一.题目要求
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
二.题目难度
中等
三.输入样例
示例 1:
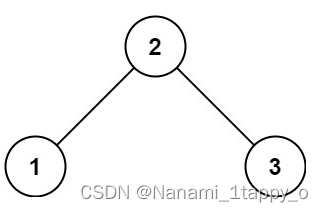
输入:root = [2,1,3]
输出:true
示例 2:
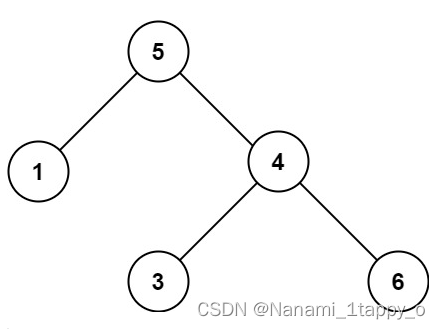
输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
四.解题思路
前中后序列递归都能解,后序的不太好想
五.代码实现
中序
class Solution {
public:
bool isValidBST(TreeNode* root) {
if(!root) return false;
midFind(root);
for(vector<int>::iterator it = ans.begin(); it != ans.end() - 1; it++)
{
if(*it >= *(it + 1)) return false;
}
return true;
}
TreeNode* midFind(TreeNode * root)
{
if(root == nullptr) return nullptr;
midFind(root->left);
ans.push_back(root->val);
midFind(root->right);
return root;
}
private:
vector<int> ans;
};
中序优化后
class Solution {
public:
bool isValidBST(TreeNode* root) {
//首先明确是中序遍历判断二叉搜索树
//中序遍历判断的核心是结点值升序排列
//基于这种情况微操作需要判断当前结点值是否大于前一个结点就行了
//不需要去考虑后面的问题
//基础情况处理
if(root == nullptr) return true;
//超级调用 判断左子树
if(!isValidBST(root->left))
return false;
//微操作 专注处理当前节点
if(pre >= root->val) return false;
else pre = root->val;
//超级调用 判断右子树
if(!isValidBST(root->right))
return false;
return true;
}
private:
long pre = LONG_MIN;
};
前序
class Solution {
public:
bool isValidBST(TreeNode* root) {
//首先明确是前序遍历判断二叉搜索树
//前序遍历判断的核心是结点值比左子树允许范围最大值大,比右子树允许范围最小值小
//基于这种情况微操作需要判断当前结点值和左右结点
return validate(root, LONG_MIN, LONG_MAX);
}
bool validate(TreeNode* node ,long min ,long max)
{
//基础情况处理
if(node == nullptr) return true;
//微操作 专注处理当前节点
if(min >= node->val || max <= node->val) return false;
//超级操作 判断左子树
if(!validate(node->left, min, node->val)) return false;
//超级操作 判断右子树
if(!validate(node->right, node->val, max)) return false;
return true;
}
};
后序
GPT解法
class Solution {
public:
struct ResultType {
bool isBST;
long long minVal, maxVal;
ResultType(bool isBST, long long minVal, long long maxVal) : isBST(isBST), minVal(minVal), maxVal(maxVal) {}
};
bool isValidBST(TreeNode* root) {
ResultType result = validateBST(root);
return result.isBST;
}
private:
ResultType validateBST(TreeNode* node) {
// 空节点视为合法BST
if (!node) return ResultType(true, LONG_MAX, LONG_MIN);
// 分别验证左右子树
ResultType left = validateBST(node->left);
ResultType right = validateBST(node->right);
// 如果左右子树都是BST,且当前节点大于左子树最大值,小于右子树最小值,则当前子树是BST
if (left.isBST && right.isBST && node->val > left.maxVal && node->val < right.minVal) {
return ResultType(true,
min((long long)node->val, left.minVal), // 更新当前子树的最小值
max((long long)node->val, right.maxVal)); // 更新当前子树的最大值
} else {
return ResultType(false, 0, 0);
}
}
};
六.题目总结
递归问题分解
1. 递归函数定义
明确函数的使命:这是设计递归函数的第一步,你需要清楚地知道这个函数要做什么,它的输入和输出是什么。
明确原问题与子问题:在递归的上下文中,需要识别如何将原始问题分解为更小的、可通过相同处理方式解决的子问题。
兼顾原问题与子问题:在设计递归时,要保证处理子问题的方式同样适用于原问题,这保证了递归的一致性和可行性。
2. 基础情况处理
数据规模较小时直接返回答案:这是递归的终止条件,也称为基案(base case)。没有这个条件,递归将无限循环下去。通常是当问题规模缩小到一个非常简单的程度时,可以直接给出答案。
3. 递归调用
超级操作:这一步涉及对子问题进行递归调用。
看成整体,忽略细节:这意味着当你调用递归函数时,不需要关心它是如何实现的。你只需“相信”递归调用能正确解决子问题。
相信递归调用:这是递归中的“信任步骤”。你要相信每次递归调用都能正确地向基案逼近,并最终得到正确答案。
4. 递推到当前层
计微操作:在完成了对子问题的递归调用后,你可能需要根据子问题的结果来计算当前问题的结果。这通常涉及到一些额外的处理,以将子问题的解逐步“递推”回原问题的解。
class Solution {
public:
bool isValidBST(TreeNode* root) {
if(root == nullptr) return true;
if(!isValidBST(root->left) || root->val <= pre)
return false;
pre = root->val;
return isValidBST(root->right);
}
根据提出的四个部分来分析这段代码:
- 递归函数定义
明确函数的使命:判断以root为根的树是否是一个有效的二叉搜索树。
明确原问题与子问题:原问题是判断整棵树是否是二叉搜索树,子问题是判断左子树和右子树是否是二叉搜索树。
兼顾原问题与子问题:如果一个节点的左子树和右子树都是二叉搜索树,并且该节点的值大于左子树中所有节点的值且小于右子树中所有节点的值,那么以该节点为根的树也是二叉搜索树。 - 基础情况处理
数据规模较小时直接返回答案:当root为空时,按照二叉搜索树的定义,空树也是一个有效的二叉搜索树,因此直接返回true。 - 递归调用
超级操作:代码通过递归调用isValidBST(root->left)和isValidBST(root->right)来分别检查左右子树。
看成整体,忽略细节:在检查左子树和右子树时,我们不需要关心它们是如何实现的,只需要相信isValidBST函数能够正确判断子树是否为二叉搜索树。 - 递推到当前层
计微操作:在中序遍历的过程中,pre变量用于记录前一个访问的节点的值。对于当前的节点,如果它的值小于等于pre的值,则不满足二叉搜索树的定义,应该返回false。如果当前节点的左子树是二叉搜索树,并且当前节点的值大于pre的值,那么更新pre为当前节点的值,并继续检查右子树。
这段代码中缺少了pre变量的初始化和声明,通常pre应该是一个长整型变量,并且在使用中序遍历之前被初始化为一个最小值(或者使用long long的最小值,或者设置为nullptr并在逻辑中适当处理)。这样可以确保第一个节点的值大于pre。此外,pre需要被定义在递归函数外部或作为参数传递,以保持其在递归调用中的连续性。
递归解题核心其实是明确微操作要干什么,即从n推到n+1的过程
本文含有隐藏内容,请 开通VIP 后查看