awk命令格式语法
awk options 'pattern {action}' file其中options 表示 常用采用命令
-F 要使用的分割符
-f 表示调用的awk的脚本文件
pattern:是用于匹配输入数据的模式。如果省略,则 awk 将对所有行进行操作。
{action}:是在匹配到模式的行上执行的动作。如果省略,则默认动作是打印整行。
file表示要操作的文件
-F后面要用的的分割符 建议用单引号括住
处理流程
1. BEGIN{} : 最开始执行
2. // : 正则
3. {} : 循环体
4. END{} : 最后执行
这里面最少有一个,最多有四个!
一般情况下我们可以省略BEGIN{} 和END{}
常见用法说明
awk -F':' '{print $1}' log.txt这条指令表示使用:分割 log.txt文件的每一行内容,然后打印第一列。
其中-F 定义你使用的是什么分割符,用单引号括住你要用的分割符 后面用单引号括住的部分表示你要执行的操作
print 是awk的内置函数,表示打印,后面紧跟后面的表示要打印的值
$1表示第一列的内容
log.txt表示要处理的文件
注意:'{print $1}' 这一部分其实省略了BENGH 和END,只有操作体,但是他不只执行一次,你的文档有几行满足条件就会执行几次,现在我们的指令,只是用:分割,只要满足有第一列就会打印。
例如:
假设我们的文件内容是这样的
aa:bb:cc:dd
ee:ff:gg:hh
kkkkkkkkkkk
mm:nn:oo:pp:qq
99;00:uu
那么执行上面的脚本指令就会打印如下结果:
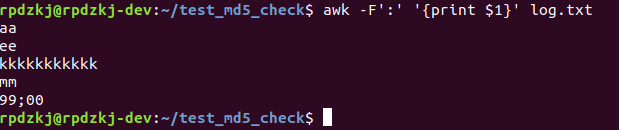
可以看到一冒号分割后,只打印了第一列 对于没有冒号分割符的那一行,就会把整行打印出来
那如果我不想把冒号打印出来呢?
有如下两种做法:
方法一:
awk -F':' '/:/{print $1}' log.txt
可以看到指令里面加了 /:/ 表示过滤只有冒号的行,换句话说,只要这一行没有冒号,我根本就不会进入打印流程。现在我们再看一下结果:
 可以看到只打印了4行,没有冒号哪一行明显被过滤掉了
可以看到只打印了4行,没有冒号哪一行明显被过滤掉了
方法二:
awk -F':' 'NF>1 {print $1}' log.txt
这条指令前面加了一个NF >1 ,其中NF是awk内置变量。表示每一行被冒号分割的字段数,假设一行里没有冒号,那么只能被分割成1段,那么NF就是1,如果这一行里有一个冒号,那么就会被分割成2段,NF就是2。执行这行指令和上面的结果一样
BEGIN 和END
awk -F':' '{print $1}' log.txt
awk -F':' 'BEGIN{}{print $1}END{}' log.txt这两行指令有什么区别吗?其实没有区别,第一条指令只是省略BEGIN 和END
BEGIN表示 执行循环命令前要执行的操作 END 表示执行循环指令后要要执行的操作。BEGIN和END 大括号里的指令执行一次。
例如:
awk -F':' 'BEGIN{print("start...")}{print $1}END{print("end....")}' log.txt执行执勤啊会打印一个start 执行之后会打印一个end

如何将awk的执行结果赋值给Shell脚本的变量
使用 $()的方式
例如:
result=$(awk -F':' 'NF>1 {print $1}' log.txt)
echo "$result"这样就会将 满足条件的数据打印出来。
那如果我只想取其中第二行呢:
方法一:
result=$(awk -F':' 'NF>1 {count++; if(count==2){print $1; exit}}' log.txt)
echo "$result"
这种方式awk执行的时候就只取了第二行
方法2:
mapfile -t arr < <(awk -F':' 'NF>1 {print $1}' log.txt)
echo "${arr[1]}" # Bash 数组索引从 0 开始,所以第2行是 arr[1]
这种方式是直接使用了Bash脚本的数组方式,然后取数组的索引
awk执行完成后 如何进行while遍历
while read line; do
echo "当前行是: $line"
done < <(awk -F':' 'NF>1 {print $1}' log.txt)
这几行脚本会将awk指令执行完后的每一行打印出来
<(...)= 过程替换,把命令输出变成“临时文件”<= 把文件或临时文件作为标准输入合起来
< <(...)= 把命令输出当作标准输入给另一个命令
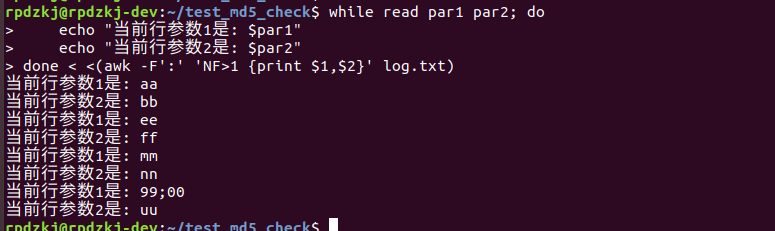
那如果我想将冒号分割的前两列都打印出来呢
while read par1 par2; do
echo "当前行参数1是: $par1"
echo "当前行参数2是: $par2"
done < <(awk -F':' 'NF>1 {print $1,$2}' log.txt)可以看到会把 前2列都遍历出来结果如下: