作者:Jiale Xu,Weihao Cheng,Yiming Gao等
编译:东岸因为@一点人工一点智能

摘要:本文提出了InstantMesh,这是一个用于从单视角图像生成即时3D网格的前馈框架,具有当前非常优秀的生成质量和显著的训练可扩展性。
通过将现成的多视角扩散模型和基于LRM [14]架构的稀疏视角重建模型的优势相结合,InstantMesh能够在10秒内创建多样化的3D物体。为了增强训练效率和利用更多几何监督,例如深度和法线,我们将可微分的等值面提取模块集成到我们的框架中,并直接在网格表示上进行优化。
在公共数据集的实验结果表明,InstantMesh在定性和定量上明显优于其他最新的图像到3D基准模型。

01 介绍
通过从单视图图像中生成3D物体(资产)可以促进广泛的应用,例如虚拟现实、工业设计、游戏和动画等。随着训练在十亿级数据上的大规模扩散模型[37, 38]的出现,我们已经在图像和视频生成方面见证了一场革命,它能够从开放域提示中生成生动而富有想象力的内容。然而,在3D生成方面复制这种成功面临着挑战,因为3D数据集的规模有限且标注质量参差不齐。
为了解决缺乏3D数据的问题,先前的研究探索了将2D扩散先验压缩为3D表示,并采用逐场景优化策略。DreamFusion [34] 提出了分数蒸馏采样 (SDS) 的方法,这在开放世界3D合成方面取得了突破。然而,使用文本到2D模型的SDS经常遇到多面问题,即“Janus”问题。为了改善3D的一致性,后续研究 [35] 提出了从Zero123 [23]蒸馏的方法,Zero123是从Stable Diffusion [37]微调得到的新视角生成器。一系列研究 [42, 50, 26, 24, 47] 进一步提出了多视角生成模型,优化过程可以同时受到多个新视角的引导。
基于2D蒸馏的方法具有强大的零样本生成能力,但它们耗时且在实际应用中不实用。随着大规模开放世界3D数据集 [8, 9] 的出现,先锋研究 [14, 13, 45] 阐明了图像令牌可以通过一种新颖的大规模重建模型 (LRM) 直接映射到3D表示(例如triplane)。基于高度可扩展的Transformer架构,LRM为快速创建高质量3D物体(资产)指明了一个有希望的方向。与此同时,Instant3D [19] 提出了通过增强的具有多视角输入的LRM预测3D形状的方法。该方法将LRMs与图像生成模型融合在一起,显著提高了泛化能力。
LRM方法使用triplane作为3D表示,使用MLP合成新视角。尽管具有强大的几何和纹理表示能力,但解码triplane需要消耗大量内存的体积渲染过程,从而严重影响了训练规模。此外,昂贵的计算开销使得难以利用高分辨率的RGB和几何信息(例如深度和法线)进行监督。为了提高训练效率,近期的研究尝试使用高斯函数 [18] 作为3D表示,这对渲染效果有效,但不适用于几何建模。几个同时进行的研究 [63, 54] 选择直接在网格表示上采用可微分的表面优化技术 [39, 40] 进行监督。然而,它们采用CNN-based的架构,限制了它们处理不同输入视角的灵活性,并限制了未来可能存在的更大数据集的训练可扩展性。
在这项工作中,我们提出了InstantMesh,这是一个用于从单张图像生成高质量3D网格的前馈框架。给定输入图像,InstantMesh首先使用多视角扩散模型生成3D一致的多视角图像,然后利用稀疏视角的大规模重建模型直接预测3D网格,整个过程可以在几秒内完成。通过集成可微的等值面提取模块,我们的重建模型直接在网格表面上应用几何监督,实现了令人满意的训练效率和网格生成质量。我们的模型建立在基于LRM的架构之上,具有优越的训练可扩展性。
实验结果表明,InstantMesh在定性和定量上明显优于其他最新的图像到3D方法。我们希望InstantMesh能够成为一个强大的图像到3D基础模型,并为3D生成人工智能领域做出实质性贡献。
02 相关工作
图像到3D的早期尝试主要集中在单视图重建任务上。随着扩散模型的兴起,先驱工作已经研究了基于图像条件的3D生成建模,在各种表示上进行了探索,例如点云、网格、SDF网格和神经场等。尽管这些方法取得了令人满意的进展,但由于训练数据规模有限,它们很难推广到开放世界的对象。

强大的文本到图像扩散模型的出现启发了将2D扩散先验融入3D神经辐射场的思想,并采用逐场景优化策略。DreamFusion提出的得分蒸馏采样(SDS)在零样本文本到3D合成方面表现出优越性能,并明显优于基于CLIP的替代方法。然而,基于SDS的方法经常遇到多面问题,也被称为"Janus"问题。Zero123证实了可以对Stable Diffusion进行微调,通过相对相机姿态进行条件生成新的视图。借助Zero123提供的新视图指导,最近的图像到3D方法展示了改进的3D一致性,并能够从开放域图像中生成合理的形状。
多视图扩散模型。为了解决Zero123生成的多个视图之间的不一致性问题,一些工作尝试对2D扩散模型进行微调,同时为同一对象合成多个视图。有了3D一致的多视图图像,可以应用各种技术来获取3D对象,例如SDS优化、神经表面重建方法、多视图条件的3D扩散模型等。为了进一步增强泛化能力和多视图一致性,一些最近的工作利用视频扩散模型中的时间先验进行多视图生成。
大规模重建模型。大规模的3D数据集的可用性使得可以训练高度泛化的重建模型,用于前向的图像到3D生成。大规模重建模型证明了transformer骨干网络可以有效地将图像记号映射到具有多视图监督的隐式3D triplane。Instant3D进一步将大规模重建模型扩展到稀疏视角输入,显著提高了重建质量。受到Instant3D的启发,LGM和GRM使用3D高斯函数代替triplaneNeRF表示,从而获得其优越的渲染效率,并避免了需要记忆密集型体积渲染过程。然而,高斯函数在显式几何建模和高质量表面提取方面存在不足。鉴于神经网格优化方法的成功,同时进行的MVD2和CRM选择直接在网格表示上进行优化,以实现高效的训练和高质量的几何和纹理建模。与它们的卷积网络架构不同,我们的模型基于大规模重建模型构建,采用纯transformer架构,提供了更高的灵活性和训练可扩展性。
03 InstantMesh的架构
类似于Instant3D,由多视图扩散模型GM和稀疏视图大规模重建模型GR组成。给定输入图像I,多视图扩散模型GM生成3D一致的多视图图像,然后将其输入稀疏视图大规模重建模型GR以重建出高质量的3D网格。我们现在介绍我们在数据准备、模型架构和训练策略方面的技术改进。
3.1 多视图扩散模型
从技术上讲,我们的稀疏视角重建模型可以使用任何视点图像作为输入,因此我们可以将任意多视图生成模型集成到我们的框架中,从而实现从文本到3D和从图像到3D的物体创建,例如MVDream,ImageDream,SyncDreamer,SPAD和SV3D。我们选择Zero123++,因为它具有可靠的多视图一致性和量身定制的视点分布,包含了3D目标的上部和下部。
白色背景微调:给定输入图像,Zero123++生成一个960×640的灰色背景图像,以3×2的网格形式呈现6个多视图图像。在实践中,我们注意到生成的背景在不同的图像区域不一致,并且在RGB值上发生了变化,导致重建结果中出现浮粒状和云状的伪影。而且,稀疏重建模型通常也是在白色背景图像上进行训练的。为了去除灰色背景,我们需要使用第三方库或模型,但不能保证多个视图之间的分割一致性。因此,我们选择微调Zero123++以合成一致的白色背景图像,确保后续的稀疏视图重建过程的稳定性。
数据准备和微调细节:我们按照Zero123++的相机分布准备微调数据。具体而言,对于Objaverse的LVIS子集中的每个3D模型,我们渲染一个查询图像和6个目标图像,均为白色背景。查询图像的方位角、仰角和相机距离是从预定义范围中随机采样的。6个目标图像的姿态由绝对仰角20°和-10°的交错组成,与查询图像相关的方位角从30°开始,每个姿态增加60°。
在微调过程中,我们将查询图像用作条件,并将6个目标图像拼接成一个3×2的网格进行去噪处理。遵循Zero123++的做法,我们采用线性噪声策略和L1预测损失。我们还随机调整条件图像的大小,使模型适应各种输入分辨率并生成清晰的图像。由于微调的目标只是替换背景颜色,所以它收敛非常快。具体而言,我们以学习率为1.0×10−5和批次大小为48的条件下对UNet进行1000步微调。微调后的模型完全保留了Zero123++的生成能力,并能一致地生成白色背景的图像。
3.2 稀疏视图大规模重建模型
我们介绍了稀疏视图重建模型GR的详细信息,该模型根据生成的多视图图像预测网格。该模型的架构经过修改和增强,改进自Instant3D。
数据准备:我们的训练数据集是从Objaverse数据集中渲染的多视图图像组成的。具体而言,我们为数据集中的每个对象从32个随机视点渲染512×512的图像、深度和法线。此外,我们使用一个经过筛选的高质量子集来训练我们的模型。
筛选的目标是移除满足以下任一条件的对象:(i)没有纹理映射的对象,(ii)渲染图像在任意角度的视野中占比少于10%,(iii)包含多个分离的对象,(iv)没有Cap3D数据集提供的标题信息的对象,以及(v)质量低的对象。根据元数据中存在的诸如“lowpoly”和其变体(例如“low_poly”)的标签,可以确定“质量低”对象的分类。通过应用我们的筛选标准,我们从Objaverse数据集的初始800k个对象中筛选出了约270k个高质量实例。
输入视图和分辨率:在训练过程中,我们随机选择一组6个图像作为输入,并将另外4个图像作为监督信号用于每个对象。为了与Zero123++的输出分辨率保持一致,所有输入图像都调整为320×320像素。在推断过程中,我们将由Zero123++生成的6个图像作为重建模型的输入,并固定它们的相机姿态。需要注意的是,我们基于Transformer的架构可以利用不同数量的输入视图,因此在某些情况下使用较少的输入视图进行重建是可行的,这可以减轻多视图不一致的问题。
网格作为3D表示:先前基于LRM的方法输出triplane,需要进行体素渲染以合成图像。在训练过程中,体素渲染消耗大量内存,阻碍了对高分辨率图像和法线进行监督。为了提高训练效率和重建质量,我们将可微分等值面提取模块FlexiCubes整合到我们的重建模型中。由于高效的网格光栅化,我们可以使用全分辨率的图像和额外的几何信息进行监督,例如深度和法线,而无需将它们裁剪成块。应用这些几何监督相比于从triplane NeRF提取的网格,可以得到更平滑的网格输出。此外,使用网格表示还可以方便地应用其他后处理步骤来增强结果,例如SDS优化或纹理烘焙。这留作待将来的工作。
与单视图LRM不同,我们的重建模型以6个视图作为输入,需要更多的内存用于triplane令牌和图像令牌之间的交叉注意力。我们注意到,从头开始训练这样一个大规模Transformer需要很长时间。为了更快的收敛,我们使用OpenLRM的预训练权重来初始化我们的模型,OpenLRM是一个开源的LRM实现。我们采用以下两阶段训练策略。
阶段1:在NeRF上训练。在第一阶段,我们在triplane NeRF表示上进行训练,并重用预训练的OpenLRM的先验知识。为了实现多视图输入,我们在ViT图像编码器中添加AdaLN相机姿态调制层,使输出的图像令牌具有姿态感知性,遵循Instant3D的方法,并删除LRM的triplane解码器中的源相机调制层。在这个训练阶段,我们采用图像损失和遮罩损失两种损失函数:
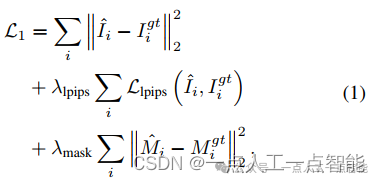
其中,、
、
和
分别表示第i个视图的渲染图像、真实图像、渲染的遮罩和真实的遮罩。在训练过程中,我们设置
,
,并使用余弦退火法将学习率从
4.0×10−4退化到4.0×10−5。为了进行高分辨率的训练,我们的模型渲染了192×192的图像块,并用大小从192×192到512×512的裁剪的真实图像块进行监督。
阶段2:在网格上进行训练。在第二阶段,我们切换到网格表示来进行高效的训练,并应用额外的几何监督。我们将FlexiCubes [40]集成到我们的重建模型中,从triplane隐式场中提取网格表面。原始的triplane NeRF渲染器包括密度MLP和色彩MLP,我们重用密度MLP来预测SDF,同时添加两个额外的MLP来预测FlexiCubes所需的变形和权重。
对于密度场,物体内部的点具有较大的值,而物体外部的点具有较小的值,而SDF场
是相反的。因此,我们初始化最后一个SDF MLP层的权重
和偏置
如下:

在原始密度MLP的最后一层中,和
分别表示权重和偏置,
表示密度场使用的等值面阈值。将最后一个MLP层的输入特征表示为
,则我们有:

通过这样的初始化,我们将密度场的“方向”反转以匹配SDF的方向,并确保等值面边界最初位于SDF场的0级集。我们以经验的方式发现,这种初始化有利于FlexiCubes的训练稳定性和收敛速度。第二阶段的损失函数为:
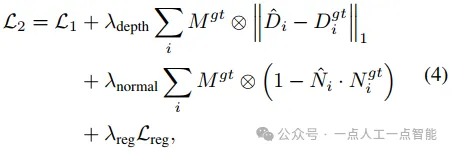
在训练过程中,我们设置,
,
,并使用学习率为4.0×10−5的余弦退火到 0。我们在8个NVIDIA H800 GPU上进行两个阶段的模型训练。
相机增强和扰动。与视图空间重建模型[13, 45, 44, 65]不同,我们的模型在一个规范的世界空间中重建3D物体,其中z轴与反重力方向对齐。为了进一步提高对3D物体尺度和方向的鲁棒性,我们对输入的多视图相机姿势进行随机旋转和缩放。考虑到Zero123++生成的多视图图像可能与预定义的相机姿势不一致,我们还在将它们输入到ViT图像编码器之前对相机参数添加随机噪声。

模型变体。在本文中,我们提供了稀疏视图重建模型的四个变体,分别来自阶段1的两个和阶段2的两个。我们根据其3D表示(“NeRF”或“Mesh”)和参数的尺度(“base”或“large”)为每个模型命名。每个模型的详细信息如表1所示。考虑到不同的3D表示和模型尺度可以为不同的应用场景带来便利,我们发布了所有4个模型的权重。我们相信我们的工作可以作为一个强大的从图像到3D的基础模型,促进未来的3D生成AI研究。
04 实验
在本节中,我们进行实验,定量和定性地比较我们的InstantMesh与现有的最先进的图像到3D基线方法。
4.1 实验设置
数据集。我们使用两个公开数据集进行定量性能评估,即Google Scanned Objects(GSO)[10]和OmniObject3D(Omni3D)[55]。GSO包含约1,000个物体,我们随机选择其中的300个物体作为评估集。对于Omni3D,我们选择了28个常见的类别,然后从每个类别中选择前5个物体,共计130个物体(某些类别少于5个物体)作为评估集。
为了评估生成的3D网格的2D视觉质量,我们为GSO和Omni3D分别创建了两个图像评估集。具体来说,我们在平均方位角和不同仰角下,以轨道轨迹呈现每个物体的21张图像,仰角为{30°,0°,-30°}。由于Omni3D还包括从对象的顶部半球上随机采样的基准视图,我们随机选择了16个视图,并为Omni3D创建了额外的图像评估集。
基线。我们将提出的InstantMesh与4个基线进行比较:(i) TripoSR [45]:迄今为止显示出最佳单视图重建性能的开源LRM实现;(ii) LGM [44]:基于unet的大型高斯模型,从生成的多视图图像中重建高斯;(iii) CRM [54]:基于unet的卷积重建模型,从生成的多视图图像和规范化坐标映射(CCM)中重建3D网格;(iv) sv3D [47]:基于稳定视频扩散的图像条件扩散模型,生成对象的轨道视频,我们仅针对新视图合成任务进行评估,因为直接从其输出生成3D网格并不简单。
度量。我们评估生成资源的2D视觉质量和3D几何质量。对于2D视觉评估,我们从生成的3D网格呈现新视图,并将其与地面真实视图进行比较,采用PSNR、SSIM和LPIPS作为度量标准。对于3D几何评估,我们首先将生成网格的坐标系与地面真实网格对齐,然后将所有网格重新定位和重新缩放为大小为[-1, 1]³ 的立方体。我们使用采样16K个点进行均匀表面采样,并报告Chamfer距离(CD)和F-Score(FS),阈值为0.2。
4.2 主要结果
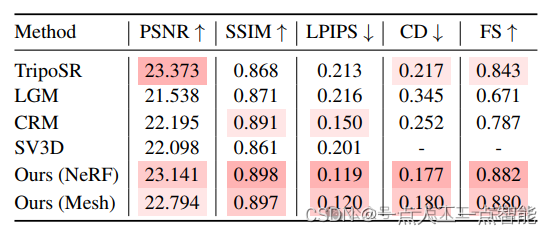
定量结果。我们分别在表2、表3和表4中报告了不同评估集上的定量结果。对于每个指标,我们突出显示了所有方法中排名前三的结果,颜色较深表示结果更好。对于我们的方法,我们报告了使用不同稀疏视图重建模型变体(即“NeRF”和“Mesh”)的结果。
从2D新视图合成指标中,我们可以看到InstantMesh在SSIM和LPIPS上明显优于基线方法,表明其生成结果具有最好的视觉质量。正如图3所示,InstantMesh展示了可信的外观,而基线方法在新视图中经常出现扭曲。我们还可以观察到InstantMesh的PSNR略低于最佳基线,这表明新视图在像素级上对地面真实性的忠实度较低,因为它们是由多视图扩散模型“幻想”出来的。然而,我们认为感知质量比忠实度更重要,因为“真正的新视图”应该是未知的,在给定单张图像作为参考时有多个可能性。
至于3D几何度量,InstantMesh在CD和FS上明显优于基线方法,这表明生成的形状具有更高的准确性。从图3可以看出,InstantMesh在所有方法中呈现出最可靠的几何形状。受益于可扩展的架构和量身定制的训练策略,InstantMesh实现了最先进的图像到3D性能。


定性结果。为了定性地比较我们的InstantMesh与其他基线方法,我们从GSO评估集中选择了两个图像,以及从互联网上选择了两个图像,并得到了图像到3D的生成结果。对于每个生成的网格,我们从两个不同的视点可视化纹理渲染(上部)和纯几何(下部)。我们使用“Mesh”变体的稀疏视图重建模型来生成我们的结果。
如图3所示,InstantMesh生成的3D网格呈现出明显更可信的几何形状和外观。TripoSR可以从与Objaverse数据集类似风格的图像中生成满意的结果,但它缺乏想象能力,并且在输入图像更自由风格时倾向于生成退化的几何形状和纹理(图3,第3行,第1列)。由于有高分辨率的监督,InstantMesh还可以生成比TripoSR更锐利的纹理。LGM和CRM与我们的框架类似,将多视图扩散模型与稀疏视图重建模型结合起来,因此它们也具有想象能力。然而,LGM显示出扭曲和明显的多视图不一致性,而CRM在生成平滑表面方面存在困难。

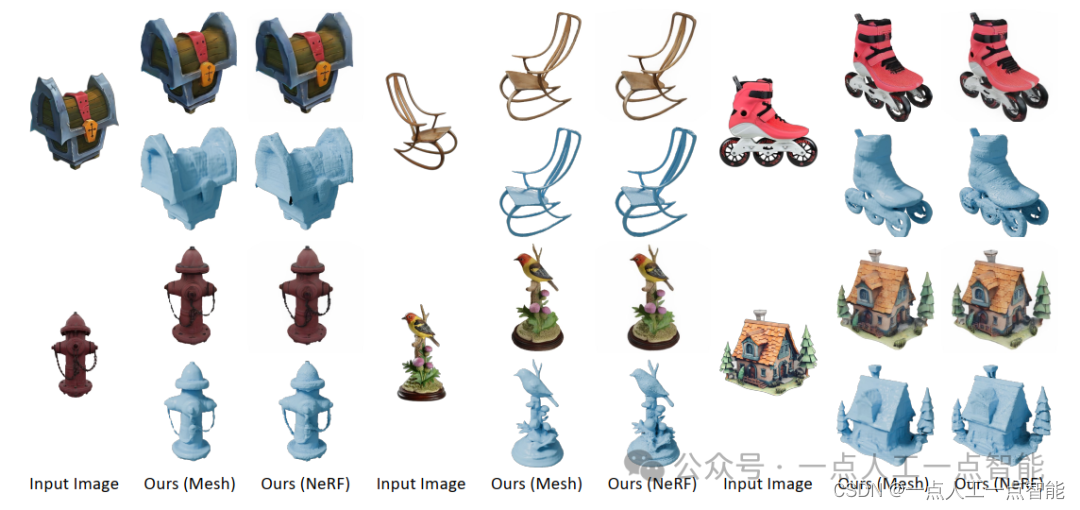
比较“NeRF”和“Mesh”变体。我们还定性和定量地比较了我们的稀疏视图重建模型的“Mesh”和“NeRF”变体。从表2、3和4中可以看出,“NeRF”变体在指标上略微优于“Mesh”变体。我们认为这是由于FlexiCubes的网格分辨率有限,当提取网格表面时会丢失细节。然而,考虑到与NeRF相比,高效的网格渲染带来的便利性相比内存密集型的体积渲染,指标下降较少且可以忽略不计。此外,我们还在图4中可视化了这两个模型变体的一些图像到3D生成结果。通过应用显式的几何监督,即深度和法线,与从NeRF的密度场中提取的网格相比,“Mesh”模型变体可以产生更平滑的表面,这在实际应用中通常更具有吸引力。
05 结论
在这项工作中,我们提出了InstantMesh,一个开源的即时图像到3D框架,使用基于transformer的稀疏视图大规模重建模型从多视图扩散模型生成的图像中创建高质量的3D物体。
在Instant3D框架的基础上,我们引入了基于网格的表示和额外的几何监督,显著提高了训练效率和重建质量。我们还在其他方面进行了改进,如数据准备和训练策略。
对公共数据集的评估表明,InstantMesh在定性和定量上优于其他最新的图像到3D基线方法。InstantMesh旨在为3D生成AI社区做出重要贡献,为研究人员和创作者提供支持。
局限性。我们注意到我们的框架仍然存在一些局限性,将其留作未来工作的方向。(i)遵循LRM [14]和Instant3D [19],我们基于transformer的triplane解码器生成64x64个triplane,其分辨率可能成为高清3D建模的瓶颈。(ii)我们的3D生成质量不可避免地受到扩散模型的多视图不一致性的影响,但我们相信未来可以通过使用更先进的多视图扩散架构来减轻这个问题。(iii)尽管FlexiCubes可以通过额外的几何监督提高网格表面的光滑性和减少伪影,但我们注意到与NeRF相比,在对微小和细长结构建模方面效果较差(图4,第2行,第1列)。