
代码:https://anonymous.4open.science/r/mol_img_rec
模型思路:
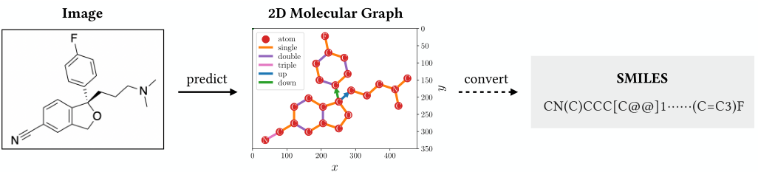
训练一个模型,从图像中预测原子和键,并构建分子图,然后使用化学工具包转换为SMILES。
使用化学结构编辑器来渲染分子,但一旦描绘被保存为图像,机器解码其原始结构就不是件容易的事。给定这样的图像,目标是生成分子的顺序表示,例如简化分子输入行输入系统(SMILES)[44]字符串。
将图像I转化为SMILES字符串s。令s = (s1, s2,…, sn),其中每个token要么对应一个原子,要么表示它们的连接(例如括号和数字)。将输出定义为二维分子图G = (a, B),其中a = {a1, a2,…, am}是原子的集合,B⊂A×A×T是键的集合,T是键类型的集合(例如,单、双、实楔、虚线楔)。
一、模型架构(编码器-解码器)
1、整体架构
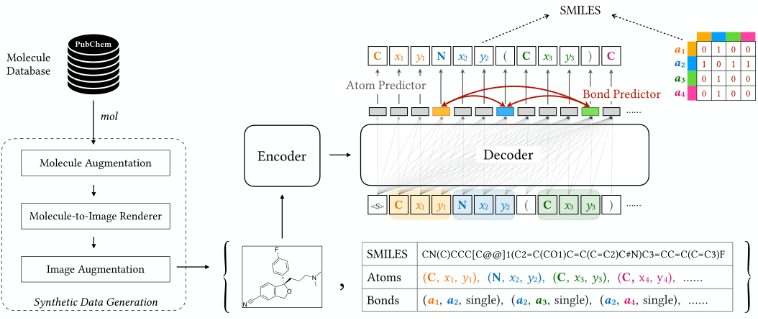
使用Encoder将input image编码为hidden embedding。Decoder以hidden embedding作为输入,自回归生成一系列token。之前的工作直接生成(标记化)SMILES字符串作为输出。主要存在两个问题:(1)生成过程是一个黑箱。人类很难检查预测的smiles或识别错误;(2)该模型难以识别复杂的化学模式,例如立体化学,这需要对分子图进行几何推理。
Encoder:Swin Transformer
Decoder:Transformer
形式上:
![]()
I为image,A为Atom predictor,B为Bond predictor。
2、组件(Atom predictor、Bond predictor)
1)、Atom predictor
位于Decoder最后一层的Linear head,可以同时预测原子label和坐标,把原子当作物体来检测(预测原子的坐标而不是边界框)。虽然SMILES字符串包含所有原子标签作为token,但将其扩充为包含图像中原子的几何坐标。具体来说,在每个原子标记之后,插入表示原子坐标(x,y)的token。连续坐标通过分组转换为离散标记。注意,在序列2中保留了非原子标记。
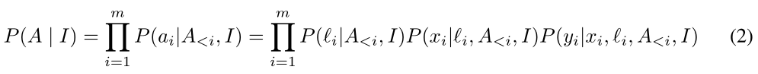
其中a表示atom label,x,y表示坐标,A<i表示第i个原子前面的原子。
2)、Bond predictor
位于Decoder最后一层的feedforward network,Decoder的工作是将embedding转为embedding:
![]()
对于每一个原子对,将两个原子的表示连接起来,作为Bond predictor的输入,对bond类型进行分类.
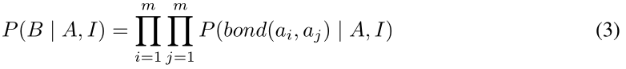
还包括一个“None”类型,表示原子对之间不存在键。
3、训练
训练数据:从PubChem中采样分子,使用Indigo渲染器自动生成分子图像。还可以通过Indigo获得图像中每个原子的像素级(x, y)坐标。在合成数据上训练的模型在真实图像上表现较差:
现实世界的分子图像可能具有合成图像中从未出现过的化学模式,例如官能团和r-基团的缩写(如Me、Et、CHO)的使用(即分子子结构的占位符)。
不同的期刊发表不同的分子绘制标准或模板,大多数化学家有自己的风格,因此真实的图像可能来自不同于合成数据的分布。
1)Molecule Augmentation
目的是使得模型吸收分子模式的必要化学知识。
构造一个常用官能团缩写的替代列表。在训练过程中,当一个分子包含列表中的一个官能团时,按照预定义概率的替换规则随机替换它。官能团内部的原子和键从分子图中删除,取而代之的是一个带有缩写标签的“伪原子”。还可以随机添加一个R-group,其标签从常见的R-group标签列表中采样。
编制了51条常用的官能团替换规则,并在50%的训练分子中随机将官能团替换为其缩写。还在训练分子中加入50%的r基团。R组标签从列表中随机抽取[R, R1, R2, . . . , R12, Ra, Rb, Rc, Rd, X, Y, Z, A, Ar]
2)Image Augmentation
利用Indigo中的可用呈现选项来动态生成不同样式的图像,以训练模型。其次,对图像进行随机数据增强操作,包括旋转、填充、裁剪、缩放、模糊、高斯噪声和椒盐噪声。该策略的设计使训练图像具有不同的风格和质量,同时保留必要的分子结构信息。
在生成图像时,控制Indigo参数:

在图像transform时,随机augment:
[90◦,90◦]任意旋转角度
将图像的每一侧最多裁剪1%
将图像的一侧pad 40%
将图像缩小15-30%,再放大还原
使用random-sized kernel模糊图像
对图像添加高斯噪声
在图像中添加椒盐噪声(随机的黑色像素)
每个操作的应用概率为50%
3)Inference
首先解码模型中所有的原子和键。分子图是根据这些预测构建的。根据预测的分子图,可以在后处理中灵活地加强化学知识和约束。
手性的问题:涉及到某些原子的相对3D位置,而不仅仅是连通性。在图像中,手性是用特定的键类型来描述的,例如,实心楔子代表指向纸的平面外,朝向观察者的键,虚线楔子代表指向纸的平面内,远离观察者的键。然而,在SMILES中,手性被指定为原子性质而不是键的类型。原子后面的符号“@”表示:从第一个键的角度看中心原子,其他键按逆时针方向排列。相反,在原子后面的“@@”表示顺时针。深度学习模型很难确定手性,因为它需要复杂的几何推理以及化学启发式。给定每个手性中心周围的原子坐标和键方向,根据化学规则重写手性
缩写的官能团标记被替换为相应的分子子图,r -基团标记被替换为通配符(“*”)。这与化学惯例是一致的,因为缩写不允许出现在正式的SMILES字符串中。
为了保证分子图的有效性,还可以添加更多的约束条件,如价键检查(例如,一个碳原子最多可以有4个键)。然而,模型默认预测在测试集上达到了超过99%的有效性,因此没有必要进行额外的处理。最后,使用化学工具包RDKit从分子图中导出了SMILES字符串。
二、实验
数据集:
200K分子用于实验,增加到1M用于训练最终模型。这些图像由化学工具包Indigo自动渲染并,得到分子图结构和原子坐标,再取样5K分子作为验证集。根据合成的和现实的基准来评估模型。测试数据:

Metrics:使用RDKit将预测和ground truth转换为规范的SMILES(唯一的分子表示),然后计算字符串的精确匹配。
