VideoBooth:基于扩散的视频生成与图像提示
paper title:VideoBooth: Diffusion-based Video Generation with Image Prompts
paper是NTU发表在CVPR 2024的工作
Code:链接

图1. 由图像提示生成的视频。我们的 VideoBooth 可以生成包含图像提示中指定主体的视频。
Abstract
基于文本驱动的视频生成正在快速发展。然而,仅仅依赖文本提示并不足以描绘出准确符合用户意图的主体外观,尤其是在定制化内容创作中。本文研究了带有图像提示的视频生成任务,图像提示相较于文本提示提供了更为准确和直接的内容控制。具体来说,我们提出了一个前馈框架 VideoBooth,并设计了两个核心模块:
- 我们提出以由粗到细的方式嵌入图像提示。来自图像编码器的粗视觉嵌入提供图像提示的高层编码,而来自所提出的注意力注入模块的细视觉嵌入则提供多尺度和细粒度的图像提示编码。这两种互补的嵌入能够忠实捕捉所需的外观特征。
- 在细粒度的注意力注入模块中,多尺度图像提示被输入到不同的跨帧注意力层,作为额外的键和值。这些额外的空间信息能够细化第一帧的细节,并传播到后续帧,从而保持时间一致性。
大量实验表明,VideoBooth 在生成由图像提示指定主体的高质量定制视频方面达到了最新的性能水平。值得注意的是,VideoBooth 是一个可泛化的框架,只需前馈推理即可使单一模型适用于广泛的图像提示场景。
1. Introduction
文本到图像模型 [16, 17, 20, 26, 31, 37, 39, 43–45, 62, 67–69, 73, 75] 已经引起了大量关注。随着 Stable Diffusion [69] 的出现,我们可以轻松地通过文本生成图像。最近,研究重点转向了文本到视频模型 [6, 18, 30, 38, 46, 48, 60, 76, 80, 84, 85, 97],通过输入文本描述来生成视频。然而,在某些用户场景下,仅依赖文本提示不足以准确地定义符合用户意图的主体外观 [21, 71]。例如,如图 2 所示,如果我们想生成一段包含第三行中的狗的视频,我们需要在文本提示中使用多个修饰性附加词来定义狗的外观。即使添加了这些丰富的附加词,模型仍然无法生成期望的外观。仅通过文本定义目标对象的外观存在以下缺陷:1) 很难穷尽所有期望的属性;2) 模型无法通过长文本准确捕捉所有属性。相比之下,更直接的方式是提供参考图像,即图像提示。图像提示是文本提示的补充,能够丰富文本难以描述的细节。

图2. 图像提示的使用。我们使用三种不同类型的提示生成了三个视频片段:简单文本提示、长文本提示和图像提示。我们使用 LLaVa 模型 [55] 生成一个描述图像提示外观的文本提示。仅使用文本提示无法完全捕捉图像提示的视觉特征。
已有一些尝试将图像提示引入到文本到图像模型中,大致可以分为两类。一类是利用少量参考图像对部分参数进行微调 [15, 21, 28, 51, 71],这些参考图像包含在不同环境下捕获的相同对象。然而,这类方法对参考图像数量的要求较高,而有时无法实际获得同一对象的多张图像。另一类方法 [11, 42, 52, 83, 87, 88] 则旨在解决这一限制,提出将图像提示嵌入到文本到图像模型中,并在推理时无需微调。这两类尝试都在生成包含图像提示中指定对象的图像方面取得了合理的效果。
本文研究了一个更具挑战性的任务,即带有图像提示的文本到视频生成。该任务有两个主要挑战:1) 与文本到图像生成类似,需要准确捕捉图像提示的属性并在生成的视频中体现出来;2) 不同于文本到图像生成,我们的目标是对象的动态运动,而不仅是静态状态。直接将这些方法迁移到视频领域会导致外观不匹配或动作不自然退化。为了解决这些挑战,我们提出了 VideoBooth,设计了精细的由粗到细视觉嵌入组件:1) 粗视觉嵌入(通过图像编码器):训练一个图像编码器,将图像提示注入到文本嵌入中;2) 细视觉嵌入(通过注意力注入):将图像提示映射到多尺度潜在表示,通过文本到视频模型的跨帧注意力控制生成过程。
具体来说,受早期尝试 [42, 83] 的启发,在带有图像提示的文本到图像模型中,我们使用预训练的 CLIP 模型 [66] 提取所提供图像提示的 CLIP 图像特征。然后将提取的特征映射到文本嵌入空间中,用于替换部分原始文本嵌入。训练良好的编码器嵌入了图像提示的粗略外观信息。然而,粗视觉嵌入是一种通用嵌入:1) 它仅包含高层语义信息;2) 它在相同尺度的所有模块之间共享。因此,一些视觉细节在粗视觉嵌入中丢失。
为了进一步细化生成的细节并保持时间一致性,我们将多尺度图像提示注入到不同层的跨帧注意力模块中,这与高度压缩的粗视觉嵌入不同。图像提示提供了空间信息以及不同粒度的细节。一方面,保持图像提示的空间信息能够保留更多细节。另一方面,不同的跨帧注意力模块在不同尺度上需要详细信息。具体来说,图像提示的潜在表示被附加为额外的键和值,用于细化生成的第一帧的细节。为了将细化后的第一帧传播到后续帧以保持时间一致性,我们进一步使用更新后的第一帧值作为后续帧的值。
我们建立了一个专用的 VideoBooth 数据集来支持对这一新任务的研究。每个视频都提供一张图像提示和一个文本提示。大量实验表明,我们提出的 VideoBooth 在生成包含图像提示中指定主体的视频方面效果显著。如图 1 所示,VideoBooth 生成的视频更好地保留了图像提示的视觉属性。此外,我们提出的 VideoBooth 在推理时无需微调,只需前馈推理即可生成视频。我们的贡献总结如下:
- 据我们所知,我们是第一个在推理时无需微调的情况下探索使用图像提示进行视频生成的任务。我们提出了一个专用数据集来支持该任务。我们提出的 VideoBooth 框架能够生成包含图像提示中指定主体的一致性视频。
- 我们引入了一种新的由粗到细的视觉嵌入策略,通过图像编码器和注意力注入,更好地捕捉图像提示的特征。
- 我们提出了一种新颖的注意力注入方法,利用带有空间信息的多尺度图像提示来细化生成的细节。
2. Related Work
文本生成视频模型(Text-to-Video Models)以文本描述作为输入并生成视频片段。早期的探索 [34, 80] 基于 VQVAE 的思想。Make-A-Video [76] 提出在 DALLE2 模型 [68] 的架构上增加时间注意力。最近,扩散模型 [32, 70] 的出现推动了文本生成视频模型的研究 [1, 23, 30, 33, 60, 82, 97]。Video LDM [6] 提出在 Stable Diffusion 上训练文本生成视频模型,并引入时间注意力和三维卷积来处理时间生成。Gen-1 [18] 引入深度图来处理文本生成视频模型的时间一致性。一些方法 [27, 95] 通过训练单独的模块来合成动作。所有这些方法都用预训练的文本生成图像模型初始化它们的模型。另一种使用文本生成图像模型的范式是直接将 Stable Diffusion [69] 应用于小样本或零样本设置。Tune-A-Video [84] 将自注意力改造成跨帧注意力,然后在一个视频片段上微调 Stable Diffusion 模型。以这种方式训练的模型能够将动作从原始视频中迁移出来。Text2Video-Zero [48] 提出通过使用相关噪声图来提高一致性,从而生成视频。除了视频生成之外,扩散模型还被应用于视频到视频的生成 [8, 9, 19, 24, 36, 41, 54, 58, 64, 65, 74, 81, 89, 90, 94]。
定制化内容生成旨在使用参考图像生成图像和视频 [15]。对于定制化的文本生成图像,优化方法 [28, 35, 51, 53] 被提出用于优化扩散模型的权重。例如,Textual Inversion [21] 优化词嵌入,而 DreamBooth [71] 也提出微调 Stable Diffusion 的权重。优化方法需要多张同一主体的参考图像以避免模型过拟合,这在实际应用中要求较高。微调的成本阻碍了这些方法的实际使用。为解决这些限制,提出了基于编码器的方法 [61, 88, 91, 98],通过学习映射网络来嵌入参考图像。ELITE [83] 提出学习全局映射网络和局部映射网络,将图像编码为词嵌入。Jia 等 [42] 提出使用额外的跨注意力来嵌入图像特征。通过训练好的编码器,可以在一次前向传播中实现个性化生成。一些最新的工作 [2, 11, 22, 25] 将基于编码器的模型与基于微调的模型结合,以提高性能。BLIP-Diffusion [52] 提出在大规模数据集上预训练多模态编码器,然后在特定主体上微调模型以进行推理。定制化图像生成还被应用于将对象放置到用户指定的场景中 [4, 13, 50, 77, 93]。此外,还进行了个性化人脸生成的研究 [12, 14, 40, 72, 79, 86, 87, 92]。He 等 [29] 从数据角度提出提高性能的方法。一些工作 [3, 47, 59] 专注于在一张图像中组合多个主体。除了图像生成的工作外,还有一些关于个性化视频操作的早期尝试。Make-A-Protagonist [96] 使用 Stable Diffusion 2.1 来嵌入图像提示,以个性化的方式编辑现有视频。原始视频的动作由 Tune-A-Video [84] 学习。VideoDreamer [10] 提出通过先使用基于微调的方法生成第一帧,然后使用 Text2Video-Zero [48] 生成视频片段,从而生成个性化视频。不同于现有工作,我们提出的 VideoBooth 在推理时无需微调任何权重。
3. VideoBooth
我们提出的 VideoBooth 旨在从图像提示 I I I 和文本提示 T T T 生成视频。图像提示指定了主体的外观。我们提出的 VideoBooth 的概览如图 3 所示。图像提示以两种层级输入到 VideoBooth 中。在粗粒度层级,它被输入到一个预训练的 CLIP 图像编码器中以提取视觉特征。一个由多个 MLP 层组成的编码器被训练来将视觉特征映射到文本嵌入的空间中。获得的嵌入 f I f_I fI 将被插入到文本嵌入中,该文本嵌入是通过将文本提示 T T T 输入到 CLIP 文本编码器中提取的。为了进一步细化合成的细节,我们提出将图像提示 I I I 注入到预训练视频扩散模型的跨帧注意力模块中。具体来说,我们将图像提示 I I I 的潜在表示 x I t x_I^t xIt 添加到跨帧注意力中。通过这种方式,具有空间信息的多尺度视觉细节被引入注意力图的计算中,从而使视觉特征能够得到更好的保留。以这种由粗到细的方式输入图像提示,两种方式可以相互协作。编码器提供图像提示的粗视觉嵌入,而注意力注入则提供细粒度的视觉嵌入。
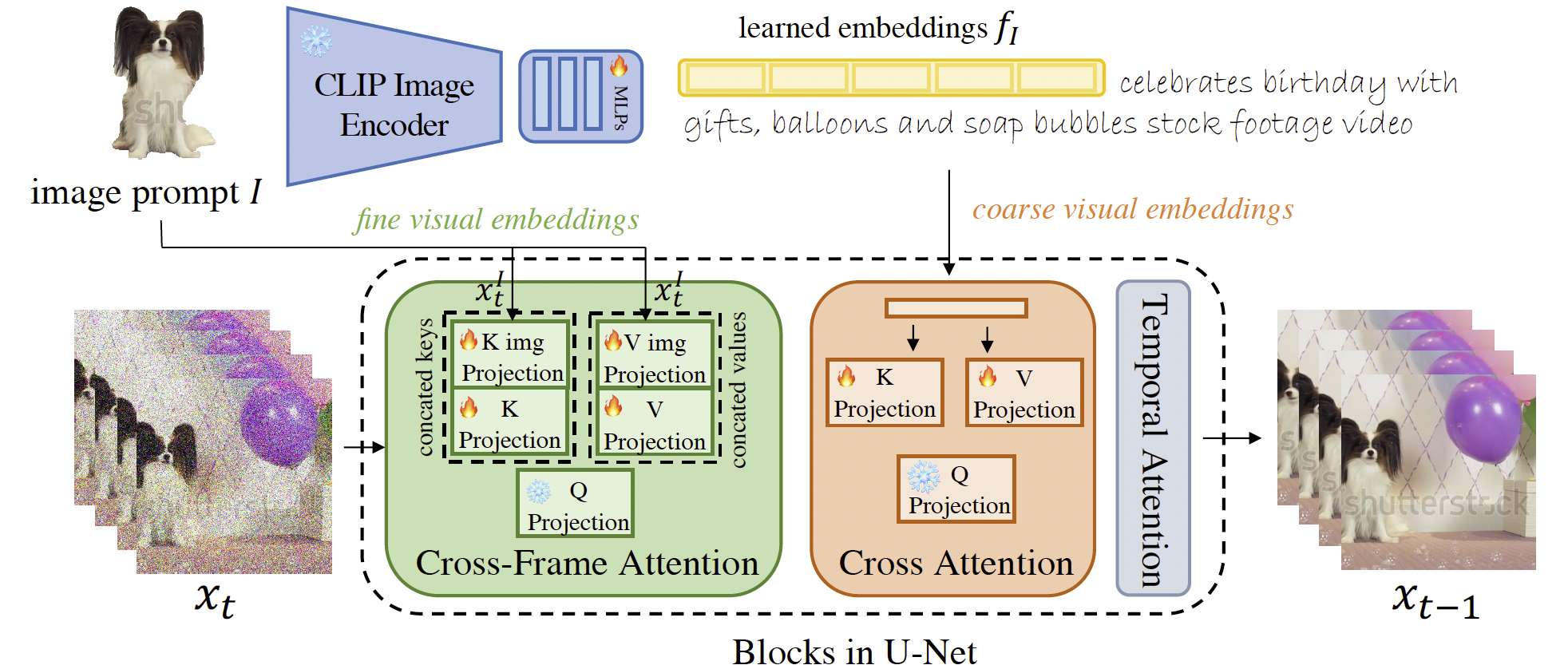
图3. VideoBooth 概览。VideoBooth 通过接收图像提示 I I I 和文本提示 T T T 作为输入来生成视频。图像提示被输入到 CLIP 图像编码器中,随后经过 MLP 层。获得的粗视觉嵌入 f I f_I fI 然后被插入到文本嵌入中。组合后的嵌入作为交叉注意力的输入。编码器提取的嵌入提供了图像提示外观的粗编码。为了进一步细化生成视频中的细节,在细粒度层级,我们将图像提示的潜在表示附加到跨帧注意力中,作为额外的键和值。不同的跨帧注意力层接收具有不同尺度的潜在表示。带有空间细节的多尺度特征能够细化合成的细节。
3.1. Preliminary: Pretrained Text-to-Video Model
我们提出的 VideoBooth 是基于预训练的文本到视频模型 [30, 82, 84] 开发的。在本节中,我们将简要介绍文本到视频模型的框架。膨胀 2D 卷积。为了处理视频数据并捕捉时间相关性,Stable Diffusion 模型中的 2D 卷积被膨胀为 3D 卷积。通过这种方式,U-Net 可以编码包含时间维度的 3D 特征。跨帧注意力模块。Stable Diffusion 具有自注意力模块,其中特征通过关注自身来增强。为了提高时间一致性,自注意力被修改为跨帧注意力。具体来说,每一帧的特征通过关注并参考第一帧和前一帧来增强。跨帧注意力在空间域和时间域上同时操作,从而提高合成帧的时间一致性。时间注意力模块。除了跨帧注意力外,还引入了时间注意力模块以进一步提高时间一致性。时间注意力在时间域上操作,并关注所有帧。
3.2. Coarse Visual Embeddings via Image Encoder
用于交叉注意力模块的嵌入。具体来说,CLIP 图像编码器被用来提取图像提示 I I I 的视觉特征 f V f_V fV。由于 CLIP 图像和文本嵌入之间存在差异, f V f_V fV 随后被送入 MLP 层 F ( ⋅ ) F(\cdot) F(⋅) 来将 f V f_V fV 映射到文本嵌入的空间中。图像提示的最终嵌入 f I f_I fI 的获取如下所示:
f V = C L I P I ( I ) , f I = F ( f V ) (1) f_V = CLIP_I(I), \quad f_I = F(f_V) \tag{1} fV=CLIPI(I),fI=F(fV)(1)
至于文本提示 T T T,我们将其送入 CLIP 文本编码器以提取文本嵌入 f T f_T fT:
f T = [ f T 0 , f T 1 , . . . , f T k , . . . ] (2) f_T = [f_T^0, f_T^1, ..., f_T^k, ...] \tag{2} fT=[fT0,fT1,...,fTk,...](2)
其中 f T k f_T^k fTk 是文本提示中的第 k k k 个词嵌入。
为了让扩散模型能够在生成视频时同时基于文本提示和图像提示进行条件控制,我们需要将这两个嵌入结合起来,即 f I f_I fI 和 f T f_T fT。具体做法是用 f I f_I fI 替换目标主体的词嵌入。数学上, f I f_I fI 和 f T f_T fT 融合以得到最终的文本条件 c T c_T cT,如下所示:
c T = [ f T 0 , f T 1 , . . . , f T k − 1 , f I , f T k + n , . . . ] (3) c_T = [f_T^0, f_T^1, ..., f_T^{k-1}, f_I, f_T^{k+n}, ...] \tag{3} cT=[fT0,fT1,...,fTk−1,fI,fTk+n,...](3)
其中 k k k 是目标主体在文本嵌入中的 token 索引, n n n 是目标主体的文本 token 的长度。例如,若给定一张蝴蝶犬的图像作为图像提示,而文本提示是 “Papillon dog celebrates birthday with gifts”,那么“papillon dog”的词嵌入将会被 f I f_I fI 替换,然后送入扩散模型的交叉注意力模块。
在粗粒度阶段的训练过程中,我们固定 CLIP 图像编码器的参数,仅训练 MLP 层。为了让扩散模型能够适应组合后的文本嵌入 c T c_T cT,我们还会微调交叉注意力模块中的 K 和 V 投影(线性层,用于将输入特征映射到对应的 keys 和 values)。
3.3. FineVisual Embeddings via Attention Injection
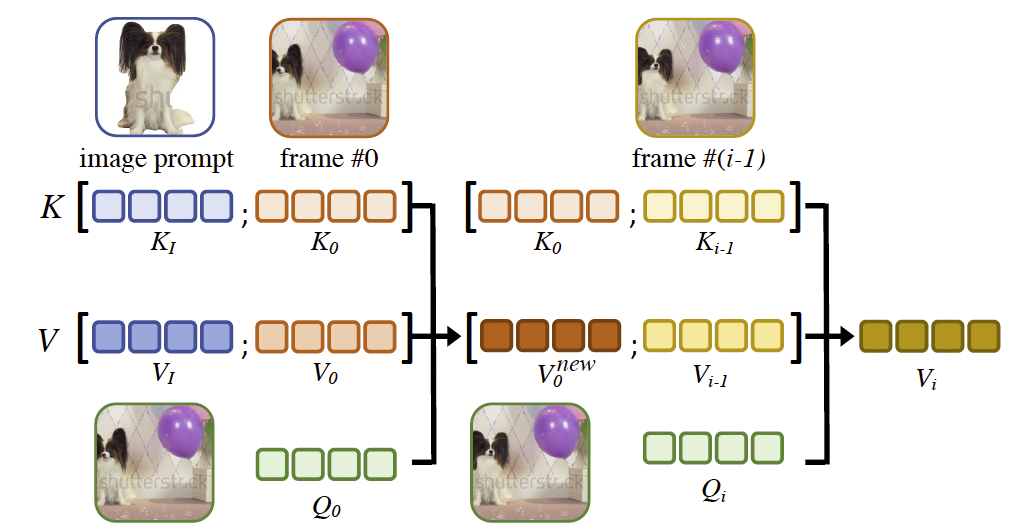
图4. 精细视觉嵌入优化。我们提出将图像提示的潜在表示(此处使用图像作示意)直接注入跨帧注意力模块。我们首先使用来自图像提示的键和值更新第一帧的值。然后,利用更新后的第一帧的值去更新其余帧。在跨帧注意力中注入图像提示有助于将图像提示的细粒度视觉特征传递到生成帧中。我们在不同尺度的跨注意力层中执行这种细化操作。
训练良好的图像编码器能够为图像提示嵌入粗粒度的视觉嵌入,因此生成的视频包含了图像提示中指定的主体。然而,图像编码器将图像提示投影为一个展平的高层次表示,导致其细节视觉信息的丢失。因此,图像提示中的某些细节视觉特征可能无法很好地保留。为了解决这个问题,更有效的方式是为模型提供具有空间分辨率的图像提示。为了进一步细化生成的细节,我们提出将图像提示注入到文本到视频模型的跨帧注意力中。通过将图像提示注入跨帧注意力,图像提示参与到合成帧的更新中,使模型能够直接从图像提示中借用一些视觉线索。由于文本到视频的扩散模型在潜空间中运行,我们首先将图像提示输入 Stable Diffusion 的 VAE,并得到其潜表示 x I x_I xI。此外,由于视频的采样过程从噪声图开始,中间时间步的潜变量中包含噪声。如果我们将图像提示的干净潜变量 x I x_I xI 直接附加到跨帧注意力中,就会出现域差异。
因此,我们遵循扩散的前向过程向 x I x_I xI添加相应的噪声:
x t I = α ˉ t x 0 I + 1 − α ˉ t ϵ , x_t^I = \sqrt{\bar{\alpha}_t}x_0^I + \sqrt{1-\bar{\alpha}_t}\epsilon, xtI=αˉtx0I+1−αˉtϵ,
其中 α ˉ \bar{\alpha} αˉ是由去噪调度决定的超参数,且 ϵ ∼ N ( 0 , I ) \epsilon \sim N(0, I) ϵ∼N(0,I)。
跨帧注意力用于提升生成帧的时间一致性。对于每一帧,键和值是由第一帧和前一帧的特征拼接得到的。在这里,我们引入图像提示作为每一帧的额外键和值。如图4所示,我们提出首先利用图像提示和该帧自身的键和值更新第一帧的值。从数学上,该操作可以表示为:
V 0 n e w = s o f t m a x ( Q 0 K T d ) ⋅ V , V_0^{new} = softmax\Big(\frac{Q_0K^T}{\sqrt{d}}\Big) \cdot V, V0new=softmax(dQ0KT)⋅V,
K = [ K I , K 0 ] , V = [ V I , V 0 ] , K = [K_I, K_0], \quad V = [V_I, V_0], K=[KI,K0],V=[VI,V0],
其中 K I K_I KI和 V I V_I VI是从图像提示中获得的键和值。第一帧的查询、键和值分别表示为 Q 0 , K 0 , V 0 Q_0, K_0, V_0 Q0,K0,V0。需要注意的是,我们为图像提示的潜在表示 x t I x_t^I xtI单独训练了K和V投影,因为图像提示通常有干净的背景,这与其他帧不同。新添加的K和V投影的参数由原始的K和V投影初始化。
然后,更新后的第一帧用于细化其余帧。在更新其余帧时,用于计算注意力图的键仍然是原始的键,而值则是更新后的值。更新过程表示为:
V i n e w = s o f t m a x ( Q i K T d ) ⋅ V , V_i^{new} = softmax\Big(\frac{Q_iK^T}{\sqrt{d}}\Big) \cdot V, Vinew=softmax(dQiKT)⋅V,
K = [ K 0 , K i − 1 ] , V = [ V 0 n e w , V i − 1 ] . K = [K_0, K_{i-1}], \quad V = [V_0^{new}, V_{i-1}]. K=[K0,Ki−1],V=[V0new,Vi−1].
总结来说,在注意力注入中,我们首先利用图像提示更新第一帧的值,然后再利用更新后的第一帧去更新其他帧。通过这种方式,图像提示中的视觉线索可以一致地传播到所有帧。
需要注意的是,扩散模型具有多个不同尺度的跨帧注意力层。为了在不同的跨帧注意力层中注入多尺度的视觉线索以实现更好的细节优化,我们将图像提示的潜在表示输入到与其分辨率对应的跨帧注意力层中,这些分辨率是从U-Net不同阶段获得的。
3.4. Coarse-to-Fine Training Strategy
图像提示的视觉细节在最终生成结果中通过两个阶段嵌入:首先是通过图像编码器得到的粗粒度视觉嵌入,其次是通过注意力注入得到的精细视觉嵌入。我们提出以由粗到细的方式训练这两个模块。换句话说,我们先训练粗粒度的图像编码器,并在交叉注意力中微调参数。在模型具备生成包含图像提示中指定主体的视频能力后,再训练注意力注入模块,将图像提示嵌入跨帧注意力层。正如在消融实验(第5.5节)中将展示的,如果这两个模块同时训练,精细的注意力注入模块会泄露强烈的视觉线索,而粗粒度编码器则会学习到无意义的表示。结果是在采样阶段,用于粗粒度视觉嵌入的图像编码器无法提供必要的粗粒度信息,从而导致精细注意力模块无法进一步优化细节。因此,有必要以由粗到细的方式训练VideoBooth。
4. VideoBooth Dataset
我们建立了VideoBooth数据集来支持利用图像提示进行视频生成的任务。我们从WebVid数据集 [5] 出发,这是一个著名的开源文本生成视频数据集。在WebVid数据集中,每个视频都配有一个文本提示。在本文中,我们研究的是从一个文本提示和一个图像提示生成视频片段的任务。因此,除了原始的文本提示之外,我们还需要为每个视频提供一个图像提示。我们提出使用Grounded-SAM (Grounded Segment Anything) [49, 57] 对视频的第一帧中的主体进行分割,分割得到的主体即作为图像提示。Grounded-SAM 接收词语提示作为输入,并为词语提示中指定的目标主体生成分割掩码。为了得到输入Grounded-SAM的词语提示,我们使用spaCy库从原始文本提示中解析名词短语,并将这些名词短语作为词语提示。在完成分割后,我们进行数据过滤以确保数据质量。我们根据目标物体与整个视频的比例,过滤掉过小或过大的物体(例如几乎与视频原尺寸相同的物体)。此外,由于我们专注于生成包含运动物体的视频片段,我们进一步过滤出包含运动物体的视频。我们用于过滤的关键词包括:dog、cat、bear、car、panda、tiger、horse、elephant 和 lion。在当前版本中,我们处理了WebVid数据集中的一个2.5M子集。经过数据过滤后,我们得到了48,724对视频数据用于训练。未来我们将处理完整的WebVid数据集,并将过滤后的数据纳入我们的VideoBooth数据集。
为了评估性能,我们还建立了一个测试基准。该测试基准由650对测试样本组成。对于每一对样本,我们提供一个图像提示和一个文本提示。测试样本选自WebVid-10M数据集的其余部分,与训练集没有重叠。