1、引言
1.1、CosyVoice2 简介
阿里通义实验室推出音频基座大模型 FunAudioLLM,包含 SenseVoice 和 CosyVoice 两大模型。
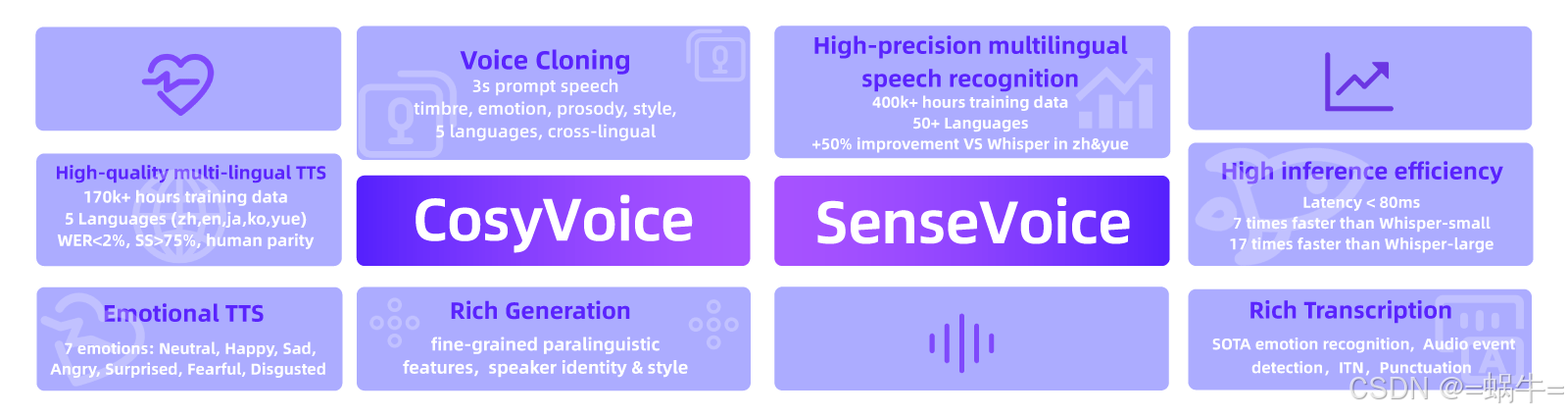
CosyVoice:模拟音色与提升情感表现力
多语言
- 支持的语言: 中文、英文、日文、韩文、中文方言(粤语、四川话、上海话、天津话、武汉话等)
- 跨语言及混合语言:支持零样本的跨语言和代码转换场景的语音克隆。
超低延迟
- 双向流支持: CosyVoice 2.0 集成了离线和流式建模技术。
- 快速首包合成: 在保持高质量音频输出的同时,实现了低至150毫秒的延迟。
高精度
- 改进发音: 与CosyVoice 1.0相比,减少了30%到50%的发音错误。
- 基准测试成就: 在Seed-TTS评估集的困难测试集中达到了最低字符错误率。
强稳定性
- 音色一致性: 确保了在零样本和跨语言语音合成中的可靠音色一致性。
- 跨语言合成: 相比1.0版本有了显著提升。
自然体验
- 增强韵律和音质: 改善了合成音频的一致性,将MOS评分从5.4提高到了5.53。
- 情感和方言灵活性: 现在支持更多细粒度的情感控制和口音调整。
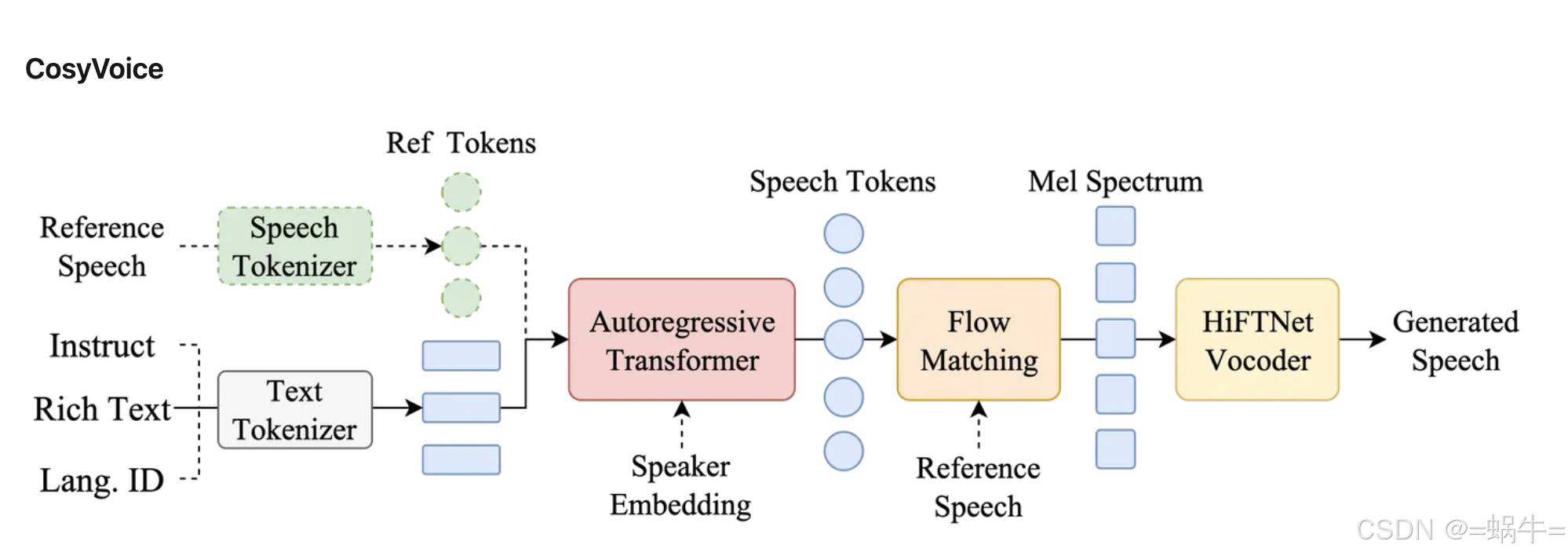
CosyVoice 由一个自回归变换器(用于为输入文本生成相应的语音标记)、一个基于 ODE 的扩散模型、流匹配(用于从生成的语音标记重建梅尔频谱)和一个基于 HiFTNet 的声码器(用于合成波形)组成。虚线模块在特定模型用途中是可选的,例如跨语言、SFT 推理等。
1.2、CosyVoice2 资源

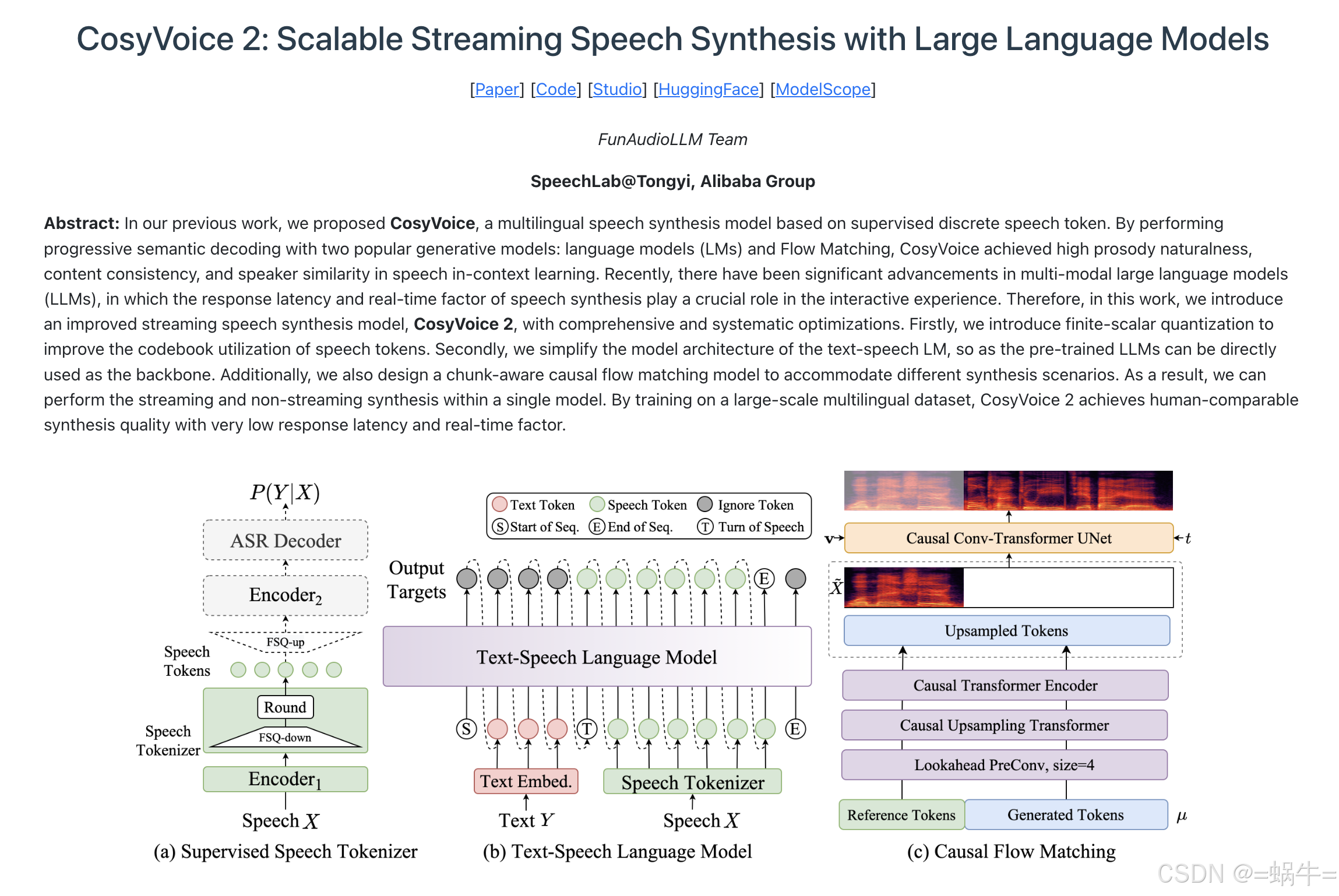
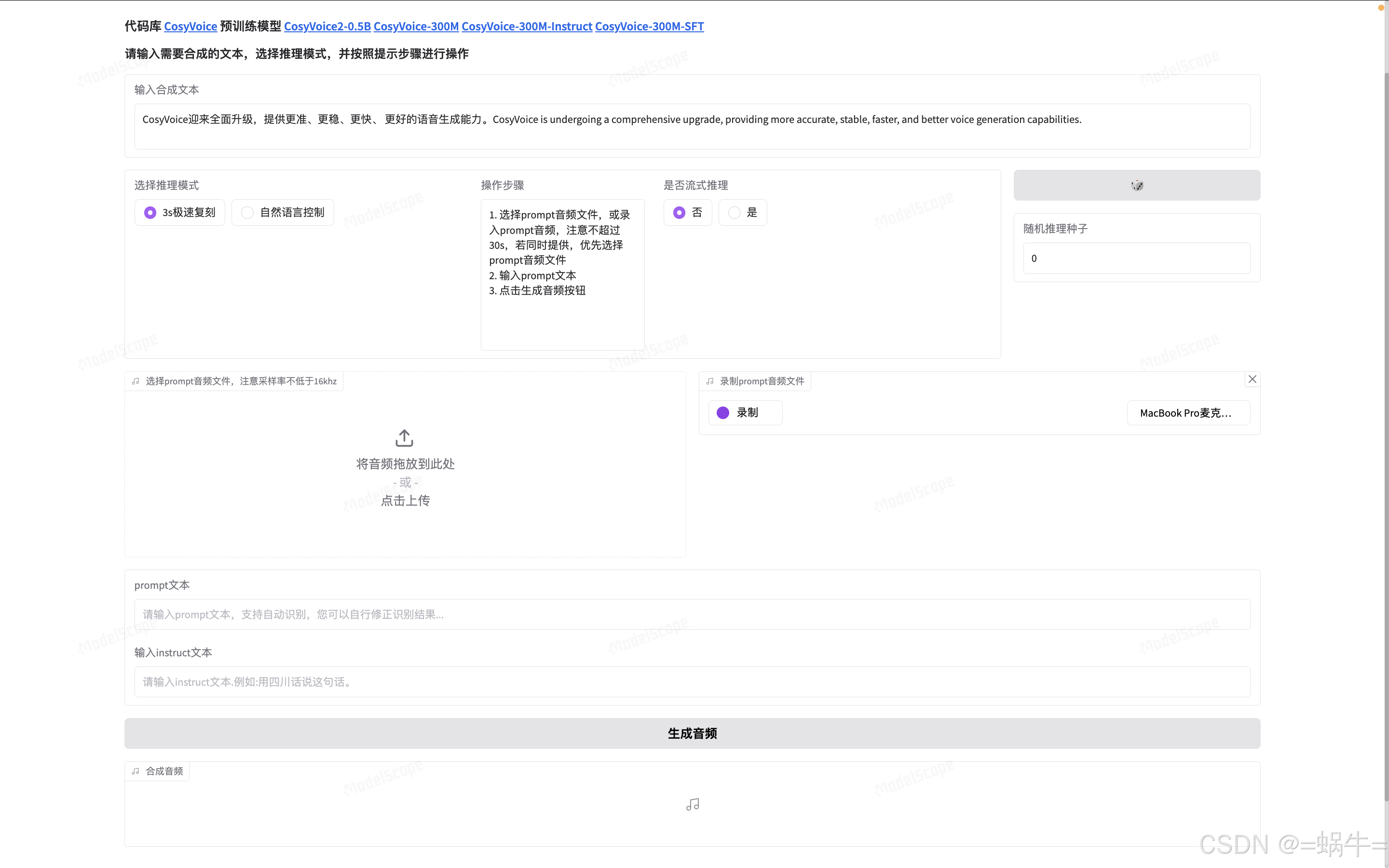
2、安装
2.1、安装 Anaconda
2.2、创建独立环境
# 创建一个名为 wn_cosyvoice 的环境,并指定在该环境中安装 Python 3.10 版本
conda create -n wn_cosyvoice -y python=3.10
# 激活并选择环境
conda activate wn_cosyvoice
2.3、下载 CosyVoice2-0.5B 模型
魔搭平台下载(推荐)
# 安装魔搭社区
pip install modelscope
# 下载 CosyVoice2-0.5B 模型到本地指定目录(替换自己本地路径)
modelscope download --model iic/CosyVoice2-0.5B --local_dir C:\Users\woniu\model\FunAudioLLM\CosyVoice2-0.5B
HF Mirror 下载(模型不是最新的,不建议)
# 列出当前 Conda 环境中所有环境变量的配置
conda env config vars list
# 设置模型下载国内镜像地址,解决因网络问题导致的模型下载失败
# 将 Hugging Face 的模型下载镜像设置为国内的镜像地址(https://hf-mirror.com),以加快模型下载速度
conda env config vars set HF_ENDPOINT="https://hf-mirror.com"
# 安装 huggingface_hub 包,这是一个用于与 Hugging Face 模型中心交互的命令行工具
conda install -c conda-forge huggingface_hub
# 下载 CosyVoice2-0.5B 模型到本地指定目录(替换自己本地路径)
huggingface-cli download FunAudioLLM/CosyVoice2-0.5B --local-dir C:\Users\woniu\model\FunAudioLLM\CosyVoice2-0.5B --resume-download
2.4、安装 Python 项目依赖项
直接按照官方仓库文档在 Windows 上安装通常会失败。请务必严格按照以下顺序执行命令。
# 进入到存放 GitHub 代码目录,例如:
cd C:\Users\woniu\github
# 克隆 FunAudioLLM/CosyVoice 仓库,包括其子模块。
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
# 进入 CosyVoice 项目目录,后续命令通常需要在此目录下执行
cd CosyVoice
# 安装项目所需的依赖项,-i 参数指定使用阿里云的 PyPI 镜像,
# --trusted-host 参数指定信任该镜像的主机名,以加快依赖安装速度
# Windows 环境需要修改 requirements.txt 并安装剩余依赖
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirr
Windows 环境注意事项:

Windows 环境继续安装指定版本依赖库(刚才删除的依赖,手动安装)
# 安装指定版本的 pynini 包(版本 2.1.5),-y 参数用于自动确认安装
conda install -y -c conda-forge pynini==2.1.5
# 安装指定版本的 WeTextProcessing 包(版本 1.0.3)
pip install WeTextProcessing==1.0.3
2.5、GPU 加速(根据自己电脑配置)
# 验证 GPU 环境是否可用
python -c "import torch; print(torch.__version__); print(torch.version.cuda); print(torch.cuda.is_available())"
# 卸载 CPU 版本 torch
pip uninstall torch torchvision torchaudio
# 安装 GPU 版本 torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
3、项目
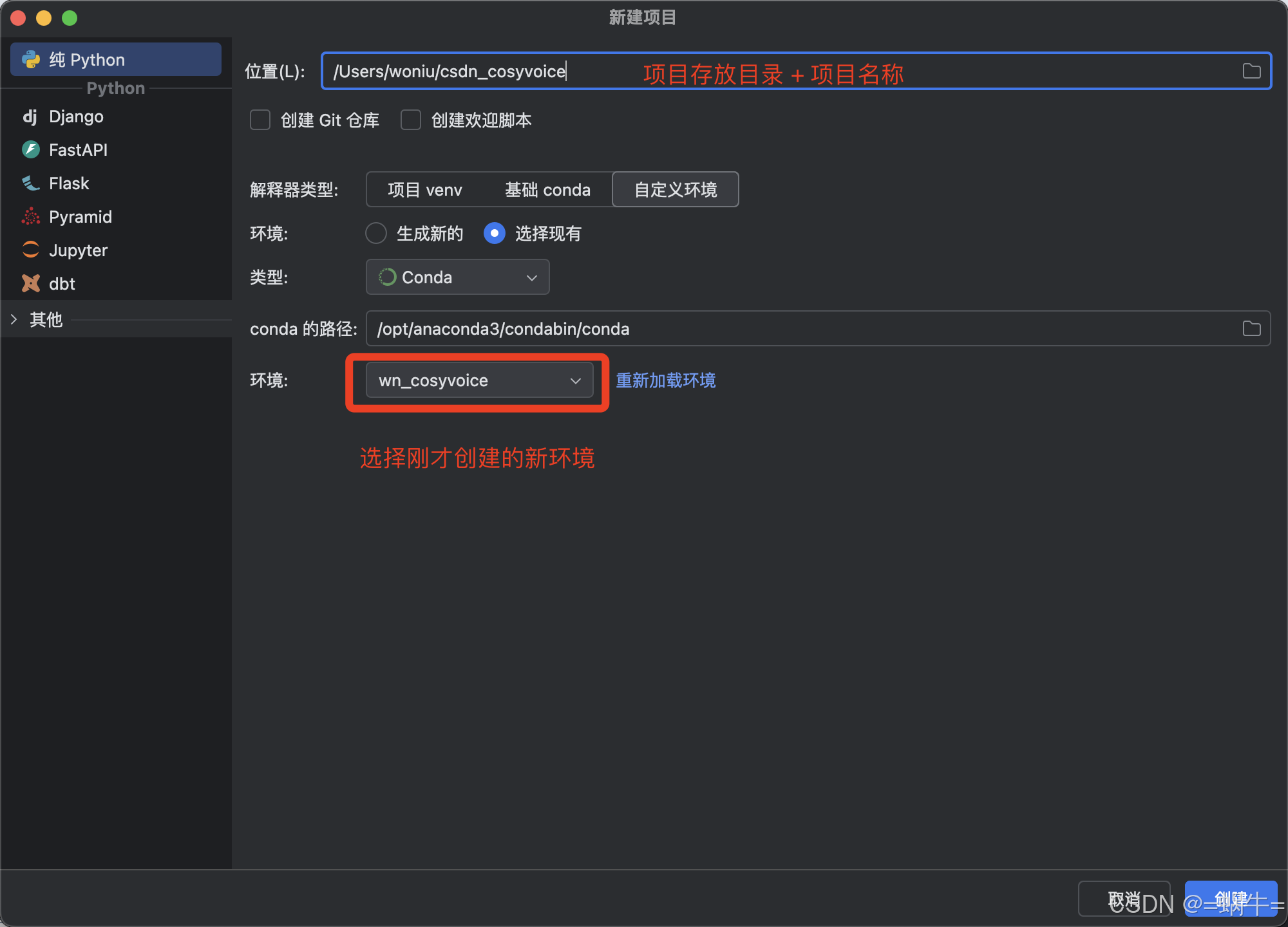
3.1、创建新项目
使用 PyCharm 工具创建一个新的 Python 项目,环境选择刚才创建的新环境
3.2、示例代码
import sys
import torch
import torchaudio
# 将 CosyVoice 项目目录添加到 sys.path
sys.path.append('C:\\Users\\woniu\\github\\CosyVoice')
# 将 Matcha-TTS 项目目录添加到 sys.path
sys.path.append('C:\\Users\\woniu\\github\\CosyVoice\\third_party\\Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice2
from cosyvoice.utils.file_utils import load_wav
class CosyVoice2Demo:
def __init__(self):
print("CosyVoice2Demo 初始化")
# 模型地址(加载本地离线模型)
model_path = r"C:\Users\woniu\model\FunAudioLLM\CosyVoice2-0.5B"
# 检查当前环境中是否支持 NVIDIA 的 CUDA 平台
device = "cuda" if torch.cuda.is_available() else "cpu"
self.cosyvoice = CosyVoice2(model_path, load_jit = False, load_trt = False, fp16 = False, use_flow_cache = False)
# 文本转语音
def text_to_speech(self, text):
# zero_shot_prompt.wav 文件替换为自己的路径
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(self.cosyvoice.inference_zero_shot(
text,
'希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], self.cosyvoice.sample_rate)
for i, j in enumerate(self.cosyvoice.inference_cross_lingual(
'在他讲述那个荒诞故事的过程中,他突然[laughter]停下来,因为他自己也被逗笑了[laughter]。',
prompt_speech_16k, stream=False)):
torchaudio.save('fine_grained_control_{}.wav'.format(i), j['tts_speech'], self.cosyvoice.sample_rate)
# instruct usage
for i, j in enumerate(self.cosyvoice.inference_instruct2(
text,
'用四川话说这句话', prompt_speech_16k, stream=False)):
torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], self.cosyvoice.sample_rate)
if __name__ == "__main__":
wnDemo = CosyVoice2Demo()
text = '您好,很高兴认识您!'
wnDemo.text_to_speech(text)