好几个月没有接触学习一些新的技术栈了,这次还是因为需要一个兼顾并发以及统计低延迟的实时预警。
学习内容:

结论分析:
1、首先学习和查看了一下flink中的几种api,发现可能顶层的sql比较符合与这样数据一些。
学习内容:

事件时间
认知学习:事件时间-记录的是设备生产(存储的时间的时间)
结论分析:
一、什么是处理时间(Processing Time)?
处理时间指的是数据被处理系统实际处理时的系统时间,也就是 Flink 任务运行所在的机器的系统时钟。
举个例子:
- 一条股票交易记录是在 10:00:05 发生的(这是事件时间)。
- 但由于网络延迟或系统负载,Flink 程序在 10:00:10 才收到并处理这条数据。
- 那么 Flink 使用的“时间”就是 10:00:10(处理时间)。
二、为什么处理时间会导致结果不一致?
情景:计算“某天第一个小时”的股票最高价
假设我们要计算 2025年9月1日 09:00 - 10:00 这个时间段内股票的最高价格。
✅ 使用事件时间:Flink 根据每条数据自带的时间戳(比如交易发生时间)来判断它属于哪个时间段。无论你什么时候运行程序,只要数据相同,结果就一致。
❌ 使用处理时间:Flink 使用的是“当前系统时间”来划分窗口。问题来了:
- 如果程序在 2025年9月1日 10:00 实时运行,它会把从 09:00 到 10:00 收到的数据划入第一个小时窗口。
- 但如果网络延迟,某些 09:00-10:00 发生的交易在 10:05 才到达,那么这些数据就会被划入 10:00-11:00 的窗口,导致第一个小时的统计结果缺失数据。
- 如果你第二天重跑程序,由于数据是回放的、没有延迟,所有数据都及时到达,那么这些本该延迟的数据现在被正确归入 09:00-10:00 窗口。
🔄 结果:同一批数据,两次运行(一次实时,一次回放),得到的“第一个小时最高价”可能完全不同!
三、为什么这会导致“再次分析历史数据”或“测试新代码”困难?
1. 无法复现历史结果
- 假设你在实时系统中发现昨天某个指标异常,想“重跑”昨天的数据来排查问题。
- 如果系统用的是处理时间,重跑时数据是快速回放的,没有网络延迟、没有背压,数据的“处理时间”分布和真实运行时完全不同。
- 导致重跑结果和线上结果不一致,无法复现问题,调试变得极其困难。
2. 测试新代码不可靠
- 你想上线一个新版本的 Flink 作业。
- 用历史数据做测试时,由于处理时间变了,窗口划分、聚合结果都可能不同。
- 你无法判断结果差异是代码逻辑问题,还是时间划分不同导致的。
3. 缺乏确定性
- 处理时间依赖于运行环境的性能、负载、网络等外部因素。
- 这使得程序的输出不再是确定性的(deterministic),违背了“相同输入应得相同输出”的基本原则。
四、事件时间如何解决这个问题?
事件时间基于数据本身携带的时间戳(如交易时间、日志时间),而不是系统时间。
- Flink 通过 时间戳提取器(Timestamp Extractor) 获取每条数据的事件时间。
- 通过 Watermark 机制 来处理乱序和延迟数据,允许系统在等待一定时间后“关闭”时间窗口。
- 这样,无论你什么时候运行程序,只要输入数据相同,窗口划分和计算结果就完全一致。
五、总结
| 对比项 | 处理时间(Processing Time) | 事件时间(Event Time) |
|---|---|---|
| 时间来源 | 系统时钟 | 数据自带时间戳 |
| 结果一致性 | ❌ 不一致(受延迟、负载影响) | ✅ 一致(可重现) |
| 适合场景 | 对延迟敏感、允许误差的场景(如实时监控) | 对准确性要求高的场景(如计费、报表、回溯分析) |
| 调试与测试 | ❌ 困难 | ✅ 容易 |
因为处理时间依赖于数据到达的“实时系统状态”(如延迟、负载),而这些状态在不同运行中是变化的。而事件时间只依赖数据本身,因此是确定性的。这就是为什么在需要可重现性的场景(如金融计算、历史分析、A/B测试),我们必须使用事件时间。
使用Event Time
使用Event Time 事件产生的时间,记录的是设备生产(或者存储)事件的时间
需要额外给 Flink 提供一个时间戳提取器和 Watermark 生成器,Flink 将使用它们来跟踪事件时间的进度。
补充逻辑--算子:
在 Apache Flink 中,算子(Operator) 是流处理程序中最基本的处理单元,你可以把它理解为“对数据进行某种操作的组件”或“数据处理的函数模块”。
简单来说:算子就是你写代码时调用的那些转换方法(如 map、filter、keyBy、window 等),它们定义了数据如何被处理。
一、通俗理解:算子就像“工厂流水线上的机器”
想象一条生产流水线:
- 原材料(输入数据)进来
- 经过一台台机器(算子)加工
- 最后变成成品(输出结果)
每台机器执行一个特定任务,比如:
- 筛选机 →
filter - 切割机 →
map - 分拣机 →
keyBy - 包装机 →
window+sum
在 Flink 中,这些“机器”就是算子。
二、常见的 Flink 算子类型(按功能分类)
1. Source 算子(数据源)
- 作用:从外部系统读取数据,是数据流的起点。
2. Transform 算子(转换操作)
这是最核心的一类,用于对数据进行各种处理:
| 算子 | 作用 | 示例 |
|---|---|---|
map |
将每条数据一对一转换 | DataStream<String> → DataStream<Integer>(字符串转长度) |
filter |
过滤掉不符合条件的数据 | 只保留价格 > 100 的交易 |
keyBy |
按某个字段分组(物理分区) | 按用户ID分组,后续做聚合 |
window |
定义窗口(时间窗口、滑动窗口等) | 统计每5分钟的销售额 |
sum / reduce / aggregate |
聚合操作 | 计算总和、最大值等 |
flatMap |
一条数据转为零或多条 | 一句话拆成多个单词 |
union |
合并多个流 | 把两个数据流合并成一个 |
Sink 算子(数据汇):
作用:将处理结果输出到外部系统,是数据流的终点
总结:算子的核心要点
| 特性 | 说明 |
|---|---|
| 本质 | 数据处理的函数或操作 |
| 作用 | 定义数据如何被转换、聚合、分组、输出 |
| 常见类型 | Source、Transform、Sink |
| 运行时 | 被实例化为 Task,可并行执行 |
| 重要性 | 是构建 Flink 流水线的“积木” |
✅ 简单记住:
你在 Flink 代码里调用的每一个 .xxx() 方法(如 .map()、.filter()),基本上就是一个算子。
Watermarks- Watermark 生成器
如果想要使用事件时间,需要额外给 Flink 提供一个时间戳提取器和 Watermark 生成器,Flink 将使用它们来跟踪事件时间的进度。
这正是 watermarks 的作用 — 它们定义何时停止等待较早的事件。
Flink 中事件时间的处理取决于 watermark 生成器,后者将带有时间戳的特殊元素插入流中形成 watermarks。事件时间 t 的 watermark 代表 t 之前(很可能)都已经到达。
当 watermark 以 2 或更大的时间戳到达时,事件流的排序器应停止等待,并输出 2 作为已经排序好的流。
理论总结:
这个生成器是作为保证在流数据中的发生时间是不一样的情况下来对流进行排序来保证流输出的正确性。这里涉及到等待较为前置的数据进入,并排序。
Windows
概要
在操作无界数据流时,经常需要应对以下问题,我们经常把无界数据流分解成有界数据流聚合分析:
- 每分钟的浏览量
- 每位用户每周的会话数
- 每个传感器每分钟的最高温度
用 Flink 计算窗口分析取决于两个主要的抽象操作:Window Assigners,将事件分配给窗口(根据需要创建新的窗口对象),以及 Window Functions,处理窗口内的数据。
Flink 的窗口 API 还具有 Triggers 和 Evictors 的概念,Triggers 确定何时调用窗口函数,而 Evictors 则可以删除在窗口中收集的元素。
窗口分配器:
Flink 有一些内置的窗口分配器,如下所示:
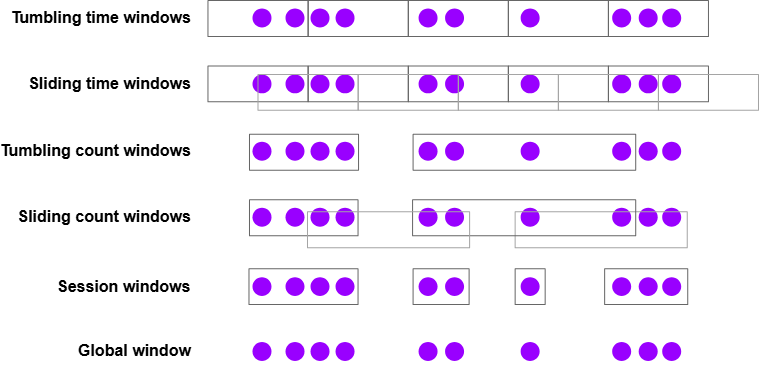
通过一些示例来展示关于这些窗口如何使用,或者如何区分它们:
- 滚动时间窗口
- 每分钟页面浏览量
TumblingEventTimeWindows.of(Duration.ofMinutes(1))
- 滑动时间窗口
- 每10秒钟计算前1分钟的页面浏览量
SlidingEventTimeWindows.of(Duration.ofMinutes(1), Duration.ofSeconds(10))
- 会话窗口
- 每个会话的网页浏览量,其中会话之间的间隔至少为30分钟
EventTimeSessionWindows.withGap(Duration.ofMinutes(30))
以下都是一些可以使用的间隔时间 Duration.ofMillis(n), Duration.ofSeconds(n), Duration.ofMinutes(n), Duration.ofHours(n), 和 Duration.ofDays(n)。
基于时间的窗口分配器(包括会话时间)既可以处理 事件时间,也可以处理 处理时间。这两种基于时间的处理没有哪一个更好,我们必须折中。使用 处理时间,我们必须接受以下限制:
- 无法正确处理历史数据,
- 无法正确处理超过最大无序边界的数据,
- 结果将是不确定的,
但是有自己的优势,较低的延迟。
使用基于计数的窗口时,请记住,只有窗口内的事件数量到达窗口要求的数值时,这些窗口才会触发计算。尽管可以使用自定义触发器自己实现该行为,但无法应对超时和处理部分窗口。
我们可能在有些场景下,想使用全局 window assigner 将每个事件(相同的 key)都分配给某一个指定的全局窗口。 很多情况下,一个比较好的建议是使用 ProcessFunction,具体介绍在这里。
结论理解:
✅ 核心结论:
Flink 中的每一个窗口都需要一个“触发条件”来决定:何时计算并输出结果。
无论是时间窗口(如每5秒)还是计数窗口(如每100条数据),背后都依赖某种触发机制(Trigger)