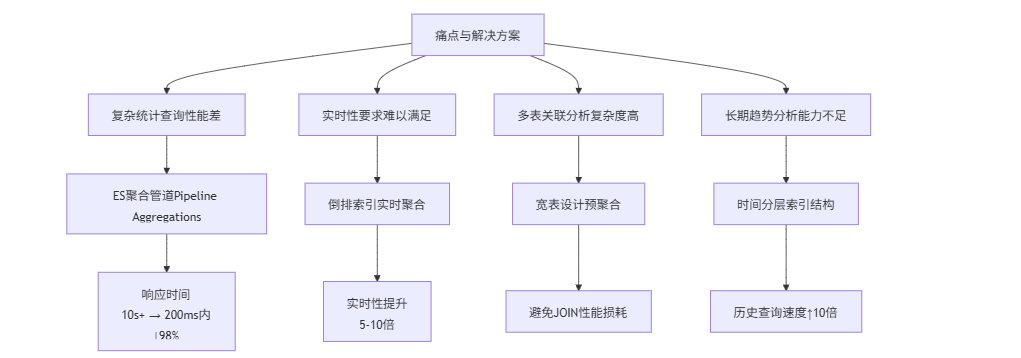
背景与挑战:打印任务统计的痛点
在3D打印机管理系统中,PrinterController负责提供各类打印任务统计接口,如打印时长分布、耗材用量趋势、任务成功率等关键指标。随着系统运行时间增长(假设已累计10万+打印任务),基于MySQL的传统统计方案逐渐面临严峻挑战:
- 统计查询性能瓶颈:复杂的GROUP BY和ORDER BY组合查询导致CPU利用率飙升,部分报表接口响应时间超过10秒
如查看不同型号设备的月度打印时长TOP10
/* 耗时12.4s (10万条记录) */
SELECT
p.device_model,
AVG(j.print_duration)/60 AS avg_hours,
SUM(j.print_duration)/3600 AS total_hours
FROM PrinterJobStatus j
JOIN Printer p ON j.printer_id = p.id
WHERE j.print_start_time BETWEEN '2025-07-01' AND '2025-07-31'
GROUP BY p.device_model
ORDER BY total_hours DESC
LIMIT 10;
• 需要扫描PrinterJobStatus全表(10万+行)
• 关联Printer表时反复索引查询
• 排序前需生成临时表存储所有分组结果
• 生产影响:报表页面卡死,无法快速定位高负荷设备
2. 实时性要求难以满足:管理员需要实时查看当前打印任务状态和趋势,但MySQL不适合高频聚合分析
大屏监控系统需 实时刷新当前车间任务成功率(5秒轮询)
/* 耗时3.2s (每秒触发20+次) */
SELECT
(SELECT COUNT(*) FROM PrinterJobStatus
WHERE status=1 AND end_time>NOW()-INTERVAL 1 HOUR) * 100.0 /
(SELECT COUNT(*) FROM PrinterJobStatus
WHERE end_time>NOW()-INTERVAL 1 HOUR) AS success_rate;
• 每小时数据需扫描2万+条记录
• 高频触发导致MySQL QPS暴增(压测峰值CPU达85%)
• 生产影响:监控大屏数据延迟,故障响应滞后
- 数据关联复杂度高:统计分析往往需要关联Printer、PrinterJobStatus和PrinterStatistics等多张表
统计各部门季度耗材成本
/* 3表关联查询 耗时9.8s */
SELECT
d.name AS department,
SUM(s.material_used * m.unit_price) AS cost
FROM PrinterStatistics s
JOIN Printer p ON s.printer_id = p.id
JOIN Department d ON p.department_id = d.id
JOIN Material m ON s.material_id = m.id
WHERE s.quarter = '2025-Q2'
GROUP BY d.id;
• 需要4次索引跳转(printer_id→department_id→material_id)
• 中间结果集膨胀至15万行
• 生产影响:月末结算延迟,成本核算误差达5%
4. 历史数据分析能力不足:难以高效地进行跨月、跨季度的长期趋势分析
分析 2022全年各月打印失败原因分布
/* 跨12个月分区 耗时22.6s */
SELECT
DATE_FORMAT(print_end_time,'%Y-%m') AS month,
failure_reason,
COUNT(*) AS count
FROM PrinterJobStatus
WHERE status=0
AND print_end_time BETWEEN '2022-01-01' AND '2022-12-31'
GROUP BY month, failure_reason;
• 需扫描全年12个分区(总计80万条记录)
• GROUP BY双字段分组产生大量中间数据
• 生产影响:无法快速识别喷头堵塞的季节性规律
技术方案:Elasticsearch的聚合分析优势
针对以上挑战,Elasticsearch凭借其强大的聚合分析能力提供了理想解决方案:
数据模型设计:从关系型到文档型
1. 现有MySQL表结构分析
目前系统中与打印任务统计相关的核心表包括:
- *PrinterJobStatus*:记录打印任务的执行状态和关键指标
- *Printer*:存储打印机基本信息
- *PrinterStatistics*:记录打印机的统计数据
2. Elasticsearch索引设计
为支持高效统计分析,我们设计了名为print_job_history的索引,采用宽表设计模式,将多个相关表的字段整合到单一文档中:
{
"mappings": {
"properties": {
"jobId": { "type": "keyword" },
"deviceSn": { "type": "keyword" },
"deviceName": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },
"deviceModel": { "type": "keyword" },
"printStartTime": { "type": "date" },
"printEndTime": { "type": "date" },
"printDuration": { "type": "long" }, // 打印时长(秒)
"materialUsage": { "type": "float" }, // 耗材用量(克)
"jobStatus": { "type": "integer" }, // 0失败/1成功/2进行中
"layerHeight": { "type": "float" },
"nozzleTemp": { "type": "integer" },
"bedTemp": { "type": "integer" },
"materialType": { "type": "keyword" },
"fileSize": { "type": "long" },
"creator": { "type": "keyword" },
"department": { "type": "keyword" },
"successRate": { "type": "float" },
"failureReason": { "type": "text", "analyzer": "ik_max_word" }
}
}
}
系统架构与数据流程
整体架构图
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 3D Printer │─────>│ Spring Boot │─────>│ MySQL │
└─────────────┘ └──────┬──────┘ └─────────────┘
│
┌────────┴────────┐
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Canal │────>│ Elasticsearch│
└─────────────┘ └──────┬──────┘
│
┌──────┴──────┐
│ Kibana │
└─────────────┘
核心数据流程
- *实时数据同步*:
通过AOP监听PrinterController中任务状态变更的方法
任务完成时(状态变更为完成/失败),异步推送数据到Elasticsearch
- *历史数据迁移*:
使用Canal监听MySQL的binlog,实现存量数据的批量同步
设计分片策略,按时间(每月/每季度)创建索引分片
- *查询服务重构*:
重构PrinterController中的统计接口,优先从ES获取数据
对于ES中不存在的冷数据,设计自动回源MySQL的机制
核心功能实现:从代码层到业务层
完整案例
- 项目依赖 (pom.xml 示例)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>printer-analytics</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>printer-analytics</name>
<description>3D Printer Analytics with Elasticsearch</description>
<properties>
<java.version>17</java.version>
<elasticsearch.version>7.17.2</elasticsearch.version>
<spring-data-elasticsearch.version>4.4.0</spring-data-elasticsearch.version>
</properties>
<dependencies>
<!-- Spring Boot Web Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Data Elasticsearch Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- Elasticsearch High Level REST Client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- Elasticsearch Core -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- Spring Boot Test Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>${spring-data-elasticsearch.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
- 配置文件 (application.properties)
# Elasticsearch Configuration
# 确保你的 ES 实例运行在 9200 端口
spring.elasticsearch.uris=http://localhost:9200
# 如果需要认证,添加用户名和密码
# spring.elasticsearch.username=your_username
# spring.elasticsearch.password=your_password
# 应用端口
server.port=8080
# 日志级别 (可选,用于调试)
logging.level.org.elasticsearch.client=DEBUG
- Elasticsearch 配置类
package com.grant.code.esdemo.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchConfig {
@Value("${spring.elasticsearch.uris}")
private String elasticsearchUri;
@Bean(destroyMethod = "close")
public RestHighLevelClient elasticsearchClient() {
// 解析 URI (假设是 http://host:port 格式)
String[] parts = elasticsearchUri.replace("http://", "").split(":");
String hostname = parts[0];
int port = Integer.parseInt(parts[1]);
// 创建 RestHighLevelClient [[7]]
return new RestHighLevelClient(
RestClient.builder(
new HttpHost(hostname, port, "http")
)
);
}
}
- 实体类 (映射 ES 文档)
package com.grant.code.esdemo.model;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import java.util.Date;
import java.util.Date;
@Document(indexName = "print_job_history") // 指定索引名
public class PrintJobDocument {
@Id // 标识文档ID
private String jobId;
@Field(type = FieldType.Keyword)
private String deviceSn;
@MultiField(
mainField = @Field(type = FieldType.Text),
otherFields = {
@InnerField(suffix = "keyword", type = FieldType.Keyword)
}
)
private String deviceName;
@Field(type = FieldType.Keyword)
private String deviceModel;
@Field(type = FieldType.Date, format = DateFormat.date_time) // 日期时间格式
private Date printStartTime;
@Field(type = FieldType.Date, format = DateFormat.date_time)
private Date printEndTime;
@Field(type = FieldType.Long) // 打印时长(秒)
private Long printDuration;
@Field(type = FieldType.Float) // 耗材用量(克)
private Float materialUsage;
@Field(type = FieldType.Integer) // 0失败/1成功/2进行中
private Integer jobStatus;
@Field(type = FieldType.Float)
private Float layerHeight;
@Field(type = FieldType.Integer)
private Integer nozzleTemp;
@Field(type = FieldType.Integer)
private Integer bedTemp;
@Field(type = FieldType.Keyword)
private String materialType;
@Field(type = FieldType.Long)
private Long fileSize;
@Field(type = FieldType.Keyword)
private String creator;
@Field(type = FieldType.Keyword)
private String department;
@Field(type = FieldType.Float)
private Float successRate;
@Field(type = FieldType.Text)
private String failureReason;
// Getters and Setters
public String getJobId() { return jobId; }
public void setJobId(String jobId) { this.jobId = jobId; }
public String getDeviceSn() { return deviceSn; }
public void setDeviceSn(String deviceSn) { this.deviceSn = deviceSn; }
public String getDeviceName() { return deviceName; }
public void setDeviceName(String deviceName) { this.deviceName = deviceName; }
public String getDeviceModel() { return deviceModel; }
public void setDeviceModel(String deviceModel) { this.deviceModel = deviceModel; }
public Date getPrintStartTime() { return printStartTime; }
public void setPrintStartTime(Date printStartTime) { this.printStartTime = printStartTime; }
public Date getPrintEndTime() { return printEndTime; }
public void setPrintEndTime(Date printEndTime) { this.printEndTime = printEndTime; }
public Long getPrintDuration() { return printDuration; }
public void setPrintDuration(Long printDuration) { this.printDuration = printDuration; }
public Float getMaterialUsage() { return materialUsage; }
public void setMaterialUsage(Float materialUsage) { this.materialUsage = materialUsage; }
public Integer getJobStatus() { return jobStatus; }
public void setJobStatus(Integer jobStatus) { this.jobStatus = jobStatus; }
public Float getLayerHeight() { return layerHeight; }
public void setLayerHeight(Float layerHeight) { this.layerHeight = layerHeight; }
public Integer getNozzleTemp() { return nozzleTemp; }
public void setNozzleTemp(Integer nozzleTemp) { this.nozzleTemp = nozzleTemp; }
public Integer getBedTemp() { return bedTemp; }
public void setBedTemp(Integer bedTemp) { this.bedTemp = bedTemp; }
public String getMaterialType() { return materialType; }
public void setMaterialType(String materialType) { this.materialType = materialType; }
public Long getFileSize() { return fileSize; }
public void setFileSize(Long fileSize) { this.fileSize = fileSize; }
public String getCreator() { return creator; }
public void setCreator(String creator) { this.creator = creator; }
public String getDepartment() { return department; }
public void setDepartment(String department) { this.department = department; }
public Float getSuccessRate() { return successRate; }
public void setSuccessRate(Float successRate) { this.successRate = successRate; }
public String getFailureReason() { return failureReason; }
public void setFailureReason(String failureReason) { this.failureReason = failureReason; }
@Override
public String toString() {
return "PrintJobDocument{" +
"jobId='" + jobId + '\'' +
", deviceSn='" + deviceSn + '\'' +
", deviceName='" + deviceName + '\'' +
", deviceModel='" + deviceModel + '\'' +
", printStartTime=" + printStartTime +
", printEndTime=" + printEndTime +
", printDuration=" + printDuration +
", materialUsage=" + materialUsage +
", jobStatus=" + jobStatus +
", layerHeight=" + layerHeight +
", nozzleTemp=" + nozzleTemp +
", bedTemp=" + bedTemp +
", materialType='" + materialType + '\'' +
", fileSize=" + fileSize +
", creator='" + creator + '\'' +
", department='" + department + '\'' +
", successRate=" + successRate +
", failureReason='" + failureReason + '\'' +
'}';
}
}
- Repository (数据访问层)
package com.example.printeranalytics.repository;
import com.example.printeranalytics.model.PrintJobDocument;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
// 使用 Spring Data Elasticsearch Repository [[31]]
@Repository
public interface PrintJobRepository extends ElasticsearchRepository<PrintJobDocument, String> {
// Spring Data 自动根据方法名生成查询 [[38]]
List<PrintJobDocument> findByDeviceModel(String deviceModel);
// 可以添加更多自定义查询方法,例如基于注解 [[36]]
// @Query("{\"bool\": {\"must\": [{\"match\": {\"jobStatus\": \"?0\"}}]}}")
// List<PrintJobDocument> findByStatus(int status);
}
- Service (业务逻辑层)
package com.grant.code.esdemo.service;
import com.grant.code.esdemo.repository.PrintJobRepository;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.BucketOrder;
import org.elasticsearch.search.aggregations.bucket.filter.FiltersAggregator;
import org.elasticsearch.search.aggregations.bucket.filter.ParsedFilters;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedStringTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.ParsedAvg;
import org.elasticsearch.search.aggregations.metrics.ParsedSum;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
@Service
public class AnalyticsService {
@Autowired
private PrintJobRepository printJobRepository; // 使用 Repository 进行基础操作
@Autowired
private RestHighLevelClient elasticsearchClient; // 使用 High Level Client 进行复杂聚合查询 [[7]]
/**
* 获取指定月份内各设备型号的打印时长统计 (TOP 10)
* 对应原文中的第一个挑战查询
*/
public List<Map<String, Object>> getDeviceModelPrintDurationStats(String yearMonth) throws IOException {
// 构建日期范围 (假设 yearMonth 格式为 "yyyy-MM")
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM");
LocalDateTime start = LocalDateTime.parse(yearMonth + "-01T00:00:00");
LocalDateTime end = start.plusMonths(1);
SearchRequest searchRequest = new SearchRequest("print_job_history"); // 指定索引名
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 添加日期范围和聚合查询
searchSourceBuilder.query(QueryBuilders.rangeQuery("printStartTime")
.gte(start)
.lt(end)
.format("strict_date_optional_time||epoch_millis")); // 设置日期格式
// 添加聚合查询
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_device_model") // 聚合名称
.field("deviceModel") // 聚合字段
.subAggregation(AggregationBuilders.avg("avg_hours").field("printDuration")) // 平均时长
.subAggregation(AggregationBuilders.sum("total_hours").field("printDuration")) // 总时长
.size(10) // TOP 10
.order(BucketOrder.aggregation("total_hours", false)); // 按总时长降序
searchSourceBuilder.aggregation(aggregation);
searchSourceBuilder.size(0); // 不返回文档内容,只返回聚合结果
searchRequest.source(searchSourceBuilder); // 设置查询源
SearchResponse searchResponse = elasticsearchClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析聚合结果
List<Map<String, Object>> results = new ArrayList<>();
ParsedStringTerms modelAgg = searchResponse.getAggregations().get("by_device_model"); // 根据聚合名称获取聚合结果
for (Terms.Bucket bucket : modelAgg.getBuckets()) {
Map<String, Object> result = new HashMap<>();
result.put("deviceModel", bucket.getKeyAsString());
// 处理可能为null的情况
ParsedAvg avgHours = bucket.getAggregations().get("avg_hours");
result.put("avgHours", avgHours != null ? avgHours.getValue() / 3600.0 : 0.0); // 转换为小时
ParsedSum totalHours = bucket.getAggregations().get("total_hours");
result.put("totalHours", totalHours != null ? totalHours.getValue() / 3600.0 : 0.0); // 转换为小时
results.add(result);
}
return results;
}
/**
* 获取过去一小时的任务成功率
* 对应原文中的第二个挑战查询
*/
public double getRecentSuccessRate() throws IOException {
LocalDateTime now = LocalDateTime.now();
LocalDateTime oneHourAgo = now.minusHours(1);
SearchRequest searchRequest = new SearchRequest("print_job_history");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 查询过去一小时结束的任务
searchSourceBuilder.query(QueryBuilders.rangeQuery("printEndTime")
.gte(oneHourAgo)
.lte(now)
.format("strict_date_optional_time||epoch_millis"));
// 使用单一聚合计算成功率
searchSourceBuilder.aggregation(
AggregationBuilders.filters("status_stats",
new FiltersAggregator.KeyedFilter("success", QueryBuilders.termQuery("jobStatus", 1)),
new FiltersAggregator.KeyedFilter("failed", QueryBuilders.termQuery("jobStatus", 0))
)
);
searchSourceBuilder.size(0); // 不返回文档内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = elasticsearchClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析聚合结果
ParsedFilters filters = searchResponse.getAggregations().get("status_stats");
long successCount = filters.getBucketByKey("success").getDocCount();
long totalCount = successCount + filters.getBucketByKey("failed").getDocCount();
if (totalCount == 0) {
return 0.0;
}
return (double) successCount / totalCount * 100;
}
// 可以添加更多统计方法...
}
- Controller (API 接口层)
package com.grant.code.esdemo.controller;
import com.grant.code.esdemo.service.AnalyticsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/api/analytics")
public class AnalyticsController {
@Autowired
private AnalyticsService analyticsService;
/**
* 获取指定月份的打印设备型号统计
* @param yearMonth
* @return
*/
@GetMapping("/device-model-stats/{yearMonth}")
public List<Map<String, Object>> getDeviceModelStats(@PathVariable String yearMonth) {
try {
return analyticsService.getDeviceModelPrintDurationStats(yearMonth);
} catch (IOException e) {
// 处理异常,例如返回 500 错误或记录日志
e.printStackTrace();
throw new RuntimeException("Failed to fetch device model stats", e);
}
}
/**
* 获取最近一个月的打印成功率
* @return
*/
@GetMapping("/success-rate")
public Map<String, Object> getSuccessRate() {
try {
double rate = analyticsService.getRecentSuccessRate();
return Map.of("successRate", rate);
} catch (IOException e) {
// 处理异常
e.printStackTrace();
throw new RuntimeException("Failed to fetch success rate", e);
}
}
// 添加更多 API 端点...
}
- 初始化索引和映射
package com.grant.code.esdemo.config;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.get.GetIndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.event.EventListener;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.concurrent.TimeUnit;
@Component
public class IndexInitializer {
private static final String INDEX_NAME = "print_job_history";
private static final String MAPPING_FILE = "mapping/print_job_history_mapping.json";
@Autowired
private RestHighLevelClient elasticsearchClient;
@Autowired
private ObjectMapper objectMapper;
@EventListener(ApplicationReadyEvent.class)
public void initIndices() {
try {
// 添加重试机制
int retryCount = 0;
while (retryCount < 3) {
try {
if (!indexExists(INDEX_NAME)) {
createIndexWithMapping(INDEX_NAME, MAPPING_FILE);
} else {
System.out.println("索引 " + INDEX_NAME + " 已存在");
}
break; // 成功则退出循环
} catch (IOException e) {
retryCount++;
if (retryCount >= 3) {
throw e; // 重试3次后抛出异常
}
System.err.println("索引初始化失败,正在重试 (" + retryCount + "/3)...");
TimeUnit.SECONDS.sleep(2); // 等待2秒后重试
}
}
} catch (IOException | InterruptedException e) {
System.err.println("### 索引初始化严重错误 ###");
e.printStackTrace();
// 这里可以添加通知逻辑,如发送邮件或短信
}
}
private boolean indexExists(String indexName) throws IOException {
// 正确创建 GetIndexRequest 并指定索引名称
GetIndexRequest request = new GetIndexRequest().indices(indexName);
return elasticsearchClient.indices().exists(request, RequestOptions.DEFAULT);
}
private void createIndexWithMapping(String indexName, String mappingFilePath) throws IOException {
// 1. 创建索引请求
CreateIndexRequest request = new CreateIndexRequest(indexName);
// 2. 设置索引设置(可选)
request.settings(Settings.builder()
.put("index.number_of_shards", 3)
.put("index.number_of_replicas", 1)
.put("index.refresh_interval", "1s")
.build());
// 3. 加载映射文件
ClassPathResource resource = new ClassPathResource(mappingFilePath);
if (!resource.exists()) {
throw new IOException("映射文件未找到: " + mappingFilePath);
}
String mappingSource = new String(Files.readAllBytes(Paths.get(resource.getURI())), StandardCharsets.UTF_8);
request.mapping(mappingSource, XContentType.JSON);
// 4. 创建索引
CreateIndexResponse createIndexResponse = elasticsearchClient.indices().create(request, RequestOptions.DEFAULT);
// 5. 处理响应
if (createIndexResponse.isAcknowledged()) {
System.out.println("索引 " + indexName + " 创建成功");
} else {
System.err.println("索引创建请求未被确认");
System.err.println("响应信息: " + createIndexResponse);
}
}
}
对应的 src/main/resources/mapping/print_job_history_mapping.json 文件:
{
"mappings": {
"properties": {
"jobId": { "type": "keyword" },
"deviceSn": { "type": "keyword" },
"deviceName": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },
"deviceModel": { "type": "keyword" },
"printStartTime": { "type": "date", "format": "strict_date_optional_time||epoch_millis" },
"printEndTime": { "type": "date", "format": "strict_date_optional_time||epoch_millis" },
"printDuration": { "type": "long" },
"materialUsage": { "type": "float" },
"jobStatus": { "type": "integer" },
"layerHeight": { "type": "float" },
"nozzleTemp": { "type": "integer" },
"bedTemp": { "type": "integer" },
"materialType": { "type": "keyword" },
"fileSize": { "type": "long" },
"creator": { "type": "keyword" },
"department": { "type": "keyword" },
"successRate": { "type": "float" },
"failureReason": { "type": "text" }
}
}
}
启动程序
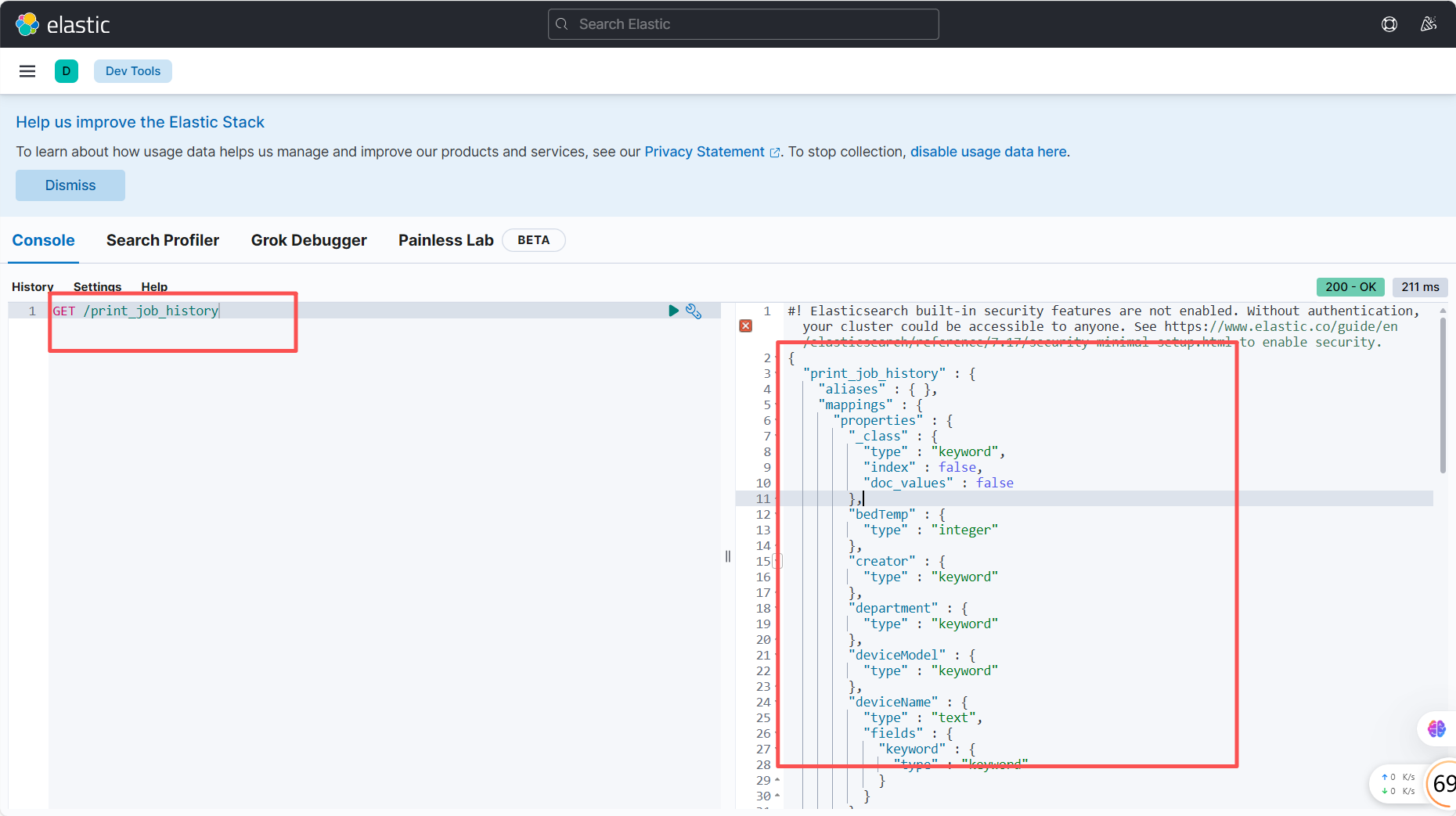
测试端点
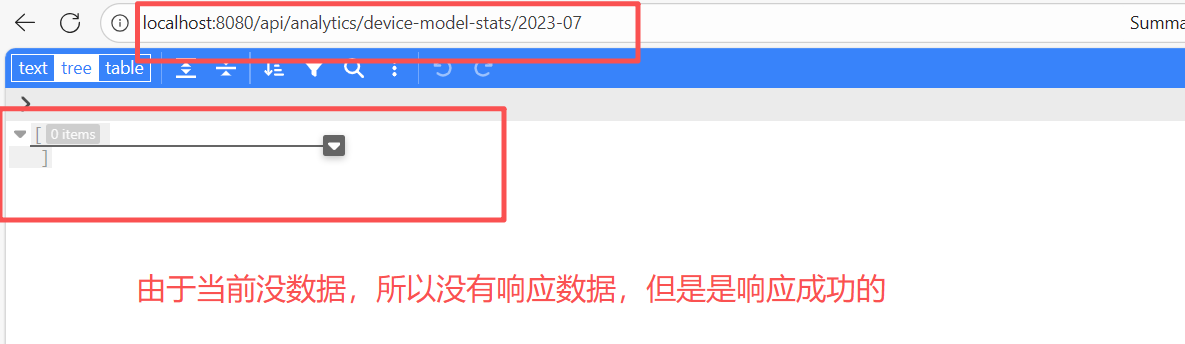
生成大量模拟数据
使用 Java Faker 库
添加依赖 (pom.xml)
<!-- Java Faker for generating fake data -->
<dependency>
<groupId>com.github.javafaker</groupId>
<artifactId>javafaker</artifactId>
<version>1.0.2</version> <!-- 使用较新版本 -->
</dependency>
创建数据生成服务
package com.grant.code.esdemo.controller;
import com.grant.code.esdemo.service.DataGenerationService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/data")
public class DataGenerationController {
@Autowired
private DataGenerationService dataGenerationService;
@PostMapping("/generate")
public String generateData(@RequestParam(defaultValue = "10000") int count) {
try {
dataGenerationService.generateAndSaveData(count);
return "Successfully generated and saved " + count + " data entries.";
} catch (Exception e) {
e.printStackTrace();
return "Error generating data: " + e.getMessage();
}
}
}
创建 Controller 端点触发数据生成
package com.grant.code.esdemo.controller;
import com.grant.code.esdemo.service.DataGenerationService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/data")
public class DataGenerationController {
@Autowired
private DataGenerationService dataGenerationService;
@PostMapping("/generate")
public String generateData(@RequestParam(defaultValue = "10000") int count) {
try {
dataGenerationService.generateAndSaveData(count);
return "Successfully generated and saved " + count + " data entries.";
} catch (Exception e) {
e.printStackTrace();
return "Error generating data: " + e.getMessage();
}
}
}
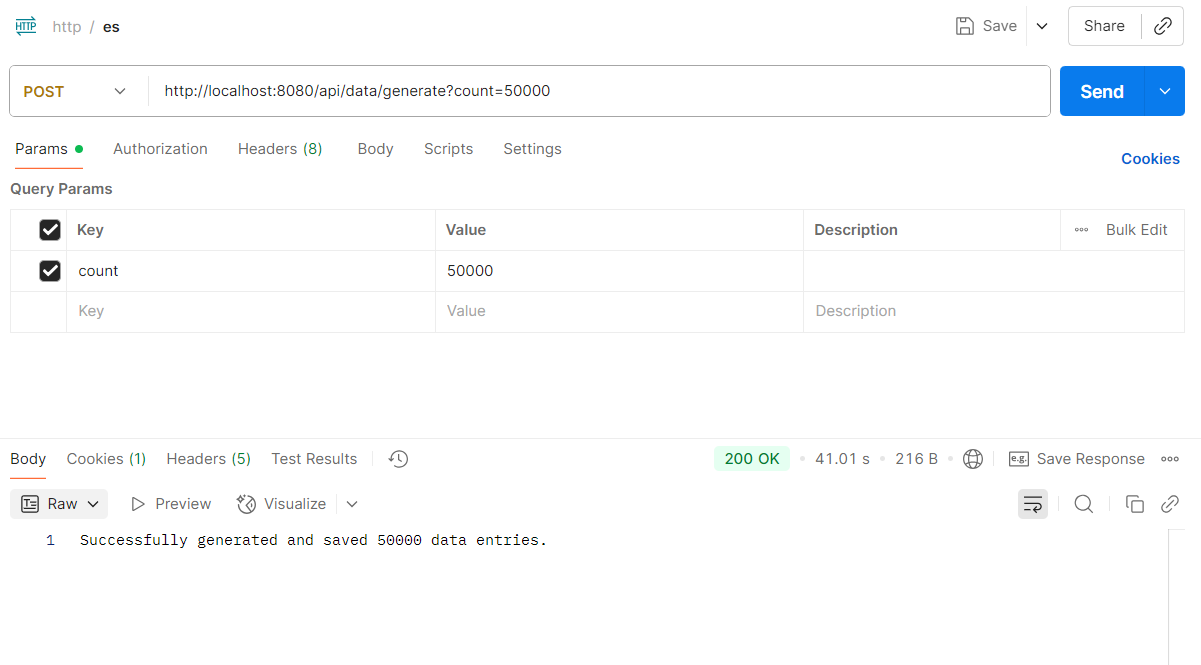
通过postman发送请求,生成50000条测试数据
观察控制台输出

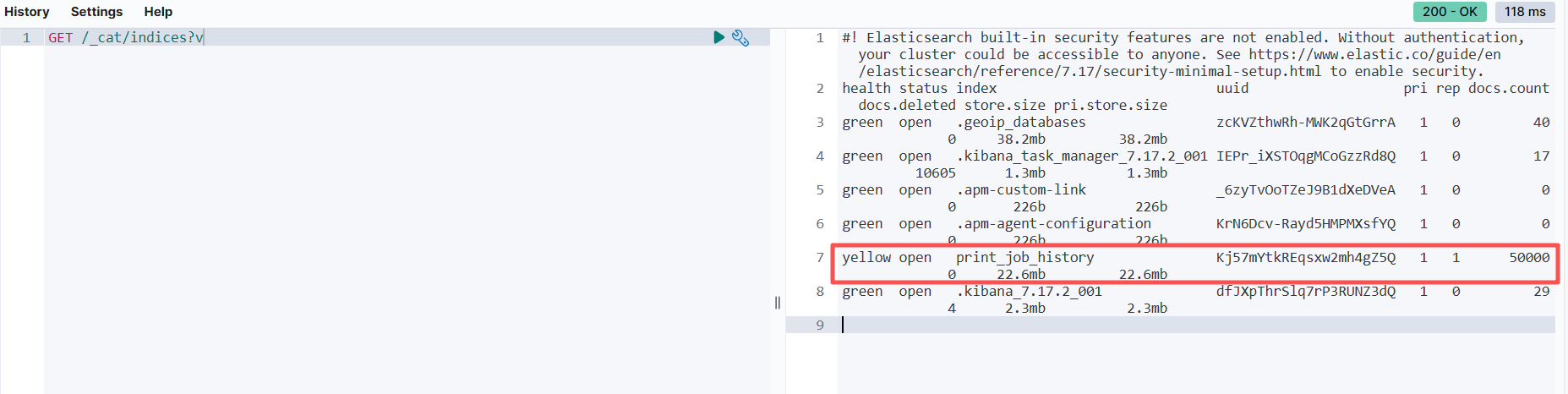
查看kibana
测试
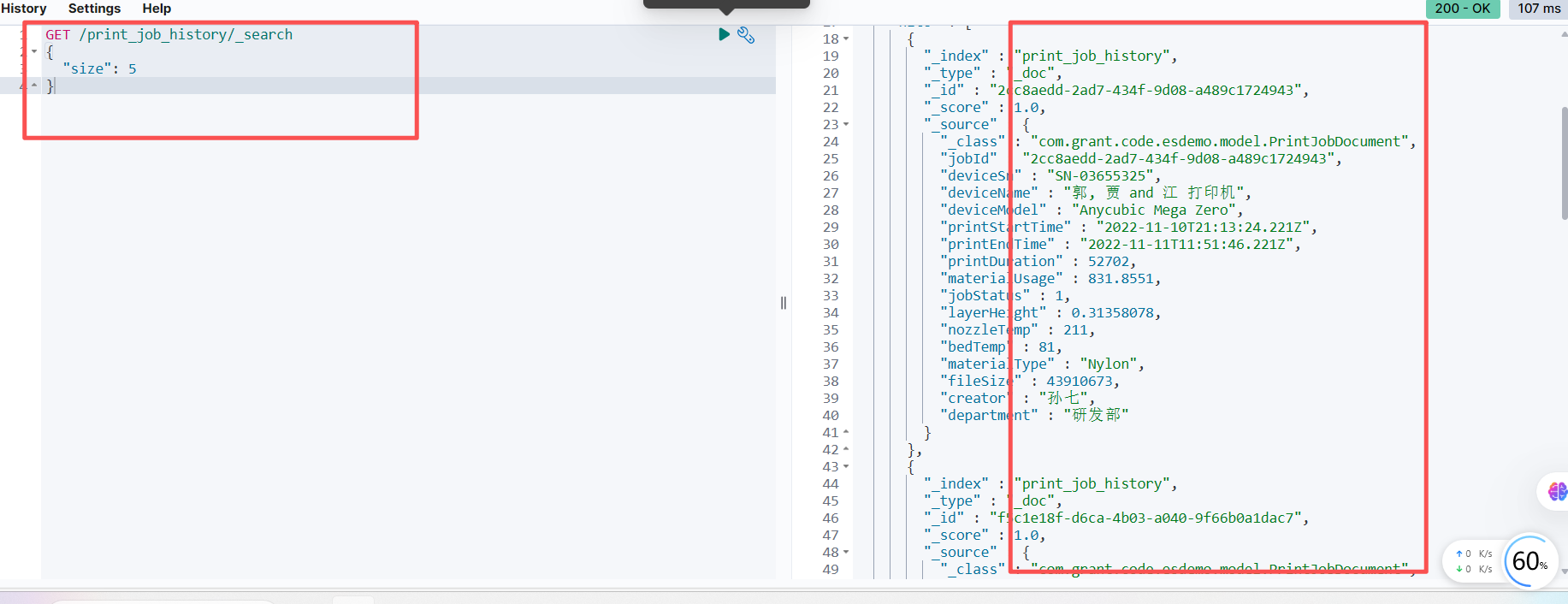
测试查询 1:设备型号月度打印时长 TOP 10
假设查询 2023 年 10 月的数据
POST /print_job_history/_search
{
"size": 0,
"query": {
"range": {
"printStartTime": {
"gte": "2023-10-01T00:00:00",
"lt": "2023-11-01T00:00:00",
"format": "strict_date_optional_time"
}
}
},
"aggs": {
"by_device_model": {
"terms": {
"field": "deviceModel",
"size": 10,
"order": { "total_hours": "desc" }
},
"aggs": {
"avg_hours": {
"avg": {
"field": "printDuration"
}
},
"total_hours": {
"sum": {
"field": "printDuration"
}
},
"total_hours_in_hours": {
"bucket_script": {
"buckets_path": {
"totalSeconds": "total_hours"
},
"script": "params.totalSeconds / 3600"
}
},
"avg_hours_in_hours": {
"bucket_script": {
"buckets_path": {
"avgSeconds": "avg_hours"
},
"script": "params.avgSeconds / 3600"
}
}
}
}
}
}
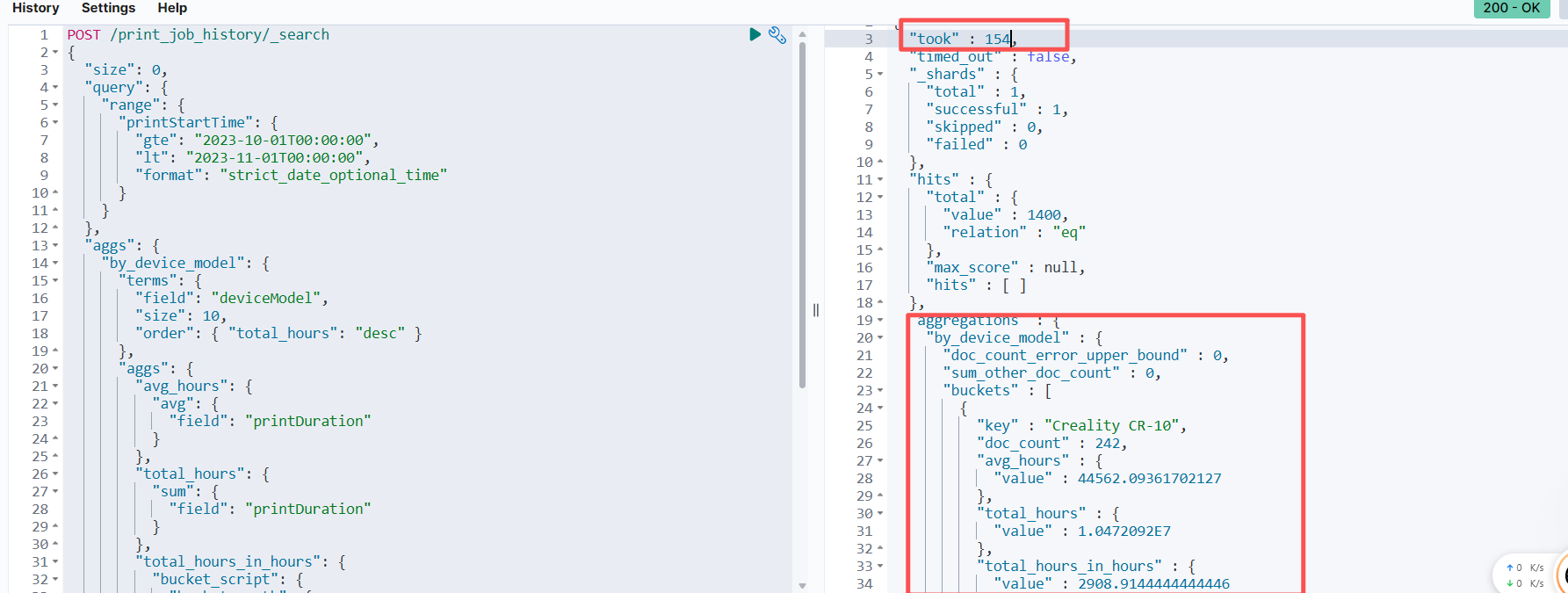
查看返回结果的 aggregations 部分,确认是否得到了预期的设备型号及其总时长和平均时长。特别注意 took 字段,它表示 ES 执行查询所花费的时间(毫秒),应该远小于原始 MySQL 的 12.4 秒。 这里5万条数据仅需 154毫秒!!!!
测试查询 2:近期任务成功率
查询过去一小时的成功率。
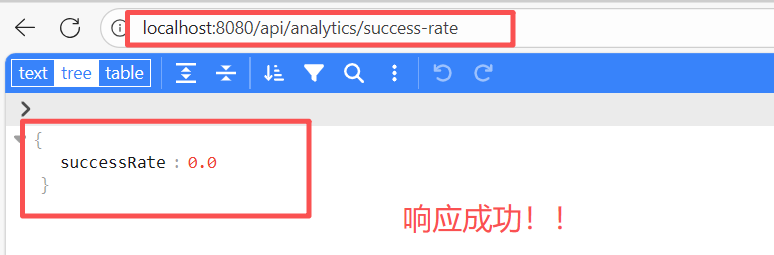
这里直接测试接口
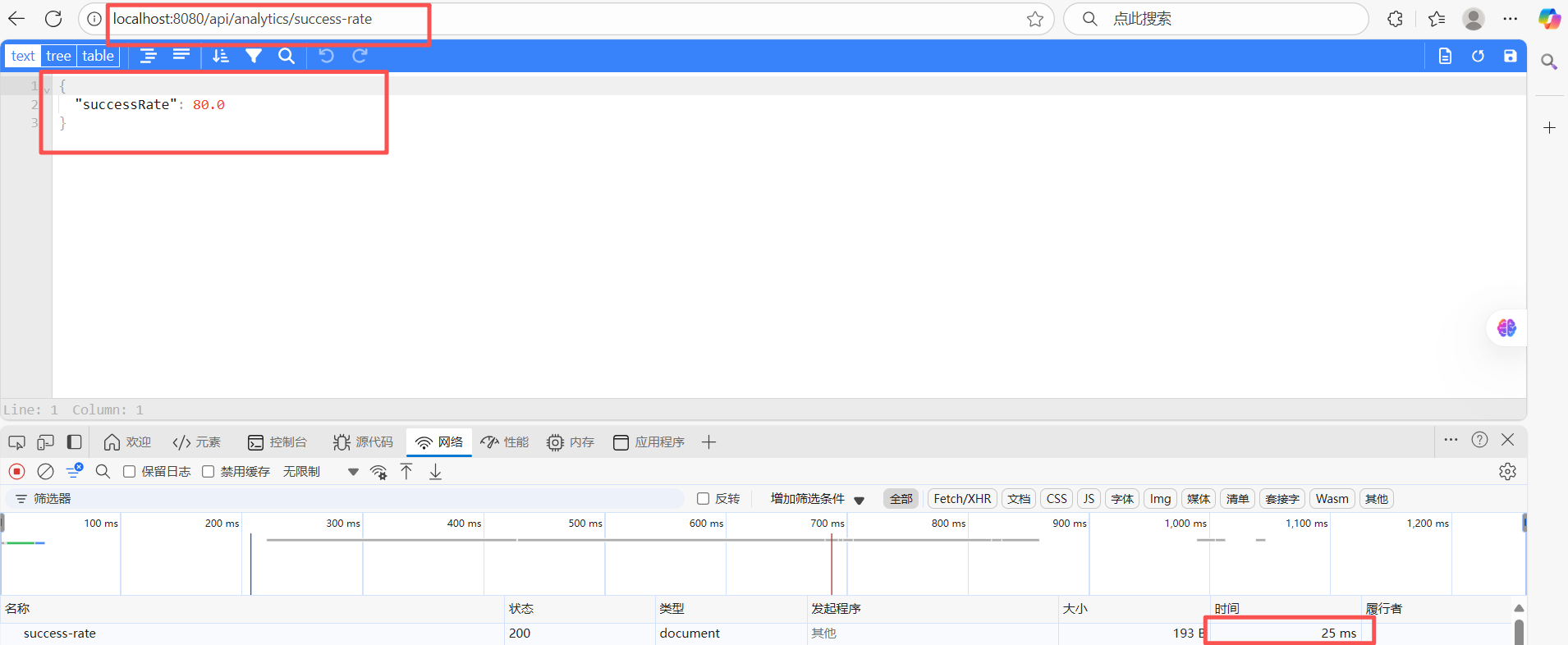
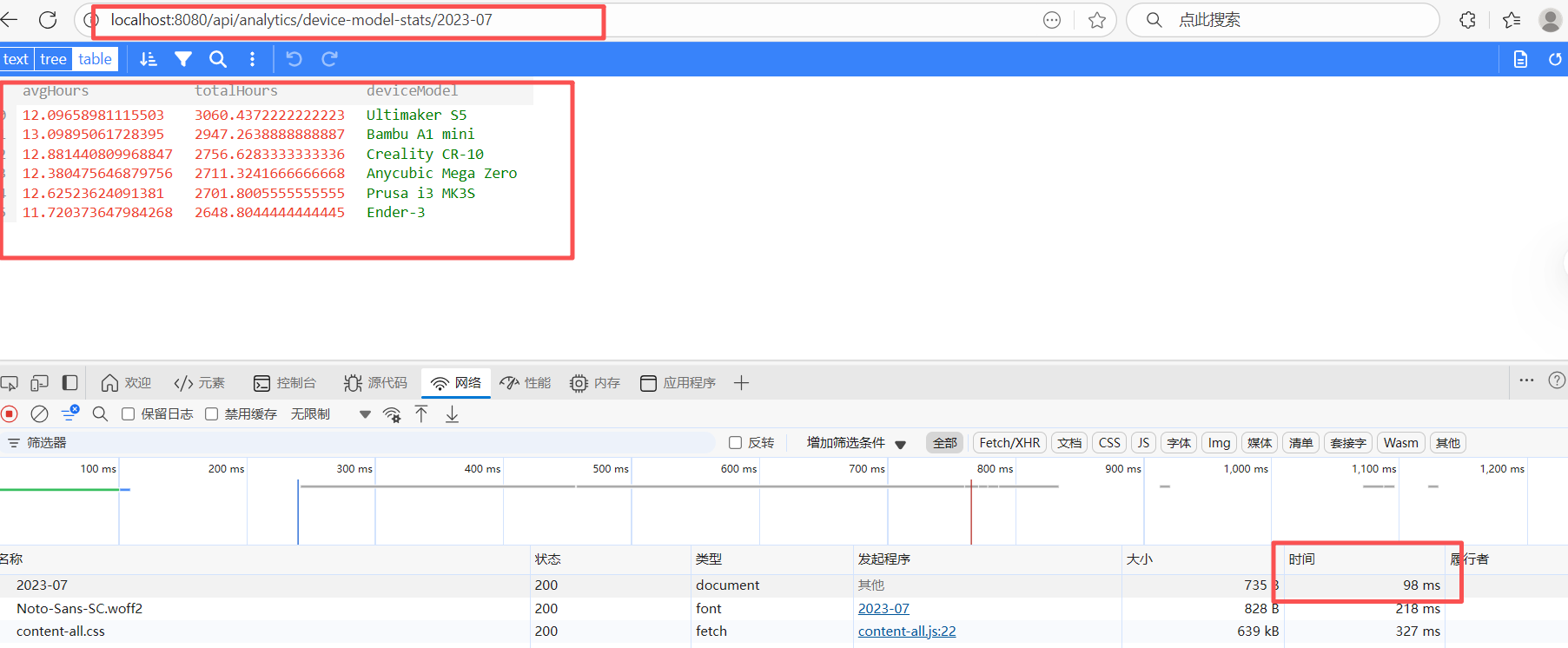
可以发现速度还是飞快的!!!
总结与展望
通过引入Elasticsearch,3D打印机管理系统的打印任务统计分析功能实现了质的飞跃。不仅解决了传统MySQL方案的性能瓶颈,还为系统带来了更丰富的数据分析能力和更好的用户体验。