基于学习的围手术期时间数据肝切除术后肝衰竭早期检测:中国全国性多中心回顾性研究
期刊:eClinicalMedicine
IF:9.6
发布时间:2025/05/06
亮点(可借鉴):(1)多中心数据,多中心特征的分布情况对模型泛化性能力的表征;(2)围术期不同时间阶段特征对模型性能,特征重要性的比较;(3)亚组分析;(4)不同条件下(不同缺失程度,不同特征数量)模型的性能比较;
关键词:多中心,时序数据,深度学习
材料与方法
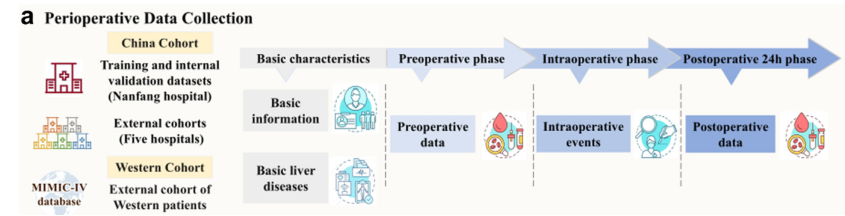
数据来源
2018 年 11 月至 2023 年 12 月来自六家医院中接受肝切除术的患者。
- 南方医院(南方队列)收集的 852 例患者被随机分配到训练组(681 名患者)和内部验证组(171 名患者)。
- 980 名患者组成的外部验证队列来自佛山市第一人民医院(101 名患者,外部队列 1)、广东省中医院(180 名患者,外部队列 2)、深圳市第三人民医院(72 名患者,外部队列 3)、西南医科大学附属医院(416 名患者,外部队列 4)和北京协和医院(211 名患者,外部队列 5)。
- 242 例患者组成的西方外部验证队列,来自MIMIC数据库。
数据类型
包括基线资料,术前资料,术中资料和术后24h资料。具体指标可参考文中Table 1。
模型框架
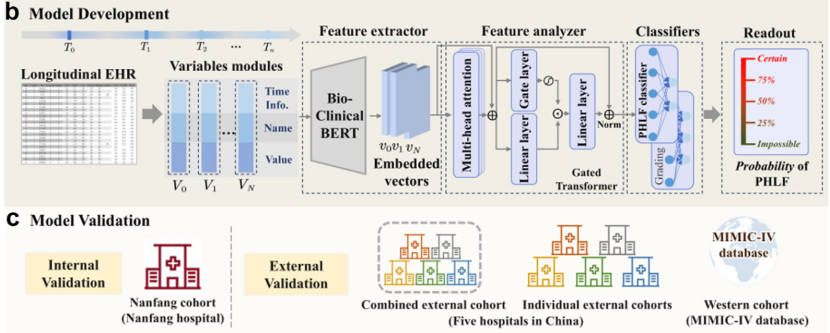 使用Bio-Clinical BERT (BC-BERT)作为基础模型,将时间数据编码成高维特征嵌入,利用上下文感知Transformer模块进行特征提取,分析不同时期的特征与结局之间的关系。采用两层MLP模型作为主分类器,分别用于PHLF检测和PHLF分级预测(本文的两个主要预测目的)。
使用Bio-Clinical BERT (BC-BERT)作为基础模型,将时间数据编码成高维特征嵌入,利用上下文感知Transformer模块进行特征提取,分析不同时期的特征与结局之间的关系。采用两层MLP模型作为主分类器,分别用于PHLF检测和PHLF分级预测(本文的两个主要预测目的)。
结果
PHLF检测模型
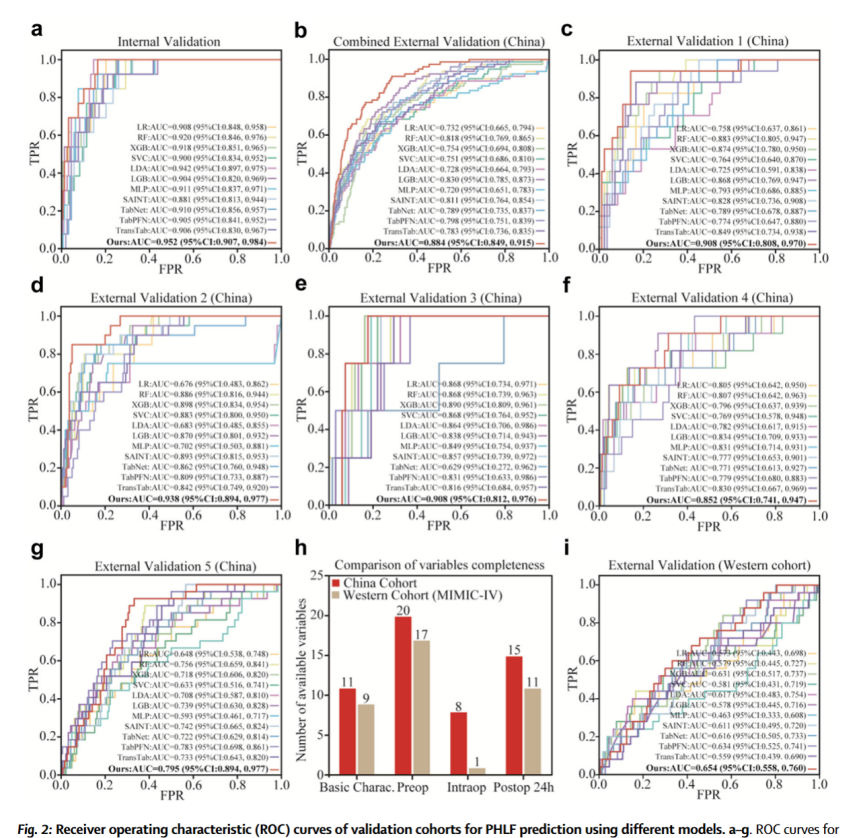
将我们的模型与其他 11 种机器学习和深度学习算法进行了比较,包括 LR、RF、XGB、SVC、LDA、LGB、MLP、自我注意和样本间注意力转换器 (SAINT)、TabNet、TabPFN 和 TransTab。
曲线下面积 (AUC) 和 F1 评分作为核心指标来评估我们的方法和比较方法在验证数据集上的性能。非参数 bootstrap 重采样技术评估 AUC 的置信区间。采用 Delong 检验对 AUC 进行统计比较。
结果表明在内部验证集中,PHLF的早期检测方面表现出最佳性能,AUC 为 0.952 (95% CI: 0.907–0.984) (图 2a)。同时,在约登指数最大化的最佳临界值处计算敏感性、特异性、 PPV 、 NPV 、准确性和 F1 评分(表2) ,表现为F1 评分 (0.643) 、 Kappa (0.611) 、 MCC (0.613) 、灵敏度 (0.692) 以及更高的准确性 (0.942) 和特异性 (0.962) 。在五个单独的外部验证队列中,我们的模型仍然实现了 0.880 的平均 AUC(范围:0.795-0.938),优于其他比较方法(图 2b-g)。
PHLF检测模型可解释性解释
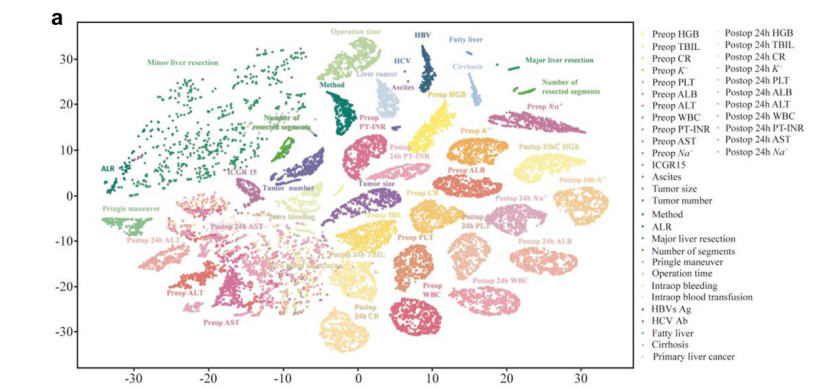
将来自不同医院不同时间阶段的特征(包括基本特征、术前、术中和术后特征)编码为高维特征嵌入并采用t-SNE可视化,结果显示这些特征在不同中心之间存在不一致性,而不同阶段的手术数据的分离表明不同阶段的特征能独立为模型提供不同的贡献。
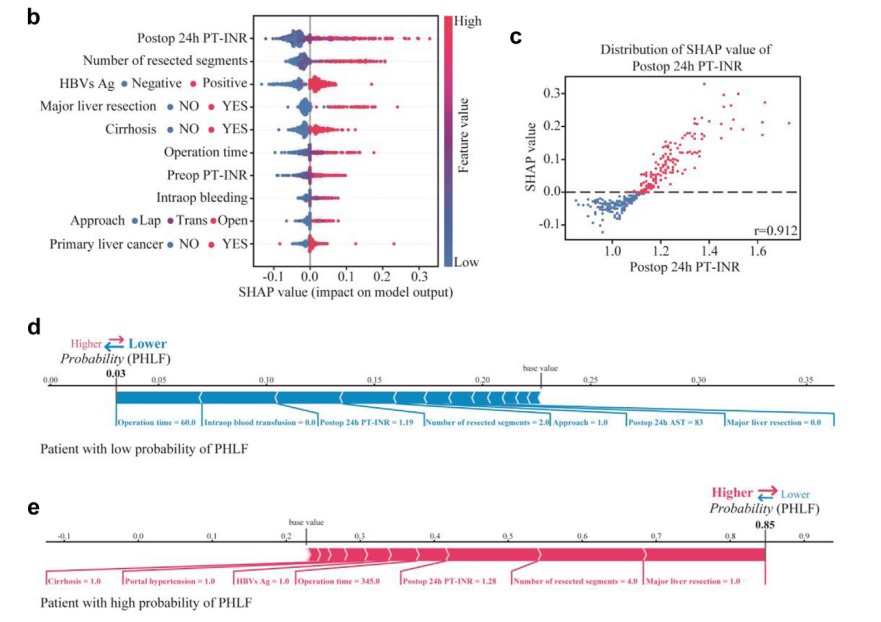
SHAP方法用于解释模型的预测结果,并分析每个特征对预测结果的影响。
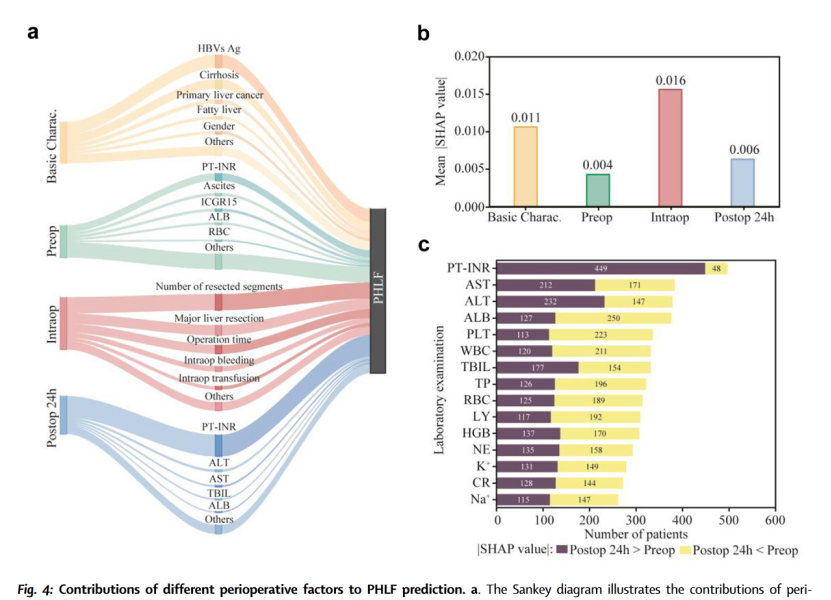
不同时间阶段特征对模型的贡献程度比较
图 4b 显示了术中特征类别对早期PHLF 发现的贡献最大(平均 SHAP值)。比较术前和术后各个特征的 SHAP 值表明,术后阶段的 PT-INR、AST、ALT 和 TBIL 的贡献比术前阶段更显着(图 4c)
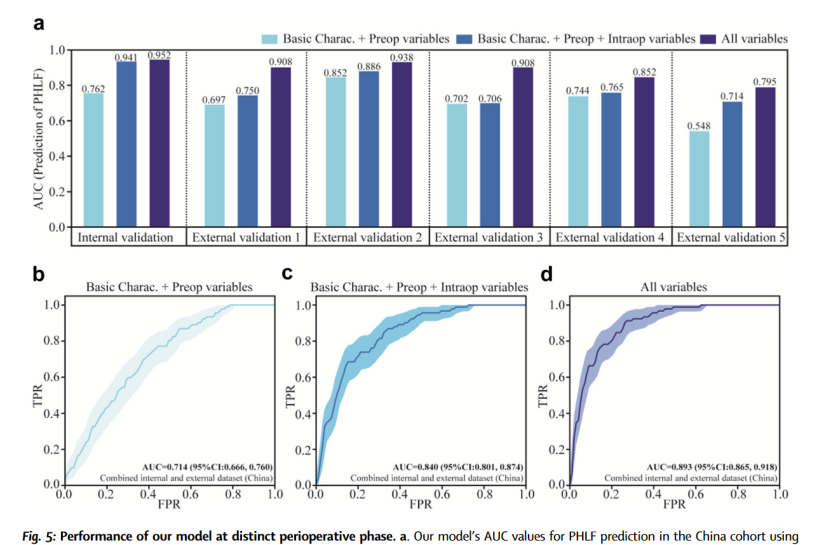
不同时间阶段特征对模型的性能评估
使用不同时间阶段的围手术期数据比较模型的性能。结果表明利用所有围手术期数据显示出最高的 AUC。强调了整合所有围手术期数据以全面评估 PHLF 的重要性。
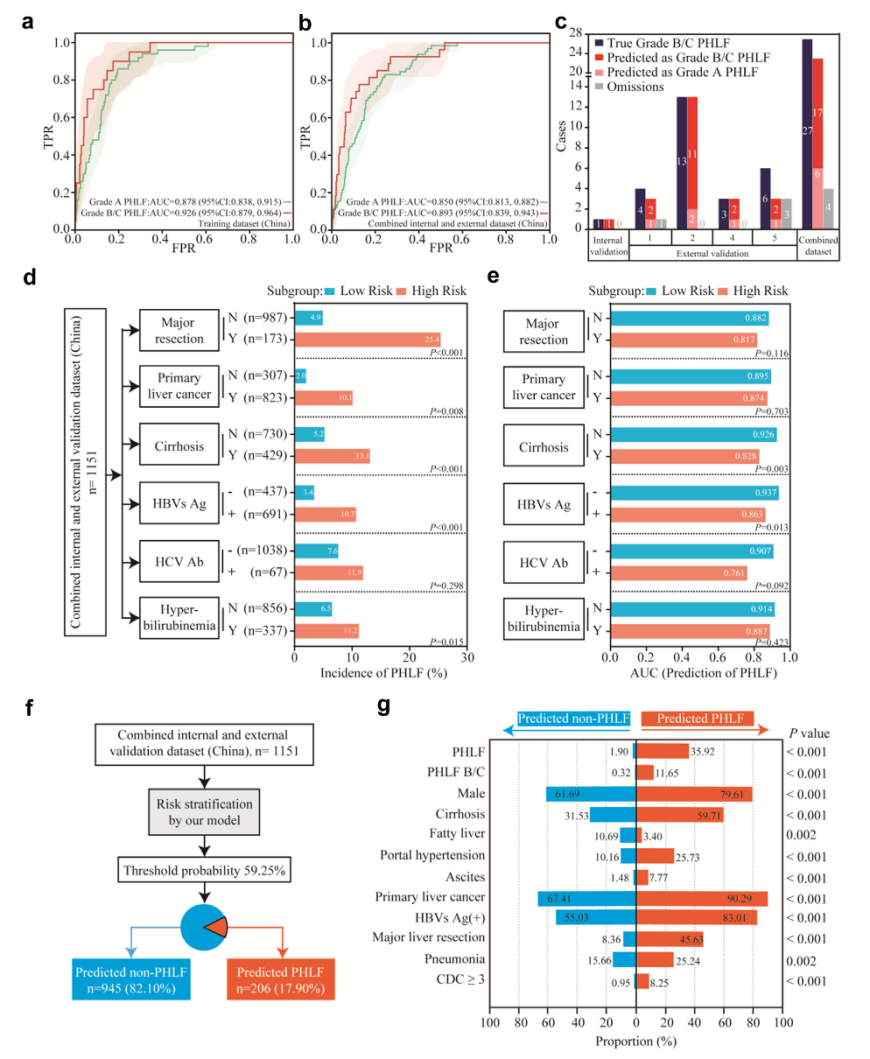
分级预测模型性能评估及亚组分析
中国队列的训练数据集 (a) 和内部和外部验证组合数据集 (b) 中预测 A 级 PHLF 和 B/C PHLF 的 ROC 曲线。亚组分析(d) 按不同风险分层后,患者的 PHLF 发生率,(e) AUC 值。(f) 中国队列中内部和外部验证联合患者的风险分层流程图 (n = 1151)。该模型使用 59.25% 的阈值概率将患者分为“预测的非 PHLF”组 (n = 945, 82.10%) 和“预测的 PHLF” 组 (n = 206, 17.90%)。(g) “预测的非 PHLF”之间关键临床特征和结果的比较
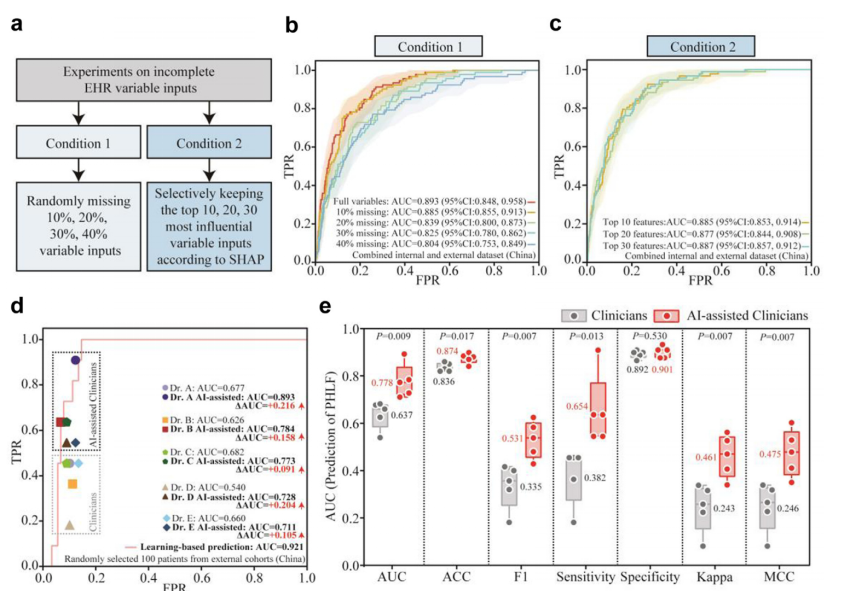
不同条件下(不同缺失程度,不同特征数量)模型的性能比较
图b,c分别评估在随机变量缺失不同程度下预测模型 PHLF 的AUC变化,仅使用前 10、20 和 30 个 SHAP 排名的变量输入预测模型 PHLF 的 ROC 曲线。d 和e展示了我们的模型与临床医生之间的早期 PHLF 检测性能比较。