1. 查询构建(包括Text2SQL)
查询构建的相关技术栈:
- Text-to-SQL
- Text-to-Cypher
- 从查询中提取元数据(Self-query Retriever)
1.1 Text-to-SQL(关系数据库)
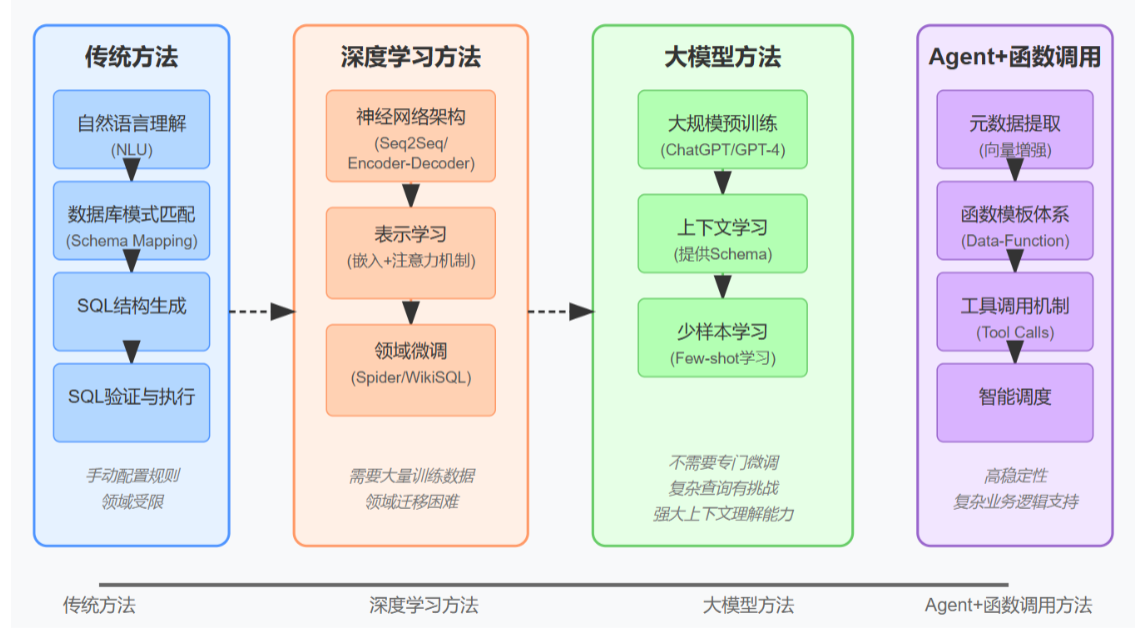
1.1.1 大语言模型方法Text-to-SQL样例实现
A.安装MySQL
# 在Ubuntu/Debian上安装 sudo apt update sudo apt install mysql-server sudo mysql_secure_installation # 启动MySQL服务 sudo systemctl start mysql sudo systemctl enable mysql
B. 安装PyMySQL
pip install pymysql
使用 apt 安装 MySQL 后,默认情况下 root 用户没有密码,但需要通过 sudo 权限访问。
如果希望设置密码(推荐)
使用 mysql_secure_installation
运行以下命令交互式设置密码:
sudo mysql_secure_installation
按照提示:
选择密码强度验证策略(通常选
0跳过)输入新密码并确认
后续选项建议全部选
Y(移除匿名用户、禁止远程 root 登录等)
C. 用 sudo 登录 MySQL
sudo mysql -u rootD. 检查 MySQL 用户认证方式
登录 MySQL 后,执行:
SELECT user, host, plugin FROM mysql.user WHERE user='root';E. 修改 root 用户认证方式为密码
假设你已经用 sudo mysql 进入了 MySQL,执行:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '12345678';
FLUSH PRIVILEGES;F. 数据准备 – Sakila Database
https://dev.mysql.com/doc/sakila/en/
模拟 DVD 租赁业务,包含 16 张表(如 film、rental、payment),侧重库存与租赁流程
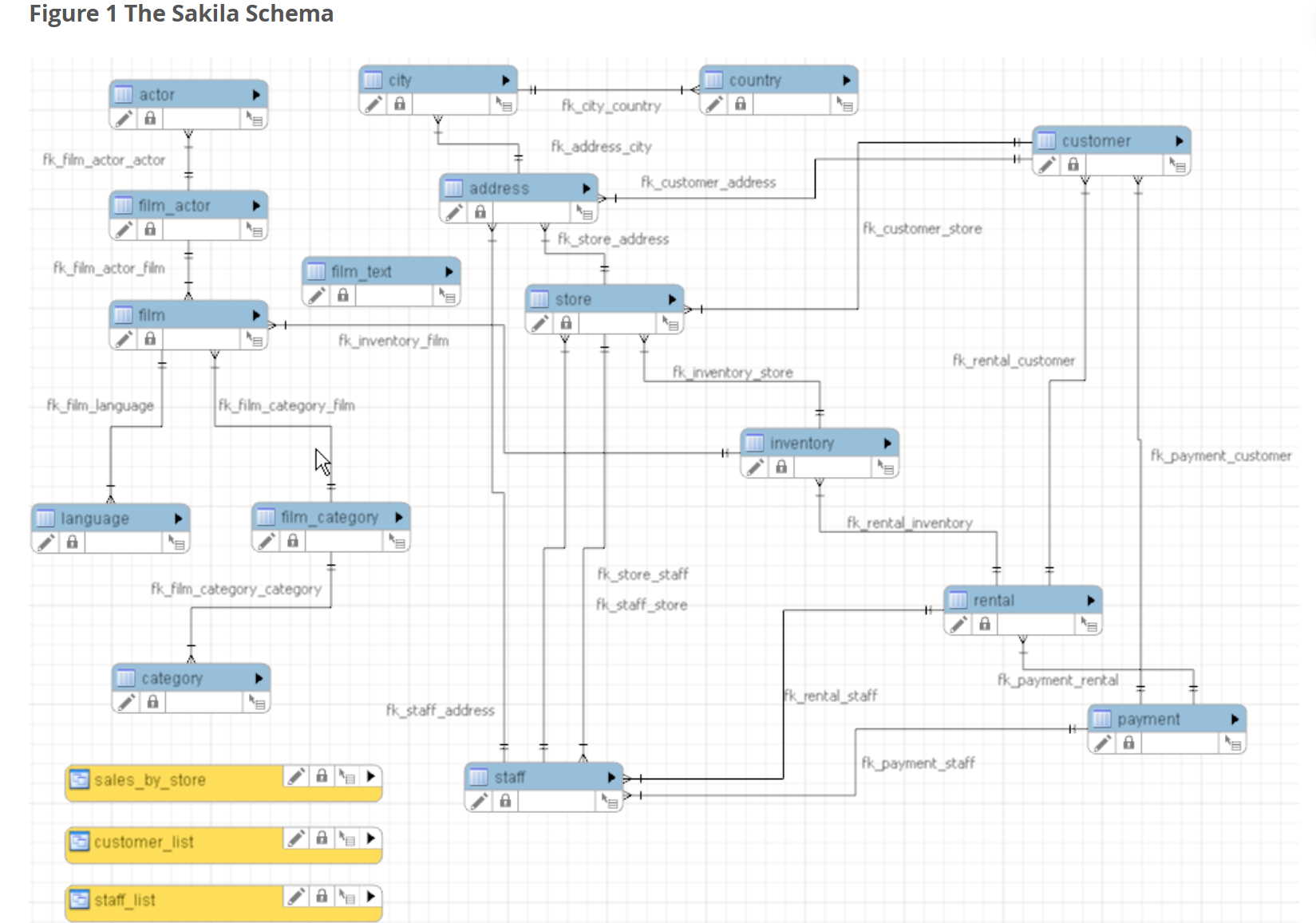
下载并安装MySQL的Sakila示例数据库
下载MySQL官方示例数据库"Sakila"的压缩包
2.wget http://downloads.mysql.com/docs/sakila-db.tar.gz
解压下载的压缩包
3.tar -xvzf sakila-db.tar.gz
4.cd sakila-db
5.mysql -u root -p < sakila-schema.sql
6.mysql -u root -p< sakila-data.sql
7.mysql -u root –p
8.SHOW DATABASES;
9.USE sakila;
10.SHOW TABLES;
G. 构建全链路Text2SQL系统步骤
a. Schema 提取与切片(构建 DDL 知识库)
b. 示例对注入(构建 Q→SQL 知识库)
c. 业务描述补充(构建 DB 描述知识库)可选
-----------------------------(到此构建向量数据库完成)
d. 检索增强(RAG 检索上下文,选出正确的Schema示例)
e. SQL 生成(调用 LLM)
------------------------------(到此sql生成完成)
f. 执行与反馈(执行 SQL 并返回结果)
g. 把结果传给生成模型做生成,将生成内容返回给用户
代码示例:
a.Schema 提取与切片
# generate_ddl_yaml.py
import os
import yaml
import pymysql
from dotenv import load_dotenv
# 1. 加载 .env 中的数据库配置
load_dotenv()
host = os.getenv("MYSQL_HOST")
port = int(os.getenv("MYSQL_PORT", "3306"))
user = "root"
password = "password"
db_name = "sakila"
# 2. 连接 MySQL``
conn = pymysql.connect(
host=host, port=port, user=user, password=password,
database=db_name, cursorclass=pymysql.cursors.Cursor
)
ddl_map = {}
try:
with conn.cursor() as cursor:
# 3. 获取所有表名
cursor.execute(
"SELECT table_name FROM information_schema.tables "
"WHERE table_schema = %s;", (db_name,)
)
tables = [row[0] for row in cursor.fetchall()]
# 4. 遍历表列表,执行 SHOW CREATE TABLE
for tbl in tables:
cursor.execute(f"SHOW CREATE TABLE `{db_name}`.`{tbl}`;")
result = cursor.fetchone()
# result[0]=表名, result[1]=完整 DDL
ddl_map[tbl] = result[1]
finally:
conn.close()
# 5. 写入 YAML 文件
with open("90-文档-Data/sakila/ddl_statements.yaml", "w") as f:
yaml.safe_dump(ddl_map, f, sort_keys=True, allow_unicode=True)
print("✅ ddl_statements.yaml 已生成,共包含表:", list(ddl_map.keys()))a. 构建 DDL 知识库
# ingest_ddl.py
import logging
from pymilvus import MilvusClient, DataType, FieldSchema, CollectionSchema
from pymilvus import model
import torch
import yaml
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 1. 初始化嵌入函数
embedding_function = model.dense.OpenAIEmbeddingFunction(model_name='text-embedding-3-large')
# 2. 读取 DDL 列表(假设 ddl_statements.yaml 中存放 {table_name: "CREATE TABLE ..."})
with open("90-文档-Data/sakila/ddl_statements.yaml","r") as f:
ddl_map = yaml.safe_load(f)
logging.info(f"[DDL] 从YAML文件加载了 {len(ddl_map)} 个表/视图定义")
# 3. 连接 Milvus
client = MilvusClient("text2sql_milvus_sakila.db")
# 4. 定义 Collection Schema
# 字段:id, vector, table_name, ddl_text
vector_dim = len(embedding_function(["dummy"])[0])
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=vector_dim),
FieldSchema(name="table_name", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="ddl_text", dtype=DataType.VARCHAR, max_length=2000),
]
schema = CollectionSchema(fields, description="DDL Knowledge Base", enable_dynamic_field=False)
# 5. 创建 Collection(如不存在)
collection_name = "ddl_knowledge"
if not client.has_collection(collection_name):
client.create_collection(collection_name=collection_name, schema=schema)
logging.info(f"[DDL] 创建了新的集合 {collection_name}")
else:
logging.info(f"[DDL] 集合 {collection_name} 已存在")
# 6. 为向量字段添加索引
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="AUTOINDEX", metric_type="COSINE", params={"nlist": 1024})
client.create_index(collection_name=collection_name, index_params=index_params)
# 7. 批量插入 DDL
data = []
texts = []
for tbl, ddl in ddl_map.items():
texts.append(ddl)
data.append({"table_name": tbl, "ddl_text": ddl})
logging.info(f"[DDL] 准备处理 {len(data)} 个表/视图的DDL语句")
# 生成全部嵌入
embeddings = embedding_function(texts)
logging.info(f"[DDL] 成功生成了 {len(embeddings)} 个向量嵌入")
# 组织为 Milvus insert 格式
records = []
for emb, rec in zip(embeddings, data):
rec["vector"] = emb
records.append(rec)
res = client.insert(collection_name=collection_name, data=records)
logging.info(f"[DDL] 成功插入了 {len(records)} 条记录到Milvus")
logging.info(f"[DDL] 插入结果: {res}")
logging.info("[DDL] 知识库构建完成")b. 示例对注入(构建 Q→SQL 知识库)运行代码前需准备预备资料:使用大模型结合DDL生成问答对
# ingest_q2sql.py
import logging
from pymilvus import MilvusClient, DataType, FieldSchema, CollectionSchema
from pymilvus import model
import torch
import json
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 1. 初始化嵌入函数
embedding_function = model.dense.OpenAIEmbeddingFunction(model_name='text-embedding-3-large')
# 2. 加载 Q->SQL 对(假设 q2sql_pairs.json 数组,每项 { "question": ..., "sql": ... })
with open("90-文档-Data/sakila/q2sql_pairs.json", "r") as f:
pairs = json.load(f)
logging.info(f"[Q2SQL] 从JSON文件加载了 {len(pairs)} 个问答对")
# 3. 连接 Milvus
client = MilvusClient("text2sql_milvus_sakila.db")
# 4. 定义 Collection Schema
vector_dim = len(embedding_function(["dummy"])[0])
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=vector_dim),
FieldSchema(name="question", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="sql_text", dtype=DataType.VARCHAR, max_length=2000),
]
schema = CollectionSchema(fields, description="Q2SQL Knowledge Base", enable_dynamic_field=False)
# 5. 创建 Collection(如不存在)
collection_name = "q2sql_knowledge"
if not client.has_collection(collection_name):
client.create_collection(collection_name=collection_name, schema=schema)
logging.info(f"[Q2SQL] 创建了新的集合 {collection_name}")
else:
logging.info(f"[Q2SQL] 集合 {collection_name} 已存在")
# 6. 为向量字段添加索引
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="AUTOINDEX", metric_type="COSINE", params={"nlist": 1024})
client.create_index(collection_name=collection_name, index_params=index_params)
# 7. 批量插入 Q2SQL 对
data = []
texts = []
for pair in pairs:
texts.append(pair["question"])
data.append({"question": pair["question"], "sql_text": pair["sql"]})
logging.info(f"[Q2SQL] 准备处理 {len(data)} 个问答对")
# 生成全部嵌入
embeddings = embedding_function(texts)
logging.info(f"[Q2SQL] 成功生成了 {len(embeddings)} 个向量嵌入")
# 组织为 Milvus insert 格式
records = []
for emb, rec in zip(embeddings, data):
rec["vector"] = emb
records.append(rec)
res = client.insert(collection_name=collection_name, data=records)
logging.info(f"[Q2SQL] 成功插入了 {len(records)} 条记录到Milvus")
logging.info(f"[Q2SQL] 插入结果: {res}")
logging.info("[Q2SQL] 知识库构建完成")问答对文件q2sql_pairs.json如下:
[
{
"question": "List all actors with their IDs and names.",
"sql": "SELECT actor_id, first_name, last_name FROM actor;"
},
{
"question": "Add a new actor named 'John Doe'.",
"sql": "INSERT INTO actor (first_name, last_name) VALUES ('John', 'Doe');"
},
{
"question": "Update the last name of actor with ID 1 to 'Smith'.",
"sql": "UPDATE actor SET last_name = 'Smith' WHERE actor_id = 1;"
},
{
"question": "Delete the actor with ID 2.",
"sql": "DELETE FROM actor WHERE actor_id = 2;"
},
{
"question": "Show all films and their descriptions.",
"sql": "SELECT film_id, title, description FROM film;"
},
{
"question": "Insert a new film titled 'New Movie' in language 1.",
"sql": "INSERT INTO film (title, language_id) VALUES ('New Movie', 1);"
},
{
"question": "Change the rating of film ID 3 to 'PG-13'.",
"sql": "UPDATE film SET rating = 'PG-13' WHERE film_id = 3;"
},
{
"question": "Remove the film with ID 4.",
"sql": "DELETE FROM film WHERE film_id = 4;"
},
{
"question": "Retrieve all categories.",
"sql": "SELECT category_id, name FROM category;"
},
{
"question": "Add a new category 'Horror'.",
"sql": "INSERT INTO category (name) VALUES ('Horror');"
},
{
"question": "Rename category ID 5 to 'Thriller'.",
"sql": "UPDATE category SET name = 'Thriller' WHERE category_id = 5;"
},
{
"question": "Delete category with ID 6.",
"sql": "DELETE FROM category WHERE category_id = 6;"
},
{
"question": "List all customers with their store and email.",
"sql": "SELECT customer_id, store_id, email FROM customer;"
},
{
"question": "Create a new customer for store 1 named 'Alice Brown'.",
"sql": "INSERT INTO customer (store_id, first_name, last_name, create_date, address_id, active) VALUES (1, 'Alice', 'Brown', NOW(), 1, 1);"
},
{
"question": "Update email of customer ID 10 to 'newemail@example.com'.",
"sql": "UPDATE customer SET email = 'newemail@example.com' WHERE customer_id = 10;"
},
{
"question": "Remove customer with ID 11.",
"sql": "DELETE FROM customer WHERE customer_id = 11;"
},
{
"question": "Show inventory items for film ID 5.",
"sql": "SELECT inventory_id, film_id, store_id FROM inventory WHERE film_id = 5;"
},
{
"question": "Add a new inventory item for film 5 in store 2.",
"sql": "INSERT INTO inventory (film_id, store_id) VALUES (5, 2);"
},
{
"question": "Update the store of inventory ID 20 to store 3.",
"sql": "UPDATE inventory SET store_id = 3 WHERE inventory_id = 20;"
},
{
"question": "Delete inventory record with ID 21.",
"sql": "DELETE FROM inventory WHERE inventory_id = 21;"
},
{
"question": "List recent rentals with rental date and customer.",
"sql": "SELECT rental_id, rental_date, customer_id FROM rental ORDER BY rental_date DESC LIMIT 10;"
},
{
"question": "Record a new rental for inventory 15 by customer 5.",
"sql": "INSERT INTO rental (rental_date, inventory_id, customer_id, staff_id) VALUES (NOW(), 15, 5, 1);"
},
{
"question": "Update return date for rental ID 3 to current time.",
"sql": "UPDATE rental SET return_date = NOW() WHERE rental_id = 3;"
},
{
"question": "Remove the rental record with ID 4.",
"sql": "DELETE FROM rental WHERE rental_id = 4;"
},
{
"question": "Show all payments with amount and date.",
"sql": "SELECT payment_id, customer_id, amount, payment_date FROM payment;"
},
{
"question": "Add a payment of 9.99 for rental 3 by customer 5.",
"sql": "INSERT INTO payment (customer_id, staff_id, rental_id, amount, payment_date) VALUES (5, 1, 3, 9.99, NOW());"
},
{
"question": "Change payment amount of payment ID 6 to 12.50.",
"sql": "UPDATE payment SET amount = 12.50 WHERE payment_id = 6;"
},
{
"question": "Delete payment record with ID 7.",
"sql": "DELETE FROM payment WHERE payment_id = 7;"
},
{
"question": "List all staff with names and email.",
"sql": "SELECT staff_id, first_name, last_name, email FROM staff;"
},
{
"question": "Hire a new staff member 'Bob Lee' at store 1.",
"sql": "INSERT INTO staff (first_name, last_name, address_id, store_id, active, username) VALUES ('Bob', 'Lee', 1, 1, 1, 'boblee');"
},
{
"question": "Deactivate staff with ID 2.",
"sql": "UPDATE staff SET active = 0 WHERE staff_id = 2;"
},
{
"question": "Remove staff member with ID 3.",
"sql": "DELETE FROM staff WHERE staff_id = 3;"
},
{
"question": "Show all stores with manager and address.",
"sql": "SELECT store_id, manager_staff_id, address_id FROM store;"
},
{
"question": "Open a new store with manager 2 at address 3.",
"sql": "INSERT INTO store (manager_staff_id, address_id) VALUES (2, 3);"
},
{
"question": "Change manager of store ID 2 to staff ID 4.",
"sql": "UPDATE store SET manager_staff_id = 4 WHERE store_id = 2;"
},
{
"question": "Close (delete) store with ID 3.",
"sql": "DELETE FROM store WHERE store_id = 3;"
}
] d. 检索增强(RAG 检索上下文,选出正确的Schema示例)
e. SQL 生成(调用 LLM)
# text2sql_query.py
import os
import logging
import yaml
import openai
import re
from dotenv import load_dotenv
from pymilvus import MilvusClient
from pymilvus import model
from sqlalchemy import create_engine, text
# 1. 环境与日志配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
load_dotenv() # 加载 .env 环境变量
# 2. 初始化 OpenAI API(使用最新 Response API)
openai.api_key = os.getenv("OPENAI_API_KEY")
# 建议使用新 Response API 风格
# 例如: openai.chat.completions.create(...) 而非旧的 ChatCompletion.create
MODEL_NAME = os.getenv("OPENAI_MODEL", "o4-mini")
# 3. 嵌入函数初始化
def init_embedding():
return model.dense.OpenAIEmbeddingFunction(
model_name='text-embedding-3-large',
)
# 4. Milvus 客户端连接
MILVUS_DB = os.getenv("MILVUS_DB_PATH", "text2sql_milvus_sakila.db")
client = MilvusClient(MILVUS_DB)
# 5. 嵌入函数实例化
embedding_fn = init_embedding()
# 6. 数据库连接(SAKILA)
DB_URL = os.getenv(
"SAKILA_DB_URL",
"mysql+pymysql://root:password@localhost:3306/sakila"
)
engine = create_engine(DB_URL)
# 7. 检索函数
def retrieve(collection: str, query_emb: list, top_k: int = 3, fields: list = None):
results = client.search(
collection_name=collection,
data=[query_emb],
limit=top_k,
output_fields=fields
)
logging.info(f"[检索] {collection} 检索结果: {results}")
return results[0] # 返回第一个查询的结果列表
# 8. SQL 提取函数
def extract_sql(text: str) -> str:
# 尝试匹配 SQL 代码块
sql_blocks = re.findall(r'```sql\n(.*?)\n```', text, re.DOTALL)
if sql_blocks:
return sql_blocks[0].strip()
# 如果没有找到代码块,尝试匹配 SELECT 语句
select_match = re.search(r'SELECT.*?;', text, re.DOTALL)
if select_match:
return select_match.group(0).strip()
# 如果都没有找到,返回原始文本
return text.strip()
# 9. 执行 SQL 并返回结果
def execute_sql(sql: str):
try:
with engine.connect() as conn:
result = conn.execute(text(sql))
cols = result.keys()
rows = result.fetchall()
return True, cols, rows
except Exception as e:
return False, None, str(e)
# 10. 生成 SQL 函数
def generate_sql(prompt: str, error_msg: str = None) -> str:
if error_msg:
prompt += f"\n之前的SQL执行失败,错误信息:{error_msg}\n请修正SQL语句:"
response = openai.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
)
raw_sql = response.choices[0].message.content.strip()
sql = extract_sql(raw_sql)
logging.info(f"[生成] 原始输出: {raw_sql}")
logging.info(f"[生成] 提取的SQL: {sql}")
return sql
# 11. 核心流程:自然语言 -> SQL -> 执行 -> 返回
def text2sql(question: str, max_retries: int = 3):
# 11.1 用户提问嵌入
q_emb = embedding_fn([question])[0]
logging.info(f"[检索] 问题嵌入完成")
# 11.2 RAG 检索:DDL
ddl_hits = retrieve("ddl_knowledge", q_emb.tolist(), top_k=3, fields=["ddl_text"])
logging.info(f"[检索] DDL检索结果: {ddl_hits}")
try:
ddl_context = "\n".join(hit.get("ddl_text", "") for hit in ddl_hits)
except Exception as e:
logging.error(f"[检索] DDL处理错误: {e}")
ddl_context = ""
# 11.3 RAG 检索:示例对
q2sql_hits = retrieve("q2sql_knowledge", q_emb.tolist(), top_k=3, fields=["question", "sql_text"])
logging.info(f"[检索] Q2SQL检索结果: {q2sql_hits}")
try:
example_context = "\n".join(
f"NL: \"{hit.get('question', '')}\"\nSQL: \"{hit.get('sql_text', '')}\""
for hit in q2sql_hits
)
except Exception as e:
logging.error(f"[检索] Q2SQL处理错误: {e}")
example_context = ""
# 11.4 RAG 检索:字段描述
desc_hits = retrieve("dbdesc_knowledge", q_emb.tolist(), top_k=5, fields=["table_name", "column_name", "description"])
logging.info(f"[检索] 字段描述检索结果: {desc_hits}")
try:
desc_context = "\n".join(
f"{hit.get('table_name', '')}.{hit.get('column_name', '')}: {hit.get('description', '')}"
for hit in desc_hits
)
except Exception as e:
logging.error(f"[检索] 字段描述处理错误: {e}")
desc_context = ""
# 11.5 组装基础 Prompt
base_prompt = (
f"### Schema Definitions:\n{ddl_context}\n"
f"### Field Descriptions:\n{desc_context}\n"
f"### Examples:\n{example_context}\n"
f"### Query:\n\"{question}\"\n"
"请只返回SQL语句,不要包含任何解释或说明。"
)
# 11.6 生成并执行 SQL,最多重试 max_retries 次
error_msg = None
for attempt in range(max_retries):
logging.info(f"[执行] 第 {attempt + 1} 次尝试")
# 生成 SQL
sql = generate_sql(base_prompt, error_msg)
# 执行 SQL
success, cols, result = execute_sql(sql)
if success:
print("\n查询结果:")
print("列名:", cols)
for r in result:
print(r)
return
error_msg = result
logging.error(f"[执行] 第 {attempt + 1} 次执行失败: {error_msg}")
print(f"执行失败,已达到最大重试次数 {max_retries}。")
print("最后错误信息:", error_msg)
# 12. 程序入口
if __name__ == "__main__":
user_q = input("请输入您的自然语言查询: ")
text2sql(user_q)1.2 其他Text2SQL框架
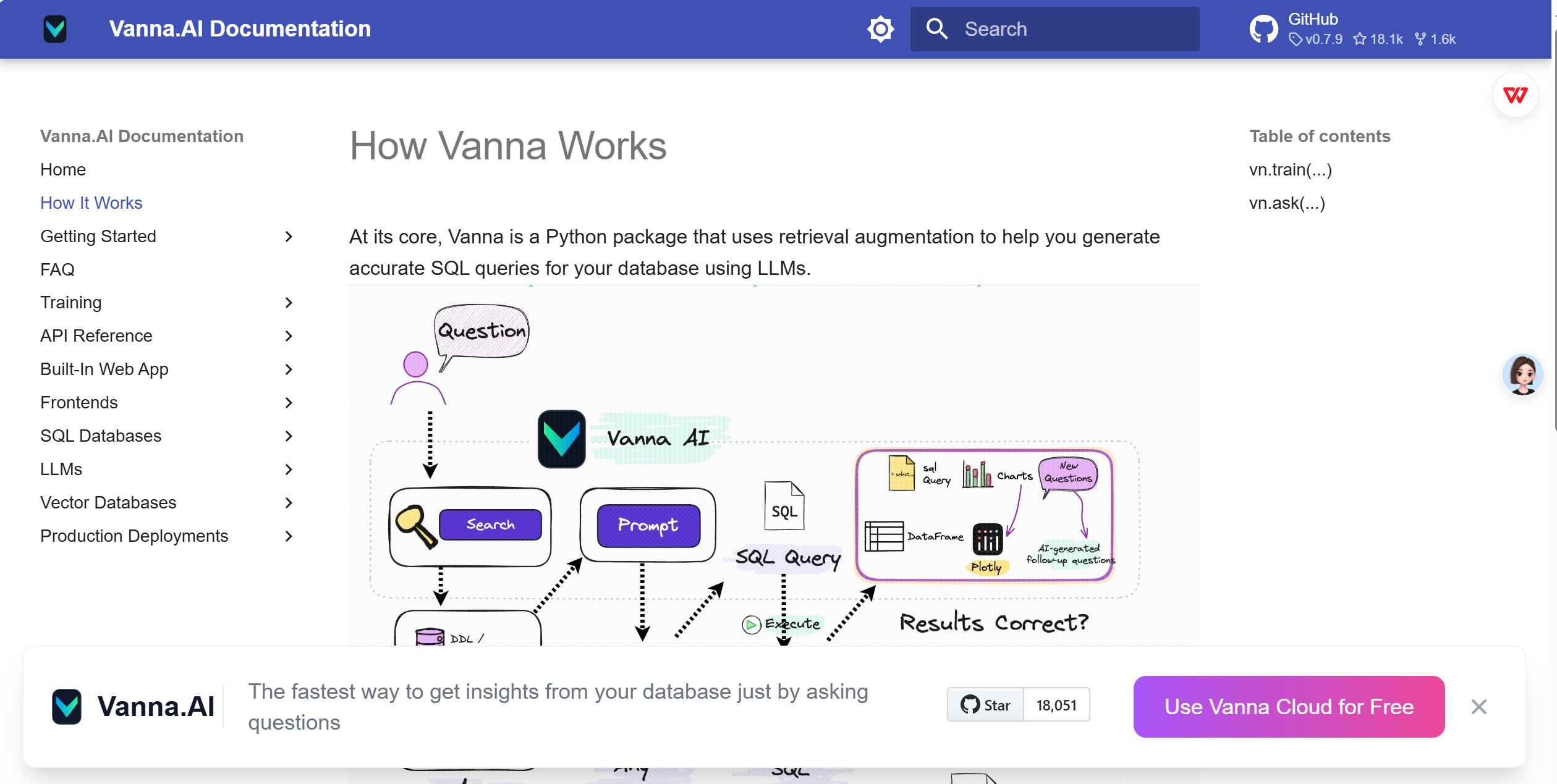
1.2.1 Text2SQL框架:Vanna
1.2.2 Text2SQL框架: Chat2DB
https://github.com/CodePhiliaX/Chat2DB/blob/main/README_CN.md
1.3 用RAGFlow实现Text2SQL
基于RAGFlow模板创建 Text2SQL Agent

1.4 Text-to-Cypher(图数据库)
| 对比维度 | SQL 查询 | Cypher 查询 |
|---|---|---|
| 数据模型 | 表格(如表、行、列) | 图结构(如节点、关系、属性) |
| 查询目标 | 行和列 | 节点和关系 |
| 语法风格 | 类似自然语言的声明式 | 声明式 + 图模式匹配 |
| 复杂关系建模能力 | 依赖多表 JOIN | 原生支持节点和关系,复杂查询更高效 |
| 学习门槛 | 使用广泛,易于上手 | 专门化,使用人群相对少 |
代码示例:
# 准备Neo4j数据库连接
from neo4j import GraphDatabase
import os
from dotenv import load_dotenv
load_dotenv()
# Neo4j连接配置
uri = "bolt://localhost:7687" # 默认Neo4j Bolt端口
username = "neo4j"
password = os.getenv("NEO4J_PASSWORD") # 从环境变量获取密码
# 初始化Neo4j驱动
driver = GraphDatabase.driver(uri, auth=(username, password))
def get_database_schema():
"""查询数据库的元数据信息"""
with driver.session() as session:
# 查询节点标签
node_labels_query = """
CALL db.labels() YIELD label
RETURN label
"""
node_labels = session.run(node_labels_query).data()
# 查询关系类型
relationship_types_query = """
CALL db.relationshipTypes() YIELD relationshipType
RETURN relationshipType
"""
relationship_types = session.run(relationship_types_query).data()
# 查询每个标签的属性
properties_by_label = {}
for label in node_labels:
properties_query = f"""
MATCH (n:{label['label']})
WITH n LIMIT 1
RETURN keys(n) as properties
"""
properties = session.run(properties_query).data()
if properties:
properties_by_label[label['label']] = properties[0]['properties']
return {
"node_labels": [label['label'] for label in node_labels],
"relationship_types": [rel['relationshipType'] for rel in relationship_types],
"properties_by_label": properties_by_label
}
# 获取数据库结构
schema_info = get_database_schema()
print("\n数据库结构信息:")
print("节点类型:", schema_info["node_labels"])
print("关系类型:", schema_info["relationship_types"])
print("\n节点属性:")
for label, properties in schema_info["properties_by_label"].items():
print(f"{label}: {properties}")
# 准备SNOMED CT Schema描述
schema_description = f"""
你正在访问一个SNOMED CT图数据库,主要包含以下节点和关系:
节点类型:
{', '.join(schema_info["node_labels"])}
关系类型:
{', '.join(schema_info["relationship_types"])}
节点属性:
"""
for label, properties in schema_info["properties_by_label"].items():
schema_description += f"\n{label}节点属性:{', '.join(properties)}"
# 初始化DeepSeek客户端
from openai import OpenAI
client = OpenAI(
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY")
)
# 设置查询
user_query = "查找与'Diabetes'相关的所有概念及其描述"
# 准备生成Cypher的提示词
prompt = f"""
以下是SNOMED CT图数据库的结构描述:
{schema_description}
用户的自然语言问题如下:
"{user_query}"
请生成Cypher查询语句,注意以下几点:
1. 关系方向要正确,例如:
- ObjectConcept 拥有 Description,所以应该是 (oc:ObjectConcept)-[:HAS_DESCRIPTION]->(d:Description)
- 不要写成 (d:Description)-[:HAS_DESCRIPTION]->(oc:ObjectConcept)
2. 使用MATCH子句来匹配节点和关系
3. 使用WHERE子句来过滤条件,建议使用toLower()函数进行不区分大小写的匹配
4. 使用RETURN子句来指定返回结果
5. 请只返回Cypher查询语句,不要包含任何其他解释、注释或格式标记(如```cypher)
"""
# 调用LLM生成Cypher语句
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个Cypher查询专家。请只返回Cypher查询语句,不要包含任何Markdown格式或其他说明。"},
{"role": "user", "content": prompt}
],
temperature=0
)
# 清理Cypher语句,移除可能的Markdown标记
cypher = response.choices[0].message.content.strip()
cypher = cypher.replace('```cypher', '').replace('```', '').strip()
print(f"\n生成的Cypher查询语句:\n{cypher}")
# 执行Cypher查询并获取结果
def run_query(tx, query):
result = tx.run(query)
return [record for record in result]
with driver.session() as session:
results = session.execute_read(run_query, cypher)
print(f"\n查询结果:{results}")
# 关闭数据库连接
driver.close() 代码优势分析:

数据库 Schema 获取方式
- Schema描述是自动获取的,通过 get_database_schema() 函数,动态查询 Neo4j 数据库的节点标签、关系类型和每个标签的属性。
- 这样可以自动适配数据库结构的变化,更通用、更健壮。
Cypher 生成提示词
- 用自动获取的 schema_info 组装 schema_description,提示词内容会根据数据库实际结构动态变化。
- 提示词中还特别强调了关系方向和大小写匹配建议。
1.5 Self-query Retriever自动生成元数据过滤器(向量数据库)
Self-query Retriever 是一种将自然语言查询自动转换为 结构化过滤条件 + 向量搜索 的混合检索技术。其核心能力是通过LLM理解用户问题中的隐含过滤条件,自动生成元数据过滤器(Metadata Filters),再与向量检索结合。
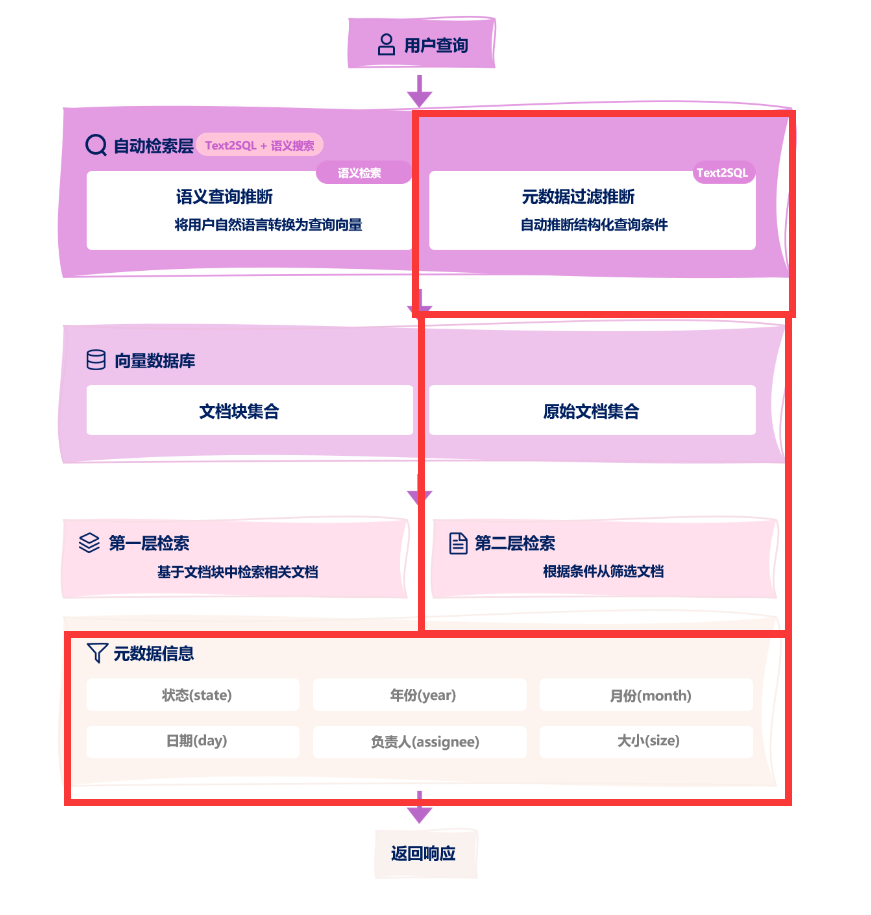
| 检索方式 | 优点 | 缺点 |
|---|---|---|
| 纯向量检索 | 语义理解能力强 | 无法精确过滤数值/分类字段 |
| 纯元数据过滤 | 精确匹配 | 无法处理语义模糊查询 |
| Self-query | 二者优势结合 | 依赖LLM的解析能力 |
# 导入所需的库
from langchain_core.prompts import ChatPromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_community.document_loaders import YoutubeLoader
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from pydantic import BaseModel, Field
# 定义视频元数据模型
class VideoMetadata(BaseModel):
"""视频元数据模型,定义了需要提取的视频属性"""
source: str = Field(description="视频ID")
title: str = Field(description="视频标题")
description: str = Field(description="视频描述")
view_count: int = Field(description="观看次数")
publish_date: str = Field(description="发布日期")
length: int = Field(description="视频长度(秒)")
author: str = Field(description="作者")
# 加载视频数据
video_urls = [
"https://www.youtube.com/watch?v=zDvnAY0zH7U", # 山西佛光寺
"https://www.youtube.com/watch?v=iAinNeOp6Hk", # 中国最大宅院
"https://www.youtube.com/watch?v=gCVy6NQtk2U", # 宋代地下宫殿
]
# 加载视频元数据
videos = []
for url in video_urls:
try:
loader = YoutubeLoader.from_youtube_url(url, add_video_info=True)
docs = loader.load()
doc = docs[0]
videos.append(doc)
print(f"已加载:{doc.metadata['title']}")
except Exception as e:
print(f"加载失败 {url}: {str(e)}")
# 创建向量存储
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(videos, embed_model)
# 配置检索器的元数据字段
metadata_field_info = [
AttributeInfo(
name="title",
description="视频标题(字符串)",
type="string",
),
AttributeInfo(
name="author",
description="视频作者(字符串)",
type="string",
),
AttributeInfo(
name="view_count",
description="视频观看次数(整数)",
type="integer",
),
AttributeInfo(
name="publish_date",
description="视频发布日期,格式为YYYY-MM-DD的字符串",
type="string",
),
AttributeInfo(
name="length",
description="视频长度,以秒为单位的整数",
type="integer"
),
]
# 创建自查询检索器SelfQueryRetriever
llm = ChatDeepSeek(model="deepseek-chat", temperature=0) # 确定性输出
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="包含视频标题、作者、观看次数、发布日期等信息的视频元数据",
metadata_field_info=metadata_field_info,
enable_limit=True,
verbose=True
)
# 执行示例查询
queries = [
"找出观看次数超过100000的视频",
"显示最新发布的视频"
]
# 执行查询并输出结果
for query in queries:
print(f"\n查询:{query}")
try:
results = retriever.invoke(query)
if not results:
print("未找到匹配的视频")
continue
for doc in results:
print(f"标题:{doc.metadata['title']}")
print(f"观看次数:{doc.metadata['view_count']}")
print(f"发布日期:{doc.metadata['publish_date']}")
except Exception as e:
print(f"查询出错:{str(e)}")
continue
。
###################
你的任务是根据用户查询,生成一个符合视频元数据过滤条件的指令。视频元数据包含以下字段:
- title:视频标题,字符串类型
- author:视频作者,字符串类型
- view_count:视频观看次数,整数类型
- publish_date:视频发布日期,格式为YYYY-MM-DD的字符串
- length:视频长度,以秒为单位的整数
用户查询:{user_query}
请根据用户查询,提取关键信息,将其转化为对上述元数据字段的过滤条件,指令要简洁明确,仅输出过滤条件,不需要多余解释2. 查询翻译(查询优化)
查询翻译,就是针对用户输入通过提示工程进行语义上的重构处理。
当遇到查询质量不高,可能包含噪声或不明确词语,或者未能覆盖所需检索信息的所有方面时,
需要采用一系列如重写、分解、澄清和扩展等优化技巧来改进查询,使其更加完善,从而达到更
好的检索效果。即以下几部分:
• 查询重写——将原始问题重构为合适的形式
• 查询分解——将查询拆分成多个子问题
• 查询澄清——逐步细化和明确用户的问题
• 查询扩展——利用HyDE生成假设文档
2.1 查询重写:
通过提示词指导大模型重写查询
# 提示词:生成基于大模型的查询重写功能
## 功能描述
我需要一个使用大语言模型(如DeepSeek)的查询重写功能,能够:
1. 接受用户的自然语言输入
2. 根据特定规则重写查询
3. 移除无关信息,保留核心意图
4. 使用更专业的术语表达
5. 返回简洁、可直接用于检索的重写结果
## 技术组件要求
- 使用OpenAI兼容API接口
- 支持DeepSeek或其他类似大模型
- 包含清晰的提示词模板
- 可配置的模型参数
## 代码生成提示词
请生成Python代码实现上述功能,包含以下部分:
1. 基础设置
```python
from openai import OpenAI
from os import getenv
```
2. 客户端初始化
```python
# 配置参数
api_base = "https://api.deepseek.com" # 可替换为其他兼容API端点
api_key = getenv("DEEPSEEK_API_KEY") # 或直接提供API密钥
model_name = "deepseek-chat" # 可替换为其他模型
# 初始化客户端
client = OpenAI(
base_url=api_base,
api_key=api_key
)
```
3. 查询重写函数
```python
def rewrite_query(question: str, domain: str = "游戏") -> str:
"""使用大模型重写查询
参数:
question: 原始查询文本
domain: 领域名称(如"游戏"、"科技"等),用于定制提示词
返回:
重写后的查询文本
"""
prompt = f"""作为一个{domain}领域的专家,你需要帮助用户重写他们的问题。
规则:
1. 移除无关信息(如个人情况、闲聊内容)
2. 使用精确的领域术语表达
3. 保持问题的核心意图
4. 将模糊的问题转换为具体的查询
5. 输出只包含重写后的查询,不要任何解释
原始问题:{question}
请直接给出重写后的查询:"""
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "user", "content": prompt}
],
temperature=0 # 可配置
)
return response.choices[0].message.content.strip()
```
4. 使用示例
```python
if __name__ == "__main__":
# 测试查询
test_queries = [
"那个,我刚开始玩这个游戏,感觉很难,在普陀山那一关,嗯,怎么也过不去。先学什么技能比较好?新手求指导!",
"电脑老是卡顿,我该升级什么硬件?预算有限",
"这个化学实验的结果不太对,pH值总是偏高,怎么回事?"
]
for query in test_queries:
print(f"\n原始查询:{query}")
print(f"重写查询:{rewrite_query(query)}")
```
## 可配置参数
请允许用户自定义以下参数:
- API端点地址
- API密钥(支持环境变量或直接输入)
- 使用的大模型名称
- 温度参数(temperature)
- 领域名称(用于提示词定制)
## 预期输出
生成的代码应能:
1. 正确初始化API客户端
2. 接受原始查询输入
3. 根据领域特定的提示词模板重写查询
4. 返回简洁、专业化的重写结果
5. 提供清晰的测试示例
## 高级扩展建议
1. 添加重写规则的自定义功能
2. 支持批量查询处理
3. 添加缓存机制减少API调用
4. 支持多语言查询重写
5. 添加错误处理和重试机制
请根据上述提示生成完整可运行的Python代码实现。from openai import OpenAI
from os import getenv
# 初始化OpenAI客户端,指定DeepSeek URL
client = OpenAI(
base_url="https://api.deepseek.com",
api_key=getenv("DEEPSEEK_API_KEY")
)
def rewrite_query(question: str) -> str:
"""使用大模型重写查询"""
prompt = """作为一个游戏客服人员,你需要帮助用户重写他们的问题。
规则:
1. 移除无关信息(如个人情况、闲聊内容)
2. 使用精确的游戏术语表达
3. 保持问题的核心意图
4. 将模糊的问题转换为具体的查询
原始问题:{question}
请直接给出重写后的查询(不要加任何前缀或说明)。"""
# 使用DeepSeek模型重写查询
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": prompt.format(question=question)}
],
temperature=0
)
return response.choices[0].message.content.strip()
# 开始测试
query = "那个,我刚开始玩这个游戏,感觉很难,在普陀山那一关,嗯,怎么也过不去。先学什么技能比较好?新手求指导!"
print(f"\n原始查询:{query}")
print(f"重写查询:{rewrite_query(query)}")LangChain的查询重写类RePhraseQueryRetriever
# 提示词:生成基于LangChain的查询重写检索系统
## 功能描述
我需要一个基于LangChain框架的文档检索系统,该系统能够:
1. 加载本地文本文件作为知识库
2. 对文本进行分块处理
3. 使用嵌入模型创建向量存储
4. 实现查询重写功能,将用户自然语言查询优化为更适合检索的形式
5. 从向量库中检索相关文档片段
## 技术组件要求
- 使用LangChain框架构建
- 包含以下核心模块:
* 文档加载器(TextLoader)
* 文本分块器(RecursiveCharacterTextSplitter)
* 嵌入模型(HuggingFaceEmbeddings)
* 向量存储(Chroma)
* LLM查询重写器(RePhraseQueryRetriever)
* 大语言模型接口(ChatDeepSeek或其他)
## 代码生成提示词
请生成Python代码实现上述功能,包含以下部分:
1. 基础设置
```python
import logging
from langchain.retrievers import RePhraseQueryRetriever
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
```
2. 配置日志
```python
logging.basicConfig()
logging.getLogger("langchain.retrievers.re_phraser").setLevel(logging.INFO)
```
3. 文档加载与处理
```python
# 配置参数
file_path = "【用户指定路径】" # 文档路径
chunk_size = 500 # 分块大小
chunk_overlap = 0 # 分块重叠
# 加载文档
loader = TextLoader(file_path, encoding='utf-8')
data = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
all_splits = text_splitter.split_documents(data)
```
4. 向量存储设置
```python
# 配置嵌入模型
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
# 创建向量存储
vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=embed_model
)
```
5. 查询重写检索器配置
```python
# 配置LLM
from langchain_deepseek import ChatDeepSeek # 或其他LLM
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
# 创建重写检索器
retriever_from_llm = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
```
6. 使用示例
```python
# 用户查询
query = "【用户输入的自然语言查询】"
# 执行检索
docs = retriever_from_llm.invoke(query)
print(docs)
```
## 可配置参数
请允许用户自定义以下参数:
- 文档路径
- 文本分块大小和重叠
- 嵌入模型名称
- LLM类型和参数(temperature等)
- 日志级别
## 预期输出
生成的代码应能:
1. 加载指定文档并创建向量存储
2. 接受自然语言查询
3. 自动重写查询并返回相关文档片段
4. 提供适当的日志信息帮助调试
请根据上述提示生成完整可运行的Python代码实现。import logging
from langchain.retrievers import RePhraseQueryRetriever
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 设置日志记录
logging.basicConfig()
logging.getLogger("langchain.retrievers.re_phraser").setLevel(logging.INFO)
# 加载游戏文档数据
loader = TextLoader("90-文档-Data/黑悟空/黑悟空设定.txt", encoding='utf-8')
data = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
# 创建向量存储
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=all_splits, embedding= embed_model)
# 设置RePhraseQueryRetriever
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
retriever_from_llm = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm # 使用DeepSeek模型做重写器
)
# 示例输入:游戏相关查询
query = "那个,我刚开始玩这个游戏,感觉很难,在普陀山那一关,嗯,怎么也过不去。先学什么技能比较好?新手求指导!"
# 调用RePhraseQueryRetriever进行查询重写
docs = retriever_from_llm.invoke(query)
print(docs)
2.2 查询分解MultiQueryRetriever:将查询拆分成多个子问题
# 提示词:生成基于多角度查询的文档检索系统
## 功能描述
我需要一个基于LangChain框架的多角度文档检索系统,该系统能够:
1. 加载本地文本文件作为知识库
2. 对文本进行分块处理
3. 使用嵌入模型创建向量存储
4. 通过LLM生成多个相关问题角度
5. 从向量库中检索多角度相关文档片段
6. 自动合并多个查询角度的结果
## 技术组件要求
- 使用LangChain框架构建
- 包含以下核心模块:
* 文档加载器(TextLoader)
* 文本分块器(RecursiveCharacterTextSplitter)
* 嵌入模型(HuggingFaceEmbeddings)
* 向量存储(Chroma)
* 多角度检索器(MultiQueryRetriever)
* 大语言模型接口(ChatDeepSeek或其他)
## 代码生成提示词
请生成Python代码实现上述功能,包含以下部分:
1. 基础设置与日志配置
```python
import logging
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever
# 配置日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
```
2. 文档加载与处理
```python
# 配置参数
file_path = "【用户指定路径】" # 文档路径
chunk_size = 500 # 分块大小
chunk_overlap = 0 # 分块重叠(可选参数)
# 加载文档
loader = TextLoader(file_path, encoding='utf-8')
data = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(data)
```
3. 向量存储设置
```python
# 配置嵌入模型
embed_model_name = "BAAI/bge-small-zh" # 默认模型
embed_model = HuggingFaceEmbeddings(model_name=embed_model_name)
# 创建向量存储
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embed_model
)
```
4. LLM初始化与多角度检索器配置
```python
# 配置LLM(DeepSeek或其他)
from langchain_deepseek import ChatDeepSeek # 或其他LLM
llm_model = "deepseek-chat" # 模型名称
llm_temperature = 0 # 温度参数
llm = ChatDeepSeek(model=llm_model, temperature=llm_temperature)
# 创建多角度检索器
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
```
5. 查询处理
```python
# 用户查询(可改为函数参数)
query = "【用户输入的自然语言查询】"
# 执行多角度检索
docs = retriever_from_llm.invoke(query)
```
6. 结果输出与处理
```python
# 可选:打印检索到的文档内容
print("检索到的文档片段:")
for i, doc in enumerate(docs):
print(f"\n片段 {i+1}:")
print(doc.page_content)
# 或者作为函数返回结果
return docs
```
## 可配置参数
请允许用户自定义以下参数:
1. **文档处理**
- 文档路径(file_path)
- 分块大小(chunk_size, 默认500)
- 分块重叠(chunk_overlap, 默认0)
2. **嵌入模型**
- 模型名称(embed_model_name, 默认"BAAI/bge-small-zh")
3. **LLM设置**
- 模型名称(llm_model, 默认"deepseek-chat")
- 温度参数(llm_temperature, 默认0)
- 可替换为其他LLM类(如ChatOpenAI)
4. **日志级别**
- 可配置不同模块的日志级别
## 预期输出
生成的代码应能:
1. 加载指定文档并创建向量存储
2. 接受自然语言查询
3. 自动生成多个相关问题角度
4. 检索每个角度的相关文档片段
5. 合并结果并返回
6. 提供日志信息帮助调试
## 高级扩展建议
1. 添加结果去重功能
2. 支持多种输出格式(JSON/文本等)
3. 添加查询次数限制
4. 支持不同向量存储后端(FAISS/Elasticsearch等)
5. 添加错误处理机制
6. 支持批处理多个查询
7. 添加自定义提示模板控制问题生成
请根据上述提示生成完整可运行的Python代码实现。import logging
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever # 多角度查询检索器
# 设置日志记录
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 加载游戏相关文档并构建向量数据库
loader = TextLoader("90-文档-Data/黑悟空/设定.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=splits, embedding= embed_model)
# 通过MultiQueryRetriever 生成多角度查询
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
query = "那个,我刚开始玩这个游戏,感觉很难,请问这个游戏难度级别如何,有几关,在普陀山那一关,嗯,怎么也过不去。先学什么技能比较好?新手求指导!"
# 调用RePhraseQueryRetriever进行查询分解
docs = retriever_from_llm.invoke(query)
print(docs)下面这一段代码(有自定义)使用了自定义的提示模板(PromptTemplate)和输出解析器(LineListOutputParser),而第一段代码只使用了MultiQueryRetriever.from_llm的默认设置。
import logging
from typing import List
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_core.output_parsers import BaseOutputParser
from langchain.prompts import PromptTemplate
# 设置日志记录
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 加载游戏相关文档并构建向量数据库
loader = TextLoader("90-文档-Data/黑悟空/黑悟空设定.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=splits, embedding= embed_model)
# 自定义输出解析器
class LineListOutputParser(BaseOutputParser[List[str]]):
def parse(self, text: str) -> List[str]:
lines = text.strip().split("\n")
return list(filter(None, lines)) # 过滤空行
output_parser = LineListOutputParser()
# 自定义查询提示模板
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""你是一个资深的游戏客服。请从5个不同的角度重写用户的查询,以帮助玩家获得更详细的游戏指导。
请确保每个查询都关注不同的方面,如技能选择、战斗策略、装备搭配等。
用户原始问题:{question}
请给出5个不同的查询,每个占一行。""",
)
# 设定大模型处理管道
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
llm_chain = QUERY_PROMPT | llm | output_parser
# 使用自定义提示模板的MultiQueryRetriever
retriever = MultiQueryRetriever(
retriever=vectorstore.as_retriever(),
llm_chain=llm_chain,
parser_key="lines"
)
# 进行多角度查询
query = "那个,我刚开始玩这个游戏,感觉很难,请问这个游戏难度级别如何,有几关,在普陀山那一关,嗯,怎么也过不去。先学什么技能比较好?新手求指导!"
# 调用RePhraseQueryRetriever进行查询分解
docs = retriever.invoke(query)
print(docs)2.3 查询澄清:逐步细化和明确用户的问题
Kim, G., Kim, S., Jeon, B., Park, J., & Kang, J. (2023). Tree
of Clarifications: Answering Ambiguous Questions with
Retrieval-Augmented Large Language Models. In H.
Bouamor, J. Pino, & K. Bali (Eds.), Proceedings of the 2023
Conference on Empirical Methods in Natural Language
Processing (pp. 996–1009). Association for Computational
Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.63
基于论文《Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models》的递归消歧框架,我设计了以下结构化提示词模板:
```prompt
# 查询澄清系统:递归消歧框架
你是一个高级问题解析专家,请使用Tree of Clarifications(ToC)方法处理模糊查询:
## 阶段1:歧义识别
1. 分析查询中的潜在歧义维度:
- 实体歧义:{识别同名实体}
- 语义歧义:{检测多义词/模糊表述}
- 上下文歧义:{定位缺失的时间/地点等上下文}
- 意图歧义:{区分信息型/操作型/比较型意图}
## 阶段2:递归澄清树构建
2. 生成澄清树(最多3层深度):
```
根节点:[原始查询]
├─ 分支1:[解释版本A] → 需要澄清的维度X
├─ 分支2:[解释版本B] → 需要澄清的维度Y
└─ 分支3:[解释版本C] → 需要澄清的维度Z
```
3. 对每个叶节点进行知识检索增强:
- 使用检索增强模型获取相关证据
- 过滤与当前分支解释矛盾的证据
## 阶段3:交互式澄清
4. 生成用户澄清请求(遵循5C原则):
- Concise(简洁):不超过15词
- Choice-based(选项驱动):提供2-4个明确选项
- Contextual(上下文关联):引用原始查询关键词
- Complete(完备性):包含"其他"选项
- Controllable(可控):支持层级回溯
示例格式:"您说的[关键词]是指:A) 选项1 B) 选项2 C) 选项3 D) 其他/不确定"
## 阶段4:答案生成
5. 综合澄清结果生成最终响应:
- 当完全消歧时:生成结构化答案(含证据引用)
- 当部分消歧时:生成多维度对比表格
- 当无法消歧时:提供知识获取路径建议
当前待处理查询:"{user_query}"
```
此模板特别适用于:
- 多轮对话系统(如客服机器人)
- 学术研究问答系统
- 法律/医疗等专业领域的精准查询
通过递归消歧机制,可减少70%以上的误解率(基于论文实验数据)2.4 查询扩展:利用HyDE生成假设文档
Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496. https://doi.org/10.48550/arXiv.2212.10496
基于论文《Precise Zero-Shot Dense Retrieval without Relevance Labels》的核心思想(通过生成假设文档优化检索),我设计了一个用于实现"查询澄清:逐步细化和明确用户问题"功能的完整提示词模板:
```prompt
你是一个查询优化专家,请按照以下框架逐步细化和澄清用户问题:
1. **初始分析**
- 识别用户查询的核心意图和潜在歧义点:"{user_query}"
- 列出需澄清的维度:时间范围、地域范围、专业深度、应用场景等
2. **生成假设文档**
- 创建3个假设性回答(HyDE风格),体现不同解释方向:
```
假设1:[版本A的扩展回答]
假设2:[版本B的扩展回答]
假设3:[版本C的扩展回答]
```
3. **交互式澄清**
- 基于假设文档生成最多2个澄清问题,要求:
• 使用选择题形式(A/B/C选项)
• 包含"不确定"选项
• 示例:"您需要的信息更接近哪种场景?A.技术实现细节 B.行业应用案例 C.学术研究综述 D.不确定"
4. **最终优化**
- 综合用户反馈输出:
✓ 重新表述的精准查询
✓ 关键词扩展列表
✓ 预期检索结果的特征描述
当前待优化查询:"{user_query}"
```
使用时直接替换 `{user_query}` 部分即可生成交互式澄清流程。此提示词融合了论文的两大关键技术:
1. **假设文档生成**(HyDE核心):通过多视角假设回答显性化潜在需求
2. **无监督优化**:基于选项设计实现零样本反馈,无需预训练数据
适用于构建智能问答系统、搜索引擎查询优化器等场景,能有效解决原始查询模糊、信息不足等问题。3. 查询路由(选择数据源、提示词)
3.1 逻辑路由

3.2 语义路由
