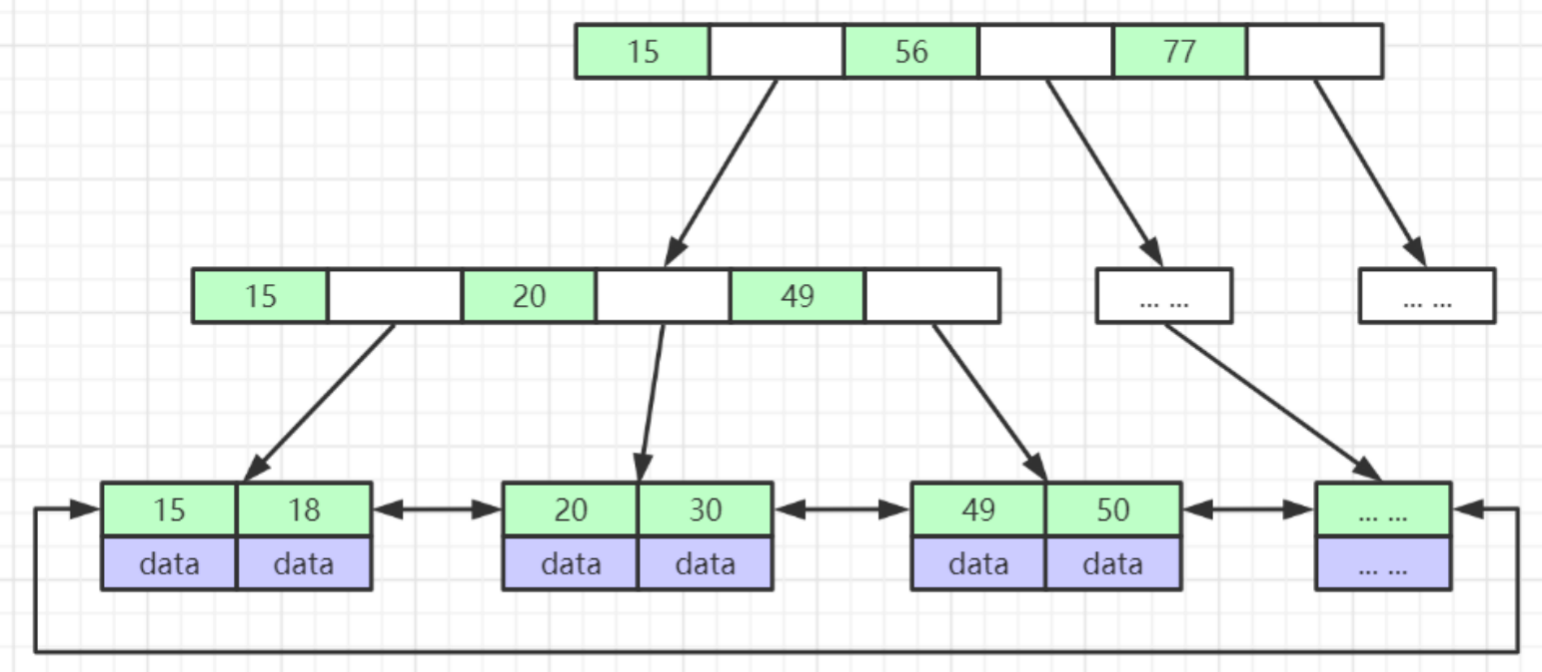
B+Tree(B-Tree变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
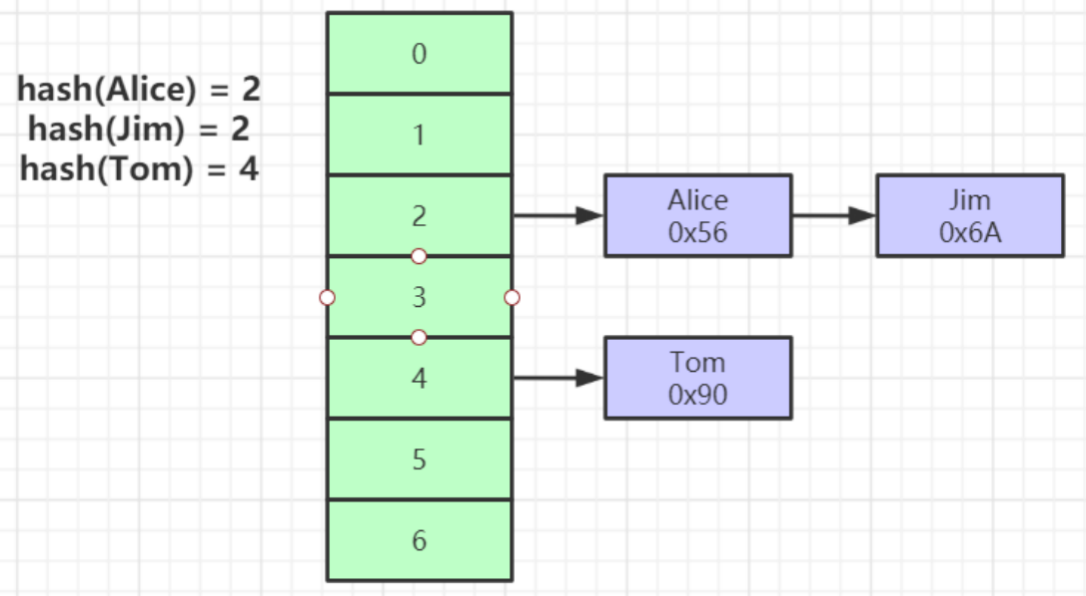
Hash
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+ 树索引更高效
- 仅能满足 “=”,“IN”,不支持范围查询
- hash冲突问题
MySQL存储引擎
MyISAM
MyISAM索引文件和数据文件是分离的(非聚集),获取数据每次都要回表
InnoDB
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录(主键对应的索引的叶子节点直接保存了这一行的完整数据)
- 为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
1.因为InnoDB的数据是保存在主键对应的索引的叶子节点下,即使不建主键,系统也会自动创建一个隐藏列做主键(类似RowID),引起不必要的性能开销。
2.自增主键在生成索引时效率更高,不用频率调整和拆分索引树节点
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
- 节省空间
- 一致性,如果存多份的话,当数据更新时要同步,较复杂,容易出错,会引起数据一致性问题
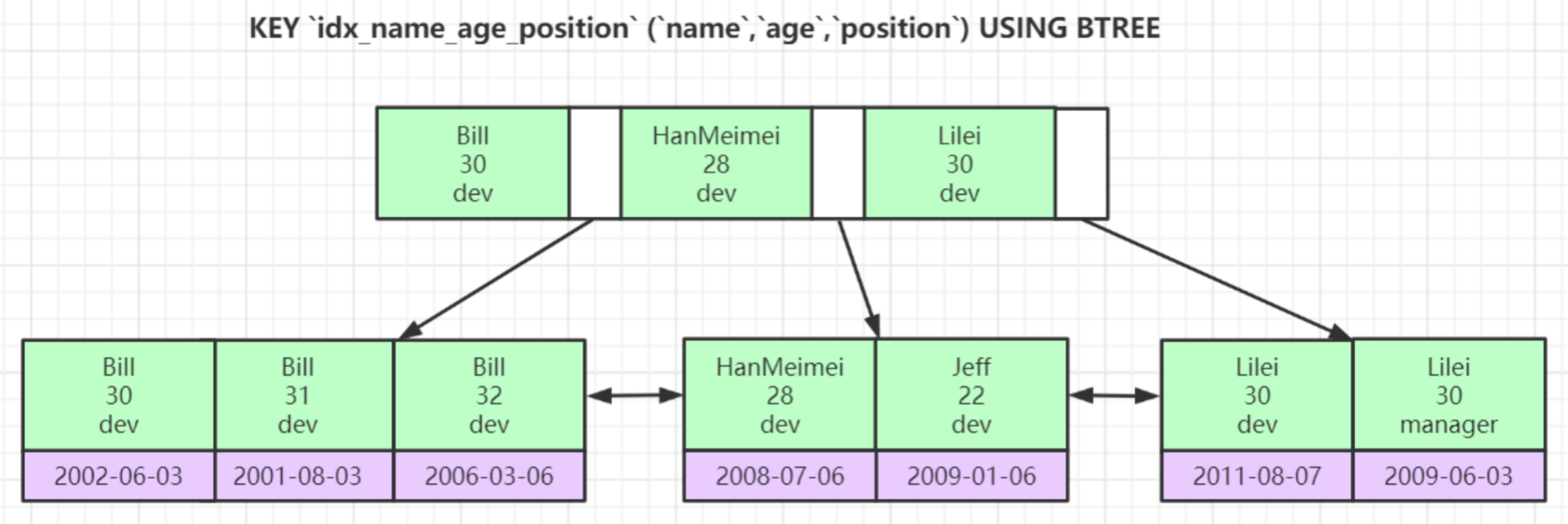
联合索引
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';关于最左前缀的补充
MySQL一定是遵循最左前缀匹配的,这句话在mysql8以前是正确的,没有任何毛病。但是在MySQL8.0中,就不一定了。
索引跳跃扫描
参考:https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html#range-access-skip-scan
索引跳跃扫描(Index Skip Scan)是MySQL 8.0.13引入的优化策略,用于在复合索引的前导列未被条件限制时,通过跳过前导列的重复值,对后续列进行范围扫描,从而减少数据访问量。以下是结合文档的详细解析:
一、核心原理
当复合索引为 (A, B)(A为前导列,B为后续列),且查询条件仅包含对B的范围过滤(如 WHERE B > 100)时:
- 传统方法:需扫描全索引(因A未被限制),性能较差。
- Index Skip Scan:
- 自动枚举A的唯一值:通过索引统计信息获取A的所有唯一值(如
A=1,A=2等)。 - 对每个A值执行子范围扫描:针对每个唯一的A值,构建条件
A=xxx AND B > 100,利用索引快速定位符合条件的B值范围。 - 跳过无效A值:仅扫描包含符合条件B值的A分组,减少不必要的索引访问。
- 自动枚举A的唯一值:通过索引统计信息获取A的所有唯一值(如
示例(文档中的案例):
表 t1 的主键为复合索引 (f1, f2),查询 WHERE f2 > 40:
- 索引结构中,
f1有唯一值1和2。 - 对每个
f1值执行f1=1 AND f2>40和f1=2 AND f2>40的子范围扫描,避免全索引扫描。
二、适用条件
根据文档,Index Skip Scan需满足以下条件:
- 索引结构:
复合索引至少包含两部分 ([A_1, ..., A_k,] B_1, ..., B_m, C),其中:
-
- A部分(前导列):可为空或包含多个列,但查询中必须使用等值条件(如
A=const或A IN (const列表))。 - C部分(后续列):必须存在范围条件(如
>,<,BETWEEN等)。 - B部分:可选,需与A部分组合使用等值条件。
- A部分(前导列):可为空或包含多个列,但查询中必须使用等值条件(如
- 查询限制:
- 仅访问单表,不涉及多表JOIN。
- 无
GROUP BY、DISTINCT、ORDER BY子句。 - 所有查询列均包含在索引中(覆盖索引)。
- 条件为合取式(
AND连接的OR条件),如(A=1 OR A=2) AND (B>10)。
- 系统配置:
optimizer_switch中的skip_scan标志需为on(默认开启)。- 可通过
FORCE INDEX强制使用特定索引。
三、执行流程与优化效果
- 执行步骤:
- 获取复合索引中前导列A的唯一值列表(通过索引统计或扫描)。
- 对每个唯一值
a_i,生成子条件A = a_i AND C的范围条件,利用索引快速定位对应范围。 - 合并所有子范围的结果,返回最终数据集。
- 优势:
- 减少索引扫描量:仅扫描包含有效C值的A分组,避免全索引遍历。
- 利用索引有序性:通过索引快速定位每个子范围,减少磁盘I/O。
- 性能对比:
- 全索引扫描:需遍历所有索引条目,过滤后返回结果。
- Index Skip Scan:扫描次数等于A的唯一值数量,每次扫描仅处理相关子范围,大幅提升效率。
四、在EXPLAIN中的体现
- Extra列:显示
Using index for skip scan,表明使用了索引跳跃扫描。 - possible_keys列:显示适用的复合索引。
- optimizer_trace:包含
skip_scan_range元素,记录索引使用细节和子范围条件。
五、限制与调优建议
- 限制:
- 前导列A的唯一值数量较多时(如百万级),枚举成本可能高于全扫描。
- 仅适用于非唯一索引,唯一索引场景无需跳跃扫描。
- 不支持空间索引(Spatial Index)的范围合并,需用
UNION替代。
- 调优建议:
- 通过
ANALYZE TABLE更新索引统计信息,确保前导列唯一值的准确性。 - 若性能未提升,可通过
SET SESSION optimizer_switch='skip_scan=off'禁用该优化。 - 对于包含大量唯一值的前导列,考虑修改索引结构或查询条件,直接限制前导列。
- 通过
六、与其他优化的对比
优化方法 |
适用场景 |
核心差异 |
Index Skip Scan |
复合索引前导列未限制,后续列有范围条件 |
枚举前导列唯一值,分批次扫描子范围 |
Loose Index Scan |
|
跳过重复的前导列值,仅取分组首行 |
Range Scan |
单索引列或复合索引全列范围条件 |
直接扫描连续索引区间,无需枚举唯一值 |
通过合理使用Index Skip Scan,可在传统范围扫描无法生效的场景下提升查询性能,尤其适用于复合索引的部分列过滤场景。