在推荐系统和广告点击率预测等场景中,特征交叉(Feature Interaction)是提升模型效果的关键。传统的因子分解机(FM)通过二阶特征交互取得了显著效果,但其线性建模方式和有限阶数限制了模型的表达能力。今天,我们将深入探讨神经因子分解机(NFM)——一种融合FM与深度学习的创新模型。NFM通过双线性交互池化(Bi-Interaction Pooling)和深度神经网络的结合,实现了高阶非线性特征交叉,同时避免了传统深度模型训练困难的问题。
接下来,我将深入对这篇论文展开全面解读。和以往一样,我会严格依照论文的结构框架,从研究背景、核心论点、实验设计到最终结论,逐一对文章的各个关键部分进行细致剖析 ,力求为大家呈现这篇时间序列预测论文的全貌,挖掘其中的研究价值与创新点。
1. Abstract
许多网络应用的预测任务需要对分类变量进行建模,例如用户ID以及性别、职业等人口统计特征。为了应用标准机器学习技术,这些分类预测变量通常通过独热编码转换为一组二元特征,导致生成的特征向量高度稀疏。为了有效利用此类稀疏数据进行学习,充分考虑特征间的交互作用至关重要。
因子分解机(Factorization Machines,FM)是一种利用二阶特征交互的流行解决方案。然而,FM以线性方式建模特征交互,可能不足以捕捉现实数据中非线性和复杂的内在结构。尽管深度神经网络近年来被工业界用于学习非线性特征交互(例如谷歌的Wide&Deep和微软的DeepCross),但其深层结构也使得模型训练变得困难。
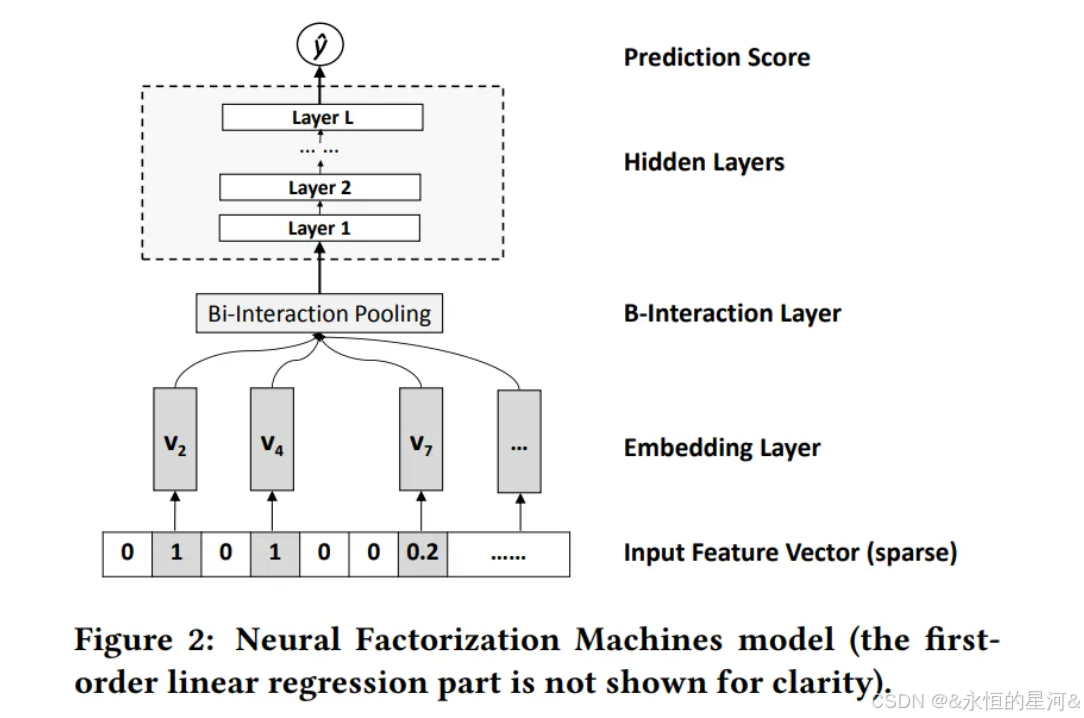
本文提出了一种新颖的稀疏场景预测模型——神经因子分解机(Neural Factorization Machine,NFM)。NFM无缝融合了FM建模二阶特征交互的线性能力与神经网络建模高阶特征交互的非线性能力。从概念上讲,NFM比FM更具表达能力,因为无隐藏层的NFM可视为FM的特例。在两个回归任务上的实验表明,仅使用单一隐藏层的NFM显著优于FM,相对性能提升达7.3%。与近期深度学习方法Wide&Deep和DeepCross相比,NFM采用更浅的网络结构却实现了更优性能,同时在实践中更易于训练和调参。
2. Introduction
预测分析是信息检索(IR)与数据挖掘(DM)诸多任务的核心技术,其应用涵盖推荐系统、定向广告、搜索排序、视觉分析及事件检测等领域。通常,预测任务被形式化为估计一个将预测变量映射至目标的函数——例如回归任务中的实值目标或分类任务中的类别目标。与图像、音频中自然存在的连续型预测变量(如原始特征)不同,网络应用的预测变量多为离散型分类变量。例如在线广告场景中,我们需要预测特定职业(第二预测变量)的用户(第一预测变量)点击广告(第三预测变量)的可能性(目标)。针对这类分类预测变量,常规解决方案是通过独热编码将其转换为二元特征集(即特征向量),进而应用逻辑回归、支持向量机等标准机器学习(ML)技术。