一级目录
二级目录
三级目录
优化器
在PyTorch中,优化器作用是管理并更新模型的可学习参数(如权值和偏置 ),使模型输出更接近真实标签。具体表现为:
- 基于梯度更新参数:通过反向传播得到损失函数对模型参数的梯度后,依据梯度信息,按照特定优化策略(如梯度下降及其变体 )调整参数值,使损失函数值逐步减小,让模型预测更准确。比如随机梯度下降(SGD)优化器,每次依据当前参数梯度来更新参数 。
- 提供多种优化策略:PyTorch提供如SGD、Momentum、AdaGrad、RMSprop、Adam等多种优化器,每种有不同更新规则和机制,适应不同训练需求。像Adam结合动量和自适应学习率思想,收敛快,适用于大规模数据集;AdaGrad适合处理稀疏特征数据,能自适应调整参数学习率 。
- 管理参数组:可管理不同的参数组,为每组参数设置不同超参数(如学习率 ),灵活调整模型不同部分参数更新方式。
1. 用法说明
这是PyTorch中 torch.optim 优化器相关的使用说明,具体讲解如下:
整体功能
torch.optim 是实现各种优化算法的包,支持常见优化方法,且接口通用,方便后续集成更复杂的算法。
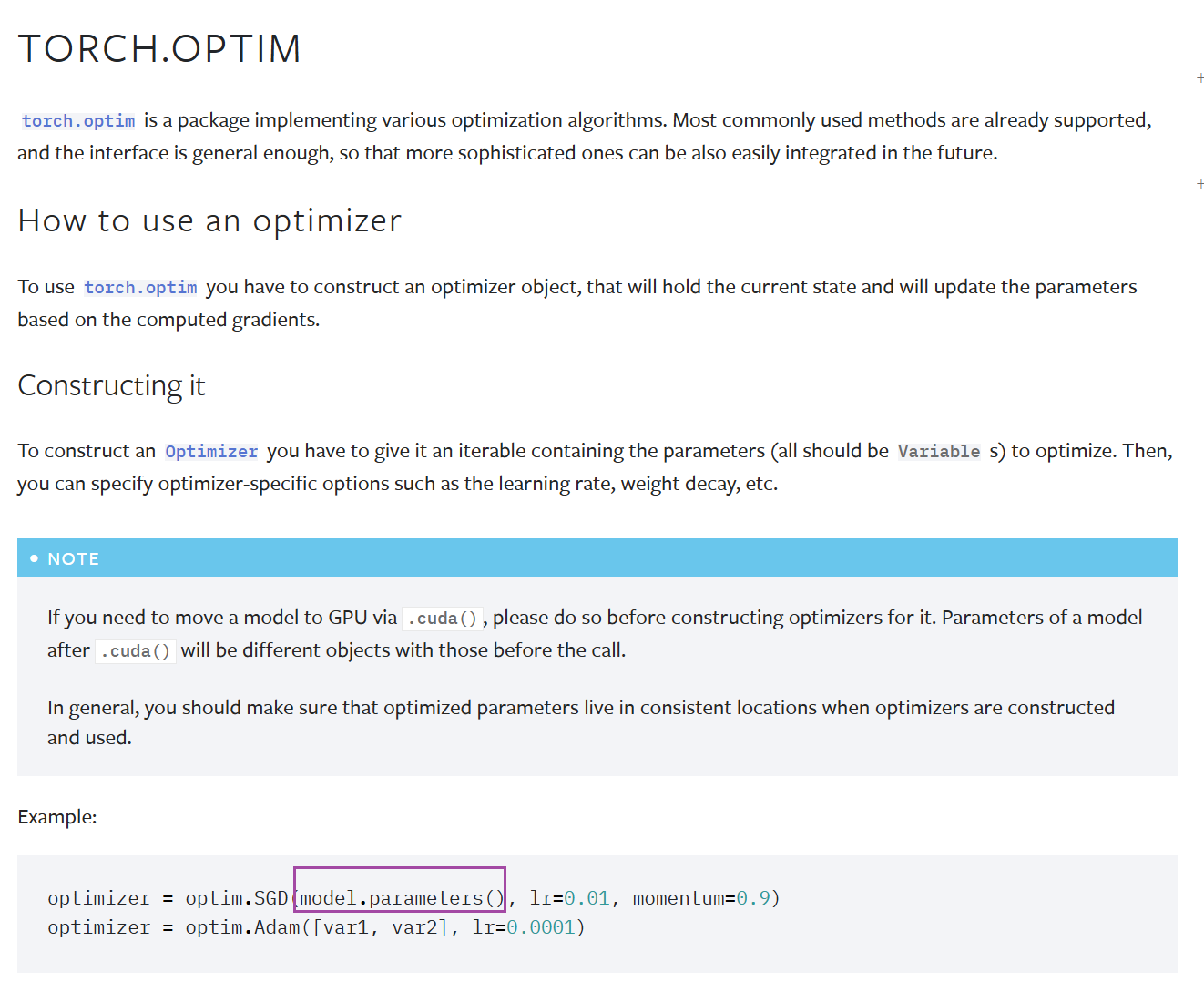
构建优化器
- 步骤:构建优化器对象时,需传入一个可迭代对象(含要优化的参数,这些参数通常是模型中的权重等,类型应为
Variable,在新版PyTorch中,Variable已和Tensor合并 ),还可指定优化器特定选项,如学习率(lr)、权重衰减(weight decay)等 。 - 注意事项:若要将模型移至GPU(通过
.cuda()方法 ),需在构建优化器之前操作。因为调用.cuda()后模型参数对象会改变,要确保优化器构建和使用时,优化的参数在一致位置。 - 示例:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9):构建随机梯度下降(SGD)优化器,对model的参数进行优化,学习率设为0.01,动量设为0.9。optimizer = optim.Adam([var1, var2], lr=0.0001):构建Adam优化器,对var1和var2这两个参数进行优化,学习率为0.0001。
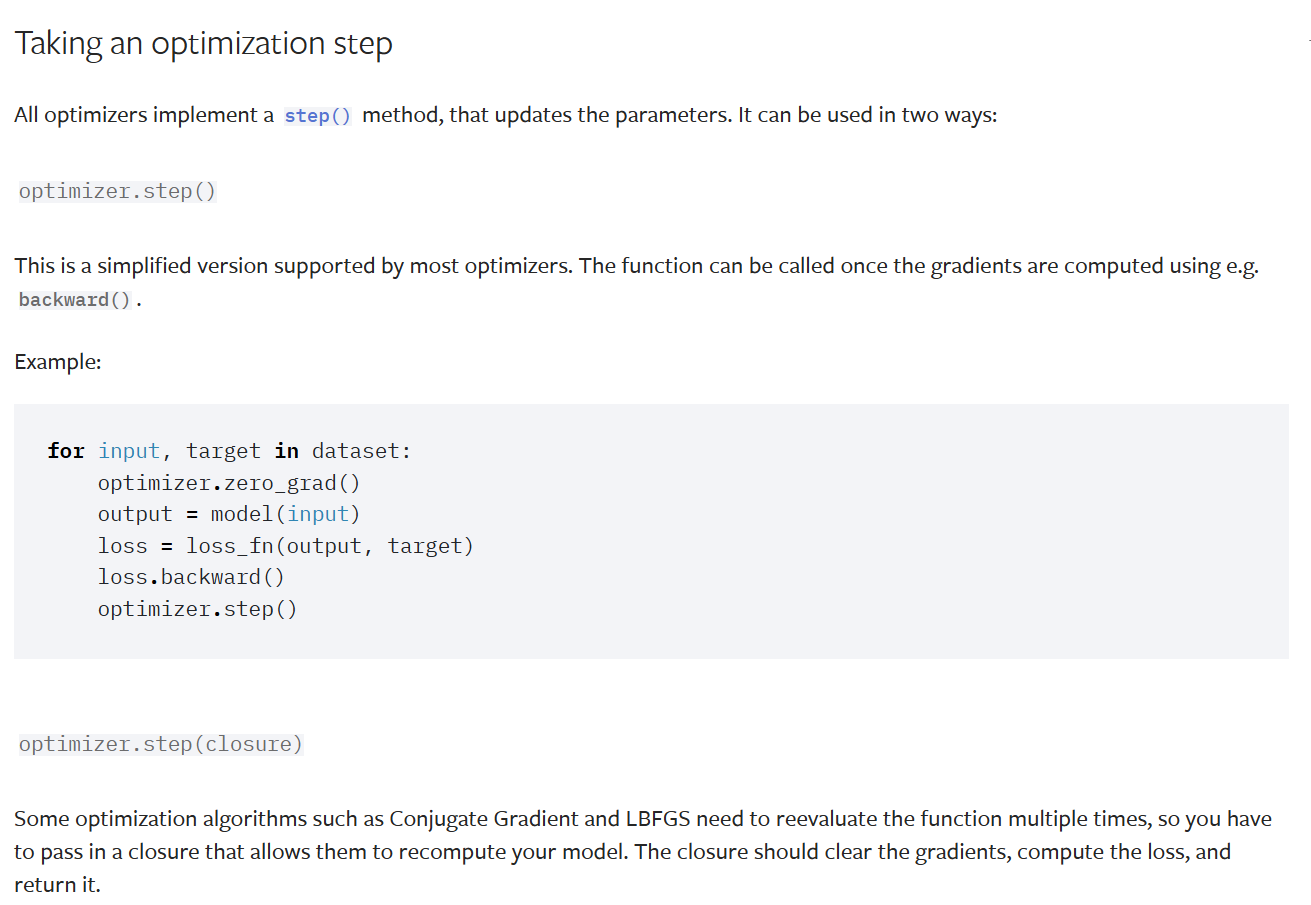
执行优化步骤
optimizer.step()方法:所有优化器都实现了step()方法用于更新参数。一种常见使用方式是在通过反向传播(如loss.backward())计算出梯度后调用。例如代码示例中,每次迭代时,先清空梯度(optimizer.zero_grad()),模型前向传播得到输出(output = model(input)),计算损失(loss = loss_fn(output, target)),反向传播计算梯度(loss.backward()),最后调用optimizer.step()更新参数。optimizer.step(closure)方法:对于共轭梯度(Conjugate Gradient )和L - BFGS等一些优化算法,需要多次重新评估函数,所以要传入一个闭包(closure)。闭包应实现清空梯度、计算损失并返回损失值的功能,以便这些算法重新计算模型。
2. 相应代码
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("das",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Test(nn.Module):
def __init__(self):
super(Test,self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
test = Test()
optim = torch.optim.SGD(test.parameters(), lr = 0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = test(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad() # 把上一轮的梯度清除为0,因为上一轮的梯度对于本轮不起作用
result_loss.backward() # 损失函数的反向传播,求出每一个节点的梯度
optim.step() # 调用优化器,对模型中的参数进行调优
# print(result_loss)
running_loss = running_loss + result_loss
print(running_loss)
运行结果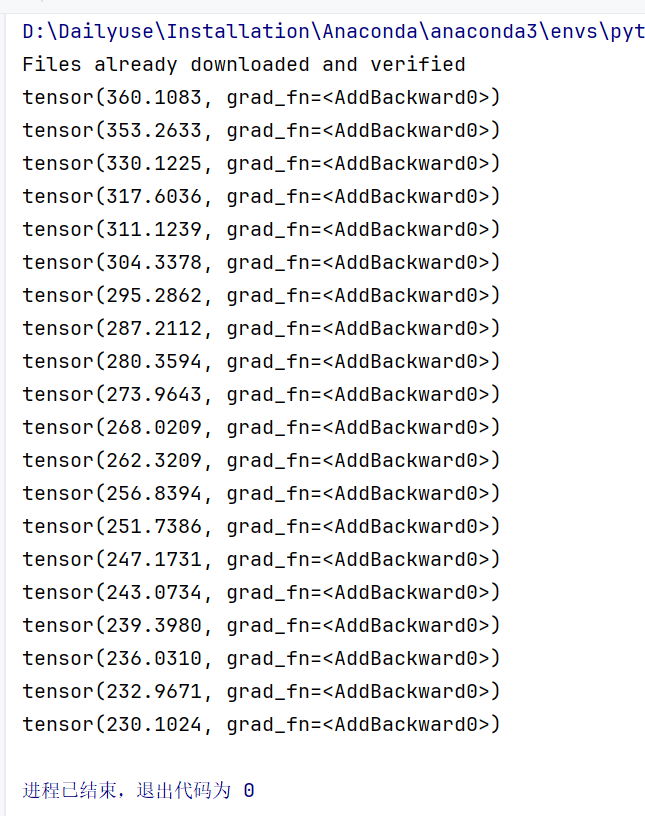
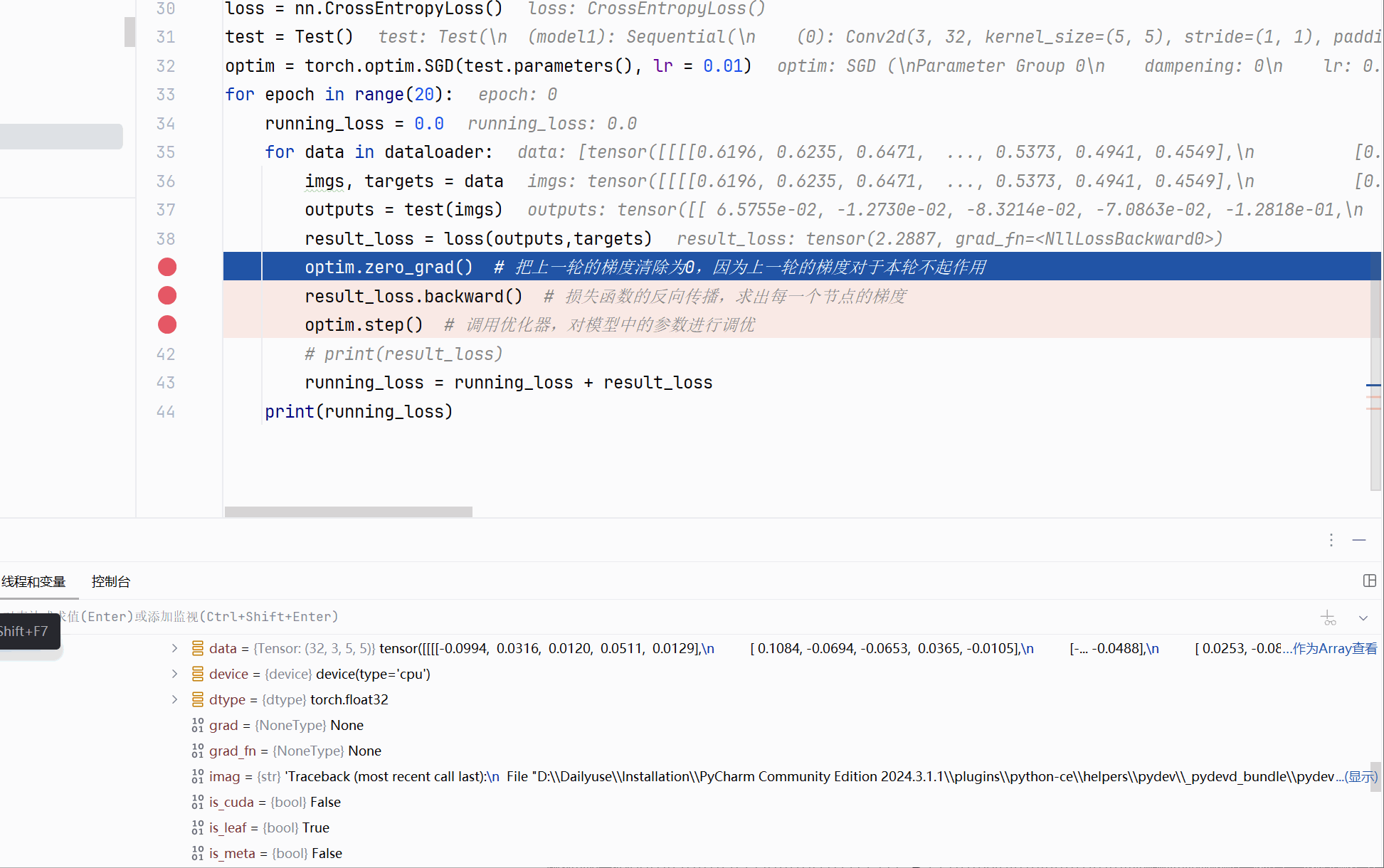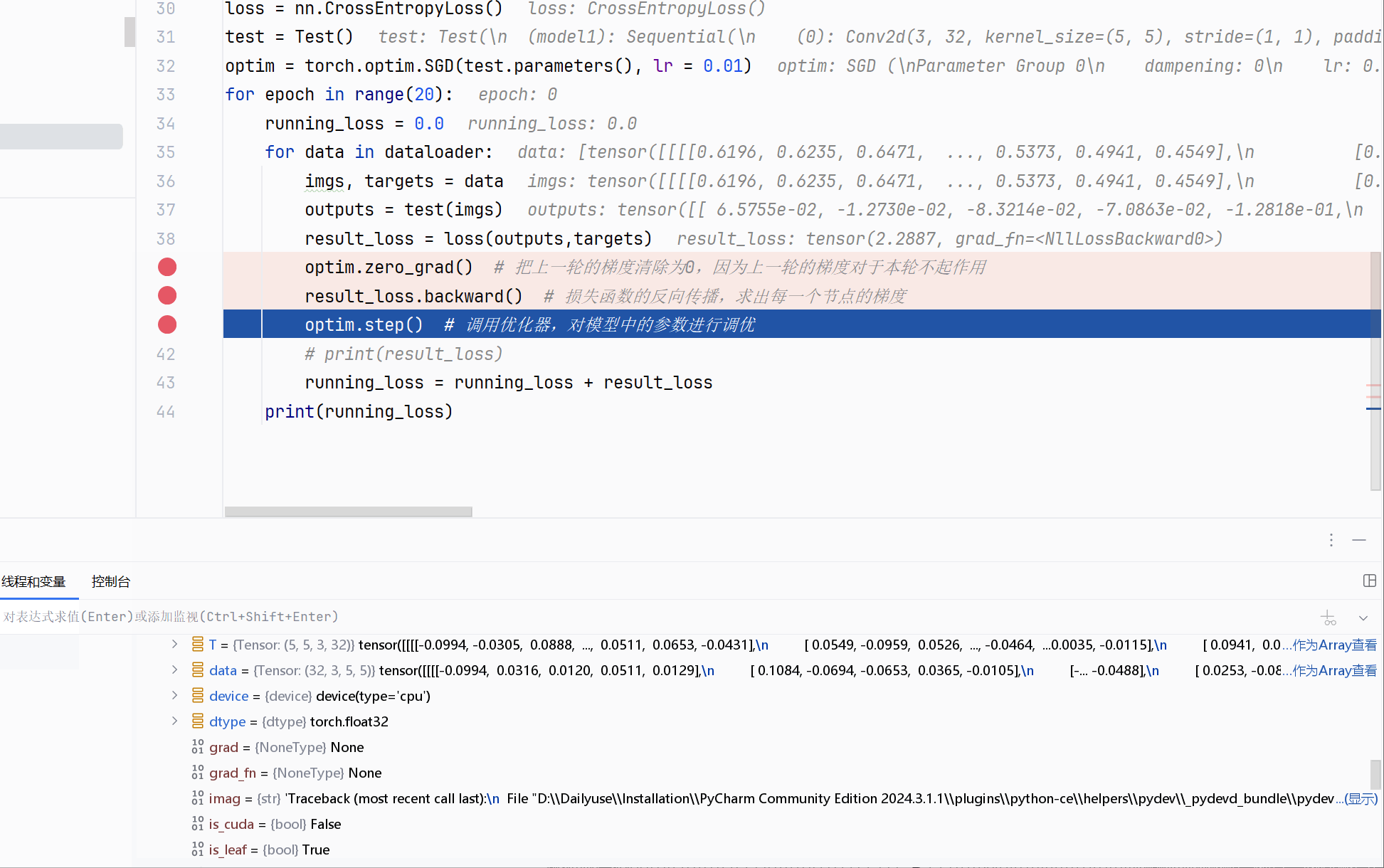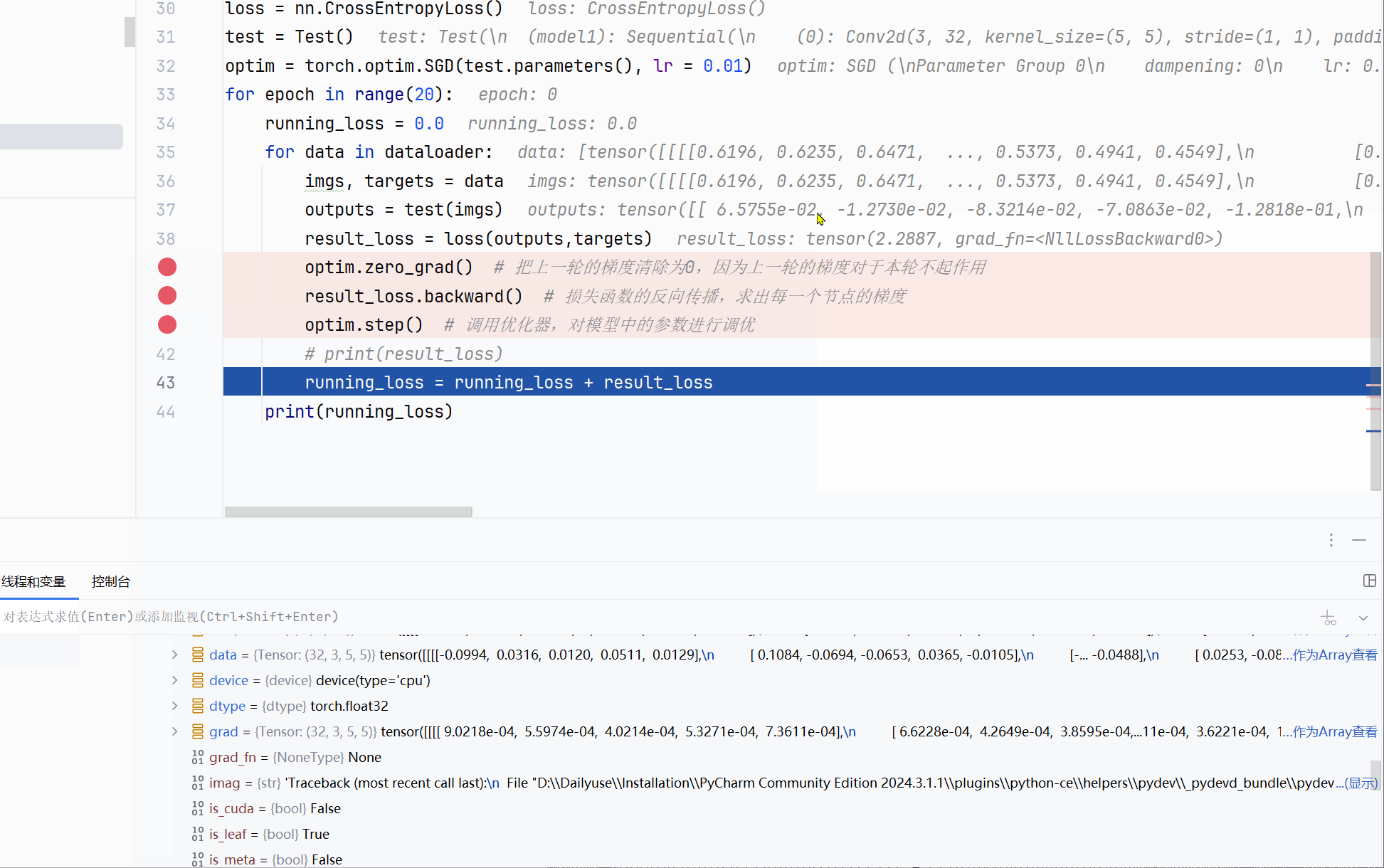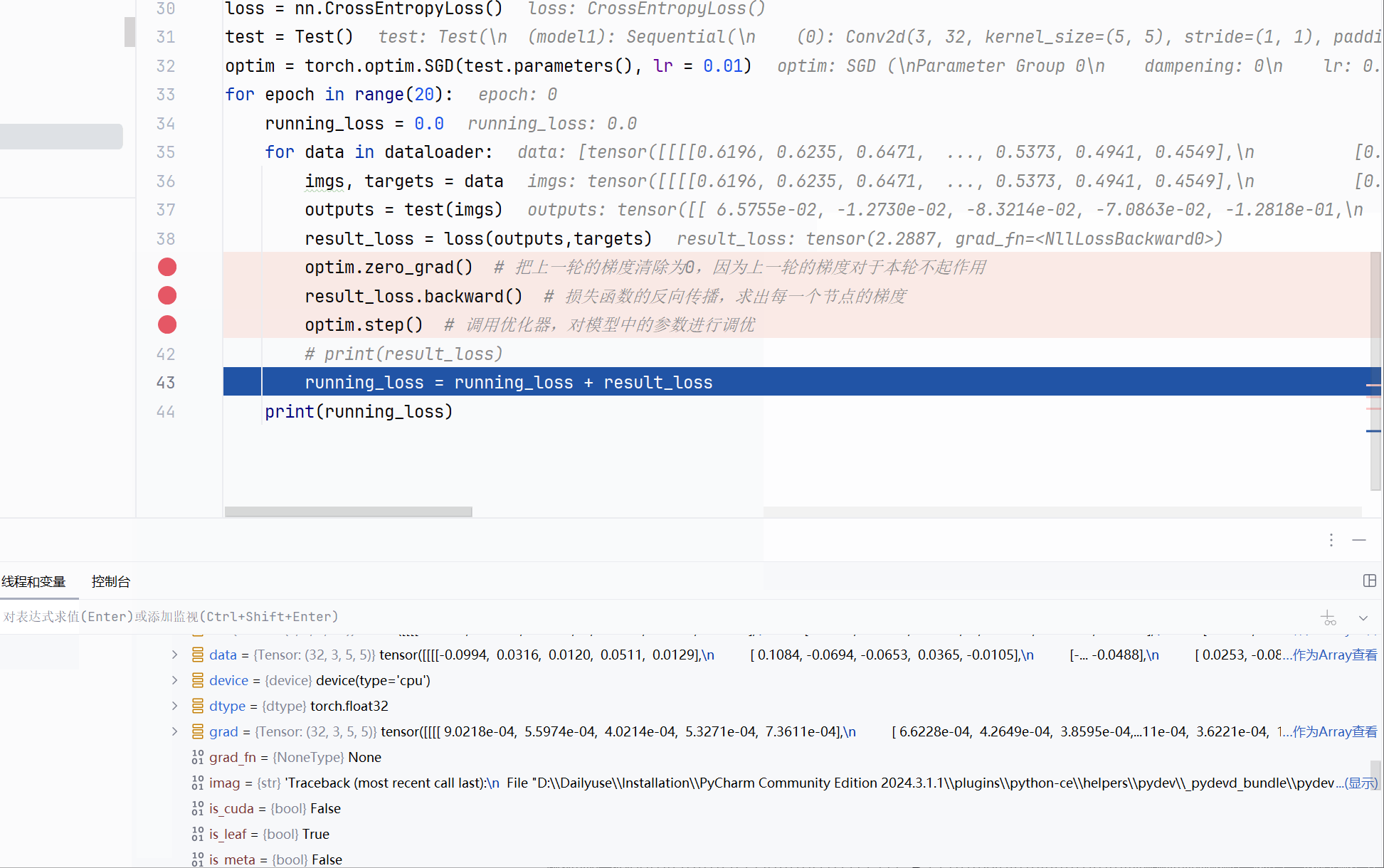
可以看到grad的改变