无需OCR,基于ColQwen2、Qwen2.5和Weaviate对PDF进行多模态RAG的解决方案
关键词:多模态RAG、ColQwen2、Qwen2.5-VL、Weaviate 向量数据库、PDF 检索问答、无需 OCR、ColBERT 多向量、跨模态检索、MaxSim 相似度、知识库构建、AI 文档处理、视觉语言模型、晚交互(Late Interaction)、向量索引、Python 教程、HuggingFace、Colab、MPS、GPU
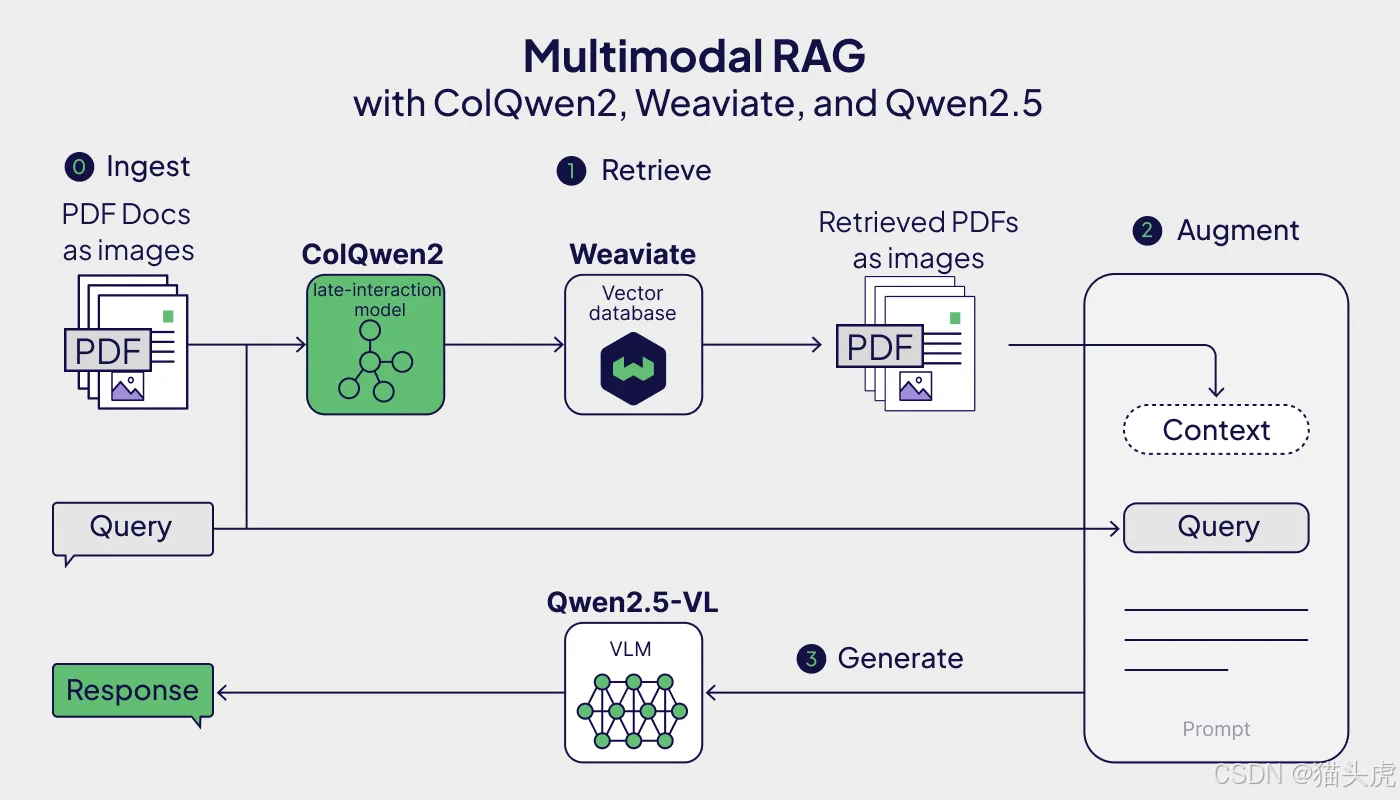
本文面向初学者,手把手搭建一个“无需 OCR 与分块”的 PDF 多模态 RAG 流水线:把 PDF 页面截图直接送入 ColQwen2 生成多向量(multi-vector)表征,写入 Weaviate 的 Multi-Vector 索引;查询时用 ColQwen2 将文本问题也编码到同一向量空间做近邻检索;最后把召回的页面截图与原问题一起交给 Qwen2.5-VL 生成答案。
教程核心参考自官方 recipe 笔记本(文末附链接),并在文中补充环境、代码注释、部署建议与排错清单。
文章目录
一、为什么要“无需 OCR + 无需分块”?
传统 PDF RAG 往往要:OCR → 版面分析 → 文本分块 → 嵌入 → 检索。
ColQwen2(晚交互 ColBERT 风格)直接对整页截图做多向量嵌入,把文本、表格、图形统一映射到同一空间,跳过 OCR/分块,从而:
- 更稳健:复杂版面(图表、公式、扫描件)也能检索;
- 更省心:流水线更短,工程复杂度更低;
- 效果好:多向量 + MaxSim 提升细粒度匹配能力。
一句话:同一模型,同一空间同时编码图片页与文本查询,实现跨模态检索问答。
二、项目总体流程(入门图概览)
摄取(Ingestion)
- 将 PDF 转为页面截图(PIL Images);
- 用 ColQwen2 把每页转为多向量;
- 写入 Weaviate Multi-Vector 索引(BYOV)。
查询(Retrieval)
- 用 ColQwen2 编码文本问题为多向量;
- 在 Weaviate 中做 MaxSim 近邻搜索,取回相关页面。
生成(Generation)
- 将召回页面截图 + 原问题交给 Qwen2.5-VL;
- 输出基于证据的多模态答案。
三、环境与前置条件
Python 3.10+(建议 3.10/3.11)
官方示例用了 3.13;初学者用 3.10/3.11 更容易装依赖,日后可再升级。至少 5–10 GB 显存/统一内存
- 可选:Google Colab(T4 免费)、Apple Silicon(M2/M3,使用 MPS)。
Weaviate ≥ 1.29.0(文中示例 1.32.x 也可)
选择其一:- Weaviate Cloud(WCD,省心)
- 本地 Docker(学习/演示足够)
- Embedded(快速试用)
四、快速开始(一键跑通骨架)
强烈建议先跑通“最小可行”骨架,再逐步加速与增强。
1)安装依赖
# 基础依赖
pip install -U colpali_engine "colpali-engine[interpretability]>=0.3.2,<0.4.0"
pip install -U weaviate-client qwen_vl_utils datasets transformers accelerate
pip install -U pillow matplotlib
如果在 Colab:记得
Runtime -> Change runtime type -> GPU。
如果是 Apple Silicon:PyTorch 需开启 MPS(文末排错节有提示)。
2)加载示例数据集(含 PDF 页面图像)
from datasets import load_dataset
dataset = load_dataset("weaviate/arXiv-AI-papers-multi-vector", split="train")
print(dataset.features)
print(len(dataset), dataset[0].keys())
数据集中含:
page_image(PIL 图像)、colqwen_embedding(也可自己现场算)。

3)加载 ColQwen2(多向量嵌入)
import torch, os
from transformers.utils.import_utils import is_flash_attn_2_available
from colpali_engine.models import ColQwen2, ColQwen2Processor
os.environ["TOKENIZERS_PARALLELISM"] = "false"
device = "cuda:0" if torch.cuda.is_available() else ("mps" if torch.backends.mps.is_available() else "cpu")
attn_impl = "flash_attention_2" if is_flash_attn_2_available() else "eager"
model_name = "vidore/colqwen2-v1.0"
model = ColQwen2.from_pretrained(model_name, torch_dtype=torch.bfloat16,
device_map=device, attn_implementation=attn_impl).eval()
processor = ColQwen2Processor.from_pretrained(model_name)
# 简易封装
class ColVision:
def __init__(self, model, processor): self.model, self.processor = model, processor
def img_embed(self, img):
batch = self.processor.process_images([img]).to(self.model.device)
with torch.no_grad(): embs = self.model(**batch) # [n_tokens, dim]
return embs[0].cpu().float().numpy().tolist()
def text_embed(self, text):
batch = self.processor.process_queries([text]).to(self.model.device)
with torch.no_grad(): embs = self.model(**batch)
return embs[0].cpu().float().numpy().tolist()
colvision = ColVision(model, processor)
4)连接 Weaviate 并创建 Multi-Vector 集合
import weaviate
import weaviate.classes.config as wc
from weaviate.classes.config import Configure
# 方案A:本地 Docker 已启动 8080 端口
# client = weaviate.connect_to_local()
# 方案B:Embedded(快速学习)
client = weaviate.connect_to_embedded()
print("Weaviate ready:", client.is_ready())
# 创建集合(BYOV + MultiVectors)
COLL = "PDFDocuments"
if client.collections.exists(COLL):
client.collections.delete(COLL)
collection = client.collections.create(
name=COLL,
properties=[
wc.Property(name="page_id", data_type=wc.DataType.INT),
wc.Property(name="paper_title", data_type=wc.DataType.TEXT),
wc.Property(name="paper_arxiv_id", data_type=wc.DataType.TEXT),
wc.Property(name="page_number", data_type=wc.DataType.INT),
],
vector_config=[
Configure.MultiVectors.self_provided(
name="colqwen",
vector_index_config=Configure.VectorIndex.hnsw(
multi_vector=Configure.VectorIndex.MultiVector.multi_vector()
)
)
]
)
5)摄取:把“页面截图 → 多向量”写入 Weaviate
page_images = {}
with collection.batch.dynamic() as batch:
for i, p in enumerate(dataset):
page_images[p["page_id"]] = p["page_image"]
multi_vec = colvision.img_embed(p["page_image"]) # 多向量(list[list[dim]])
batch.add_object(
properties={
"page_id": p["page_id"],
"paper_title": p["paper_title"],
"paper_arxiv_id": p["paper_arxiv_id"],
"page_number": p["page_number"],
},
vector={"colqwen": multi_vec}
)
if (i + 1) % 25 == 0:
print(f"Ingested {i+1}/{len(dataset)}")
batch.flush()
print("Total objects:", len(collection))
6)检索:文本问题 → 多向量 → MaxSim Top-K
from weaviate.classes.query import MetadataQuery
query_text = "How does DeepSeek-V2 compare against the LLaMA family of LLMs?"
qvec = colvision.text_embed(query_text)
resp = collection.query.near_vector(
near_vector=qvec,
target_vector="colqwen",
limit=1,
return_metadata=MetadataQuery(distance=True) # 返回 MaxSim 距离
)
hits = resp.objects
for i, o in enumerate(hits, 1):
p = o.properties
print(f"{i}) MaxSim: {-o.metadata.distance:.2f} | {p['paper_title']} p.{int(p['page_number'])}")
7)生成:把命中的“页面截图 + 问题”交给 Qwen2.5-VL
import base64
from io import BytesIO
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# 加载 VLM(占用较大内存,建议单卡/Colab 先 limit=1)
vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct",
torch_dtype=torch.bfloat16,
device_map=device,
attn_implementation=attn_impl
)
# 画质范围可按需调
processor_vl = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct",
min_pixels=256*28*28, max_pixels=1280*28*28
)
# 取回页面图片
img = page_images[hits[0].properties["page_id"]]
# 打包为 chat 输入
buf = BytesIO(); img.save(buf, format="jpeg")
img_b64 = base64.b64encode(buf.getvalue()).decode("utf-8")
messages = [{
"role": "user",
"content": [{"type":"image","image":f"data:image;base64,{img_b64}"},
{"type":"text","text":query_text}]
}]
text = processor_vl.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor_vl(text=[text], images=image_inputs, videos=video_inputs,
padding=True, return_tensors="pt").to(device)
out = vlm.generate(**inputs, max_new_tokens=128)
ans = processor_vl.batch_decode(out[:, inputs.input_ids.shape[1]:],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]
print("Answer:", ans)
至此,一个无需 OCR的 PDF 多模态 RAG 最小闭环完成 ✅。
五、Mermaid 流程图
六、关键概念一图读懂
- ColQwen2:视觉语言模型,**晚交互(ColBERT)**多向量;同一模型编码图片与文本。
- Multi-Vector + MaxSim:以token/patch 级向量交互匹配,保留细粒度对齐。
- Weaviate Multi-Vector:原生支持多向量 BYOV + HNSW,加速近邻检索。
- Qwen2.5-VL:将召回页面(图像)与问题(文本)一起喂给模型,基于证据作答。
七、扩展与优化建议
批量/并发摄取:
- 控制
batch.dynamic()的批量大小; - 对页面分辨率/patch 数做折中(更小更快,略降召回上限)。
- 控制
Top-K 与重排序:
- 先用 Multi-Vector 粗排(Top-K=3/5),再用 Qwen2.5-VL 对候选进行重排序/评分。
混合检索:
- 同时维护文本嵌入(如 BGE/ColBERT 文本端)与图像多向量;
- 按查询意图动态融合。
成本与部署:
- Weaviate Cloud(省心)或 Docker(可控);
- 模型可用
bitsandbytes量化、max_pixels控制分辨率。
八、常见报错与排查(新人必看)
显存不足(OOM)
- 降低
max_pixels;检索limit=1起步;必要时 CPU/MPS 先验证流程。
- 降低
MPS 慢/不稳定(Apple Silicon)
- 使用
torch.bfloat16;某些算子仍会回退到 CPU,耐心为要。
- 使用
Weaviate 版本不匹配
- 确保 ≥1.29.0;若是 Docker,拉取对应 tag;若嵌入式,升级 weaviate-client。
网络下载模型慢
- 配置国内镜像或提前手动缓存 HuggingFace 权重。
九、知识点表格总结
| 知识点 | 要点 | 原理/优势 | 实践建议 |
|---|---|---|---|
| 无需 OCR/分块 | 直接用页面截图做检索 | 避免版面/表格/公式丢失 | 首次先小分辨率验证流程 |
| ColQwen2 多向量 | 晚交互、ColBERT 风格 | token/patch 级匹配更细粒度 | 同一模型编码图像与文本 |
| Weaviate Multi-Vector | 原生多向量 + HNSW | 支持 BYOV,查询快 | 建议单独 collection 管理 |
| MaxSim 相似度 | 多向量间最大相似 | 强化局部对齐 | 与 Top-K/重排序配合 |
| Qwen2.5-VL 生成 | 图像+文本共同上下文 | 基于证据作答更可靠 | 控制 max_new_tokens 成本 |
| 端到端 RAG | 摄取→检索→生成 | 管道短、工程简 | 先跑通最小闭环 |
十、完整可复现骨架(拷贝即用)
下面代码把摄取 → 检索 → 生成串起来,方便你一次性跑通(与上文分步一致,只是整合)。
# 0) 安装依赖(参考前文)
# 1) 加载数据集
from datasets import load_dataset
dataset = load_dataset("weaviate/arXiv-AI-papers-multi-vector", split="train")
# 2) ColQwen2
import torch, os, base64
from io import BytesIO
from transformers.utils.import_utils import is_flash_attn_2_available
from colpali_engine.models import ColQwen2, ColQwen2Processor
os.environ["TOKENIZERS_PARALLELISM"] = "false"
device = "cuda:0" if torch.cuda.is_available() else ("mps" if torch.backends.mps.is_available() else "cpu")
attn_impl = "flash_attention_2" if is_flash_attn_2_available() else "eager"
model_name = "vidore/colqwen2-v1.0"
model = ColQwen2.from_pretrained(model_name, torch_dtype=torch.bfloat16,
device_map=device, attn_implementation=attn_impl).eval()
processor = ColQwen2Processor.from_pretrained(model_name)
class ColVision:
def __init__(self, model, processor): self.model, self.processor = model, processor
def img_embed(self, img):
batch = self.processor.process_images([img]).to(self.model.device)
with torch.no_grad(): embs = self.model(**batch)
return embs[0].cpu().float().numpy().tolist()
def text_embed(self, text):
batch = self.processor.process_queries([text]).to(self.model.device)
with torch.no_grad(): embs = self.model(**batch)
return embs[0].cpu().float().numpy().tolist()
colvision = ColVision(model, processor)
# 3) Weaviate(嵌入式或本地)
import weaviate
import weaviate.classes.config as wc
from weaviate.classes.config import Configure
from weaviate.classes.query import MetadataQuery
client = weaviate.connect_to_embedded()
COLL = "PDFDocuments"
if client.collections.exists(COLL):
client.collections.delete(COLL)
collection = client.collections.create(
name=COLL,
properties=[
wc.Property(name="page_id", data_type=wc.DataType.INT),
wc.Property(name="paper_title", data_type=wc.DataType.TEXT),
wc.Property(name="paper_arxiv_id", data_type=wc.DataType.TEXT),
wc.Property(name="page_number", data_type=wc.DataType.INT),
],
vector_config=[
Configure.MultiVectors.self_provided(
name="colqwen",
vector_index_config=Configure.VectorIndex.hnsw(
multi_vector=Configure.VectorIndex.MultiVector.multi_vector()
)
)
]
)
# 4) 摄取
page_images = {}
with collection.batch.dynamic() as batch:
for i, p in enumerate(dataset):
page_images[p["page_id"]] = p["page_image"]
batch.add_object(
properties={
"page_id": p["page_id"],
"paper_title": p["paper_title"],
"paper_arxiv_id": p["paper_arxiv_id"],
"page_number": p["page_number"],
},
vector={"colqwen": colvision.img_embed(p["page_image"])}
)
if (i + 1) % 50 == 0: print(f"Ingested {i+1}/{len(dataset)}")
batch.flush()
# 5) 查询
query_text = "How does DeepSeek-V2 compare against the LLaMA family of LLMs?"
qvec = colvision.text_embed(query_text)
resp = collection.query.near_vector(
near_vector=qvec, target_vector="colqwen", limit=1,
return_metadata=MetadataQuery(distance=True)
)
hit = resp.objects[0]
print("Hit:", hit.properties["paper_title"], "p.", int(hit.properties["page_number"]))
# 6) 生成
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct", torch_dtype=torch.bfloat16,
device_map=device, attn_implementation=attn_impl
)
processor_vl = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=256*28*28, max_pixels=1280*28*28
)
img = page_images[hit.properties["page_id"]]
buf = BytesIO(); img.save(buf, format="jpeg")
img_b64 = base64.b64encode(buf.getvalue()).decode("utf-8")
messages = [{"role":"user","content":[{"type":"image","image":f"data:image;base64,{img_b64}"},
{"type":"text","text":query_text}]}]
text = processor_vl.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor_vl(text=[text], images=image_inputs, videos=video_inputs,
padding=True, return_tensors="pt").to(device)
gen = vlm.generate(**inputs, max_new_tokens=128)
answer = processor_vl.batch_decode(gen[:, inputs.input_ids.shape[1]:],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]
print("Answer:", answer)
十一、FAQ
- Q:能否换 ColPali?
A:可以,ColPali 与 ColQwen2 都属于“ColVision”家族,只是编码器不同。替换加载与 Processor 即可。 - Q:需要把所有页都喂给 Qwen2.5-VL 吗?
A:不建议。先用 Multi-Vector 粗排 Top-K(1~3),再做多轮生成/重排序,控制成本。 - Q:如何支持中文 PDF 或扫描件?
A:本方案天然对图像友好,扫描件常见噪声也能一定程度处理;若需要文字级精确抽取(复制/高亮),再结合 OCR 做“加分项”。
参考与致谢
- 原始官方教程(强烈推荐):
“Multimodal RAG over PDFs using ColQwen2, Qwen2.5, and Weaviate”
GitHub(Jupyter Notebook):
https://github.com/weaviate/recipes/blob/main/weaviate-features/multi-vector/multi-vector-colipali-rag.ipynb
到这里,你已经掌握了无需 OCR 的多模态 RAG基本套路:ColQwen2 把图片页/文本统一到一个多向量空间 → Weaviate 做 Multi-Vector 近邻搜索 → Qwen2.5-VL 基于证据生成。拿去替换你现有的 PDF 问答、图表检索或扫描件归档工作流,立刻上手,立竿见影!