【四】情感支撑对话论文最近进展 Emotion Support Conversation
今天给大家分享一篇在EMNLP 2022的关于情感对话的论文。主要思想是从策略安排的角度来有效地提供情感支撑,并且通过理解用户的状态达到更好的生成效果。
相关情感支撑论文综述整理指路 -> 点这里
MultiESC:
Improving Multi-turn Emotional Support Dialogue Generation with Lookahead Strategy Planning
分以下四部分介绍:
- Motivation
- Challenges & Contributations
- Model
- Experiment
- Discussion
Motivation
一个更合理的策略安排可以有效地提供情感支撑,并且理解用户的状态也可以更好地帮助回复。
1、Challenges & Contributations
Challenges
- how to conduct support strategy planning that could lead to the best supporting effects
- how to dynamically model the user’s state.
Contributations
- Propose MultiESC which conducts support strategy planning with foresight of the user feedback and dynamically tracks the user’s state by capturing the subtle emotional expressions
- adopts A∗-like lookahead heuristics to achieve dialogue strategy selection on a long planning
- Experiments show that MultiESC significantly outperforms a set of state-of-the-art models
2、Model
2.1 overview
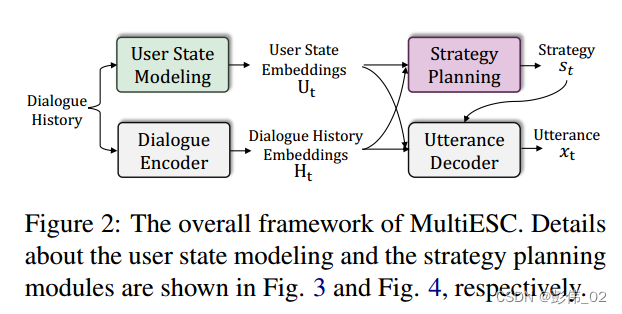
整个模型包含4个部分,左边是编码部分,右边是策略的预测以及解码部分。
在编码部分,第1部分就是对话历史上下文的建模,第2部分是对用户的状态进行建模。核心部分是在于如何进行一个好的策略预测,最后是回复生成部分。
对话历史建模就不详细说了,和之前的建模方式一样。
2.2 用户状态建模

主要是两部分,第1部分是输入的构造,第2部分是情感向量的构造。
2.2.1 输入的构造
在输入部分,作者首先用当前轮的上下文(x,y),并且根据用户的句子通过一个情感模型来得到反应当前的一个情感状态的句子(万一没有怎么办),如图中划线部分。并且用一个特殊的标志[EC]来将它跟上下文串联在一起(我的理解就是对上下文中情感信息做了一个增强),如图所示。此时输入的token embedding构造完毕。
2.2.2 情感向量构造:
作者借助 NRC VAD 字典来识别上下文当中的每一个词属于哪一个子空间(三个维度,V,A,D),这样每个词就会有一个向量状态,表示对于没有情感的词统一用一个额外的向量进行表示。
关于VAD的详细介绍如下:

最后通过一个transformer的编码器,把这些向量去进行编码。
2.3 策略打分&反馈计算
总的来说就是如何找到下面这样的一个打分函数,作者考虑用到A*搜索的启发策略。
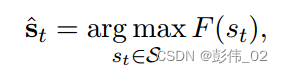
该函数有两部分打分组成,第1部分打分表示的是根据过去的信息来得到当前的一个策略,第2部分的打分是如何考虑未来的信息评估用户的反馈(肯定要选择反馈好的策略)。
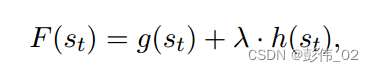
那第1部分的计算就很简单了,主要是根据对话的历史和用户状态计算策略的概率分布:
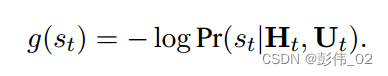
关于第2部分的计算,作者把未来的信息计算成——未来用户反馈得分的数学期望。
其中P表示的是策略的概率分布,f表示的是使用这个策略用户的情感打分。
因此就存在两个问题,P和f如何去进行计算?
因为要使用未来的信息,所以在这个地方最直接和最暴力的一种方法就是直接枚举所有未来可能的策略,但是这样的方法计算复杂度太大,因此作者在这里做了两个简化。
第1个是限定未来固定长度,只考虑一定的窗口。
第2个是说只考虑未来的Top-k,并不是所有的。
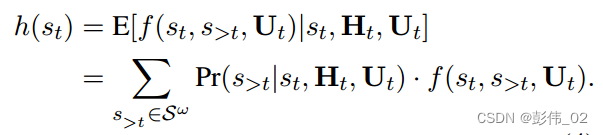
因此公式简化如下:
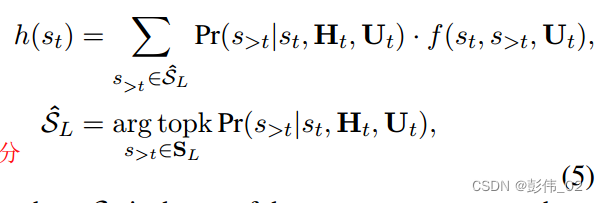
2.3.1 策略打分计算
关于未来策略得分的计算,肯定是每一时刻的策略得分乘起来,所以:
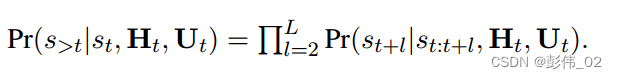
这个地方作者构造了一个策略序列生成器,简单来说就是如何根据对话历史H,用户的状态U和策略序列P来计算策略概率。
直接多头注意力即可:
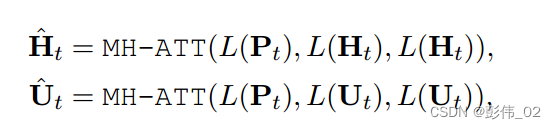
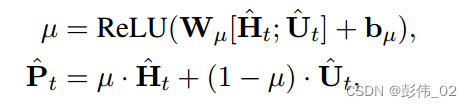
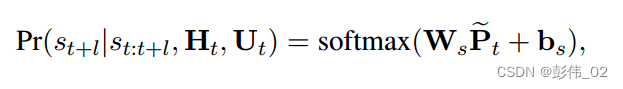
训练的时候直接用真实标签的NLL loss进行优化。
2.3.2 用户的反馈计算
关于用户的反馈计算作者是使用了一个注意力机制。那么query和key分别是什么呢?
首先定义策略向量矩阵,可以把这个理解为词向量。通过下面的公式来计算策略序列的信息。
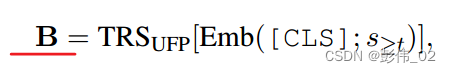
Suppose the encoded hidden state corresponding to the [CLS] token is q s q_s qs.
因此,query即策略信息 q s q_s qs。
然后将用户的状态信息U当做key,进行attention,加权求和得到 u f u_f uf:
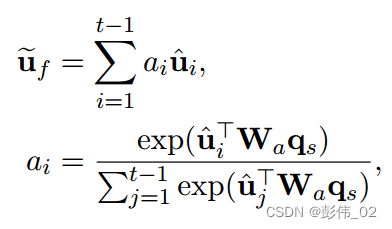
最后再通过一个全连接层来计算打分,把这个打分当做用户的反馈。
损失函数直接用均方差损失来计算模型输出的打分和真实打分之间的差距。
2.4 解码部分
直接通过解码器融入最开始定义的策略进行回复生成,下图
3、Experiment
实验部分主要的是两个实验,第1个是回复生成的实验,第2个是策略预测的实验,那么这个也是给了这些相关的实验来证明模型的有效性。
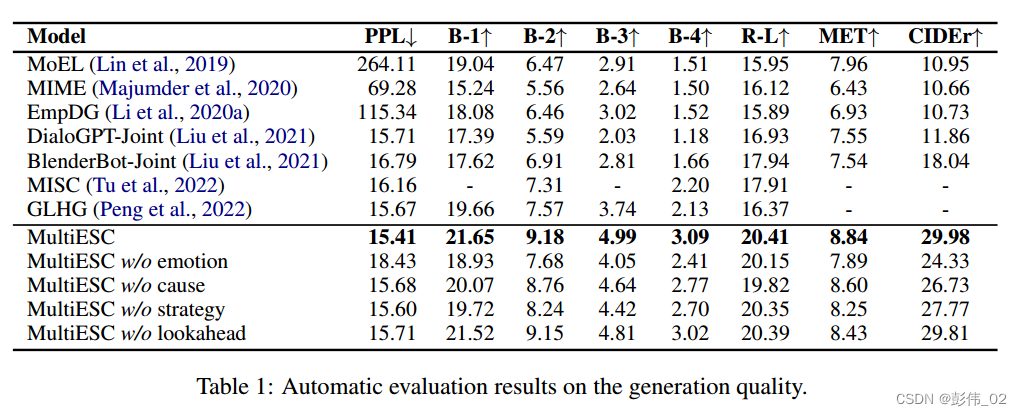
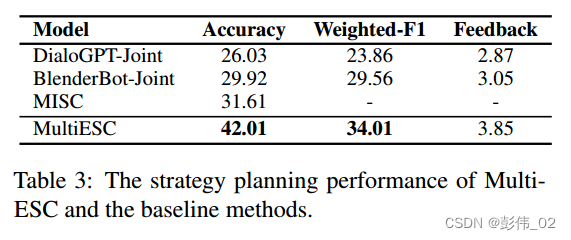
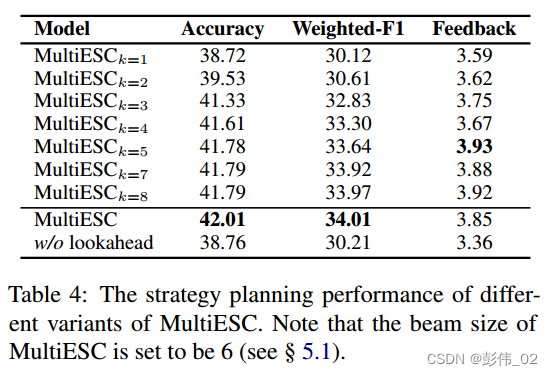
case study:

4、Discussion
这篇文章主要考虑的是做一个未来策略的安排,在其中用到了A*搜索算法,分别计算了基于历史,对当前作出的判断以及对未来的一个规划实验效果,充分的说明了模型的有效性。
比较想知道的一个点就是在进行多步未来探索的过程当中,因为作者是限制了未来的窗口以及top-k的一个效果,这些超参数对实验的影响程度以及复杂程度有多大。另外在对反馈计算的过程当中,作者是利用用户的状态信息和策略的表示去进行attention的计算,这一个过程真正思考下来其实不是特别容易想明白。但是通过实验的指标可以提现出来,模型确实有了一个很大的提升,回头可以等代码放出来之后好好学习一下。

相关论文整理指路 -> 点这里
更多有趣MRC文章见:利用逆向思维的机器阅读理解。
相关文献
Bi-directional Cognitive Thinking Network for Machine Reading Comprehension 论文阅读
证据推理网络。
Hybrid Curriculum Learning for Emotion Recognition in Conversation
BERT用于文本分类方法