1 万维网概述
1.1 万维网概述
万维网WWW(World Wide Web)是一个大规模的、联机式的信息储藏所,并非某种特殊的计算机网络。
访问方法:链接;提供分布式服务
万维网是分布式超媒体(hypermedia)系统:
- 超文本hypertext系统的扩充,超文本:多个信息源链接成,是万维网的基础
- 超媒体与超文本文档内容不同
- 分布式系统:信息分布在整个互连网上,每台主机上的文档独立管理
万维网的工作方式:客户端/服务器方式
- 客户端程序:浏览器
- 服务器程序:在万维网文档所在的主机上运行,称为万维网服务器
- 客户端程序向服务器程序发出请求,服务器程序向客户端程序送回客户需要的万维网文档
- 在一个客户程序主窗口上显示出的万维网文档称为i而页面(page)

万维网需要解决的问题

1.2 统一资源定位符URL
用于资源定位,每个资源由URL唯一标识

1.3 超文本传输协议HTTP
HTTP是应用层协议,定义通信的格式和规则,是万维网上能可靠地交换文件的重要基础。
使用面向连接的TCP/QUIC作为传输层协议,保证数据的可靠传输;
HTTP本身是无连接的;
HTTP是无状态的,没有记忆能力
1 HTTP/1.0
HTTP/1.0每请求一个文档要重新建立新的TCP连接,即非持续连接

2 HTTP/1.1
HTTP/1.1使用持续连接
非流水线方式

流水线方式

3 HTTP/2
HTTP/2改进:
- 多路复用:允许在单个TCP连接上同时发送多个请求和接收多个响应。这意味着不再需要等待前一个请求的响应完成,后续请求可以立即发送。解决队头阻塞
- 二进制分帧:HTTP/2将HTTP消息分割为更小的二进制帧,并对每个帧进行标识和优先级排序。这样可以更灵活地传输和处理HTTP消息,不再受到HTTP/1.1中的消息顺序限制。
- 头部压缩
- 服务器推送:支持服务器主动推送资源给客户端
4 HTTP/3
HTTP/3改进:
TCP改为QUIC

HTTP/3网站访问流程

更安全的HTTPS:结合HTTP协议和SSL/TLS协议,对内容进行加密
代理服务器
代理服务器(proxy server)又称万维网高速缓存,它代表浏览器发出HTTP请求

代理服务器会将源点服务器的内容保存在本地存储中,若有新的请求该内容,直接返回。
HTTP报文结构:
请求报文

请求报文的常见方法:

示例:

响应报文

状态码3位数,分为5类:- 1xx:通知信息,如请求收到了或正在处理
- 2xx:成功
- 3xx:重定向
- 4xx:客户端差错,如请求中有错误语法或不能完成
- 5xx:服务器差错
常见的三种状态行:
- HTTP/1.1 202 Accepted
- HTTP/1.1 400 Bad Request
- HTTP/1.1 404 Not Found
Cookie
万维网使用Cookie跟踪在HTTP服务器和客户端之间传递的状态信息

Cookie的实现原理

基于Cookie机制实现需身份认证才可访问信息请求

总结HTTP

1.4 万维网的文档
页面制作的标准语言HTML(HyperText Markup Language),后缀.html或.htm。

一些其它标签:
- <img>图片
- <a>链接,<a href="http://example.com>,链接可以是远程也可以是本地
CSS层叠样式表(Cascading Style Sheets)为HTML定义布局。
1.5 万维网的信息检索系统
搜索的程序——搜索引擎,分为2类:全文检索搜索、分类目录搜索

垂直搜索引擎:针对特定领域/人群
元搜索引擎:搜索引擎之上的搜索引擎
2 网络爬虫
爬虫:请求网站并提取数据的自动化程序。

如何请求
Request中包含:请求方式、请求URL、请求头、请求体
可能需要的字段:

Response中包含:响应状态、响应头、响应体
模拟浏览器发请求:Requests
如何提取
如何提取(解析)—— 解析的局部的文本内容会在标签对应的属性中存储
- 定位指定标签
- 提取标签或标签对应属性中存储的数据
可以直接处理、正则表达式匹配、BeautifulSoup、Xpath
动态网页内容获取
动态网页主题内容及内嵌URL信息完全封装与网页源文件中的脚本语言片段内,无法直接使用HTML标记匹配方法提取网页主题内容等。抓取动态网页的关键是分析网页数据获取和跳转逻辑。
1 利用HTML DOM树提取动态网页内的脚本语言片段

2 基于浏览器模拟
使用Selenium库模拟浏览器完成抓取,直接运行在浏览器中,浏览器按照脚本做出点击、输入、打开、验证等操作。包括三个关键内容:自动化测试代码、浏览器驱动、浏览器。三者关系如下:

爬虫检测技术
- 通过IP与访问间隔等请求模式的识别
- 通过Header内容
- 通过Cookie信息
- 通过验证码
- 通过客户端是否支持js分析

- 页面资源是否加载
- 是否通过Robots协议
通常在<域名>/robots.txt,告知网络爬虫可以抓取的页面
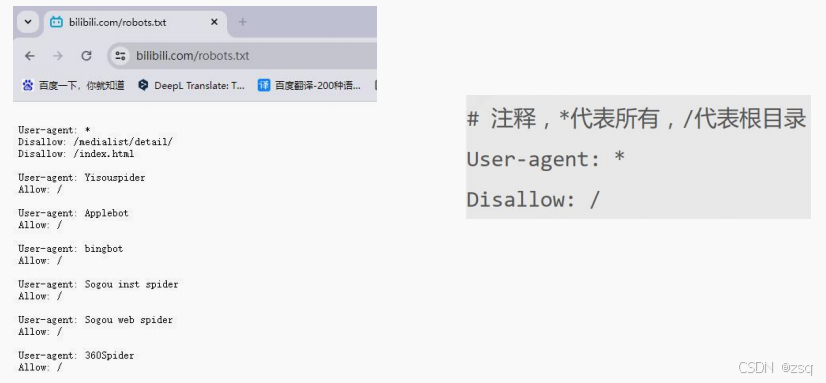


Robots协议是建议但非约束性,爬虫可以不遵守,但存在法律风险
反反爬:
- 使用代理服务器或云主机,不使用真实IP
- 使用Selenium模拟访问,构造合理的Headers,包括User-Agent和Hosts
- 使用不同的线程记录访问的信息,为每个线成保存Cookies
爬虫URL抓取策略:
WEB页面抽象为一张有向图,遍历图

- 深度优先遍历DFS:A-F-G E-H-I B C D
- 宽度优先遍历BFS:A-B-C-D-E-F G H I
- 反向链接数:一个网页被其它网页链接指向数量
- 大站优先:待下载页面数多的优先
- Partial PageRank:计算已下载与待抓取的URL每个页面的PageRank
3 网页排名
PageRank基于从许多优质的网页链接过来的网页,必定还是优质网页的回归关系,判定网页的重要性
两个假设:
数量假设:指向的入链(in-links)越多,网页重要性越高

质量假设:一个质量高的网页指向(out-links)一个网页,说明被指网页质量高

2. PageRank 的计算公式
PageRank 是通过一个迭代算法计算的。假设网页集合为 P = { P 1 , P 2 , … , P n } P = \{P_1, P_2, \dots, P_n\} P={P1,P2,…,Pn},每个网页 P i P_i Pi 有一个 PageRank 值 P R ( P i ) PR(P_i) PR(Pi)。PageRank 的计算公式如下:
P R ( P i ) = ∑ P j ∈ B P i P R ( P j ) L ( P j ) PR(P_i) = \sum_{P_j \in B_{P_i}} \frac{PR(P_j)}{L(P_j)} PR(Pi)=Pj∈BPi∑L(Pj)PR(Pj)
其中:
- P R ( P i ) PR(P_i) PR(Pi) 是网页 P i P_i Pi 的 PageRank 值。
- B P i B_{P_i} BPi 是指向网页 P i P_i Pi 的网页集合。
- L ( P j ) L(P_j) L(Pj) 是网页 P j P_j Pj 的出链数量(即 P j P_j Pj 链接到的网页数量)。
用转移矩阵/马尔可夫矩阵表示: P = M × V P=M \times V P=M×V

存在问题:
Dead Ends:只有入链没有出链,PR趋于0

解决方法:修正M,将无出链的设置为平均指向其它节点

Spider Traps:自指向的节点,PR趋于1

解决方法:
引入随机跳转(Random Teleport)的概念,即在迭代过程中以一定的概率 β \beta β随机跳转到其他网页,而不是只通过链接跳转
