
目录
Finding Rows in a Heap with a Nonclustered Index
Finding Rows in a Clustered Index
Finding Rows in a Clustered Index with a Nonclustered Index
Indexes
- Index = data structure used to speed access to tuples of a relation, given values of one or more attributes.(用于给定一个或者多个属性后加速对于关系的访问)
- Could be a hash table, but in a DBMS it is always a balanced search tree with giant nodes (a full disk page) called a B+ tree.
Using Clustered Indexes
- Each Table Can Have Only One Clustered Index(每张表只能有一个聚焦索引)
- The Physical Row Order of the Table and the Order of Rows in the Index Are the Same(物理储存顺序与聚焦索引的顺序一样)
- Key Value Uniqueness Is Maintained Explicitly or Implicitly(键值的维护是显式或者隐式的)
Using Nonclustered Indexes
- Nonclustered Indexes Are the SQL Server Default(非聚焦索引是SQL_Server的默认索引类型)
- Existing Nonclustered Indexes Are Automatically Rebuilt When:
- An existing clustered index is dropped
- A clustered index is created
- The DROP_EXISTING option is used to change which columns define the clustered index
以上情况会导致非聚焦索引会重建:
- 已存在的聚焦索引被删除(会导致非聚焦索引储存的数据指针失效,所以需要重建)
- 新的聚焦索引被创建
- 修改了聚焦索引的列(可能会导致物理储存顺序重新排列)
总结来说的话就是,影响了物理储存顺序就可能会导致非聚焦索引的顺序失效
Declaring Indexes
No standard!
Typical syntax:
CREATE INDEX BeerInd ON
Beers(manf);
CREATE INDEX SellInd ON
Sells(bar, beer);Using Indexes
Given a value v, the index takes us to only those tuples that have v in the attribute(s) of the index.(通过给定的值v,能够快速找到包含v属性的元组)
Example: use BeerInd and SellInd to find the prices of beers manufactured by Pete’s and sold by Joe.
SELECT price FROM Beers, Sells
WHERE manf = ’Pete’’s’ AND
Beers.name = Sells.beer AND
bar = ’Joe’’s Bar’;Use BeerInd to get all the beers made by Pete’s.
Then use SellInd to get prices of those beers, with bar = ’Joe’’s Bar’
Finding Rows Without Indexes
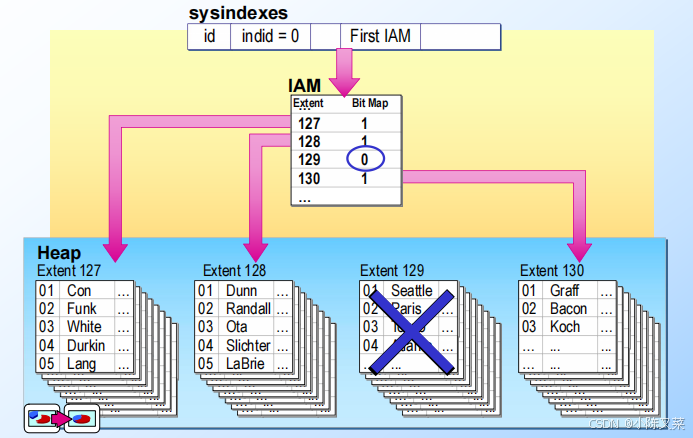
Finding Rows in a Heap with a Nonclustered Index
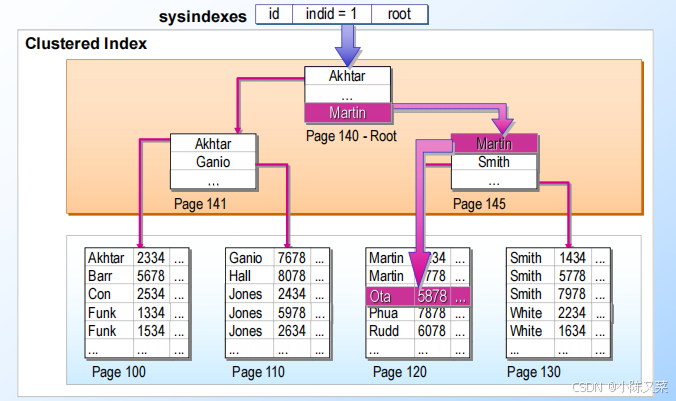
Finding Rows in a Clustered Index
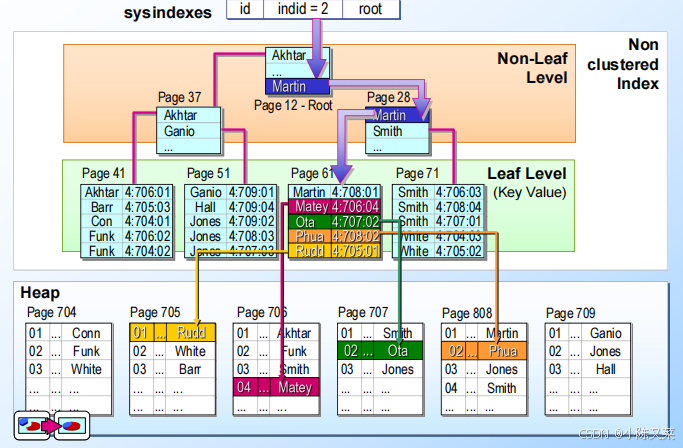
Finding Rows in a Clustered Index with a Nonclustered Index
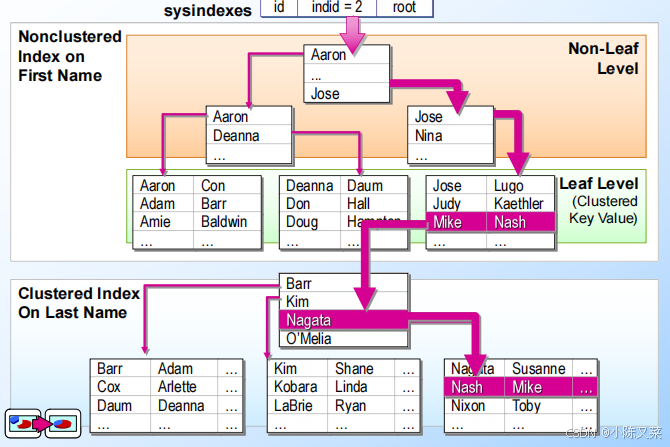
总结:
- 非聚集索引的叶子结点存放的是聚集索引的关键字,聚集索引叶子结点存放的是数据本身
- 所以使用非聚焦索引查询数据时,应该是先找到非聚焦索引的叶子结点上的聚焦索引的关键字,然后通过这个关键字,从聚焦索引找到存放了数据的叶子结点
Database Tuning
- A major problem in making a database run fast is deciding which indexes to create.(一个主要的问题就是,要决定那些索引是需要被创建的)
- Pro: An index speeds up queries that can use it.(优点:能够提升查询的速度)
- Con: An index slows down all modifications on its relation because the index must be modified too.(缺点:是的关系上的修改效率降低,因为修改的同时索引也需要修改)