1. 简介
单类支持向量机,简称One-Class SVM(One-Class Support Vector Machine),用于异常检测和离群点检测(无监督学习,其他svm属于有监督的),可以在没有大量异常样本的情况下有效地检测异常。其目标是通过仅使用正常数据来建模,识别出与正常模式不同的异常数据点。其在处理高维数据和非常稀疏的异常检测问题时非常有用。
严格来说,OCSVM不是一种outlier detection,而是一种奇异点检测(novelty detection)方法:它的训练集不应该掺杂异常点,因为模型可能会去匹配这些异常点。但在数据维度很高,或者对相关数据分布没有任何假设的情况下,OCSVM也可以用于outlier detection。
1. novelty detection: 当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本;
2. outlier detection: 当训练数据中包含离群点,模型训练时要匹配训练数据的中心样本,忽视训练样本中的其他异常点。
在one-class classification中,仅仅只有一类的信息是可以用于训练,其他类别的(总称outlier)信息是缺失的,也就是区分两个类别的边界线是通过仅有的一类数据的信息学习得到的。对比与有正负样例的二分类SVM,OCSVM可以训练出一个高维超球面,把数据尽可能紧的包围起来。二分类不但能识别是否为目标类别,还能输出样本具体类别;而单分类只需判断是否为目标类别即可。
2. 基本原理
算法思路:
就是寻找一个超平面将样本中的正例圈出来(该超平面将正常样本和异常样本分隔开),预测就是用这个超平面做决策,在圈内的样本就认为是正样本。这个超平面被称为“分割超平面”,并且由支持向量支持,即最靠近分割超平面的正常样本点。
具体算法描述:
没有类别标签,如何寻找划分的超平面以及寻找支持向量机呢?一种特别的思想SVDD,我们期望所有不是异常的样本都是正类别,同时它采用一个超球体而不是一个超平面来做划分,该算法在特征空间中获得数据周围的球形边界,期望最小化这个超球体的体积,从而最小化异常点数据的影响。
它通过构造原点与单类训练数据之间的超平面,进而可以判断测试数据与单类训练数据之间相似与否,如果测试集数据与单类训练数据相似,则可以将其归为相似样本,记为1,如果测试集数据与单类训练集数据不相似,则记为-1。由于其可以通过超平面的构建,发现待预测数据与训练集数据“相似与否”,进而该模型可以用作异常点检测。
1. 数据映射 -- 核函数
OCSVM使用核函数来将数据映射到高维空间。常用的核函数包括线性核、多项式核和高斯核。这些核函数允许OCSVM在原始特征空间中找到非线性分割超平面。但由于核函数计算比较耗时,数据量较大时不太适用。
2. 寻找最优超平面
其目标是找到一个分割超平面(通过最大化超平面与正常数据之间的间隔),使得正常数据点能够被该超平面所包围(正常样本远离该超平面,而异常样本尽可能接近),这个超平面被称为决策边界。这个分割超平面的法向量和距离到原点的距离是训练过程中优化的参数。
支持向量是离分割超平面最近的正常样本点,它们决定了分割超平面的位置和方向。在训练过程中,OCSVM会选择最优的支持向量,以使分割超平面最大化远离正常样本。
3. 异常检测
对于新的数据点,通过计算其与超平面的距离,来判断该数据点是否为异常。距离较大的数据点更有可能是异常点。
4. 总结
OCSVM的关键在于如何选择合适的超平面,以使得正常数据被尽可能包围,而异常数据则被远离。这是通过优化一个目标函数来实现的,其中包括最小化超平面到最近正常数据点的距离和最大化超平面与正常数据之间的间隔。
3. 应用场景
在异常检测领域有广泛的应用:
1. 网络安全
检测网络中的异常行为,如入侵检测。它可以识别与正常网络流量不同的异常流量模式,从而提高网络安全性。
2. 金融欺诈检测
检测信用卡欺诈、异常交易和洗钱行为。它可以识别与正常交易模式不符的异常交易。
3. 工业制造
监测工业制造中的设备异常和故障。它可以帮助预测设备可能出现的问题,从而减少停机时间和维修成本。
4. 医疗诊断
检测医疗图像中的异常,如肿瘤、病变和异常组织。它有助于提高医学诊断的准确性。
4. 异常检测实践
sklearn提供了一些ML方法,其中OCSVM可以用于Novelty Dection(奇异点检测);IF(Isolation Forest),LOF(Local Outlier Factor)可用于Outlier Detection(异常点检测)。
4.1 API简介
1. 构造函数
oneClassSvm(cacheSize = 100, kernel = rbfKernel(), epsilon = 0.001,
nu = 0.1, shrink = TRUE, ...)(1)kernel:用于计算样本之间相似度的核函数
1. 径向基础函数内核
rbfKernel();2. 线性内核
linearKernel();3. 多项式内核
polynomialKernel();4. Sigmoid 内核
sigmoidKernel();
(2)nu:限制了在模型中允许存在的异常点的比例,默认值为 0.1。其值必须介于 0 和 1 之间,通常介于 0.1 和 0.5 之间。
(3)epsilon:优化器收敛的阈值,默认值为 0.001。 如果迭代间的改进小于阈值,则算法将停止并返回当前模型。
(4)cacheSize:存储训练数据的缓存的最大大小, 默认值为 100 MB。
(5)shrink:默认值是 TRUE,表示使用缩减启发式。 在这种情况下,某些样本将在训练过程中“缩减”,这可能会加快训练速度 。
2. 其他
(1)fit(X):训练,根据训练样本和上面两个参数探测边界;(注意是无监督)
(2)predict(X):返回预测值(+1:正常样本,-1:异常样本);
(3)fit_predict(X[, y]):在X上执行拟合并返回X的标签;
(4)decision_function(X):返回各样本点到超平面的函数距离(signed distance),正的为正常样本,负的为异常样本。
(5)set_params(**params):设置评估器的参数;
(6)get_params([deep]):获取评估器的参数。
4.2 demo
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
rng = np.random.RandomState(42)
X = 0.3 * rng.randn(200, 2) # 正常样本
X_train = np.r_[X + 2, X - 2]
X_test = np.r_[rng.uniform(low=-6, high=6, size=(50, 2))] # 异常样本
model = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
model.fit(X_train)
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
# n_error_train = y_pred_train[y_pred_train == -1].size # 训练集异常样本个数
# 绘制训练样本和测试样本的散点图
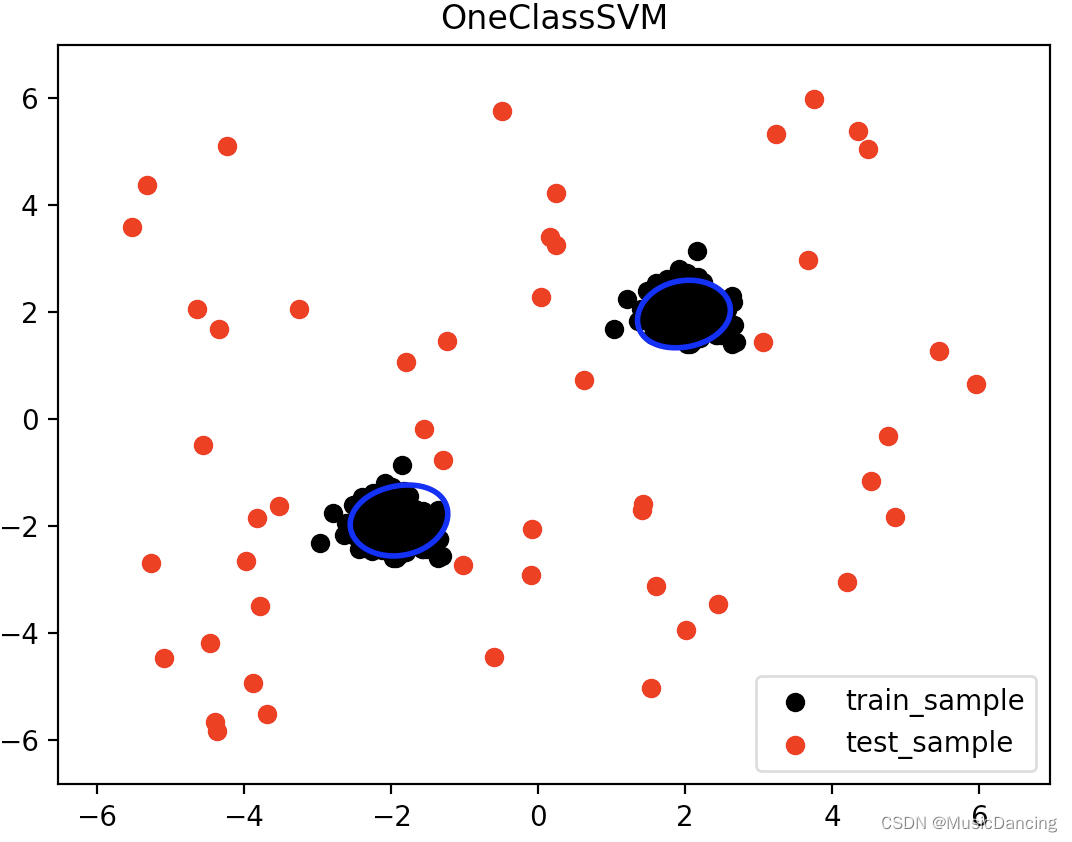
plt.scatter(X_train[:, 0], X_train[:, 1], color='black', label='train_sample')
plt.scatter(X_test[:, 0], X_test[:, 1], color='red', label='test_sample')
# 绘制异常样本的边界
xmin, xmax = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
ymin, ymax = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(xmin, xmax, 500), np.linspace(ymin, ymax, 500))
Z = model.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='blue')
# 设置图形标题和图例
plt.title("OneClassSVM")
plt.legend()
plt.show()模型将正常样本点标记为1,异常样本点标记为-1,并将它们可视化出来。
5. 优缺点
5.1 优点
1. 不需要异常数据进行训练,只需要正常数据即可;
2. 对于高维数据和复杂的数据分布具有较好的适应性;
3. 可以通过调整模型参数来控制异常点的检测灵敏度。
5.2 缺点
1. 在处理高维数据和大规模数据时,计算复杂度较高;
2. 对于数据分布不均匀或存在噪声的情况,效果可能不理想;
3. 需要谨慎选择模型参数,以避免过拟合或欠拟合的情况。