最近需要对一些细胞图像进行分割,需要比较几个模型之间的优劣,于是找到了DDRNet。
1.前言
电脑环境配置:win11+NVIDIA GeForce RTX 3060 Laptop+CUDA11.7
如果想用他的数据集cityscapes和他的预训练模型,可以根据上面的项目来源中的指示来做,下载好像都要科学上网。
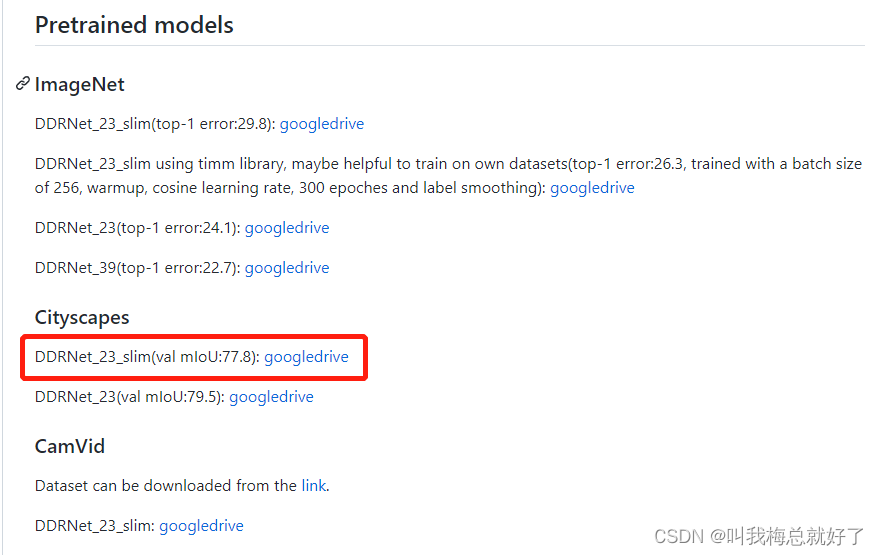
预训练模型选择这个:
cityscapes数据下载:

2.数据集准备
2.1自己数据准备
我的原始数据集是512*512的彩色细胞图像,DDRNet所需要的语义标签图像是8位的灰度图,其中像素点的灰度值即为语义标签的值:
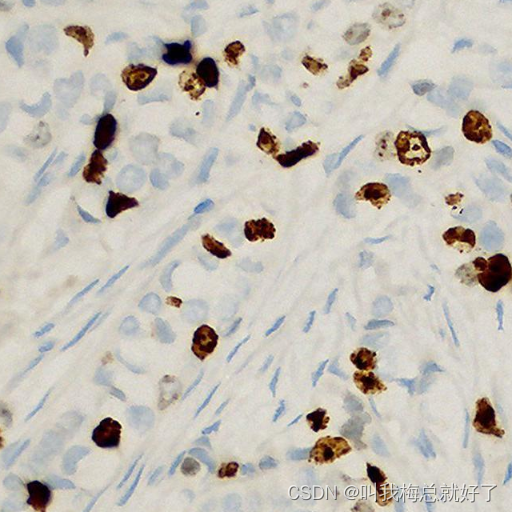
原图如下,我选择了四个标签值【0,1,2,3】分别代表【背景图案,好细胞,坏细胞,细胞边缘】,转化成label后灰度值即为【0,1,2,3】:
上图转化为label之后图像如下:看起来漆黑一片,其实不完全是黑色的。。。
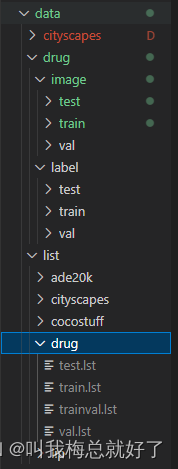
获得了image和label之后,在DDRNet工程项目的data文件夹下创建新的文件夹,我命名为drug,同时在list下创建文件夹drug。将image和label放入文件夹下,同时编辑list下的映射文件,最终data文件夹格式如下:
创建list的相对路径映射文件代码如下:
import os def op_file(): # train train_image_root = 'image/train/' train_label_root = 'label/train/' train_image_path = 'data/drug/image/train' train_label_path = 'data/drug/label/train' trainImageList = os.listdir(train_image_path) trainLabelList = os.listdir(train_label_path) train_image_list = [] for image in trainImageList: train_image_list.append(train_image_root + image) train_label_list = [] for label in trainLabelList: train_label_list.append(train_label_root + label) train_list_path = 'data/list/drug/train.lst' file = open(train_list_path, 'w').close() with open(train_list_path, 'w', encoding='utf-8') as f: for i1,i2 in zip(train_image_list, train_label_list): print(i1, i2) f.write(i1 + " " + i2 + "\n") f.close() # test test_image_root = 'image/test/' test_label_root = 'label/test/' test_image_path = 'data/drug/image/test' testImageList = os.listdir(test_image_path) test_image_list = [] for image in testImageList: test_image_list.append(test_image_root + image) test_list_path = 'data/list/drug/test.lst' file = open(test_list_path, 'w').close() with open(test_list_path, 'w', encoding='utf-8') as f: for i1 in test_image_list: f.write(i1 + "\n") f.close() # val val_image_root = 'image/val/' val_label_root = 'label/val/' val_image_path = 'data/drug/image/val' val_label_path = 'data/drug/label/val' valImageList = os.listdir(val_image_path) valLabelList = os.listdir(val_label_path) val_image_list = [] for image in valImageList: val_image_list.append(val_image_root + image) val_label_list = [] for label in valLabelList: val_label_list.append(val_label_root + label) val_list_path = 'data/list/drug/val.lst' file = open(val_list_path, 'w').close() with open(val_list_path, 'w', encoding='utf-8') as f: for (i1,i2) in zip(val_image_list, val_label_list): f.write(i1 + " " + i2 + "\n") f.close() # trainval trainval_list_path = 'data/list/drug/trainval.lst' file = open(trainval_list_path, 'w').close() with open(trainval_list_path, 'w', encoding='utf-8') as f: for (i1,i2) in zip(train_image_list, train_label_list): f.write(i1 + " " + i2 + "\n") f.close() with open(trainval_list_path, 'a', encoding='utf-8') as f: for (i1,i2) in zip(val_image_list, val_label_list): f.write(i1 + " " + i2 + "\n") f.close() if __name__ == '__main__': op_file()2.2 和自己数据相关的工程代码修改
在lib/datasets下创建Drug.py,复制同级目录下的cityscapes.py,在此基础上修改:
1.文件中的所有和cityscapes都改成drug
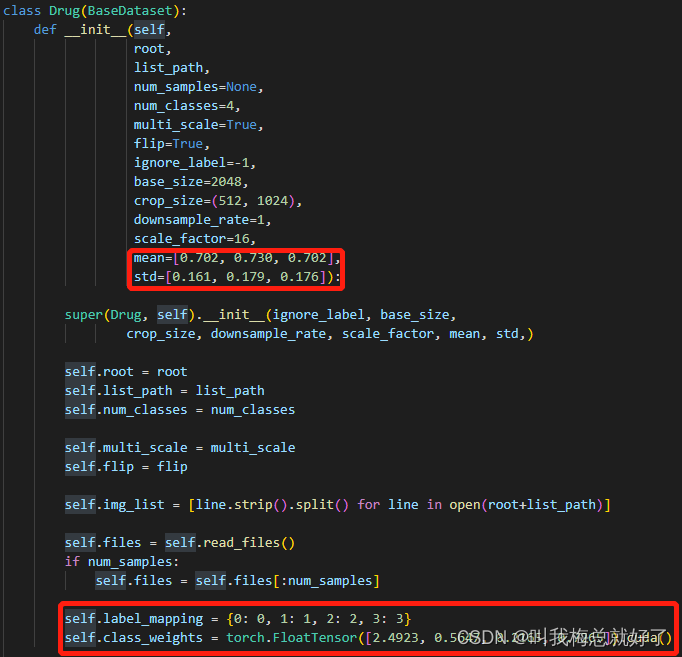
2.修改mean和std,这个应该是需要根据原图来进行计算。计算方法https://blog.csdn.net/dcrmg/article/details/102467434
3.修改label_mapping和class_weight
label_mapping需要啥改啥,我就四个标签0,1,2,3...初始权重class_weight需要通过计算得到,计算方法有很多种
4.在_init_.py中导入drug.py
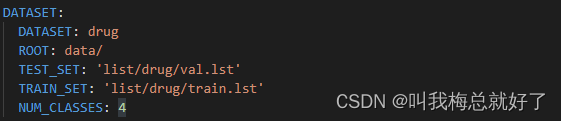
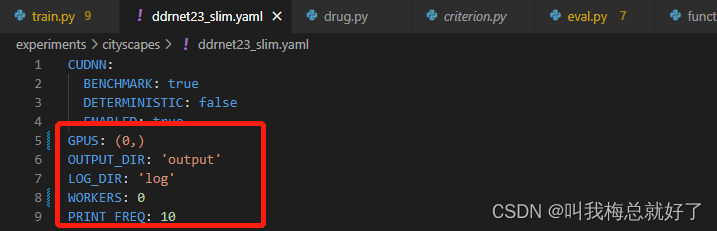
5.打开experiments/cityscapes下的ddrnet23_slim.yaml进行修改:
DATASET是你在data下创建的存放image和label的文件夹,NUM_CLASSES是标签数
根据你的图片大小进行修改,BASE_SIZE我不知道咋搞,但是我改了512没什么问题,就512了,hhhhhh...
如果你的GPU显存不够的话把BATCH_SIZE_PRE_GPU改小吧,我的3060笔记本才6GB的显存
test同理:
6.打开./lib/models/ddrnet_23_slim.py,DualResNet_imagenet函数中的num_classes默认设置成了19,需要修改成自己的:
至此为止,如果你和原文一样有两块GPU的话(原文两块3080),能用DDP的分布式训练的话,应该就能跑了。但很显然,我没有这个条件,还需继续进行修改。





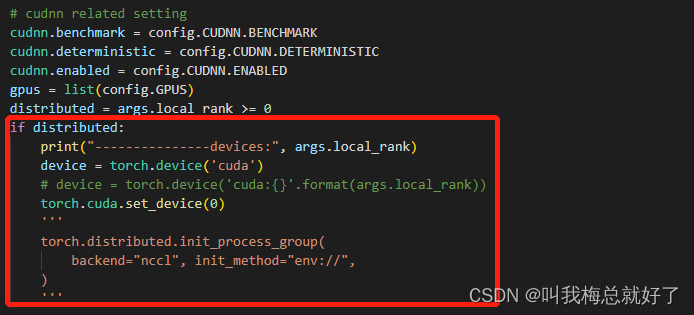
3.修改为单GPU
把train和eval中所有和并行训练的代码注释掉
1.train.py
main()中,注释掉:
else中的并行训练没注释掉,反正也跑不进去
2.eval.py中的并行测试注释掉:
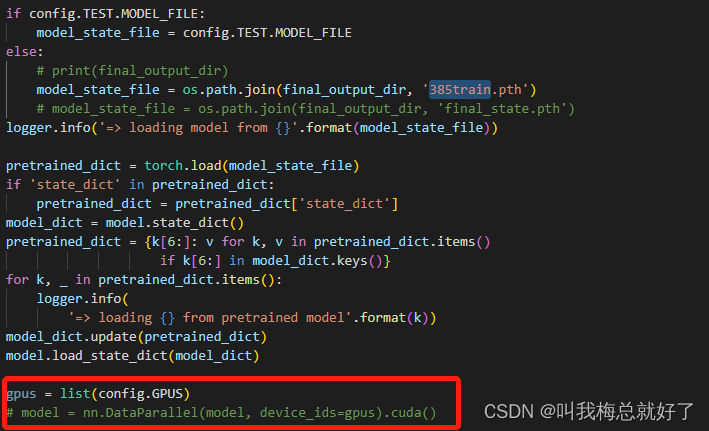
3.ddrnet23_slim.py中
GPUS也可以不用动,反正不并行训练应该也用不上
修改为单GPU好像就这些地方了,可能会漏了一些地方,因为修修改改太多了,有点忘记了,总而言之,把全部和并行训练有关的代码注释掉。

4.训练数据
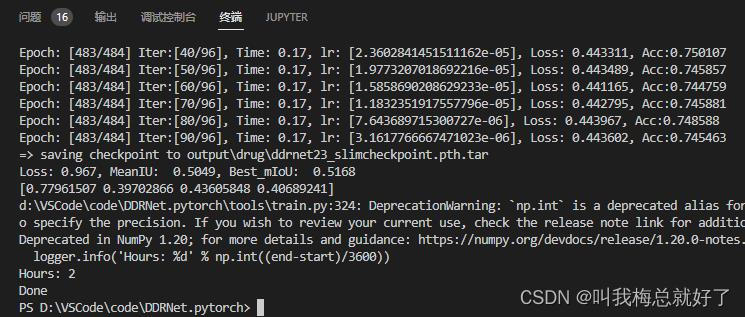
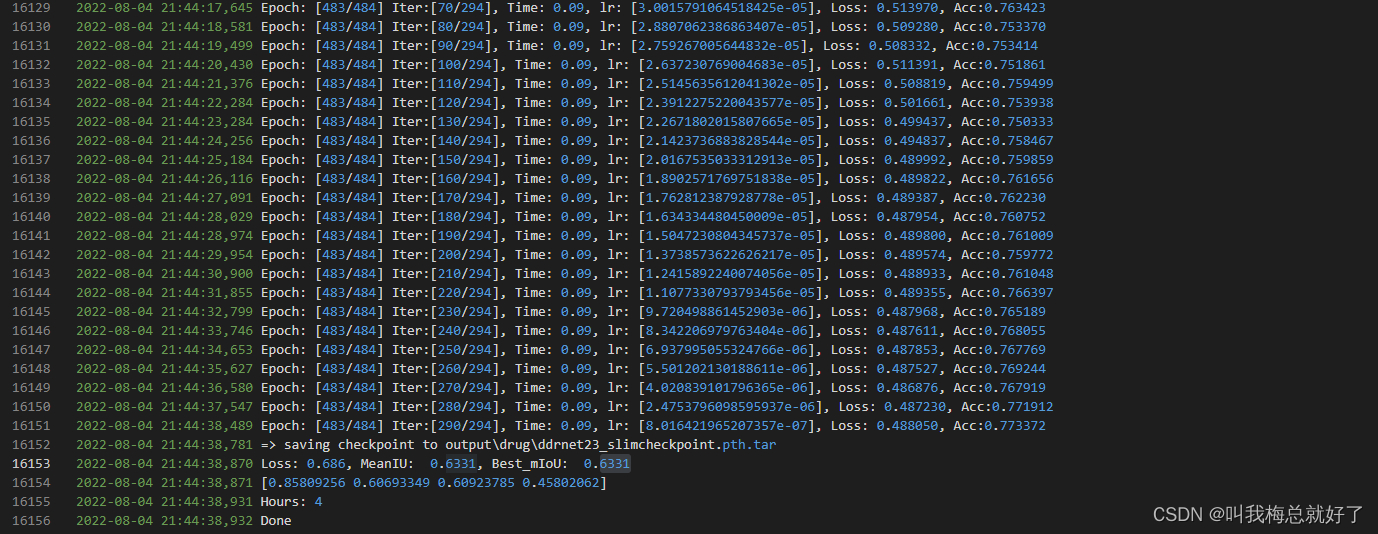
做好上述工作就可以进行训练了,如果你用的不是ddrnet23_slim.yaml,又直接python trian.py的,需要修改train.py中的parse_args()中的默认配置文件。我使用385张图像训练结果如下:
miou才0.51,之前用600张的结果能达到0.63
5.测试数据
5.1 得到测试结果
现在我们获得一个训练好的模型(用自己的数据),这个模型保存在output文件夹中的best.pth.
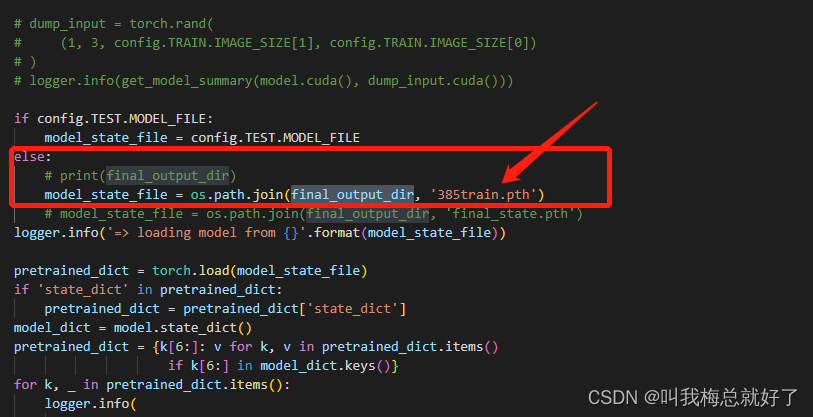
修改best.pth为385train.pth,并修改ddrnet23_slim.py中的预训练模型配置,修改为自己的路径(好像不改也没影响,忘记了,不确定)。
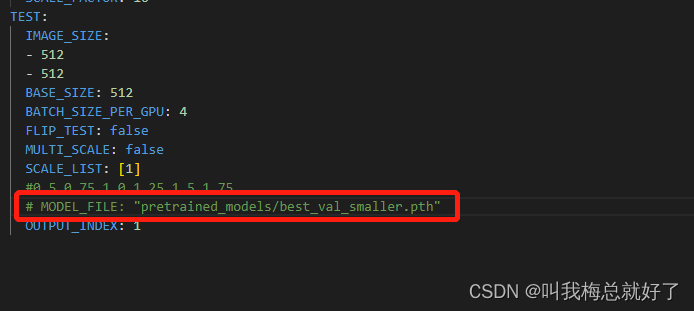
修改eval.py,由于配置文件中的TEST.MODEL_FILE被注释掉了,需要修改者eval.py中的代码:
或者修改配置文件:
如果你不需要输出图像,至此就可以进行测试了,但我需要得到分割后的图像,需要继续修改
5.2 得到测试分割图像
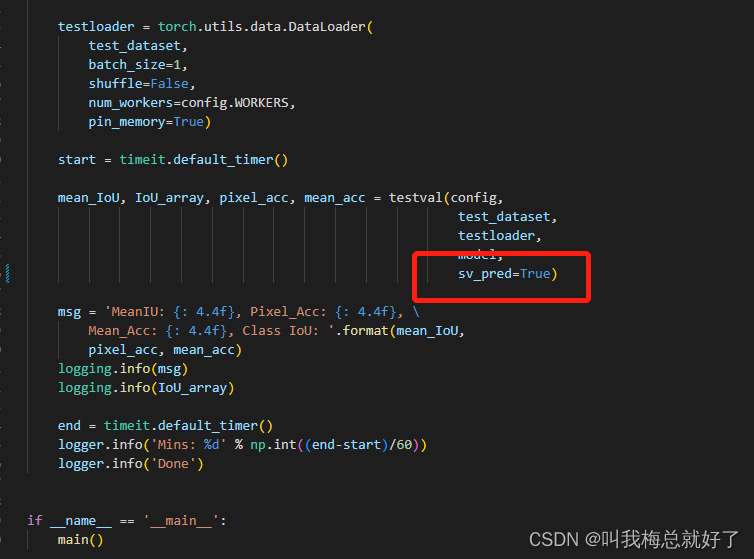
eval中是设置了不保存图像的,我们需要修改成保存图像,将sv_pred设置为True
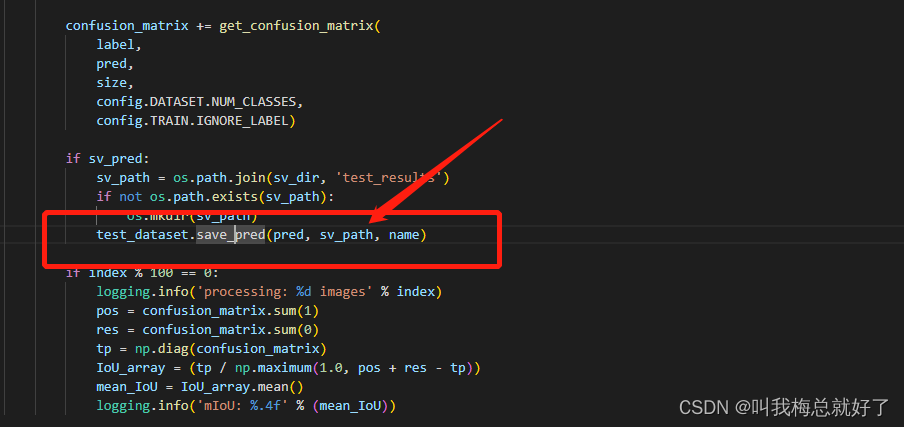
这样还不够,他的testval中的save_pred()多写了一个参数,直接删掉img。
这样你就可以得到分割后的图像了,项目会自动生成一个test_resluts的文件夹,保存了你的分割结果
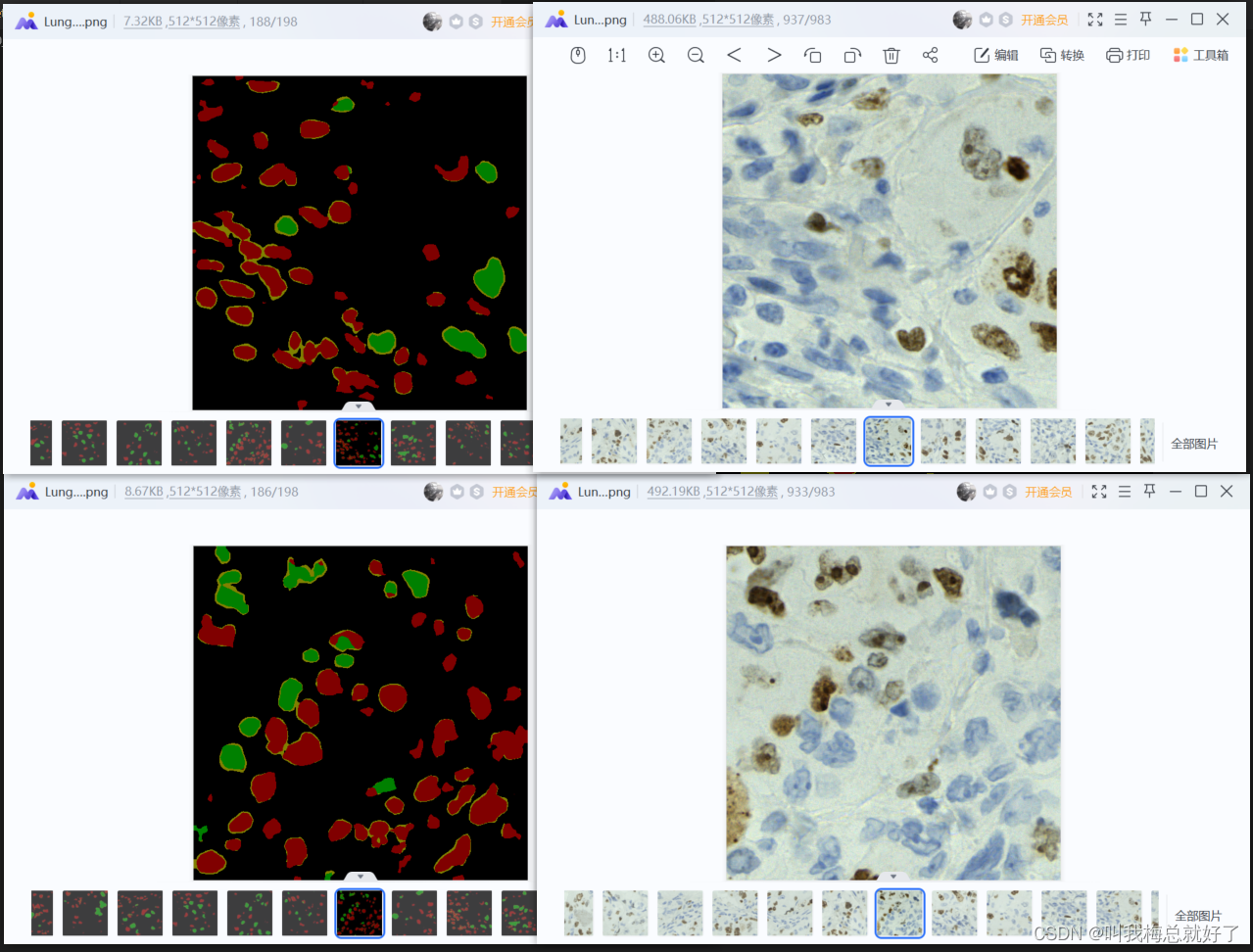
5.3 测试结果
分割图像结果从广度上来看还行,细节上还有些错误,不过我这个数据集用在这个模型上的结果中是相当好。