在技术领域,“Overlay”和“Overlap”常因拼写相似被混淆,但二者实则代表两种截然不同的优化逻辑:Overlay 是“主动构建分层结构”,通过资源复用与隔离提升效率;Overlap 是“让耗时环节时间交叉”,通过并行化压缩整体耗时。本文将拆解这两个概念的技术落地场景,带你看清如何用“叠加”与“重叠”双引擎优化系统性能。
一、先理清:Overlay 与 Overlap 的核心差异
在性能优化语境下,二者的本质区别体现在“操作逻辑”与“优化目标”上,我们用一张表明确边界:
| 维度 | Overlay(主动叠加) | Overlap(时间重叠) |
|---|---|---|
| 核心逻辑 | 构建“分层结构”,复用底层资源、隔离上层操作 | 让“等待环节”与“计算环节”时间交叉,减少空转 |
| 优化目标 | 降低资源占用(存储、网络、内存) | 缩短整体耗时(IO密集、多任务场景) |
| 典型场景 | 容器存储、分布式网络、图形渲染 | 批量API调用、数据处理流水线、任务调度 |
| 类比生活 | 抽屉分层收纳——复用抽屉空间,隔离不同物品 | 边烧水边切菜——利用等待时间完成其他操作 |
简单说:Overlay 是“空间上的优化”,通过分层复用资源;Overlap 是“时间上的优化”,通过并行重叠环节。二者虽逻辑不同,但常结合使用(如容器环境中用 Overlay 做存储分层,再用 Overlap 优化容器启动流程)。
二、Overlay:用“分层叠加”实现资源高效利用
Overlay 的核心价值是通过“底层复用+上层隔离”的分层结构,避免重复存储、简化网络通信、降低资源开销。最典型的落地场景是容器存储和分布式网络。
场景1:容器存储(OverlayFS)——分层复用镜像资源
容器镜像的“轻量性”全靠 Overlay 技术支撑。传统虚拟机需为每个实例分配完整磁盘,而 Docker/containerd 用 OverlayFS(叠加文件系统) 构建分层存储,实现资源复用。
核心原理:三层叠加的“魔法”
OverlayFS 由三个部分组成,共同形成容器的文件视图:
- Lowerdir(只读镜像层):容器镜像的底层(如基础镜像
alpine:latest),多个容器可共享同一层,无需重复存储; - Upperdir(读写容器层):容器运行时的修改层(如新建文件、修改配置),仅存储当前容器的变更,不影响底层镜像;
- Merged(联合视图):容器最终看到的“统一文件系统”,将只读层与读写层的内容叠加展示。
性能优势:写时复制(Copy-on-Write)
当容器修改只读层中的文件时,OverlayFS 会先将该文件“复制”到读写层,再修改副本——这一机制避免了对底层镜像的破坏,同时让多个容器共享99%的镜像资源。例如:
- 10个基于
alpine:latest(5MB)的容器,传统存储需50MB,而 OverlayFS 仅需5MB(基础镜像)+ 每个容器的修改量(通常<1MB),资源节省近90%。
实操验证:查看Docker的Overlay存储
Docker 默认使用 overlay2 驱动,可通过以下命令查看分层结构:
# 查看容器的Overlay层
docker inspect --format '{{.GraphDriver.Data}}' <容器ID>
# 输出示例(显示lowerdir、upperdir、merged路径)
# map[LowerDir:/var/lib/docker/overlay2/xxx/lowerdir upperdir:/var/lib/docker/overlay2/xxx/upperdir merged:/var/lib/docker/overlay2/xxx/merged]
场景2:分布式网络(Overlay Network)——叠加虚拟网络简化通信
在 Kubernetes 等分布式集群中,不同主机的容器要通信,需跨越物理网络的限制。Overlay 网络通过在物理网络上“叠加”一层虚拟网络,让跨主机容器像在同一子网内一样通信,大幅简化网络配置。
核心原理:隧道封装实现跨主机通信
Overlay 网络通过 VXLAN(虚拟扩展局域网) 技术封装数据包:
- 底层:现有物理网络(如企业内网192.168.0.0/24);
- 叠加层:为容器分配独立虚拟子网(如10.244.0.0/16);
- 通信过程:容器数据包先被封装成物理网络的数据包,传输到目标主机后再解封装,交付给目标容器。
性能优势:突破物理网络限制
无需修改物理网络配置,即可实现:
- 跨主机容器直接通信(如Pod1(10.244.1.2)直接访问Pod2(10.244.2.3));
- 网络隔离(不同命名空间的容器默认不互通);
- 动态扩缩容(新节点加入集群后自动接入Overlay网络)。
实操验证:查看K8s的Overlay网络
K8s 常用 Flannel 插件实现 Overlay 网络,可通过以下命令查看虚拟子网:
# 查看节点的Pod子网
kubectl get nodes -o custom-columns=NAME:.metadata.name,POD_CIDR:.spec.podCIDR
# 输出示例
# NAME POD_CIDR
# node-1 10.244.0.0/24
# node-2 10.244.1.0/24
三、Overlap:用“时间重叠”压缩整体耗时
Overlap 的核心价值是让“等待环节”(IO、网络、锁)与“计算环节”(数据处理、逻辑运算)在时间上交叉,避免资源空转。最典型的落地场景是批量IO任务和数据处理流水线。
场景1:批量API调用——让“请求等待”与“结果处理”重叠
痛点:批量调用远程API时,串行流程(请求1→处理1→请求2→处理2)中,“网络等待”会导致CPU闲置。例如3个API(每个请求200ms、处理100ms),串行总耗时900ms。
优化思路:发起请求后不等待结果,立即发起下一个请求;当第一个请求返回时,利用其他请求的“等待时间”处理结果——让“网络IO”与“CPU计算”完全重叠。
代码实现(Go):Goroutine 实现重叠优化
package main
import (
"fmt"
"time"
)
// fetch 模拟API请求(IO等待,200ms)
func fetch(url string) (string, error) {
time.Sleep(200 * time.Millisecond)
return fmt.Sprintf("[%s] 响应", url), nil
}
// process 模拟结果处理(CPU计算,100ms)
func process(data string) string {
time.Sleep(100 * time.Millisecond)
return "处理完成:" + data
}
func main() {
urls := []string{"url1", "url2", "url3"}
// 1. 串行执行(基准对比)
startSerial := time.Now()
for _, url := range urls {
data, _ := fetch(url)
_ = process(data)
}
fmt.Printf("串行耗时:%v\n", time.Since(startSerial)) // 约900ms
// 2. Overlap优化:请求与处理重叠
startOverlap := time.Now()
resultCh := make(chan string, len(urls)) // 缓冲通道避免阻塞
for _, url := range urls {
go func(u string) {
data, _ := fetch(u) // 网络请求(等待)
resultCh <- process(data) // 处理(与其他请求重叠)
}(url)
}
// 收集结果
for i := 0; i < len(urls); i++ {
<-resultCh
}
fmt.Printf("Overlap优化后耗时:%v\n", time.Since(startOverlap)) // 约200ms
}
效果:耗时从900ms降至200ms,性能提升4.5倍
场景2:数据处理流水线——让“数据加载”与“计算”重叠
痛点:处理大量数据时,串行流程(加载1→处理1→加载2→处理2)中,“磁盘IO等待”会浪费计算资源。例如3批数据(每批加载300ms、处理200ms),串行总耗时1500ms。
优化思路:处理当前批次数据时,异步预加载下一批数据——让“磁盘IO”与“CPU计算”重叠。
代码实现(Go):预加载实现重叠优化
package main
import (
"fmt"
"time"
)
// loadData 模拟数据加载(磁盘IO,300ms)
func loadData(batch int) ([]int, error) {
time.Sleep(300 * time.Millisecond)
return []int{batch*10, batch*10 + 1}, nil
}
// processBatch 模拟数据处理(CPU计算,200ms)
func processBatch(data []int) int {
time.Sleep(200 * time.Millisecond)
sum := 0
for _, v := range data {
sum += v
}
return sum
}
func main() {
batches := 3
// 1. 串行执行(基准对比)
startSerial := time.Now()
for i := 0; i < batches; i++ {
data, _ := loadData(i)
_ = processBatch(data)
}
fmt.Printf("串行耗时:%v\n", time.Since(startSerial)) // 约1500ms
// 2. Overlap优化:预加载下一批数据
startOverlap := time.Now()
dataCh := make(chan []int, 1)
// 预加载第一批数据
go func() {
data, _ := loadData(0)
dataCh <- data
}()
for i := 0; i < batches; i++ {
currentData := <-dataCh // 等待当前批次数据
// 预加载下一批(与当前处理重叠)
if i < batches-1 {
go func(next int) {
nextData, _ := loadData(next)
dataCh <- nextData
}(i + 1)
}
_ = processBatch(currentData) // 处理当前批次
}
fmt.Printf("Overlap优化后耗时:%v\n", time.Since(startOverlap)) // 约900ms
}
效果:耗时从1500ms降至900ms,性能提升66%
四、协同增效:Overlay 与 Overlap 结合的实战案例
在实际系统中,Overlay 与 Overlap 常结合使用,形成“空间+时间”的双重优化。以“K8s 容器启动流程”为例:
- Overlay 优化存储:容器镜像通过 OverlayFS 分层存储,节点只需拉取一次基础镜像,后续容器复用该层,减少镜像拉取时间和存储占用;
- Overlap 优化启动:
- 拉取镜像时,采用“边拉边解压”(拉取数据的IO等待与解压的CPU计算重叠);
- 启动容器时,预加载容器配置(配置加载的IO等待与镜像层挂载的操作重叠)。
通过二者结合,K8s 容器的启动时间可从秒级压缩至百毫秒级,同时节点存储占用降低70%以上。
五、总结:如何选择两种优化逻辑?
当你面临性能问题时,可按以下流程判断该用 Overlay 还是 Overlap:
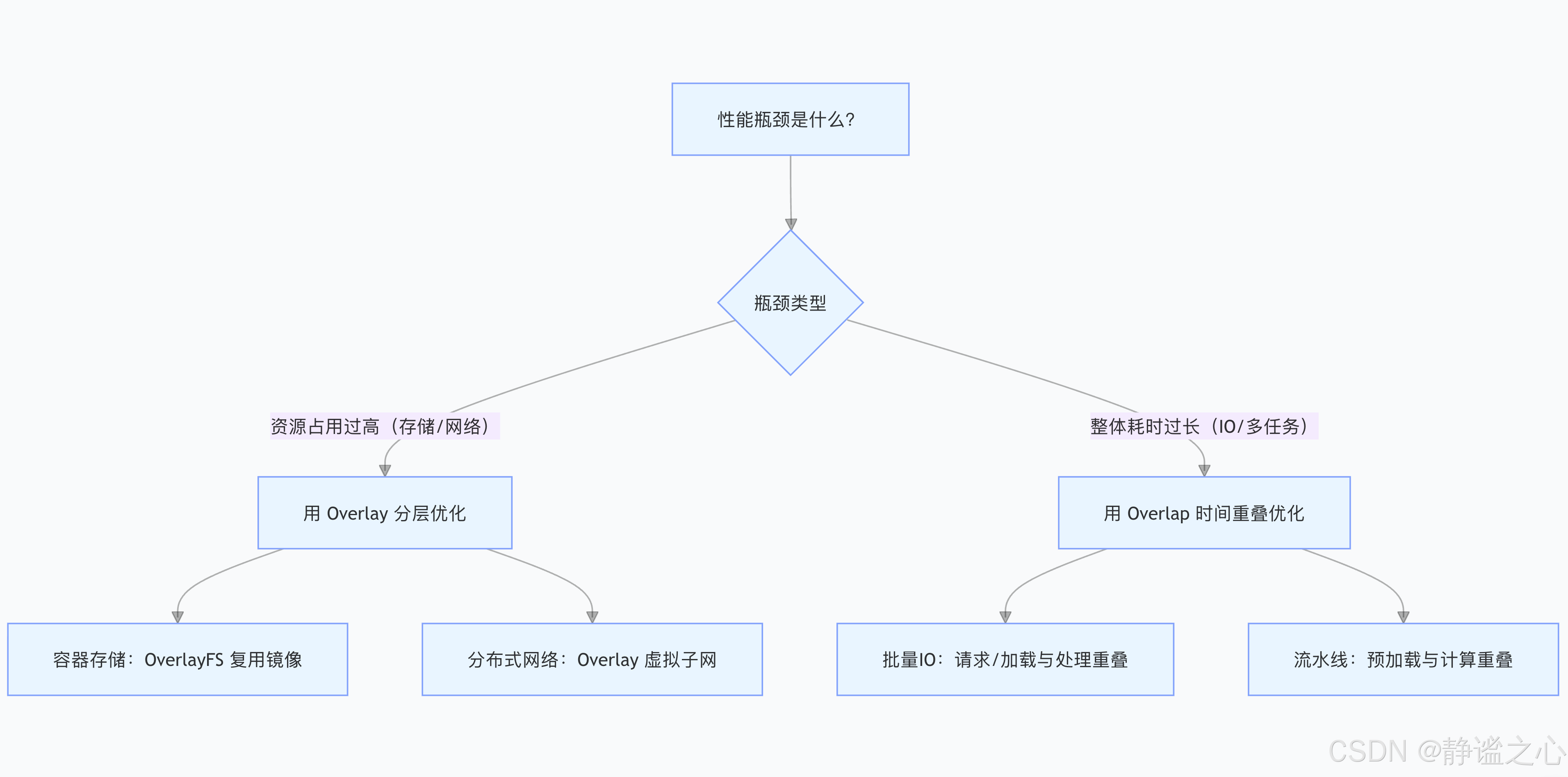
Overlay 是“给资源做减法”,通过分层复用降低开销;Overlap 是“给时间做减法”,通过并行重叠缩短耗时。理解二者的核心逻辑,才能在技术优化中精准发力,实现“资源更省、速度更快”的双重目标。