Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting
Pixel-GS:用于3D高斯溅射的具有像素感知梯度的密度控制
老宜兴市郑张文博胡 †
Tong He Hengshuang Zhao†
赵同和恒双 †1122113311
Abstract 摘要 [2403.15530] Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting
3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis results while advancing real-time rendering performance. However, its efficacy heavily relies on the quality of the initial point cloud, leading to blurring and needle-like artifacts in regions with inadequate initializing points. This issue is mainly due to the point cloud growth condition, which only considers the average gradient magnitude of points from observable views, thereby failing to grow for large Gaussians that are observable for many viewpoints while many of them are only covered in the boundaries. To address this, we introduce Pixel-GS, a novel approach to take into account the number of pixels covered by the Gaussian in each view during the computation of the growth condition. We regard the covered pixel numbers as the weights to dynamically average the gradients from different views, such that the growth of large Gaussians can be prompted. As a result, points within the areas with insufficient initializing points can be grown more effectively, leading to a more accurate and detailed reconstruction. In addition, we propose a simple yet effective strategy to scale the gradient field according to the distance to the camera, to suppress the growth of floaters near the camera. Extensive qualitative and quantitative experiments confirm that our method achieves state-of-the-art rendering quality while maintaining real-time speeds, outperforming on challenging datasets such as Mip-NeRF 360 and Tanks & Temples. Code and demo are available at: https://pixelgs.github.io
3D高斯溅射(3DGS)已经展示了令人印象深刻的新颖的视图合成结果,同时提高了实时渲染性能。然而,它的有效性严重依赖于初始点云的质量,导致在初始化点不足的区域中出现模糊和针状伪影。这个问题主要是由于点云增长条件,它只考虑来自可观察视图的点的平均梯度幅度,从而无法增长对于许多视点可观察的大高斯,而其中许多仅覆盖在边界中。为了解决这个问题,我们引入了Pixel-GS,这是一种新的方法,可以在计算生长条件的过程中考虑每个视图中高斯覆盖的像素数量。我们将覆盖像素数作为权重,动态平均来自不同视图的梯度,从而可以促进大高斯的增长。 结果,可以更有效地生长初始化点不足的区域内的点,从而导致更准确和详细的重建。此外,我们提出了一个简单而有效的策略,根据到相机的距离来缩放梯度场,以抑制相机附近漂浮物的增长。大量的定性和定量实验证实,我们的方法实现了最先进的渲染质量,同时保持实时速度,在具有挑战性的数据集,如Mip-NeRF 360和坦克和寺庙。代码和演示可在:https://pixelgs.github。io
Keywords:
View Synthesis Point-based Radiance Field Read-time Rendering 3D Gaussian Splatting Adaptive Density Control关键词:视图合成基于点的辐射场实时绘制三维高斯溅射自适应密度控制
††Corresponding author.
† 通讯作者。
1Introduction 1介绍
Novel View Synthesis (NVS) is a fundamental problem in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) [21] has drawn increasing attention for its explicit point-based representation of 3D scenes and real-time rendering performance.
新视图合成是计算机视觉和图形学中的一个基本问题。最近,3D高斯溅射(3DGS)[ 21]因其显式的基于点的3D场景表示和实时渲染性能而受到越来越多的关注。
|
|
|
|
|
|
|
|
| (a) Ground Truth (a)地面实况 | (b) 3DGS∗ (original threshold) (b)3DGS(原始阈值) |
(c) 3DGS∗ (lower threshold) (c)3DGS(低阈值) |
(d) Pixel-GS (Ours) (d)Pixel-GS(我们的) |








To convert b to d, adjust densification from ∑‖𝐠‖∑1>�pos to ∑pixel⋅‖𝐠‖∑pixel>�pos.
为了将B转换为d,将致密化从 ∑‖𝐠‖∑1>�pos 调整为 ∑pixel⋅‖𝐠‖∑pixel>�pos 。
Figure 1: Our Pixel-GS effectively grows points in areas with insufficient initializing points (a), leading to a more accurate and detailed reconstruction (d). In contrast, 3D Gaussian Splatting (3DGS) suffers from blurring and needle-like artifacts in these areas, even with a lower threshold of splitting and cloning to encourage more grown points (c). The rendering quality (in LPIPS ↓) and memory consumption are shown in the results. 3DGS∗ is our retrained 3DGS model with better performance.
图一:我们的Pixel-GS有效地在初始化点不足的区域中增加点(a),从而实现更准确和详细的重建(d)。相比之下,3D高斯溅射(3DGS)在这些区域中遭受模糊和针状伪影,即使具有较低的分裂和克隆阈值以鼓励更多的生长点(c)。渲染质量(以LPIPS ↓ 为单位)和内存消耗将显示在结果中。3DGS ∗ 是我们重新训练的3DGS模型,具有更好的性能。
3DGS represents the scene as a set of points associated with geometry (Gaussian scales) and appearance (opacities and colors) attributes. These attributes can be effectively learned by the differentiable rendering, while the optimization of the point cloud’s density is challenging. 3DGS carefully initializes the point cloud using the sparse points produced by the Structure from Motion (SfM) process and presents an adaptive density control mechanism to split or clone the points during the optimization process. However, this mechanism relies heavily on the initial point cloud’s quality and cannot effectively grow points in areas where the initial point cloud is sparse, resulting in blurry or needle-like artifacts in the synthesized images. In practice, the initial point cloud from SfM unavoidably suffers from insufficient points in areas with repetitive textures and few observations. As shown in the first and second columns of Figure 1, the blurry regions in the RGB images are well aligned with the areas where few points are initialized, and 3DGS fails to generate enough points in these areas.
3DGS将场景表示为与几何体(高斯比例)和外观(不透明度和颜色)属性相关联的一组点。这些属性可以通过可微绘制有效地学习,而点云密度的优化是具有挑战性的。3DGS使用由运动恢复结构(SfM)过程产生的稀疏点仔细地对点云进行优化,并提出了一种自适应密度控制机制来在优化过程中分割或克隆点。然而,这种机制严重依赖于初始点云的质量,并且不能有效地在初始点云稀疏的区域中生长点,从而导致合成图像中的模糊或针状伪影。在实践中,来自SfM的初始点云必然会在具有重复纹理和很少观测的区域中遭受点不足的问题。 如图1的第一列和第二列所示,RGB图像中的模糊区域与初始化很少的点的区域对齐良好,并且3DGS无法在这些区域中生成足够的点。
In essence, this issue is mainly attributed to the condition of when to split or clone a point. 3DGS decides it by checking whether the average gradient magnitude of the points in the Normalized Device Coordinates (NDC) is larger than a threshold. The magnitude of the gradient is equally averaged across different viewpoints, and the threshold is fixed. Large Gaussians are usually visible in many viewpoints, and the size of their projection area varies significantly across views, leading to the number of pixels involved in the gradient calculation varies significantly. According to the mathematical form of the Gaussian distribution, a few pixels near the center of the projected Gaussian contribute much more to the gradient than the pixels far away from the center. Larger Gaussians often have many viewpoints where the area near the projected center point is not within the screen space, thereby lowering the average gradient, making them difficult to split or clone. This issue cannot be solved by merely lowering the threshold, as it would more likely encourage growing points in areas with sufficient points, as shown in the third column of Figure 1, still leaving blurry artifacts in the areas with insufficient points.
从本质上讲,这个问题主要归因于何时分割或克隆一个点的条件。3DGS通过检查归一化设备坐标(NDC)中的点的平均梯度幅度是否大于阈值来决定它。梯度的大小在不同视点之间相等地平均,并且阈值是固定的。大高斯通常在许多视点中可见,并且它们的投影区域的大小在视图之间变化很大,导致梯度计算中涉及的像素数量变化很大。根据高斯分布的数学形式,靠近投影高斯中心的几个像素比远离中心的像素对梯度的贡献大得多。较大的高斯曲线通常有许多视点,其中投影中心点附近的区域不在屏幕空间内,从而降低了平均梯度,使其难以分割或克隆。 这个问题不能仅仅通过降低阈值来解决,因为它更可能鼓励在具有足够点的区域中的增长点,如图1的第三列所示,仍然在具有不足点的区域中留下模糊伪影。
In this paper, we propose to consider the calculation of the mean gradient magnitude of points from the perspective of pixels. During the computation of the average gradient magnitude for a Gaussian, we take into account the number of pixels covered by the Gaussian in each view by replacing the averaging across views with the weighted average across views by the number of covered pixels. The motivation behind this is to amplify the gradient contribution of large Gaussians while leaving the conditions for splitting or cloning small Gaussians unchanged, such that we can effectively grow points in the areas with large Gaussians. In the meanwhile, for small Gaussians, the weighted average only slightly impacts the final gradient since the variation of covered pixel numbers across different viewpoints is minimal. Therefore, the final number of points in areas with sufficient initial points would not change significantly to avoid unnecessary memory consumption and processing time, but importantly, points in areas with insufficient initial points can be effectively grown to reconstruct fine-grained details. As shown in the last column of Figure 1, our method effectively grows points in areas with insufficient initial points and renders high-fidelity images, while directly lowering the threshold in 3DGS to maintain a similar number of final points fails to render blurring-free results. Besides, we observe that “floaters” tend to appear near the camera, which are points that are not well aligned with the scene geometry and are not contributing to the final rendering. To this end, we propose to scale the gradient field in NDC space according to the depth value of the points, thereby suppressing the growth of “floaters” near the camera.
在本文中,我们建议考虑从像素的角度计算点的平均梯度幅度。在高斯平均梯度幅度的计算过程中,我们考虑到每个视图中高斯覆盖的像素数量,通过将视图间的平均值替换为覆盖像素数量的视图间的加权平均值。这背后的动机是放大大高斯的梯度贡献,同时保持分裂或克隆小高斯的条件不变,这样我们就可以在具有大高斯的区域中有效地增长点。同时,对于小高斯,加权平均值仅轻微影响最终梯度,因为不同视点之间覆盖像素数量的变化是最小的。 因此,具有足够初始点的区域中的点的最终数目不会显著改变以避免不必要的存储器消耗和处理时间,但重要的是,具有不足够初始点的区域中的点可以有效地增长以重构细粒度细节。如图1的最后一列所示,我们的方法有效地在初始点不足的区域中增加点并渲染高保真图像,而直接降低3DGS中的阈值以保持类似数量的最终点无法渲染无模糊的结果。此外,我们观察到,“浮动”往往出现在相机附近,这是点,没有很好地与场景几何对齐,并没有贡献的最终渲染。为此,我们建议根据点的深度值来缩放NDC空间中的梯度场,从而抑制相机附近的“漂浮物”的增长。
To evaluate the effectiveness of our method, we conducted extensive experiments on the challenging Mip-NeRF 360 [3] and Tanks & Temples [22] datasets. Experimental results validate that our method consistently outperforms the original 3DGS, both quantitatively (17.8% improvement in terms of LPIPS) and qualitatively. We also demonstrate that our method is more robust to the sparsity of the initial point cloud by manually discarding a certain proportion (up to 99%) of the initial SfM point clouds. In summary, we make the following contributions:
为了评估我们方法的有效性,我们对具有挑战性的Mip-NeRF 360 [ 3]和Tanks & Temples [ 22]数据集进行了广泛的实验。实验结果验证了我们的方法始终优于原来的3DGS,无论是定量(17.8%的LPIPS方面的改善)和定性。我们还证明了我们的方法是更强大的初始点云的稀疏手动丢弃一定比例(高达99%)的初始SfM点云。总之,我们做出了以下贡献:
- –
We analyzed the reason for the blurry artifacts in 3DGS and propose to optimize the number of points from the perspective of pixels, thereby enabling effectively growing points in areas with insufficient initial points.
- 我们分析了3DGS中模糊伪影的原因,并建议从像素的角度优化点的数量,从而在初始点不足的区域中有效地增长点。 - –
We present a simple yet effective gradient scaling strategy to suppress the “floater” artifacts near the camera.
- 我们提出了一个简单而有效的梯度缩放策略,以抑制相机附近的“浮动”伪影。 - –
Our method achieves state-of-the-art performance on the challenging Mip-NeRF 360 and Tanks & Temples datasets and is more robust to the quality of initial points.
- 我们的方法在具有挑战性的Mip-NeRF 360和Tanks & Temples数据集上实现了最先进的性能,并且对初始点的质量更具鲁棒性。
2Related Work 2相关工作
Novel view synthesis. The task of novel view synthesis refers to the process of generating images from perspectives different from the original input viewpoints. Recently, NeRF [35] has achieved impressive results in novel view synthesis by using neural networks to approximate the radiance field and employing volumetric rendering [10, 27, 32, 33] techniques for rendering. These approaches use implicit functions (such as MLPs [35, 2, 3], feature grid-based representations [6, 13, 29, 37, 46], or feature point-based representations [21, 50]) to fit the scene’s radiance field and utilize a rendering formula for rendering. Due to the requirement to process each sampled point along a ray through an MLP to obtain its density and color, during the volume rendering, these works significantly suffer from low rendering speed. Subsequent methods [15, 41, 42, 56, 58] have refined a pre-trained NeRF into a sparse representation, thus achieving real-time rendering of NeRF. Although some advanced scene representations [6, 7, 13, 29, 25, 37, 46, 2, 3, 4, 16] have been proposed to improve one or more aspects of NeRF, such as training cost, rendering results, and rendering speed, 3D Gaussian Splatting (3DGS) [21] still draws increasing attention due to its explicit representation, high-fidelity results, and real-time rendering speed. Some subsequent works on 3DGS have further improved it from perspectives such as anti-aliasing [59, 51], reducing memory usage [12, 39, 38, 26, 36, 30], replacing spherical harmonics functions to enhance the modeling capability of high-frequency signals based on reflective surfaces [54], and modeling dynamic scenes [31, 55, 11, 49, 53, 20, 24, 17]. However, 3DGS still tends to exhibit blurring and needle-like artifacts in areas where the initial points are sparse. This is because 3DGS initializes the scale of each Gaussian based on the distance to neighboring Gaussians, making it challenging for the point cloud growth mechanism of 3DGS to generate sufficient points to accurately model these areas.
新颖的视图合成。新视角合成的任务是指从不同于原始输入视点的视角生成图像的过程。最近,NeRF [ 35]通过使用神经网络来近似辐射场并采用体积渲染[ 10,27,32,33]技术进行渲染,在新颖的视图合成中取得了令人印象深刻的结果。这些方法使用隐式函数(例如MLP [35,2,3],基于特征网格的表示[6,13,29,37,46]或基于特征点的表示[21,50])来拟合场景的辐射场并利用渲染公式进行渲染。由于体绘制过程中需要对沿着穿过MLP的射线上的每个采样点进行处理以获得其密度和颜色,因此这些工作的绘制速度明显较低。随后的方法[15,41,42,56,58]将预先训练的NeRF细化为稀疏表示,从而实现NeRF的实时渲染。 尽管已经提出了一些先进的场景表示[6,7,13,29,25,37,46,2,3,4,16]来改善NeRF的一个或多个方面,例如训练成本,渲染结果和渲染速度,但3D高斯飞溅(3DGS)[ 21]仍然由于其显式表示,高保真度结果,和实时渲染速度。3DGS的一些后续工作从抗混叠[ 59,51],减少内存使用[ 12,39,38,26,36,30],替换球谐函数以增强基于反射表面的高频信号的建模能力[ 54],以及建模动态场景[ 31,55,11,49,53、20、24、17]。然而,3DGS仍然倾向于在初始点稀疏的区域中表现出模糊和针状伪影。 这是因为3DGS基于与相邻高斯的距离来调整每个高斯的尺度,使得3DGS的点云增长机制难以生成足够的点来准确地对这些区域进行建模。
Point-based radiance field. Point-based representations (such as point clouds) commonly represent scenes using fixed-size, unstructured points, and are rendered by rasterization using GPUs [5, 43, 45]. Although this is a simple and convenient solution to address topological changes, it often results in holes or outliers, leading to artifacts during rendering. To mitigate issues of discontinuity, researchers have proposed differentiable rendering based on points, utilizing points to model local domains [14, 18, 28, 57, 50, 21, 48]. Among these approaches, [1, 23] employs neural networks to represent point features and utilizes 2D CNNs for rendering. Point-NeRF [50] models 3D scenes using neural 3D points and presents strategies for pruning and growing points to repair common holes and outliers in point-based radiance fields. 3DGS [21] renders using a rasterization approach, which significantly speeds up the rendering process. It starts with a sparse point cloud initialization from SfM and fits each point’s influence area and color features using three-dimensional Gaussian distributions and spherical harmonics functions, respectively. To enhance the representational capability of this point-based spatial function, 3DGS introduces a density control mechanism based on the gradient of each point’s NDC (Normalized Device Coordinates) coordinates and opacity, managing the growth and elimination of the point cloud. Recent work [8] on 3DGS has improved the point cloud growth process by incorporating depth and normals to enhance the fitting ability in low-texture areas. In contrast, our Pixel-GS does not require any additional priors or information resources, e.g. depths and normals, and can directly grow points in areas with insufficient initializing points, reducing blurring and needle-like artifacts.
基于点的辐射场。基于点的表示(如点云)通常使用固定大小的非结构化点表示场景,并使用GPU通过光栅化渲染[ 5,43,45]。虽然这是解决拓扑变化的一种简单方便的解决方案,但它通常会导致空洞或离群值,从而导致渲染过程中出现伪影。为了减轻不连续性的问题,研究人员提出了基于点的可微分渲染,利用点来建模局部域[ 14,18,28,57,50,21,48]。在这些方法中,[ 1,23]采用神经网络来表示点特征,并利用2D CNN进行渲染。Point-NeRF [ 50]使用神经3D点对3D场景进行建模,并提出了修剪和生长点的策略,以修复基于点的辐射场中的常见孔和离群值。3DGS [ 21]使用光栅化方法进行渲染,这显着加快了渲染过程。 它从SfM的稀疏点云初始化开始,分别使用三维高斯分布和球谐函数拟合每个点的影响区域和颜色特征。为了增强这种基于点的空间函数的表示能力,3DGS引入了一种基于每个点的NDC(归一化设备坐标)坐标梯度和不透明度的密度控制机制,管理点云的增长和消除。最近的3DGS工作[ 8]通过结合深度和法线来提高低纹理区域的拟合能力,从而改进了点云生长过程。相比之下,我们的Pixel-GS不需要任何额外的先验或信息资源,例如深度和法线,并且可以在初始化点不足的区域中直接生长点,减少模糊和针状伪影。
Floater artifacts. Most radiance field scene representation methods encounter floater artifacts, which predominantly appear near the camera and are more severe with sparse input views. Some papers [44, 9] address floaters by introducing depth priors. NeRFshop [19] proposes an editing method to remove floaters. Mip-NeRF 360 [3] introduces a distortion loss by adding a prior that the density distribution along each ray is unimodal, effectively reducing floaters near the camera. NeRF in the Dark [34] suggests a variance loss of weights to decrease floaters. FreeNeRF [52] introduces a penalty term for the density of points close to the camera as a loss to reduce floaters near the camera. Most of these methods suppress floaters by incorporating priors through loss or editing methods, while “Floaters No More” [40] attempts to explore the fundamental reason for the occurrence of floaters and points out that floaters primarily arise because, for two regions of the same volume and shape, the number of pixels involved in the computation is proportional to the inverse square of each region’s distance from the camera. Under the same learning rate, areas close to the camera rapidly complete optimization and, after optimization, block the optimization of areas behind them, leading to an increased likelihood of floaters near the camera. Our method is inspired by this analysis and deals with floaters by a simple yet effective strategy, i.e., scaling the gradient field by the distance to the camera.
浮尸藏物。大多数辐射场场景表示方法遇到漂浮物伪影,主要出现在相机附近,并且在稀疏输入视图中更严重。一些论文[ 44,9]通过引入深度先验来解决浮动。NeRFshop [ 19]提出了一种编辑方法来删除浮动项。Mip-NeRF 360 [ 3]通过添加一个先验来引入失真损失,即沿沿着每条射线的密度分布是单峰的,从而有效地减少了相机附近的漂浮物。NeRF在黑暗中[ 34]建议方差损失的重量,以减少浮动。FreeNeRF [ 52]引入了一个惩罚项,用于接近摄像机的点的密度,作为减少摄像机附近漂浮物的损失。 这些方法中的大多数通过丢失或编辑方法合并先验来抑制浮动,而“Floaters No More”[ 40]试图探索浮动发生的根本原因,并指出浮动主要是因为,对于相同体积和形状的两个区域,计算中涉及的像素数量与每个区域到相机的距离的平方成反比。在相同的学习率下,靠近摄像头的区域快速完成优化,优化后会阻碍后面区域的优化,导致摄像头附近出现飞蚊的可能性增加。我们的方法受到这种分析的启发,并通过一种简单而有效的策略来处理漂浮物,即,通过到相机的距离来缩放梯度场。
3Method 3方法
We first review the point cloud growth condition of “Adaptive density control” in 3DGS. Then, we propose a method for calculating the average gradient magnitude in the point cloud growth condition from a pixel perspective, significantly enhancing the reconstruction capability in areas with insufficient initial points. Finally, we show that by scaling the spatial gradient field that controls point growth, floaters near the input cameras can be significantly suppressed.
首先回顾了3DGS中“自适应密度控制”的点云生长条件。然后,我们提出了一种从像素角度计算点云增长条件下的平均梯度幅值的方法,显著增强了初始点不足区域的重建能力。最后,我们表明,通过缩放空间梯度场,控制点的增长,输入摄像机附近的浮动可以显着抑制。
3.1Preliminaries
In 3D Gaussian Splatting, Gaussian � under viewpoint � generates a 2D covariance matrix Σ2��,�=(��,���,���,���,�), and the corresponding influence range radius ��� can be determined by:
在3D高斯溅射中,视点 � 下的高斯 � 生成2D协方差矩阵 Σ2��,�=(��,���,���,���,�) ,对应的影响范围半径 ��� 可以由下式确定:
| ���=3×(��,�+��,�2+(��,�+��,�2)2−(��,���,�−(��,�)2)), | (1) |
which covers 99% of the probability in the Gaussian distribution. For Gaussian �, under viewpoint �, the coordinates in the camera coordinate system are (��,��,�,��,��,�,��,��,�), and in the pixel coordinate system, they are (��,��,�,��,��,�,��,��,�). With the image width being � pixels and the height � pixels, Gaussian � participates in the calculation for viewpoint � when it simultaneously satisfies the following six conditions:
它覆盖了高斯分布中的99 % 概率。对于高斯 � ,在视点 � 下,相机坐标系中的坐标是 (��,��,�,��,��,�,��,��,�) ,并且在像素坐标系中,它们是 (��,��,�,��,��,�,��,��,�) 。在图像宽度为 � 像素且高度为 � 像素的情况下,当高斯 � 同时满足以下六个条件时,高斯 � 参与视点 � 的计算:
| {���>0,��,��,�>0.2,−���−0.5<��,��,�<���+�−0.5,−���−0.5<��,��,�<���+�−0.5. | (2) |
In 3D Gaussian Splatting, whether a point is split or cloned is determined by the average magnitude of the gradient of the NDC coordinates for the viewpoints in which the Gaussian participates in the calculation. Specifically, for Gaussian � under viewpoint �, the NDC coordinate is (�ndc,x�,�,�ndc,y�,�,�ndc,z�,�), and the loss under viewpoint � is ��. During “Adaptive Density Control” every 100 iterations, Gaussian � participates in the calculation for �� viewpoints. The threshold �pos is set to 0.0002 in 3D Gaussian Splatting. When Gaussian satisfies
在3D高斯飞溅中,点是被分割还是克隆由高斯参与计算的视点的NDC坐标的梯度的平均幅度确定。具体地,对于视点 � 下的高斯 � ,NDC坐标是 (�ndc,x�,�,�ndc,y�,�,�ndc,z�,�) ,并且视点 � 下的损失是 �� 。在每100次迭代的“自适应密度控制”期间,高斯 � 参与 �� 视点的计算。在3D高斯溅射中,阈值 �pos 被设置为0.0002。当Gaussian满足
| ∑�=1��(∂��∂�ndc,x�,�)2+(∂��∂�ndc,y�,�)2��>�pos, | (3) |
it is transformed into two Gaussians.
它被转换成两个高斯。
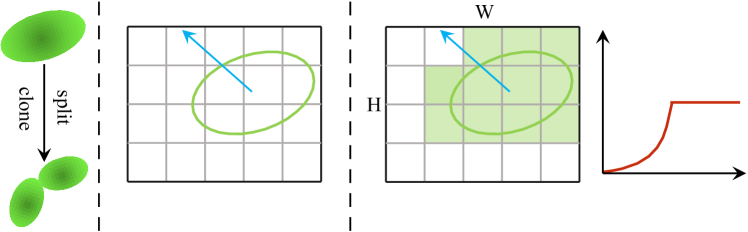
∑‖𝐠�‖∑1>�pos∑p�⋅�(‖𝐠�‖)∑p�>�pos�depth𝐠�𝐠�
Figure 2:Pipeline of Pixel-GS. p� represents the number of pixels participating in the calculation for the Gaussian from this viewpoint, and 𝐠� represents the gradient of the Gaussian’s NDC coordinates. We changed the condition for deciding whether a Gaussian should split or clone from the left to the right side.
图2:Pixel-GS的流水线。 p� 表示从该视点参与高斯计算的像素数, 𝐠� 表示高斯的NDC坐标的梯度。我们改变了决定高斯是否应该从左侧分裂或克隆到右侧的条件。
3.2Pixel-aware Gradient 3.2像素感知渐变
Although the current criteria used to decide whether a point should split or clone are sufficient for appropriately distributing Gaussians in most areas, artifacts tend to occur in regions where initial points are sparse. In 3DGS, the lengths of the three axes of the ellipsoid corresponding to Gaussian � are initialized using the values calculated by:
虽然用于决定点是否应该分裂或克隆的当前标准足以在大多数区域中适当地分布高斯,但伪影往往发生在初始点稀疏的区域中。在3DGS中,对应于高斯 � 的椭圆体的三个轴的长度使用由下式计算的值来初始化:
| ��=(�1�)2+(�2�)2+(�3�)23, | (4) |
where �1�, �2�, and �3� are the distances to the three nearest points to Gaussian �, respectively. We observed that areas inadequately modeled often have very sparse initial SfM point clouds, leading to the initialization of Gaussians in these areas with ellipsoids having larger axis lengths. This results in their involvement in the computation from too many viewpoints. These Gaussians exhibit larger gradients only in viewpoints where the center point, after projection, is within or near the pixel space. This implies that, from these viewpoints, the large Gaussians cover a larger area in the pixel space after projection. This results in these points having a smaller average gradient size of their NDC coordinates during the “Adaptive Density Control” process every 100 iterations (Eq. 3), because they participate in the computation from too many viewpoints and only have significant gradient sizes in individual viewpoints. Consequently, it is difficult for these points to split or clone, leading to poor modeling in these areas.
其中 �1� 、 �2� 和 �3� 分别是到高斯 � 的三个最近点的距离。我们观察到,未充分建模的区域通常具有非常稀疏的初始SfM点云,导致这些区域中的高斯初始化具有较大轴长的椭球。这导致他们从太多的观点参与计算。这些高斯曲线仅在投影后中心点位于像素空间内或附近的视点中表现出较大的梯度。这意味着,从这些观点来看,大高斯在投影后覆盖像素空间中的更大区域。这导致这些点在每100次迭代的“自适应密度控制”过程期间具有它们的NDC坐标的较小平均梯度大小(等式2)。3),因为它们从太多的视点参与计算,并且仅在各个视点中具有显著的梯度大小。 因此,这些点很难分割或克隆,导致这些区域的建模效果不佳。
Below, we analyze through equations why the Gaussians in the previously mentioned sparser areas can only obtain larger NDC coordinate gradients from viewpoints with sufficient coverage, whereas for viewpoints that only affect the edge areas, the NDC coordinate gradients are smaller. The contribution of a pixel under viewpoint � to the NDC coordinate gradient of Gaussian � can be computed as:
下面,我们通过方程来分析为什么在前面提到的稀疏区域中的高斯只能从具有足够覆盖的视点获得较大的NDC坐标梯度,而对于仅影响边缘区域的视点,NDC坐标梯度较小。视点 � 下的像素对高斯 � 的NDC坐标梯度的贡献可以计算为:
| (∂��∂�ndc,x�,�∂��∂�ndc,y�,�)=∑���=1���∑�=13(∂��∂�����×∂�����∂��,����×(∂��,����∂�ndc,x�,�∂��,����∂�ndc,y�,�)), | (5) |
where both ∂��,����∂�ndc,x�,� and ∂��,����∂�ndc,y�,� contain factor ���, which can be calculated as:
其中 ∂��,����∂�ndc,x�,� 和 ∂��,����∂�ndc,y�,� 都包含因子 ��� ,其可以计算为:
| ��,����=��×exp(−12(����−��,��,�����−��,��,�)�(Σ2��,�)−1(����−��,��,�����−��,��,�)), | (6) |
where ����� represents the color of the �th channel of the current pixel, and ��� represents the number of pixels involved in the calculation for Gaussian � under viewpoint �. ��,���� as a function of the distance between the center of the projected Gaussian and the pixel center, exhibits exponential decay as the distance increases.
其中 ����� 表示当前像素的第 � 通道的颜色,并且 ��� 表示在视点 � 下的高斯 � 的计算中涉及的像素的数量。作为投影高斯的中心与像素中心之间的距离的函数,随着距离的增加呈现指数衰减。
This results in a few pixels close to the center position of the projected Gaussian making a primary contribution to the NDC coordinate gradient of this Gaussian. For large Gaussians, many viewpoints will only affect the edge areas, projecting onto pixels in these viewpoints, leading to the involvement of these viewpoints in the calculation but with very small NDC coordinate gradients. On the other hand, we observe that for these points, for a given viewpoint, when a large number of pixels are involved in the calculation after projection, these points often exhibit larger gradients of NDC coordinates in this viewpoint. This is easy to understand because, when a large number of pixels are involved in the calculation after projection, the projected center point tends to be within the pixel plane, and according to previous calculations, a few pixels near the center point are the main contributors to the gradient of the NDC coordinates.
这导致靠近投影高斯的中心位置的几个像素对该高斯的NDC坐标梯度做出主要贡献。对于大高斯,许多视点将仅影响边缘区域,投影到这些视点中的像素上,导致这些视点参与计算,但具有非常小的NDC坐标梯度。另一方面,我们观察到,对于这些点,对于给定的视点,当投影后的计算中涉及大量像素时,这些点在该视点中往往表现出较大的NDC坐标梯度。这很容易理解,因为当投影后的计算中涉及大量像素时,投影的中心点往往在像素平面内,根据之前的计算,中心点附近的几个像素是NDC坐标梯度的主要贡献者。
To solve this problem, we assign a weight to the gradient size of the NDC coordinates for each Gaussian at every viewpoint, where the weight is the number of pixels involved in the computation for that Gaussian from the corresponding viewpoint. The advantage of this computational approach is that, for large Gaussians, the number of pixels involved in the calculations varies significantly across different viewpoints. According to previous derivations, these large Gaussians only receive larger gradients in viewpoints where a higher number of pixels are involved in the calculations. Weighting the magnitude of gradients by the number of participating pixels in an average manner can more rationally promote the splitting or cloning of these Gaussians. Additionally, for smaller Gaussians, the variation in the number of pixels involved across different viewpoints is minimal. The current averaging method does not produce a significant change compared to the original conditions and does not result in excessive additional memory consumption. The modified equation to decide whether a Gaussian undergoes split or clone is given by:
为了解决这个问题,我们为每个视点处每个高斯的NDC坐标的梯度大小分配一个权重,其中权重是从相应视点计算该高斯时所涉及的像素数。这种计算方法的优点是,对于大高斯,计算中涉及的像素数量在不同的视点之间变化很大。根据先前的推导,这些大高斯仅在计算中涉及更多像素的视点中接收更大的梯度。以平均方式通过参与像素的数量来加权梯度的大小可以更合理地促进这些高斯的分裂或克隆。此外,对于较小的高斯,跨不同视点所涉及的像素数量的变化是最小的。 与原始条件相比,电流平均方法不会产生显著变化,也不会导致额外的内存消耗。 决定高斯是分裂还是克隆的修改后的方程由下式给出:
| ∑�=1�����×(∂��∂�ndc,x�,�)2+(∂��∂�ndc,y�,�)2∑�=1�����>�pos, | (7) |
where �� is the number of viewpoints in which Gaussian � participates in the computation during the corresponding 100 iterations of “Adaptive Density Control”, ��� is the number of pixels Gaussian � participates in at viewpoint �, and ∂��∂�ndc,x�,� and ∂��∂�ndc,y�,� respectively represent the gradients of Gaussian � in the � and � directions of NDC space at viewpoint �. The conditions under which a Gaussian participates in the computation for a pixel is given by:
其中 �� 是在“自适应密度控制”的对应100次迭代期间高斯 � 参与计算的视点的数目, ��� 是高斯 � 在视点 � 处参与的像素的数目,而 ∂��∂�ndc,x�,� 和 ∂��∂�ndc,y�,� 分别表示在视点 � 处高斯 � 在NDC空间的 � 和 � 方向上的梯度。高斯参与像素计算的条件由下式给出:
| {(����−��,��,�)2+(����−��,��,�)2<���,∏�=1�(1−��,����)⩾10−4,��,����⩾1255, | (8) |
while the conditions under which a Gaussian participates in the computation from a viewpoint is given by Eq. 2.
而高斯参与计算的条件从一个观点由方程给出。2.
3.3Scaled Gradient Field 3.3缩放梯度场
While using “Pixel-aware Gradient” to decide whether a point should split or clone (Eq. 7) can address artifacts in modeling areas with insufficient viewpoints and repetitive texture, we found that this condition for point cloud growth also exacerbates the presence of floaters near the camera. This is mainly because floaters near the camera occupy a large screen space and have significant gradients in their NDC coordinates, leading to an increasing number of floaters during the point cloud growth process. To address this issue, we scale the gradient field of the NDC coordinates.
当使用“像素感知梯度”来决定一个点是否应该分裂或克隆时(等式10),7)可以解决建模区域中视点不足和重复纹理的伪影,我们发现点云增长的这种情况也加剧了相机附近的漂浮物的存在。这主要是因为摄像机附近的漂浮物占据了很大的屏幕空间,并且在其NDC坐标中具有显著的梯度,导致在点云增长过程中漂浮物的数量不断增加。为了解决这个问题,我们缩放NDC坐标的梯度场。
Specifically, we use the radius to determine the scale of the scene, where the radius is calculated by:
具体来说,我们使用半径来确定场景的比例,其中半径通过以下公式计算:
| radius=1.1⋅max�{‖𝐂�−1�∑�=1�𝐂�‖2}. | (9) |
In the training set, there are � viewpoints, with 𝐂� representing the coordinates of the �th viewpoint’s camera in the world coordinate system. We scale the gradient of the NDC coordinates for each Gaussian � under the �th viewpoint, with the scaling factor �(�,�) being calculated by:
在训练集中,有 � 个视点,其中 𝐂� 表示世界坐标系中第 � 个视点的相机的坐标。我们在第 � 个视点下缩放每个高斯 � 的NDC坐标的梯度,其中缩放因子 �(�,�) 通过下式计算:
| �(�,�)=clip((��,��,��depth×radius)2,0,1), | (10) |
where ��,��,� is the z-coordinate of Gaussian � in the camera coordinate system under the �th viewpoint, indicating the depth of this Gaussian from the viewpoint, and �depth is a hyperparameter set manually.
其中, ��,��,� 是第 � 视点下的相机坐标系中的高斯 � 的z坐标,指示该高斯距视点的深度,并且 �depth 是手动设置的超参数。
The primary inspiration for using squared terms as scaling coefficients in Eq. 10 comes from “Floaters No More” [40]. This paper notes that floaters in NeRF [35] are mainly due to regions close to the camera occupying more pixels after projection, which leads to receiving more gradients during optimization. This results in these areas being optimized first, consequently obscuring the originally correct spatial positions from being optimized. The number of pixels occupied is inversely proportional to the square of the distance to the camera, hence the scaling of gradients by the squared distance.
在方程中使用平方项作为比例系数的主要灵感。10来自“不再漂浮”[ 40]。这篇论文指出,NeRF [ 35]中的浮动主要是由于靠近相机的区域在投影后占据更多像素,这导致在优化过程中接收更多梯度。这导致这些区域首先被优化,从而使最初正确的空间位置无法被优化。所占用的像素数与到相机的距离的平方成反比,因此梯度的缩放比例为平方距离。
In summary, a major issue with pixel-based optimization is the imbalance in the spatial gradient field, leading to inconsistent optimization speeds across different areas. Adaptive scaling of the gradient field in different spatial regions can effectively address this problem. Therefore, the final calculation equation that determines whether a Gaussian undergoes a “split” or “clone” is given by:
总之,基于像素的优化的一个主要问题是空间梯度场的不平衡,导致不同区域的优化速度不一致。梯度场在不同空间区域的自适应缩放可以有效地解决这个问题。因此,确定高斯是否经历“分裂”或“克隆”的最终计算方程由下式给出:
| ∑�=1�����×�(�,�)×(∂��∂�ndc,x�,�)2+(∂��∂�ndc,y�,�)2∑�=1�����>�pos. | (11) |
4Experiments 4实验
4.1Experimental Setup 4.1实验装置
Datasets and benchmarks. We evaluated our method across a total of 30 real-world scenes, including all scenes from Mip-NeRF 360 (9 scenes) [3] and Tanks & Temples (21 scenes) [22], which are two most widely used datasets in the field of 3D reconstruction. They contain both bounded indoor scenes and unbounded outdoor scenes, allowing for a comprehensive evaluation of our method’s performance.
数据集和基准。我们在总共30个真实世界场景中评估了我们的方法,包括来自Mip-NeRF 360(9个场景)[ 3]和Tanks & Temples(21个场景)[ 22]的所有场景,这是3D重建领域最广泛使用的两个数据集。它们包含有界的室内场景和无界的室外场景,允许我们的方法的性能进行全面的评估。
Evaluation metrics. We assess the quality of reconstruction through PSNR↑, SSIM↑ [47], and LPIPS↓ [60]. Among them, PSNR reflects pixel-aware errors but does not quite correspond to human visual perception as it treats all errors as noise without distinguishing between structural and non-structural distortions. SSIM accounts for structural transformations in luminance, contrast, and structure, thus more closely mirroring human perception of image quality. LPIPS uses a pre-trained deep neural network to extract features and measures the high-level semantic differences between images, offering a similarity that is closer to human perceptual assessment compared to PSNR and SSIM.
评价指标。我们通过PSNR ↑ 、SSIM ↑ [ 47]和LPIPS ↓ [ 60]评估重建质量。其中,PSNR反映了像素感知误差,但并不完全对应于人类视觉感知,因为它将所有误差视为噪声,而不区分结构性和非结构性失真。SSIM解释了亮度、对比度和结构的结构转换,从而更接近地反映了人类对图像质量的感知。LPIPS使用预训练的深度神经网络来提取特征并测量图像之间的高级语义差异,与PSNR和SSIM相比,提供更接近人类感知评估的相似性。
Implementation details. Our method only requires minor modifications to the original code of 3DGS, so it is compatible with almost all subsequent works on 3DGS. We use the default parameters of 3DGS to ensure consistency with the original implementation, including maintaining the same threshold ���� for splitting and cloning points as in the original 3DGS. For all scenes, we set a constant �depth value in Eq. 10 as 0.37 which is obtained through experimentations. All experiments were conducted on one RTX 3090 GPU with 24GB memory.
实施细节。我们的方法只需要对3DGS的原始代码进行微小的修改,因此它与几乎所有的3DGS后续工作兼容。我们使用3DGS的默认参数来确保与原始实现的一致性,包括保持与原始3DGS中相同的分割和克隆点的阈值 ���� 。对于所有场景,我们在等式中设置恒定的 �depth 值。10为0.37,通过实验得到。所有实验均在具有24 GB内存的RTX 3090 GPU上进行。
4.2Main Results 4.2主要结果
We select several representative methods for comparison, including the NeRF methods, e.g., Plenoxels [13], INGP [37], and Mip-NeRF 360 [3], and the 3DGS method [21]. We used the official implementation for all of the compared methods, and the same training/testing split as Mip-NeRF 360, selecting one out of every eight photos for testing.
我们选择了几种有代表性的方法进行比较,包括NeRF方法,例如,Plenoxels [ 13],INGP [ 37]和Mip-NeRF 360 [ 3]以及3DGS方法[ 21]。我们对所有比较的方法都使用了官方实现,并使用了与Mip-NeRF 360相同的训练/测试划分,每八张照片中选择一张进行测试。
Quantitative results. The quantitative results (PSNR, SSIM, and LPIPS) on the Mip-NeRF 360 and Tanks & Temples datasets are presented in Tables 1 and 2, respectively. We also provide the results of three challenging scenes for each dataset for more detailed information. Here, we retrained the 3DGS (noted as 3DGS∗) as doing so yields a better performance than the original 3DGS (noted as 3DGS). We can see that our method consistently outperforms all the other methods, especially in terms of the LPIPS metric, while maintaining real-time rendering speed (to be discussed later). Besides, compared to 3DGS, our method shows significant improvements in the three challenging scenes in both datasets and achieves better performance over the entire dataset. It quantitatively validates the effectiveness of our method in improving the quality of reconstruction.
定量结果。Mip-NeRF 360和Tanks & Temples数据集的定量结果(PSNR、SSIM和LPIPS)分别见表1和表2。我们还为每个数据集提供了三个具有挑战性的场景的结果,以获得更详细的信息。在这里,我们重新训练了3DGS(标记为3DGS ∗ ),因为这样做会产生比原始3DGS(标记为3DGS)更好的性能。我们可以看到,我们的方法始终优于所有其他方法,特别是在LPIPS指标方面,同时保持实时渲染速度(稍后讨论)。此外,与3DGS相比,我们的方法在两个数据集中的三个具有挑战性的场景中表现出显着的改进,并在整个数据集上实现了更好的性能。定量验证了该方法在提高重建质量方面的有效性。
Table 1:Quantitative results on the Mip-NeRF 360 dataset. Cells are highlighted as follows: best, second best, and third best. We also show the results of three challenging scenes. 3DGS∗ is our retrained 3DGS model with better performance.
表1:Mip-NeRF 360数据集的定量结果。单元格突出显示如下:最佳、第二佳和第三佳。我们还展示了三个具有挑战性的场景的结果。3DGS ∗ 是我们重新训练的3DGS模型,具有更好的性能。
| Mip-NeRF 360 (all scenes) Mip-NeRF 360(所有场景) |
Flowers 花 | Bicycle 自行车 | Stump 残端 | |||||||||
| Method 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
| Plenoxels [13] | 23.08 | 0.625 | 0.463 | 20.10 | 0.431 | 0.521 | 21.91 | 0.496 | 0.506 | 20.66 | 0.523 | 0.503 |
| INGP-Base [37] INGP-基础[ 37] | 25.30 | 0.671 | 0.371 | 20.35 | 0.450 | 0.481 | 22.19 | 0.491 | 0.487 | 23.63 | 0.574 | 0.450 |
| INGP-Big [37] [ 37]第三十七话 | 25.59 | 0.699 | 0.331 | 20.65 | 0.486 | 0.441 | 22.17 | 0.512 | 0.446 | 23.47 | 0.594 | 0.421 |
| Mip-NeRF 360 [3] | 27.69 | 0.792 | 0.237 | 21.73 | 0.583 | 0.344 | 24.37 | 0.685 | 0.301 | 26.40 | 0.744 | 0.261 |
| 3DGS [21] | 27.21 | 0.815 | 0.214 | 21.52 | 0.605 | 0.336 | 25.25 | 0.771 | 0.205 | 26.55 | 0.775 | 0.210 |
| 3DGS∗ [21] | 27.71 | 0.826 | 0.202 | 21.89 | 0.622 | 0.328 | 25.63 | 0.778 | 0.204 | 26.90 | 0.785 | 0.207 |
| Pixel-GS (Ours) Pixel-GS(我们的) | 27.88 | 0.834 | 0.176 | 21.94 | 0.652 | 0.251 | 25.74 | 0.793 | 0.173 | 27.11 | 0.796 | 0.181 |
Table 2:Quantitative results on the Tanks & Temples dataset. We also show the results of three challenging scenes. ∗ indicates retraining for better performance.
表2:Tanks & Temples数据集的定量结果。我们还展示了三个具有挑战性的场景的结果。 ∗ 表示重新培训以获得更好的性能。
| Tanks & Temples (all scenes) 坦克和寺庙(所有场景) |
Train 火车 | Barn 谷仓 | Caterpillar | |||||||||
| Method 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
| 3DGS∗ [21] | 24.19 | 0.844 | 0.194 | 22.02 | 0.812 | 0.209 | 28.46 | 0.869 | 0.182 | 23.79 | 0.809 | 0.211 |
| Pixel-GS (Ours) Pixel-GS(我们的) | 24.38 | 0.850 | 0.178 | 22.13 | 0.823 | 0.180 | 29.00 | 0.888 | 0.144 | 24.08 | 0.832 | 0.173 |
Qualitative results. In Figures 1 and 3, we showcase the comparisons between our method and 3DGS∗. We can see our approach significantly reduces the blurring and needle-like artifacts, e.g. the region of the flowers in the second row and the blow-up region in the last row, compared against the 3DGS∗. These regions are initialized with insufficient points from SfM, and our method effectively grows points in these areas, leading to a more accurate and detailed reconstruction. Please refer to the supplemental materials for the point cloud comparison. These examples clearly validate that our method is more robust to the quality of initialization point clouds and can reconstruct high-fidelity details.
定性结果。在图1和图3中,我们展示了我们的方法和3DGS ∗ 之间的比较。我们可以看到,与3DGS ∗ 相比,我们的方法显着减少了模糊和针状伪影,例如第二行中的花朵区域和最后一行中的放大区域。这些区域是用SfM中的不足点初始化的,我们的方法有效地在这些区域中增加点,从而实现更准确和更详细的重建。点云比较请参考补充资料。这些例子清楚地验证了我们的方法是更强大的初始化点云的质量,可以重建高保真的细节。
4.3Ablation Studies 4.3消融研究
To evaluate the effectiveness of individual components of our method, i.e. the pixel-aware gradient and the scaled gradient field, we conducted ablation studies on the Mip-NeRF 360 and Tanks & Temples datasets. The quantitative and qualitative results are presented in Table 3 and Figure 4, respectively. We can see that both the pixel-aware gradient and the scaled gradient field contribute to the improvement of the reconstruction quality in the Mip-NeRF 360 dataset. However, the pixel-aware gradient strategy reduces the reconstruction quality in the Tanks & Temples dataset. This is mainly due to floaters that tend to appear near the camera in some large scenes in Tanks & Temples and the pixel-aware gradient encourages more Gaussians, as shown in column (b) of Figure 4. Notably, this phenomenon also exists for the 3DGS when the threshold �pos is lowered, which also promots more Gaussians, as shown in Table 4. But importantly, the combination of both proposed strategies achieves the best performance in the Tanks & Temples dataset, as shown in Table 3, since the scaled gradient field can suppress the growth of floaters near the camera. In summary, the ablation studies demonstrate the effectiveness of our proposed individual components and the necessity of combining them to achieve the best performance.
为了评估我们的方法的各个组成部分的有效性,即像素感知梯度和缩放梯度场,我们对Mip-NeRF 360和Tanks & Temples数据集进行了消融研究。定量和定性结果分别见表3和图4。我们可以看到,像素感知梯度和缩放梯度场都有助于提高Mip-NeRF 360数据集中的重建质量。然而,像素感知梯度策略降低了Tanks & Temples数据集的重建质量。这主要是由于在坦克和寺庙中的一些大型场景中,漂浮物往往出现在相机附近,并且像素感知梯度鼓励更多的高斯,如图4的列(B)所示。值得注意的是,当阈值 �pos 降低时,3DGS也存在这种现象,这也促进了更多的高斯,如表4所示。 但重要的是,这两种策略的组合在Tanks & Temples数据集中实现了最佳性能,如表3所示,因为缩放的梯度场可以抑制相机附近漂浮物的增长。总之,消融研究证明了我们提出的单个组件的有效性以及将它们组合以实现最佳性能的必要性。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| (a) Ground Truth (a)地面实况 | (b) Pixel-GS (Ours) (b)Pixel-GS(我们的) | (c) 3DGS∗ [21] (c)3DGS ∗ [ 21] |





















Figure 3: Qualitative comparison between Pixel-GS (Ours) and 3DGS∗. The first three scenes are from the Mip-NeRF 360 dataset (Bicycle, Flowers, and Treehill), while the last four scenes are from the Tanks & Temples dataset (Barn, Caterpillar, Playground, and Train). The blow-up regions or arrows highlight the parts with distinct differences in quality. 3DGS∗ is our retrained 3DGS model with better performance.
图3:Pixel-GS(我们的)和3DGS ∗ 之间的定性比较。前三个场景来自Mip-NeRF 360数据集(自行车,鲜花和树丘),而最后四个场景来自坦克和寺庙数据集(谷仓,卡特彼勒,游乐场和火车)。放大区域或箭头突出显示具有明显质量差异的零件。3DGS ∗ 是我们重新训练的3DGS模型,具有更好的性能。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| (a) 3DGS (a)3DGS∗ | (b) Pixel-aware Gradient (b)像素感知渐变 | (c) Scaled Gradient Field (c)缩放梯度场 |
(d) Complete Model (d)完整模型 |
















Figure 4:Qualitative results of the ablation study. The PSNR↑ results are shown on the corresponding images.
图4:消融研究的定性结果。PSNR ↑ 结果显示在相应的图像上。 Table 3:Ablation study. The metrics are derived from the average values across all scenes of the Mip-NeRF 360 and Tanks & Temples datasets, respectively.
表3:消融研究。这些指标分别来自Mip-NeRF 360和Tanks & Temples数据集所有场景的平均值。
| Mip-NeRF 360 | Tanks & Temples 坦克和寺庙 | |||||
| Method 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
| 3DGS∗ [21] | 27.71 | 0.826 | 0.202 | 24.23 | 0.844 | 0.194 |
| Pixel-aware Gradient 像素感知渐变 | 27.74 | 0.833 | 0.176 | 21.80 | 0.791 | 0.239 |
| Scaled Gradient Field 缩放梯度场 | 27.72 | 0.825 | 0.202 | 24.34 | 0.843 | 0.198 |
| Complete Model 完整模型 | 27.88 | 0.834 | 0.176 | 24.38 | 0.850 | 0.178 |
Table 4:Impact of lowering �pos. We show the corresponding quality and efficiency metrics when lowering the threshold �pos of point growth for 3DGS∗ and our method.
表4:降低 �pos 的影响。当降低3DGS ∗ 和我们的方法的点增长的阈值 �pos 时,我们显示了相应的质量和效率指标。
| Dataset 数据集 | Strategy 战略 | PSNR↑ | SSIM↑ | LPIPS↓ | Train 火车 | FPS | Memory 存储器 |
| Mip-NeRF 360 | 3DGS∗ (�pos=2�−4) | 27.71 | 0.826 | 0.202 | 25m40s | 126 | 0.72GB |
| 3DGS∗ (�pos=1.28�−4) | 27.83 | 0.833 | 0.181 | 43m23s | 90 | 1.4GB | |
| Ours (�pos=2�−4) 我们的 (�pos=2�−4) | 27.88 | 0.834 | 0.176 | 41m25s | 89 | 1.2GB | |
| Tanks & Temples 坦克和寺庙 | 3DGS∗ (�pos=2�−4) | 24.19 | 0.844 | 0.194 | 16m3s 16 m3秒 | 135 | 0.41GB |
| 3DGS∗ (�pos=1�−4) | 23.86 | 0.842 | 0.187 | 27m59s | 87 | 0.94GB | |
| Ours (�pos=2�−4) 熊 (�pos=2�−4) | 24.38 | 0.850 | 0.178 | 26m36s 26米36秒 | 92 | 0.84GB |
|
|
|
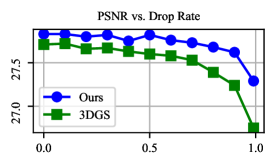
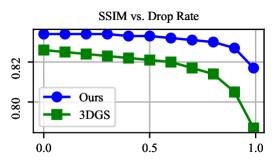
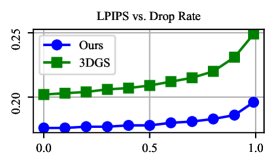
Figure 5: Reconstruction quality (PSNR↑, SSIM↑, and LPIPS↓) vs. Dropping rate of initializing points. Here, the dropping rate refers to the percentage of points dropped from the original SfM point clouds for initializing Gaussians. The results are obtained on the Mip-NeRF 360 dataset.
图5:重建质量(PSNR ↑ 、SSIM ↑ 和LPIPS ↓ )与初始化点丢弃率的关系。这里,丢弃率是指从用于初始化高斯的原始SfM点云丢弃的点的百分比。结果是在Mip-NeRF 360数据集上获得的。
4.4Analysis
The impact of lowering the threshold �pos. As the blurring and needle-like artifacts in 3DGS mainly occur in areas with insufficient initializing points, one straightforward solution would be to lower the threshold �pos to encourage the growth of more points. To verify this, we experimented on the Mip-NeRF 360 and Tanks & Temples datasets by lowering the threshold �pos from 2�−4 to 1.28�−4 for 3DGS to make the final optimized number of points comparable to ours. From Table 4, we can see that lowering the threshold �pos for 3DGS significantly increases the memory consumption and decreases the rendering speed, while still falling behind ours in terms of reconstruction quality. As can be seen from the qualitative comparison in Figure 1, this is because the point cloud growth mechanism of 3DGS struggles to generate points in areas with insufficient initializing points and only yields unnecessary points in areas where the initial SfM point cloud is already dense. In contrast, although our method also results in additional memory consumption, our method’s point cloud distribution is more uniform, enabling effectively growing points in areas with insufficient initializing points, thereby leading to a more accurate and detailed reconstruction while still maintaining real-time rendering speed.
降低阈值 �pos 的影响。由于3DGS中的模糊和针状伪影主要发生在初始化点不足的区域中,因此一种直接的解决方案是降低阈值 �pos 以鼓励更多点的增长。为了验证这一点,我们在Mip-NeRF 360和Tanks & Temples数据集上进行了实验,将3DGS的阈值 �pos 从 2�−4 降低到 1.28�−4 ,以使最终优化的点数与我们的点数相当。从表4中,我们可以看到,降低3DGS的阈值 �pos 会显著增加内存消耗并降低渲染速度,但在重建质量方面仍然落后于我们。从图1中的定性比较可以看出,这是因为3DGS的点云增长机制难以在初始化点不足的区域中生成点,并且仅在初始SfM点云已经密集的区域中生成不必要的点。 相比之下,虽然我们的方法也会导致额外的内存消耗,但我们的方法的点云分布更均匀,能够在初始化点不足的区域有效地增长点,从而在保持实时渲染速度的同时实现更准确和详细的重建。
Robustness to the quality of initialization point clouds. Finally, SfM algorithms often fail to produce high-quality point clouds in some areas, e.g., too few observations, repetitive textures, or low textures. The point cloud produced by SfM is usually the necessary input for 3DGS and our method. Therefore, we explored the robustness of our method to the quality of initialization point clouds by randomly dropping points from the SfM point clouds used for initialization and compared the results with that of 3DGS. Figure 5 shows how the reconstruction quality varies with the proportion of dropped points. We can see that our method consistently outperforms 3DGS in terms of all the metrics (PSNR, SSIM, and LPIPS). And more importantly, our method is less affected by the dropping rate than 3DGS. Notably, even though the 99% initializing points have been dropped, the reconstruction quality of our method still surpasses that of 3DGS initialized with complete SfM point clouds, in terms of LPIPS. These results demonstrate the robustness of our method to the quality of initialization point clouds, which is crucial for real-world applications.
对初始化点云质量的鲁棒性。最后,SfM算法通常无法在某些区域产生高质量的点云,例如,太少的观察,重复的纹理,或低纹理。由SfM产生的点云通常是3DGS和我们的方法的必要输入。因此,我们探讨了我们的方法的鲁棒性的初始化点云的质量随机下降点从SfM点云用于初始化,并比较结果与3DGS。图5显示了重建质量如何随丢弃点的比例而变化。我们可以看到,我们的方法在所有指标(PSNR,SSIM和LPIPS)方面始终优于3DGS。更重要的是,我们的方法比3DGS受下降率的影响更小。 值得注意的是,即使 99% 初始化点已经被丢弃,我们的方法的重建质量仍然超过了用完整的SfM点云初始化的3DGS的重建质量,就LPIPS而言。这些结果表明,我们的方法的鲁棒性的初始化点云的质量,这是至关重要的现实世界中的应用。
5Conclusion 5结论
The blurring and needle-like artifacts in 3DGS are mainly attributed to its inability to grow points in areas with insufficient initializing points. To address this issue, we propose Pixel-GS, which considers the number of pixels covered by a Gaussian in each view to dynamically weigh the gradient of each view during the computation of the growth condition. This strategy effectively grows Gaussians with large scales, which are more likely to exist in areas with insufficient initializing points, such that our method can adaptively grow points in these areas while avoiding unnecessary growth in areas with enough points. We also introduce a simple yet effective strategy to deal with floaters, i.e., scaling the gradient field by the distance to the camera. Extensive experiments demonstrate that our method significantly reduces blurring and needle-like artifacts and effectively suppresses floaters, achieving state-of-the-art performance in terms of rendering quality. Meanwhile, although our method consumes slightly more memory consumption, the increased points are mainly distributed in areas with insufficient initializing points, which are necessary for high-quality reconstruction, and our method still maintains real-time rendering speed. Finally, our method is more robust to the number of initialization points, thanks to our effective pixel-aware gradient and scaled gradient field.
3DGS中的模糊和针状伪影主要归因于其无法在初始化点不足的区域中生长点。为了解决这个问题,我们提出了Pixel-GS,它认为在每个视图中的高斯覆盖的像素的数量动态加权的梯度的每个视图在计算的增长条件。该策略有效地增长了大尺度的高斯,这些高斯更有可能存在于初始化点不足的区域中,因此我们的方法可以自适应地在这些区域中增长点,同时避免在有足够点的区域中不必要的增长。我们还介绍了一个简单而有效的策略来处理飞蚊症,即,通过到相机的距离来缩放梯度场。大量的实验表明,我们的方法显着减少模糊和针状文物,并有效地抑制浮动,实现最先进的性能方面的渲染质量。 同时,虽然我们的方法消耗了更多的内存消耗,但增加的点主要分布在初始化点不足的区域,这是高质量重建所必需的,我们的方法仍然保持实时渲染速度。最后,由于我们有效的像素感知梯度和缩放梯度场,我们的方法对初始化点的数量更具鲁棒性。