1. 背景
上一篇https://blog.csdn.net/wyw0000/article/details/137622977?spm=1001.2014.3001.5502中实现手撸代码的方式实现了手写数字识别,本文将使用pytorch的API实现。
2. nn.Linear线性层
相当于x = x@w1.t() + b1
因此可以使用nn.Linear代替,上一篇文中中的
w1, b1 = torch.randn(200, 784, requires_grad=True),\
torch.zeros(200, requires_grad=True)
x = x@w1.t() + b1
使用nn.Linear定义的三层网络,如下图所示:

增加激活函数relu

2. 实现MLP网络
- 实现__init__函数
- 将网络各层放到序列化容器Sequential中
见下图使用nn.Sequential创建一个小的model,运行时输入首先传给nn.Linear(784, 200),nn.Linear(784, 200)的输出再传给nn.ReLU(inplace=True),这样依次传递下去,直至结束。 - 实现forward
调用将输入x作为model的参数调用model,并将结果返回。

3. train
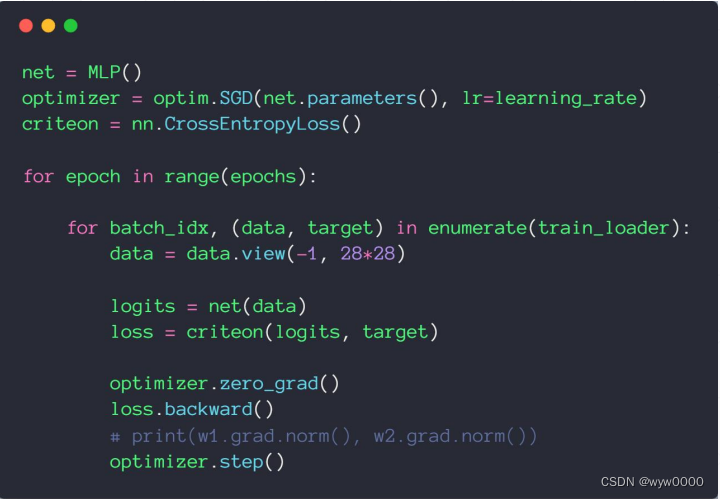
4. 完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
net = MLP()
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))