一.分类:
1.概念:
分类中,输出变量y只能取少数几个可能值中的一个。
2.构建分类算法:
回答结果值只有两种:yes或者no,如以下图中所示。

其中,也可以用0或1,false或true表示结果值,其中0、no、false表示负例,而1,true和yes就是正例。
(1)线性回归:
- 不可取
如图所示为分类肿瘤是否为恶性的训练集示例,若在图中出现一个最右边的样本点,注意这个训练样本实际上不应该改变如何分类数据点,蓝色的垂直分界线任然合理,若一旦最右边添加额外的训练样本,线性回归的最佳拟合线将会像绿色线一样,若继续使用0.5阈值,则会将绿色垂直线左边预测为0,这不是合理的。
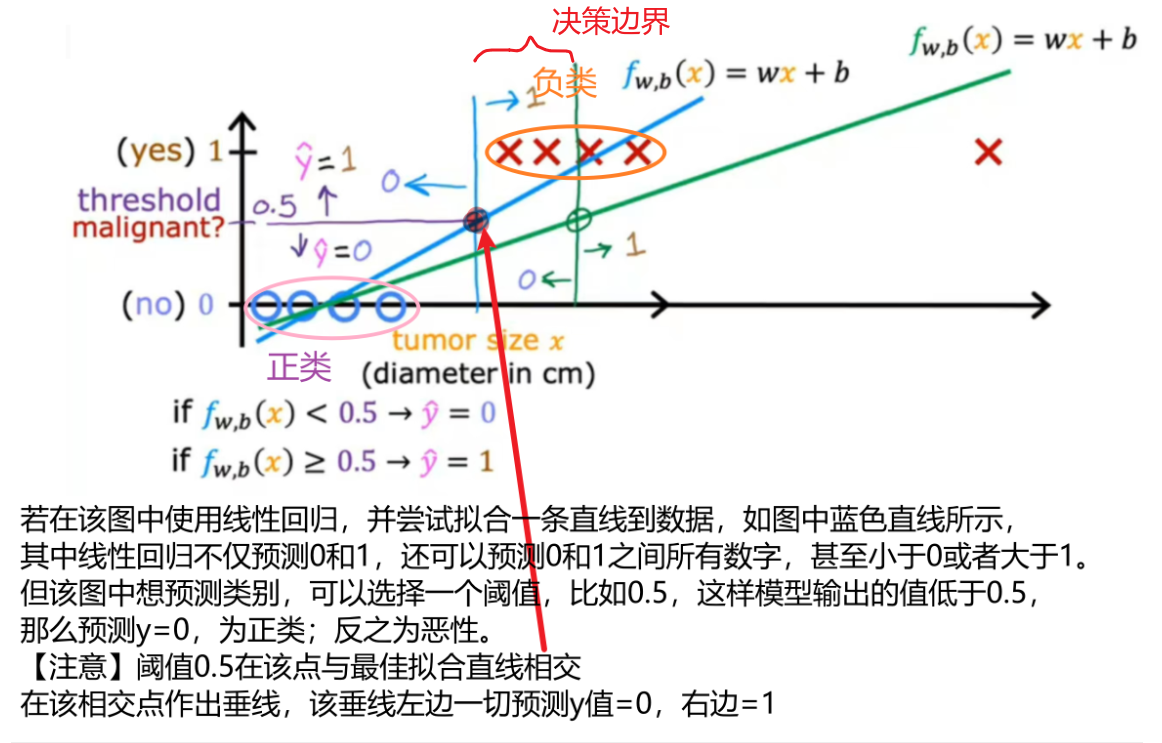
决策边界:线性回归导致最佳拟合线,当我们在右边添加一个样本时,向右移动从而分割线。
(2)逻辑回归:
<1>Sigmoid/逻辑函数:
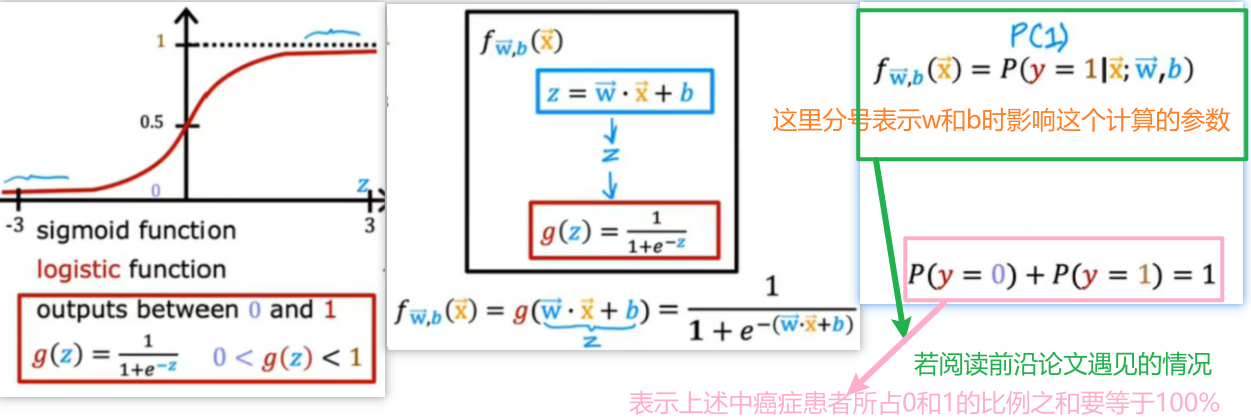
- 逻辑回归模型作用:输入一个特征或一组特征x,输出一个在[0,1]之间的值
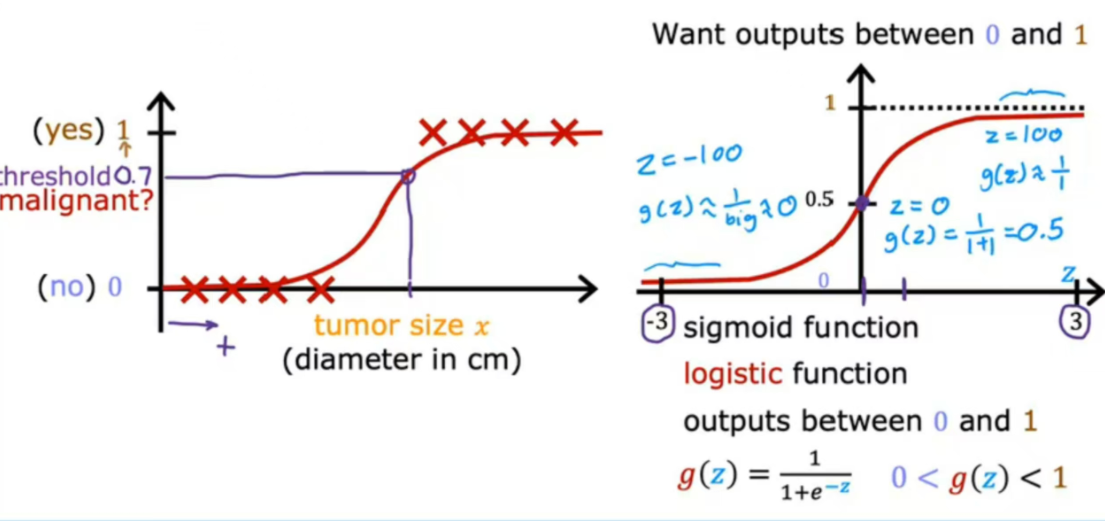
如图所示仍然以分类肿瘤为例,在<1>中线性回归不大合适,所以采用sigmoid函数,若一名患者由算法输出0.7,则偏向于恶性;这里机器所认为占恶性的比例70%,不是绝对的1或0。
如图所示为sigmoid函数的推导过程。
<2>决策边界:
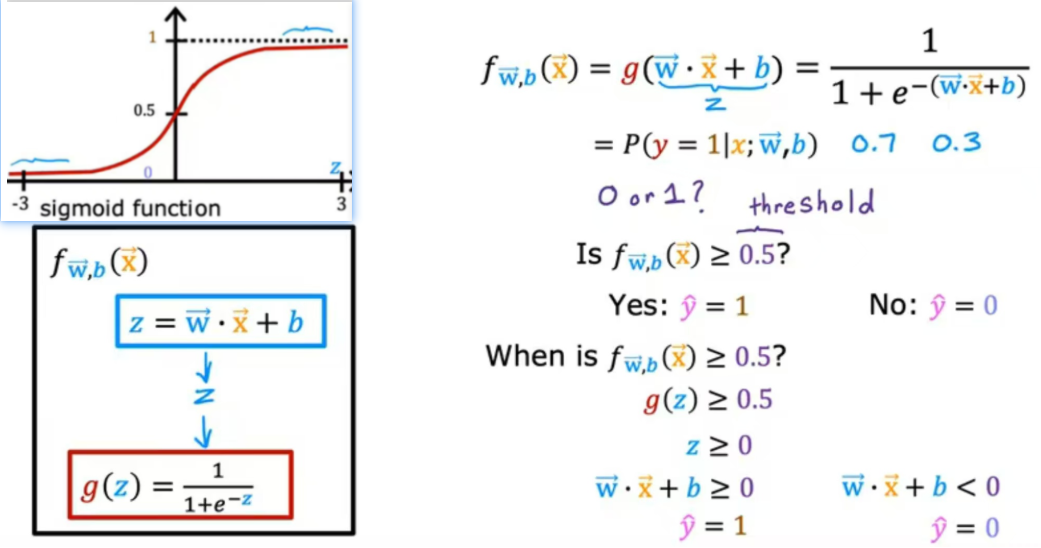
如图所示,上述例子中,如何判断肿瘤占1的比例大,还是占0的比例大,我们将以预测值y=0.5为分割,什么时候是f>=0.5?(当g(z)>=0.5,z>=0)如图中推导:
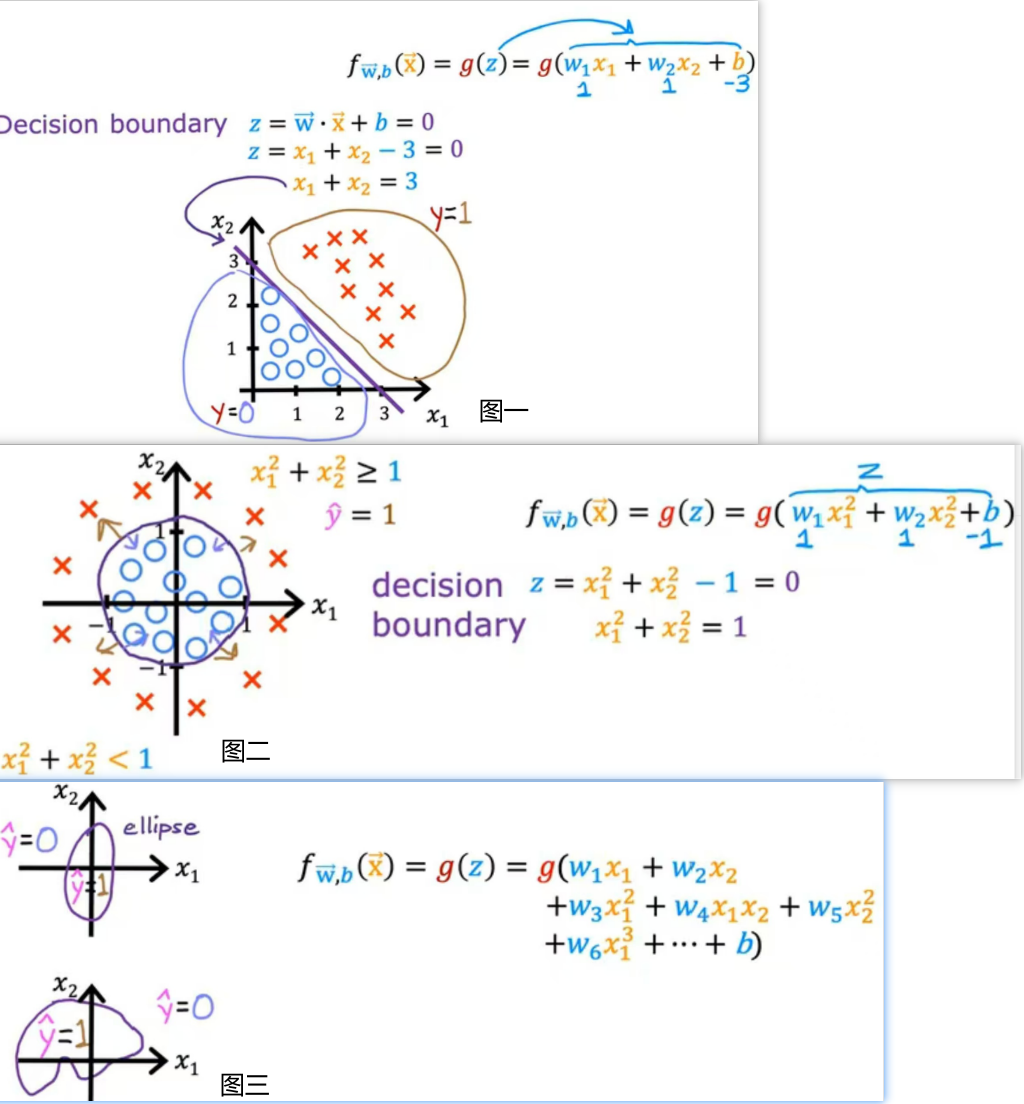
如图所示,图一中有两个特征,所示式子是z=w1x1+w2x2+b,要求决策边界,所以令z=0,去求特征值,蓝色区域是好类,黄色区域是差类,决策边界是紫色的线;图二比较复杂,采用多项式进行运算决策边界,紫色内区域是预测值为1;反之是预测值为正类;图三表示更复杂的模型,可能需要更复杂的多项式去求解,只是比了个例子而已。
<3>代价函数:
<3.1>损失与代价区分:

<3.2>推导过程:
成本函数提供了一种衡量特定参数集与训练数据适合度的方法,进而可以选择一个更好参数的方法。接下来将重点讨论为什么平方误差成本函数不是逻辑回归理想成本函数?并介绍一种可以帮助我们为逻辑回归选择更好参数的不同成本函数:
下图是可以逻辑回归模型的训练集,这里每一行可能对应一个患者,

该图中L是学习算法预测f(x)的函数以及真实值y,因此给定预测f(x)和真实值y的损失,在这种情况下等于1/2的平方差,选择不同的损失函数L,可以保持整体成本函数J作为一个凸函数。
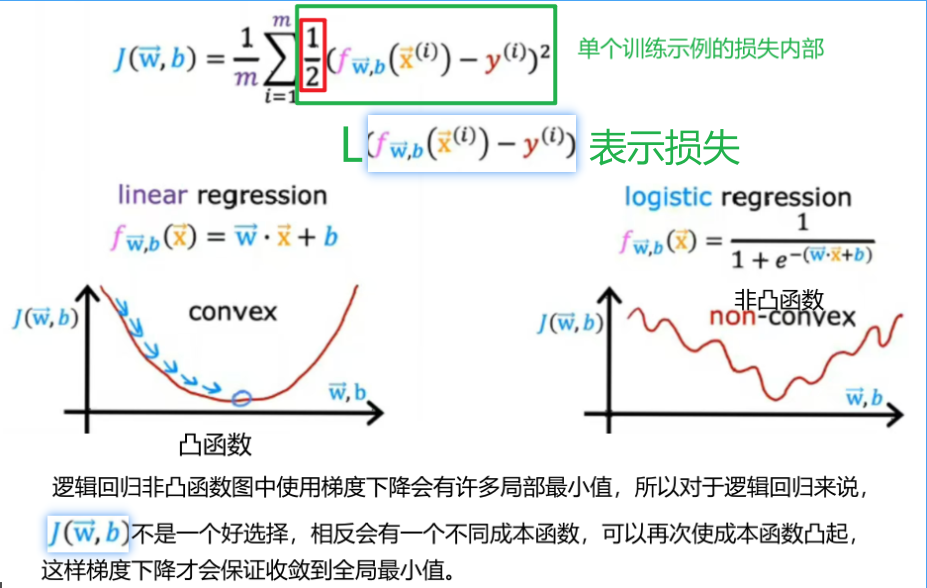
损失函数衡量的是单个训练样本的表现,通过对所有训练样本损失求和,可以得到J。
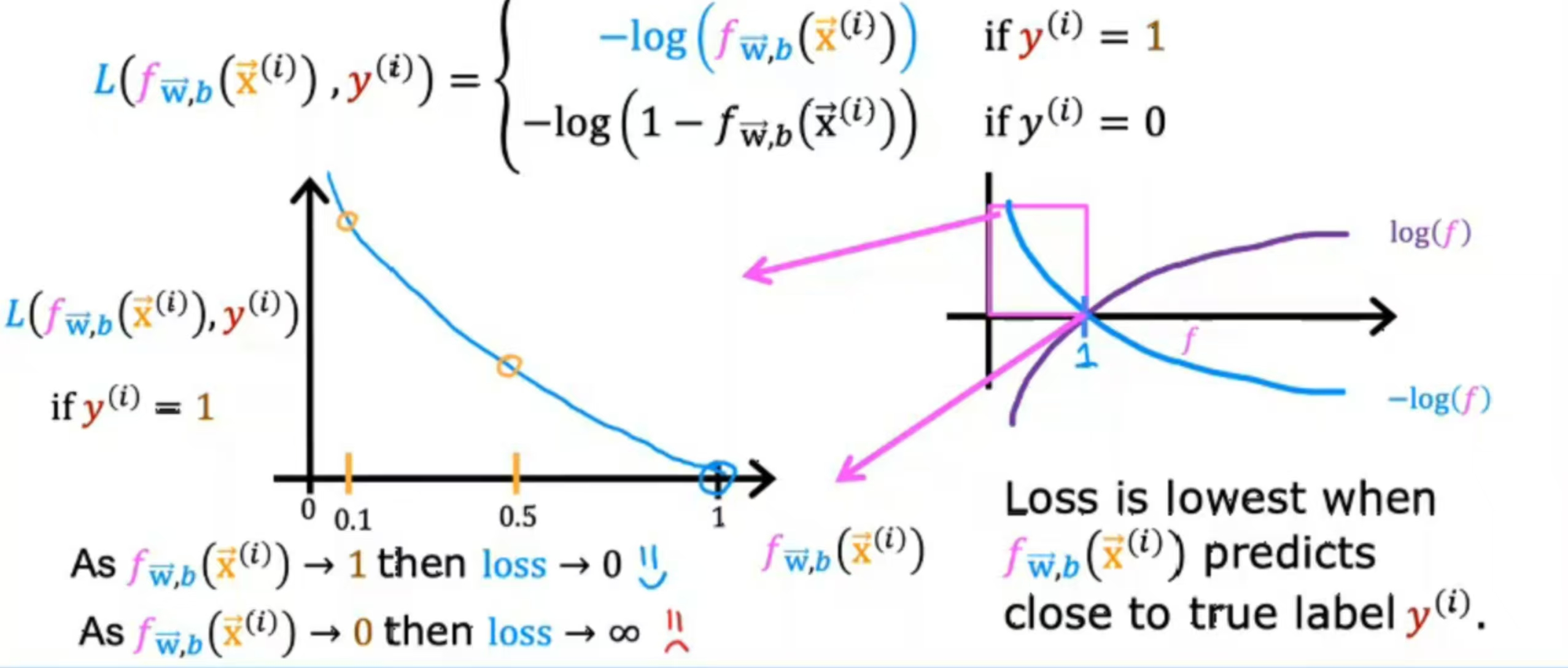
如图所示为逻辑回归的损失函数定义,若y=1,则损失函数就是-log(f(x)),绘制图像,在f(x)=1时与x轴相交,因为是逻辑回归值介于[0,1],所以函数作用范围只截取粉色段放大,;分析:若算法预测概率接近1,真实值为1时,那么损失是非常小的,几乎为0;例【若肿瘤检测预测值为0.5,真实值为1,损失在曲线中间的黄色圈圈;若预测为0.1,则损失值非常高】。
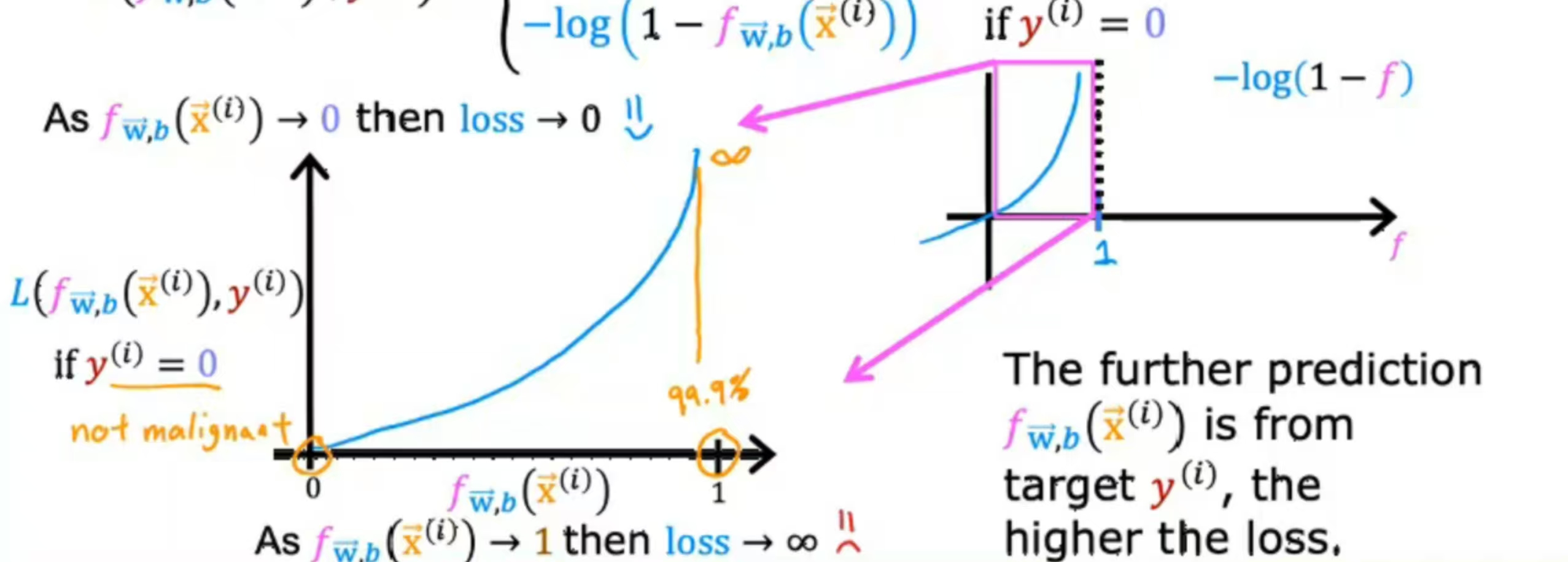
若y=0,向左移动1个单位得到如图所示,当f(x)非常接近0时,损失值非常小
- 总结:选择该损失函数,整体成本函数将变凸,可以更可靠的使用梯度下降找到全局最小值,
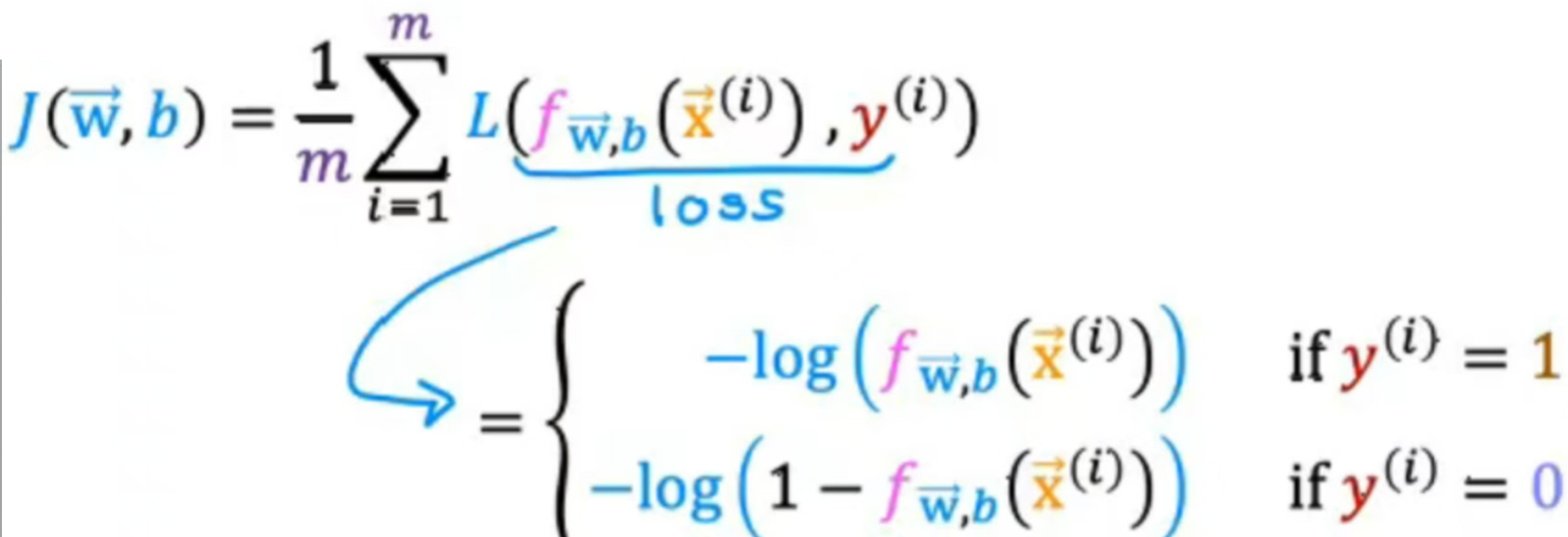
所以代价函数/成本函数也可以是这样的。
<3.3>简化版:

<4>梯度下降实现:
如何找到一个合适的参数w和b?

虽然梯度下降公式中,线性的和逻辑回归的差不太多,但其中的f(x)定义是不同的。
二.拟合:
1.是什么?
- 过拟合:模型在训练数据上表现好,在测试数据上表现很差;
- 欠拟合:模型在训练数据上和测试数据上都表现不佳;
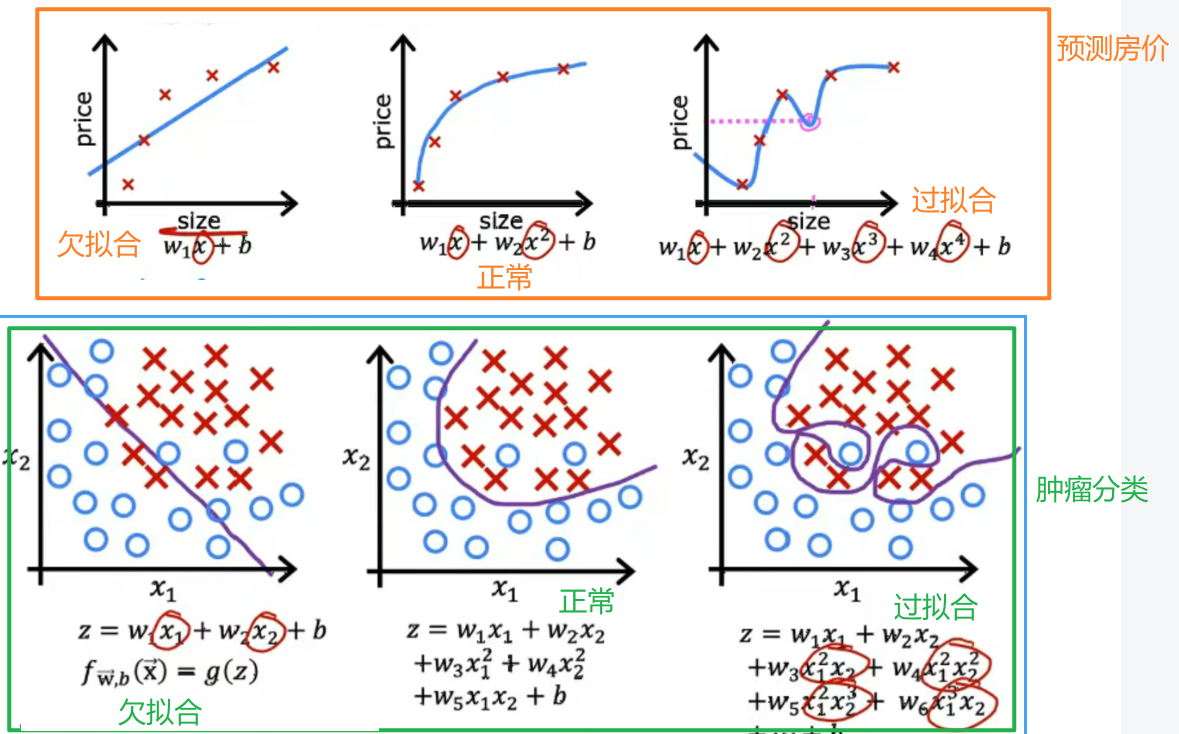
这里过拟合也称为高方差,欠拟合也称为高偏差。
2.过拟合解决方案:
- 获取更多训练数据
- 使用较少特征
- 正则化减少参数大小:鼓励学习算法缩小参数值(不是直接为0)
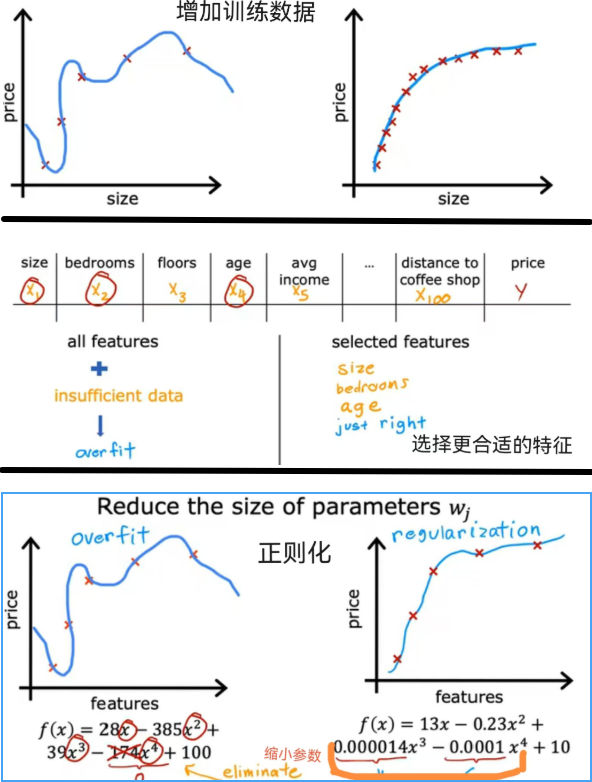
3.正则化:
(1)代价函数:
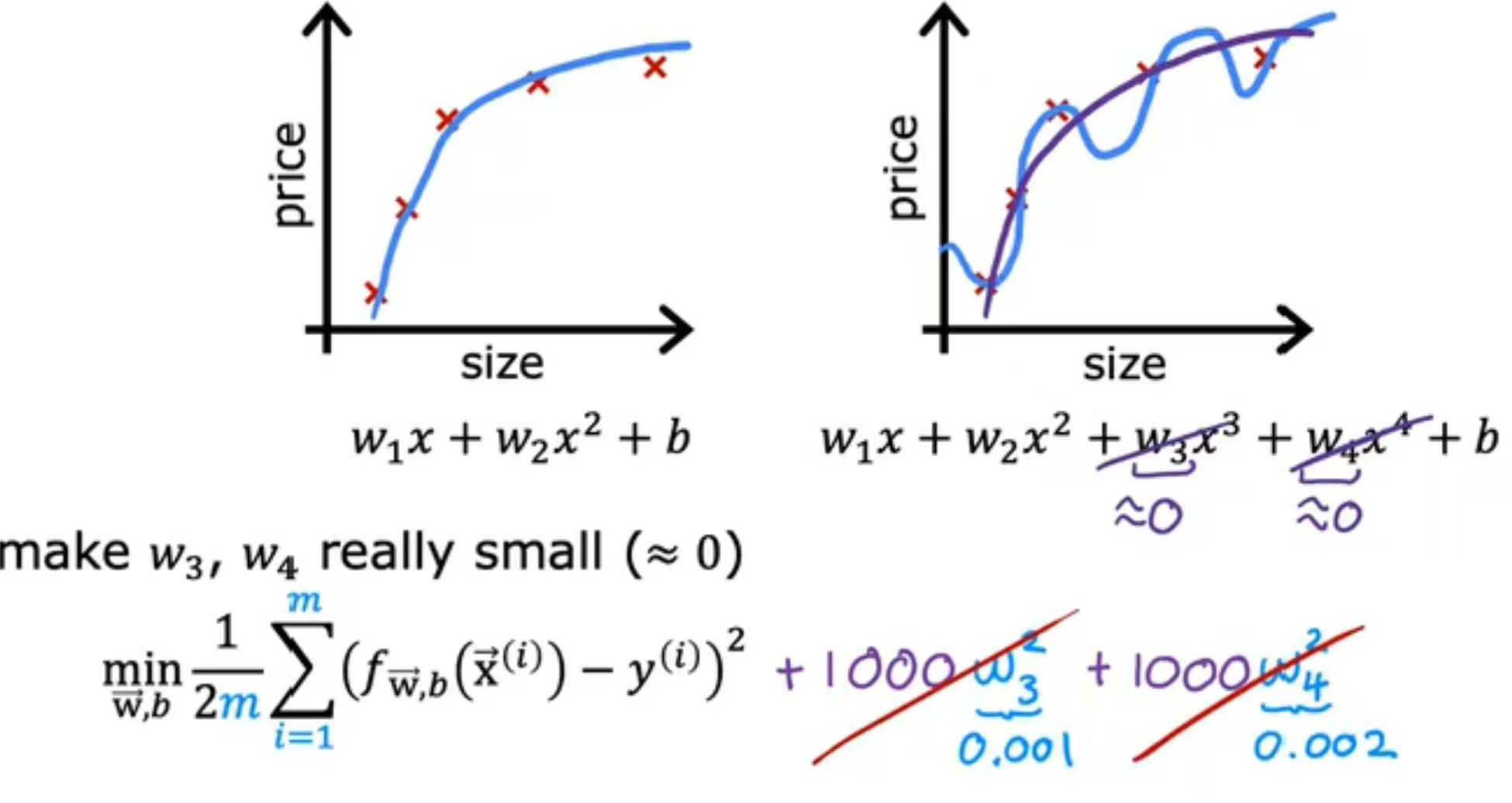
如图所示,以房价预测为例,最合适的预测曲线为w^2,若为w^4则会产生过拟合现象,当使用正则化使得w3与w4接近于0时,模型是最优的;
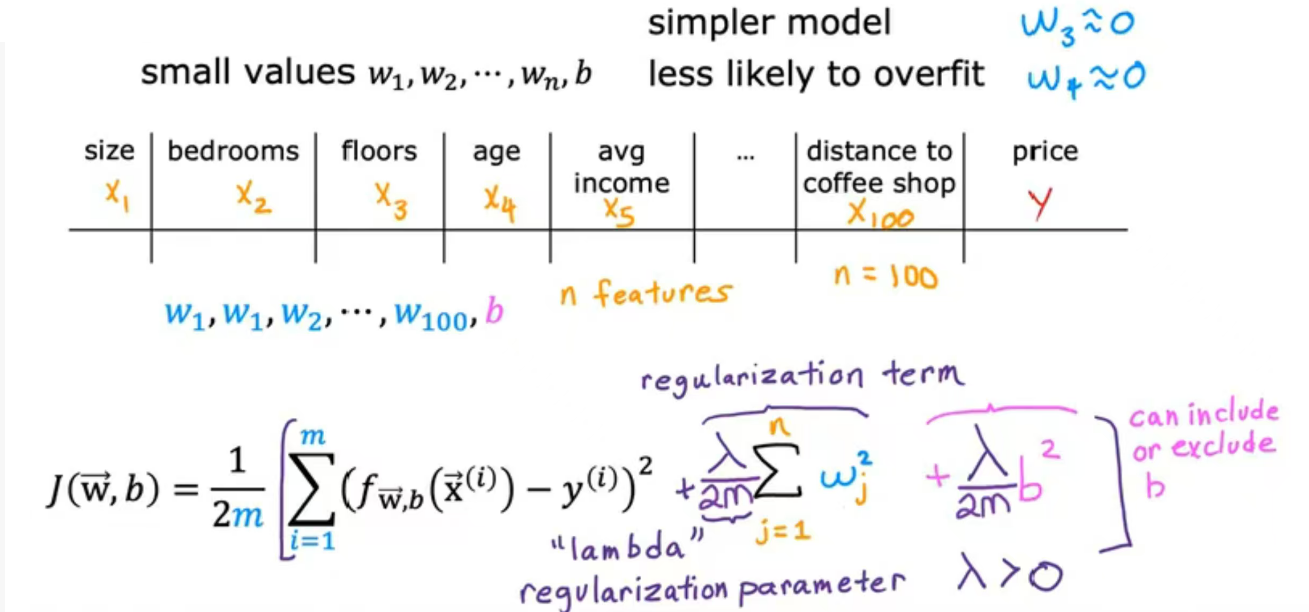
如图所示,n为特征数(图中n=100),常见的是对w进行正则化,b正则化不常见。
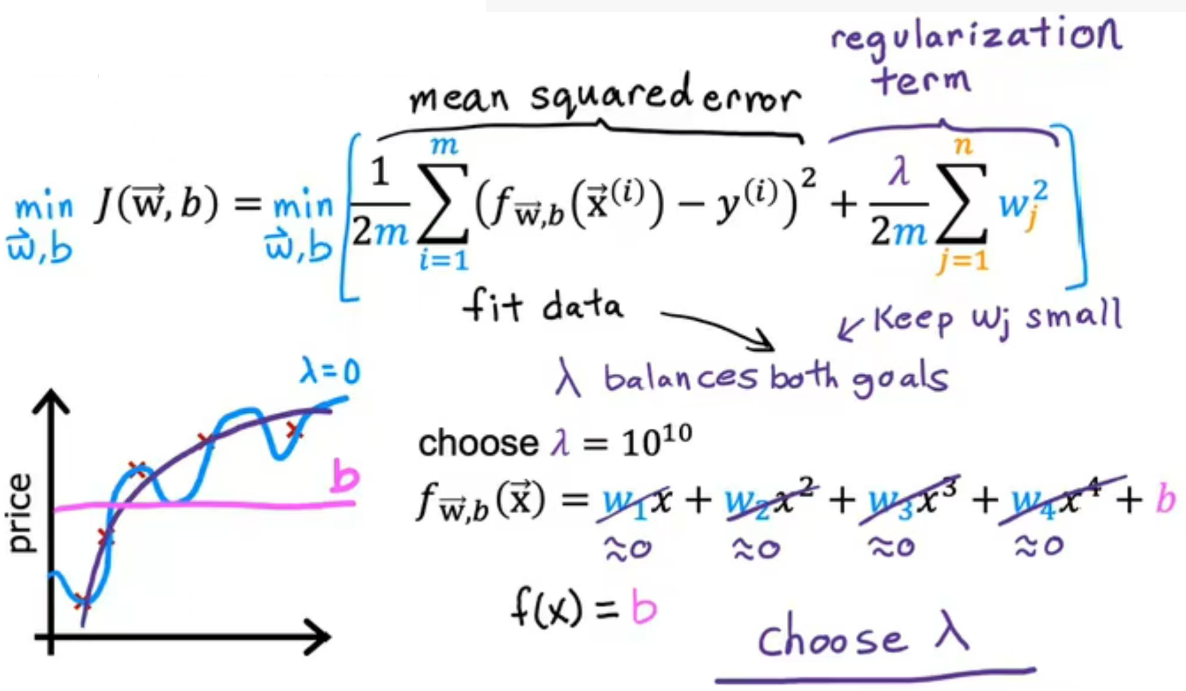
如图所示,J(w,b)为新的成本函数,若最小化第一项。算法通过最小化平方误差来更好的拟合训练数据预测值与实际值之间的差异;若最小化第二项,算法试图使参数wj保持较小,将会倾向于减少过拟合,λ可以相对权衡这两项。
若λ=0,则房价预测过拟合;若λ=10^10,w1、w2、w3、w4接近0,则f=b欠拟合;只有选择合适的λ,模型才可以更好的拟合数据,兼顾最小化均方误差和保持参数较小。
(2)梯度下降
<1>线性回归:
如何通过正则化线性回归实现梯度下降?
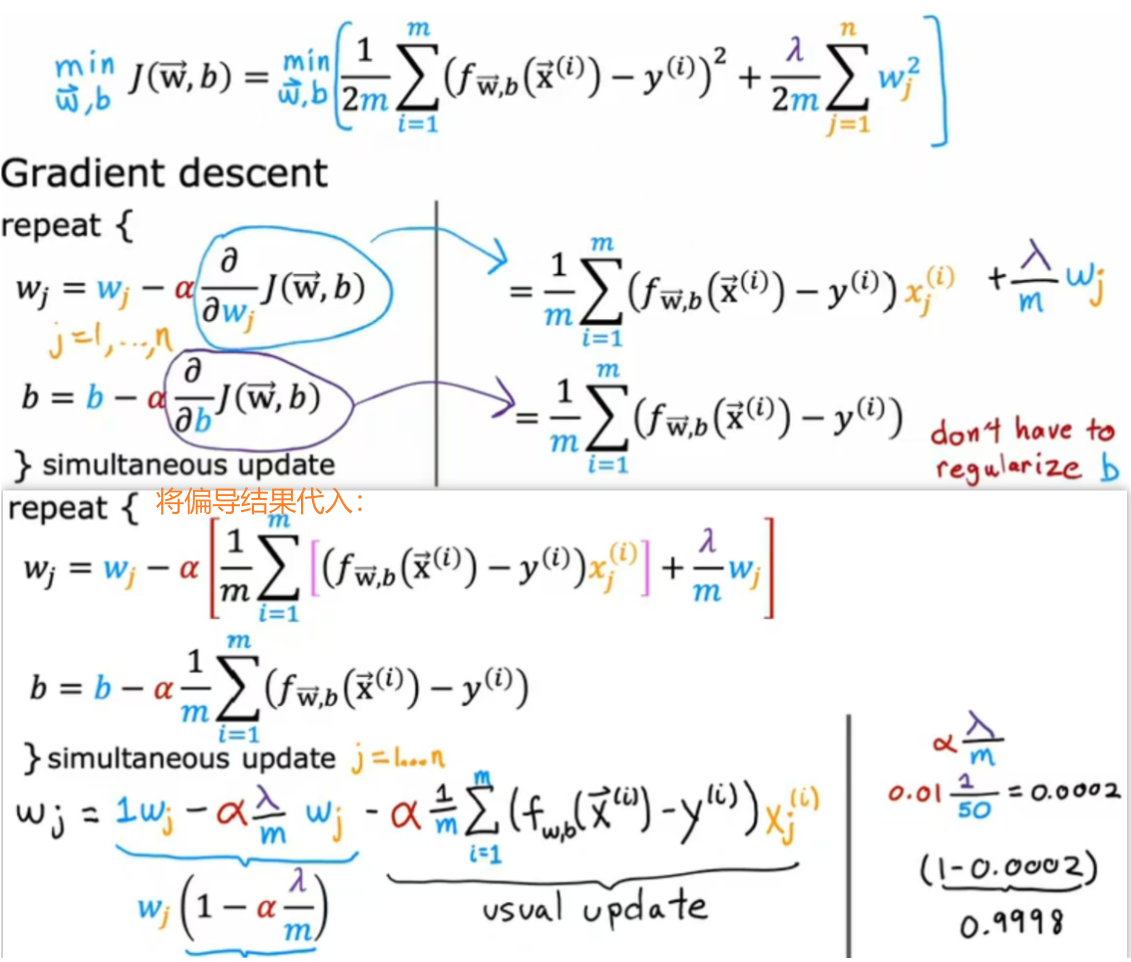
如图所示为正则化的成本函数与梯度下降,图中最下方的是进行整理,假设λ=1,α=0.01,m=50(样本数),则在每一次梯度下降的迭代中,wj*0.9998,也就是进行常规更新之前乘以一个稍微小于1的数字,效果是让wj的值稍微小一点。
推导过程如下:
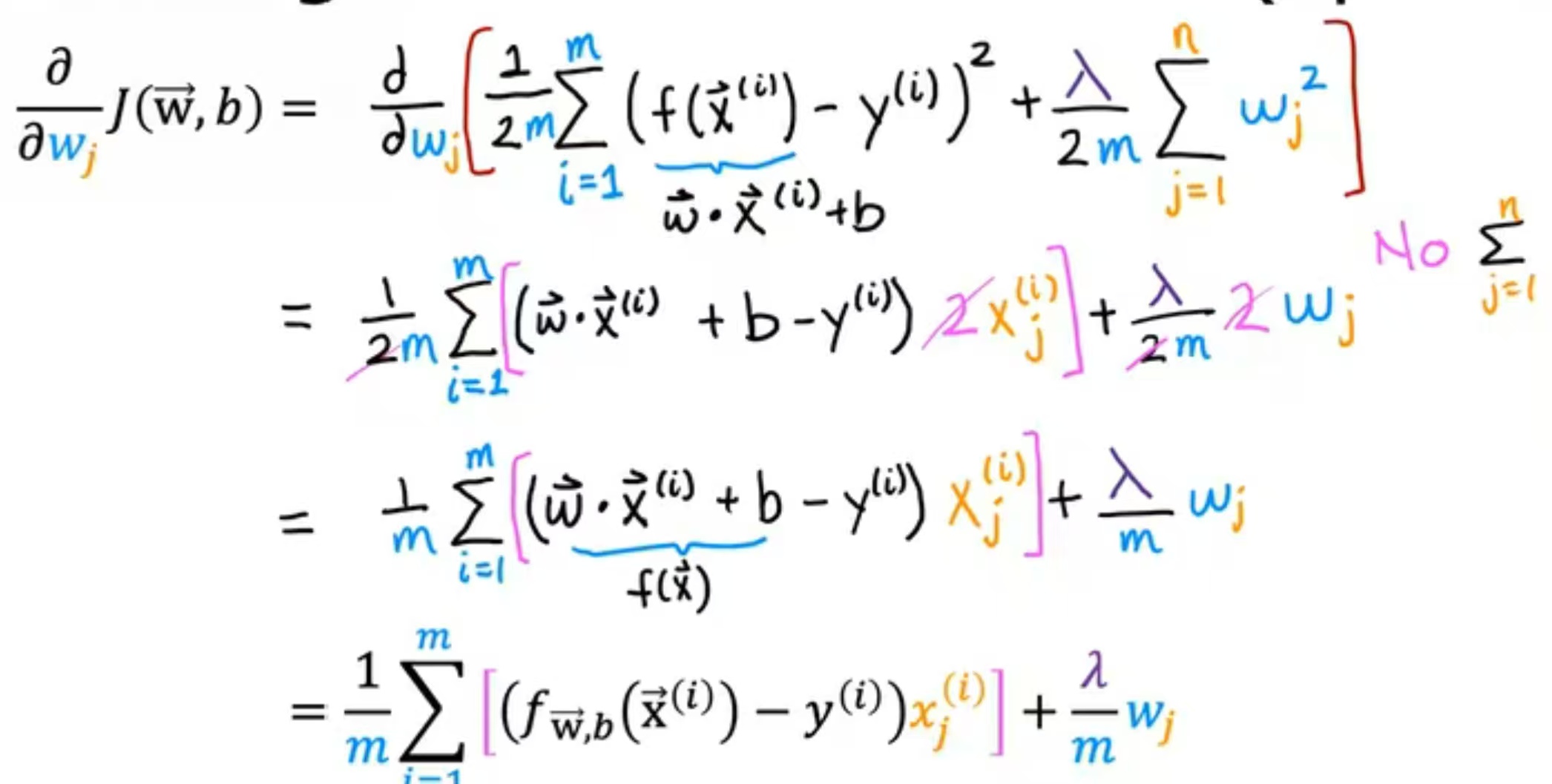
<2>logistic回归:

如图所示为逻辑回归正则化的成本函数,效果图如橙色线所示;
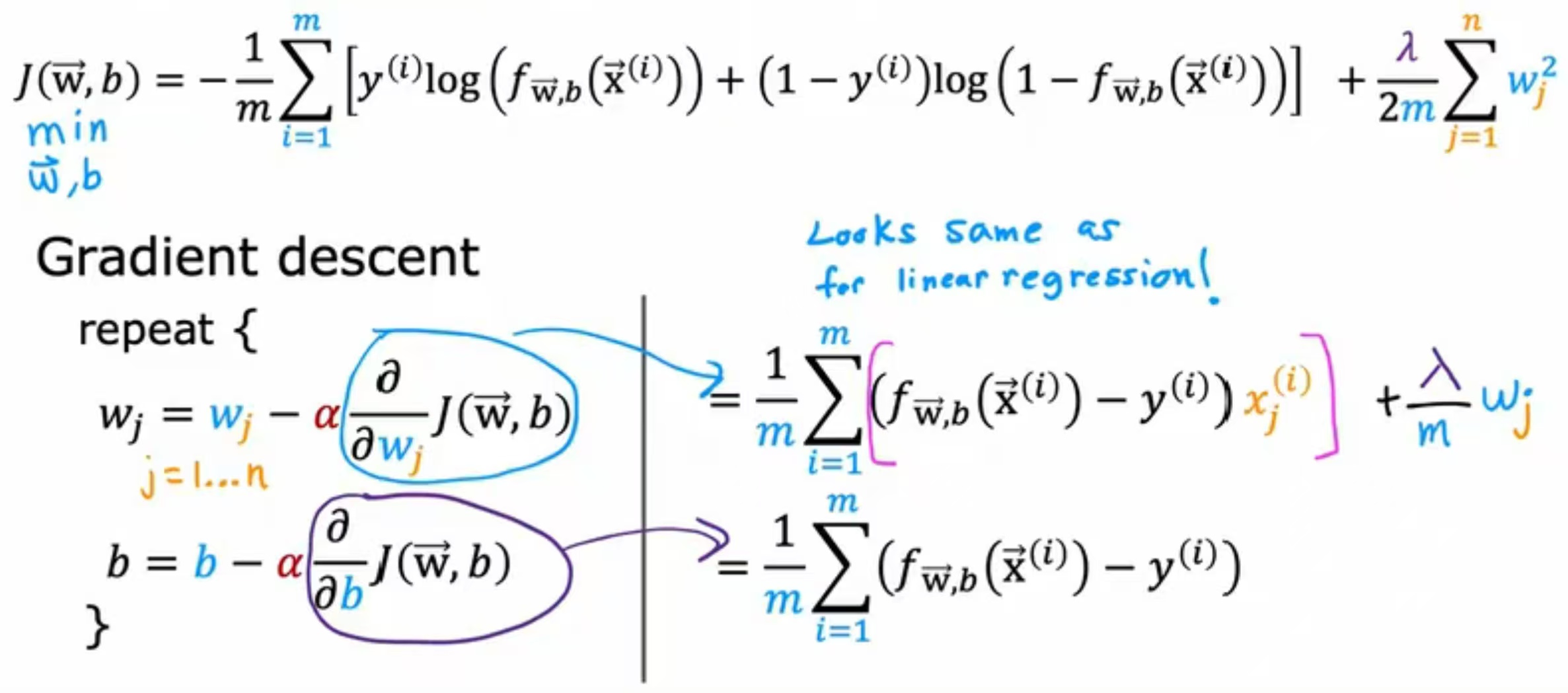
如图所示,为逻辑回归正则化的梯度下降公式。
四:线性和逻辑区分总结:

MSE(均方误差) 。
。
