一. 六大日志
- 慢查询日志:记录所有执行时间超过long_query_time的查询,方便定位并优化。
# 查询当前慢查询日志状态
SHOW VARIABLES LIKE 'slow_query_log';
#启用慢查询日志
SET GLOBAL slow_query_log = 'ON';
#设置慢查询文件位置
SET GLOBAL slow_query_log_file = '/path/to/your/slow-query.log';
#设置慢查询的阈值 ,单位秒
SET GLOBAL long_query_time = 2
#记录所有未走索引的查询到慢查询日志
SET GLOBAL log_queries_not_using_indexes = 'ON';
- 通用查询日志:记录用户的所有操作,包括启动和关闭MySQL服务、所有用户的连接开始时间和截止时间、发给MySQL数据库服务器的所有SQL指令等,如select、show等,无论SQL的语法正确还是错误、也无论SQL执行成功还是失败,MySQL都会将其记录下来。通用查询日志用来还原操作时的具体场景,可以帮助我们准确定位一些疑难问题,比如重复支付等问题。
# 查询通用查询日志状态
show variables like '%general_log%';
# 打开通用查询日志
SET GLOBAL general_log=on;
# 设置通用查询日志文件位置
SET GLOBAL general_log_file='/path/to/your/general.log';
3.错误日志:记录了数据库启动和停止,以及运行过程中发生任何严重错误时的相
关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
在MySQL数据库中,错误日志功能是默认开启的,而且无法被关闭。
# 查看错误日志存放位置
show variables like '%log_error%';
4.二进制日志:即binlog日志,记录了所有执行过的修改操作语句,不保存查询语句。可用于数据库灾备和主从复制。
# 查看binlog相关参数
show variables like '%log_bin%';
打开或关闭binlog文件需要在mysql配置文件中修改(Mysql5.7默认关闭,Mysql8.0默认开启),然后重启数据库
# log‐bin设置binlog的存放位置,可以是绝对路径,也可以是相对路径,这里写的相对路径,则binlog文件默认会放在data数据目录下
log‐bin=mysql‐binlog
# Server Id是数据库服务器id,随便写一个数都可以,这个id用来在mysql集群环境中标记唯一mysql服务器,集群环境中每台mysql服务器的id不能一样,不加启动会报错
server‐id=1
# 其他配置
binlog_format = row # 日志文件格式
expire_logs_days = 15 # 执行自动删除binlog日志文件的天数, 默认为0, 表示不自动删除
max_binlog_size = 200M # 单个binlog日志文件的大小限制,默认为 1GB
binlog日志格式
在Mysql配置文件中可以设置binlog_format不同的参数来设置不同的binlog日志记录格式,MySQL支持三种binlog日志格式:
- statement:基于sql语句的复制,每一条修改语句都会记录到binlog日志中,这样的记录方式数据量小,节省I/O开销,但是遇到一直执行时才能确定结果的函数,例如:UUID(),RAND(),SYSDATE()等函数,如果使用binlog恢复数据或者从机通过binlog同步数据,则会出现不一致的问题。
- row:基于行的复制,日志中会记录成每一条记录的修改语句,可以解决函数、存储过程等问题,但是日志里较大,没有statement性能好。假设update语句更新10行数据,statement方式就记录这条update语句,row方式会记录被修改的10行数据。
- mixed:混合模式,两种方式的结合,MySQL会根据执行语句的不同来选择不同的记录方式,也就是statement和row中选一种,如果sql里有需要执行才能确定的函数,那么就用row的形式记录,其他情况就用statement。推荐用这种方式。
binlog写入磁盘的机制
binlog写入磁盘的方式由sync_binlog参数控制,默认是0
- 为0的时候,表示每次提交事务都只 write 到page cache,由系统自行判断什么时候执行 fsync 写入磁盘。虽然性能得到提升,但是机器宕机,page cache里面的 binlog 会丢失。
- 也可以设置为1,表示每次提交事务都会执行 fsync 写入磁盘,这种方式最安全。
- 还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write 到page cache,但累积N个事务后才 fsync 写入磁盘,这种如果机器宕机会丢失N个事务的binlog。
- 中继日志:MySQL8.0加入的日志,用于主从服务器架构中,从服务器存放主服务器二进制日志的一个中间文件,从服务器通过读取中继日志,来同步主服务器的操作。
- 数据定义语句日志:MySQL8.0加入的日志,记录数据定义语句执行的元数据操作。
InnoDB的三大特性
双写缓冲区
innodb的基本操作单位是数据页,一个页是16KB,而系统和磁盘间的数据操作是以4KB为操作单位进行的,这样一个数据页写入对应到磁盘可能需要执行多次,极端情况下,可能会出现数据页只写前面一部分,然后发生系统宕机的问题。
对于这样的极端情况就可以使用双写缓冲区来恢复
- 在执行脏页刷盘时MySQL实际会写两份,一份通过顺序写写到双写缓冲区文件,一份随机写写到磁盘也就是数据的实际落盘
- 通过fsync多写一次数据到双写缓冲区,虽然顺序写大概还是会造成5%-10%的性能消耗,但是能保证数据的安全
- 数据写入双写缓冲区成功,真实落盘失败时,会通过双写缓冲区拿到写入的数据重新落盘
- 数据写入双写缓冲区如果失败,MySQL会通过B+树载入原始数据,通过redoLog恢复原始数据
自适应的hash索引
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,这个二级索引建立对应的哈希索引提高性能(这个hash索引是存在BufferPool上的)
BufferPool
主从复制架构
背景
在一个简单的web应用后端架构中通常是一个nginx用来转发请求,一个redis用来缓存数据减少一些热点访问数据频繁访问数据库,最后就是一个mysql用来做数据的持久化保存。但是在这样的单机部署情况下,如果出现单点故障的问题,例如数据库、java应用或者redis任意一个宕机,都会造成整个系统的不可用。
MySQL的主从复制就是MySQL官方提出来的一种方案,是MySQL使用最广泛的容灾方案。
原理和步骤
MySQL的主从复制机制就是主机进行修改操作时会保存一份binlog日志,里面记录了数据的相关操作,从库通过网络获取到主库的binlog,然后自己重复一遍binlog中的操作,即可完成数据同步。
步骤如下:
- 客户端链接主机,发送写操作命令
- 主库在事务提交时会将操作写入binlog日志文件
- 从库根据记录的主库binlog文件名和position通过I/O线程向主库获取相应位点之后的binlog文件
- 主库通过dump线程获取到binlog并发送给从库
- 从库将获取到的binlog写入relaylog中,并给主库返回响应
- 从库的sql线程读取并解析relaylog
- 从库的 SQL 线程重放 relay log 中的命令
复制方案
异步复制
MySQL默认使用异步复制,执行事务和复制binlog是由两个不同的线程去完成的,互不等待,这样的方式响应性能最高,但是如果复制延迟,或者复制过程中主库宕机都会发生丢数据的情况
使用
1.添加配置
主库
#主库
# 服务器唯一ID,默认是1
server-id=10
#启用二进制日志
log-bin=mysql-bin
#待同步的数据库日志
#replicate_do_db= test
#不同步的数据库日志
#replicate_ignore_db= test
从库
#主库
# 服务器唯一ID,默认是1
server-id=11
#启用二进制日志
log-bin=mysql-bin
2.主库操作
# 连接主库
CREATE USER 'test'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'test'@'%';
flush privileges;
#获取主库的binlog文件名和位点信息,从库同步时需要
SHOW MASTER STATUS;

3.从库操作
#链接从库
#1.设置主库信息
#mysql8.0.23之前
change MASTER to MASTER_HOST='192.168.65.185', MASTER_USER='test',
MASTER_PASSWORD='123456', MASTER_port=3307, MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=1273;
#mysql8.0.23之后
change replication source to source_host='192.168.65.185', source_user='test',
source_password='123456', source_port=3307, source_log_file='mysql-bin.000003',
source_log_pos=1273, source_connect_retry=30;
#2.开启同步复制
#开启从库
start slave; 或者 start replica;
#查看从库状态
show slave status \G; 或者 show replica status \G;
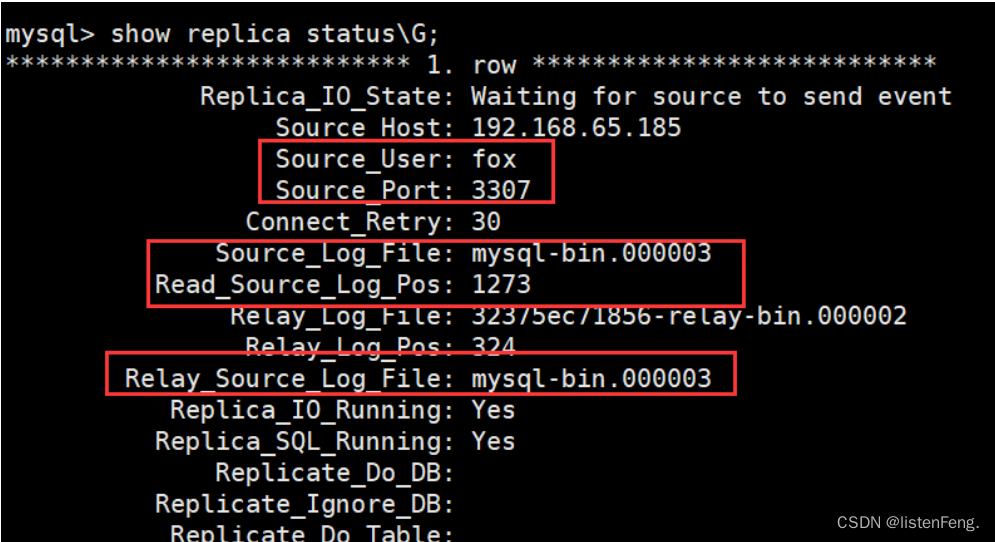
半同步复制
基于异步复制容易出现数据丢失的问题,MySQL从5.7开始增加了一种半同步复制的方式。具体机制如下:
- 主库在收到客户端的请求时,必须在完成主库日志写入的同时,还需要等待一个或多个从库完成数据同步的响应之后,才能响应请求
- 从库只有在relaylog写入完成后,才会向主库响应
- 当从库响应超时时,主库会将半同步复制退化为异步复制(即不再去等待从库的响应)。直到至少一个从库恢复,并同步到最新的数据之后,主库才会再次将同步机制恢复为半同步复制
因为需要保证至少一个从节点的响应,所以半同步复制的响应性能相比异步复制要有所降低,但是在主库没有没有退化至异步复制的情况下,如果发生宕机,至少可以保证有一个从库的数据是完整的,那么就可以将这个从库先升为主库,其他从库从这个新的主库中获取数据
半同步复制有两个重要的参数: - 8.0.26及之前
- rpl_semi_sync_master_wait_slave_count:至少等待数据复制到几个从节点再返回。这个数量配置的越大,丢数据的风险越小,但是集群的性能和可用性就越差。
- rpl_semi_sync_master_wait_point:这个参数控制主库
执行事务的线程,是在提交事务之前(AFTER_SYNC)等待复制,还是在提交事务之后(AFTER_COMMIT)等待复制。默认是 AFTER_SYNC,也就是先等待复制,再提交事务,这样就不会丢数据。
- 8.026之后
- rpl_semi_sync_source_wait_for_replica_count:至少等待数据复制到几个从节点再返回。
- rpl_semi_sync_source_wait_point:控制主库
执行事务的线程,是在提交事务之前等待复制,还是在提交事务之后等待复制。默认是 AFTER_SYNC
使用
使用方式和异步复制类似,但是主从库都需要安装插件并增加一些配置
可以直接在异步复制的基础上去调整
1.主从库安装插件
主库、从库分别执行
#from MySQL 8.0.26:
INSTALL PLUGIN rpl_semi_sync_source SONAME'semisync_source.so';
#验证是否成功安装
SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%';
2.启用半同步复制
主库、从库分别执行
SET GLOBAL rpl_semi_sync_source_enabled=1;
#持久化全局变量
set persist GLOBAL rpl_semi_sync_source_enabled=1;
#查看是否开启
show variables like "%semi_sync%";
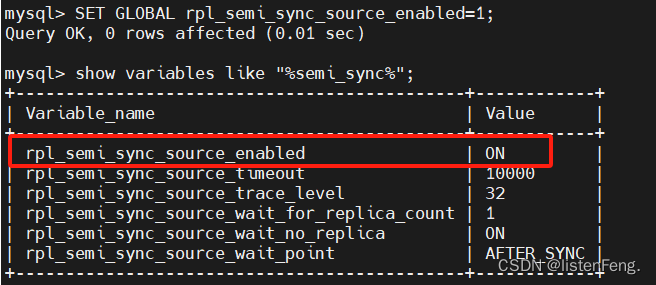
3.重启从库的I/O线程
STOP REPLICA IO_THREAD;
START REPLICA IO_THREAD;
基于全局事务标识符(GTID)复制
上述的异步复制和半同步复制都是基于位点的复制,同步时需要手动获取和设置从库的同步位点,这样的步骤繁杂且容易出错,所以MySQL 5.6 版本引入了 GTID,彻底解决了这个困难。
GTID是一个基于原始mysql服务器生成的一个已经被成功执行的全局事务ID,它由服务器ID以及事务
ID组合而成。这个全局事务ID不仅仅在原始服务器器上唯一,在所有存在主从关系 的mysql服务器上
也是唯一的。正是因为这样一个特性使得mysql的主从复制变得更加简单,以及数据库一致性更可靠。
通过GTID实现复制方案不再需要人工确认从库开始同步的位点,交由服务器自动判断。主库通过计算主库的GTID和从库GTID的之间的差,判断出从库未同步的binlog并推送给从库。
使用
基于上面异步复制中已完成的配置进行调整
1.添加配置文件
主库、从库分别执行
#GTID:
#启用全局事务标识符(GTID)模式
gtid_mode=on
# 强制GTID的一致性。这意味着在执行事务时,MySQL将确保所有涉及的服务器都使用相同的GTID集。
enforce_gtid_consistency=on
2.从库设置主库信息
#停止主从复制
stop replica;
#mysql8.0.23之前
change MASTER to MASTER_HOST='192.168.65.185', MASTER_USER='test',
MASTER_PASSWORD='123456', MASTER_port=3307, MASTER_AUTO_POSITION = 1;
#mysql8.0.23之后
change replication source to source_host='192.168.65.185', source_user='test',
source_password='123456', source_port=3307, SOURCE_AUTO_POSITION =1 ;
# 开启主从复制
start replica
组复制
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制通过判断响应个数来决定是否响应客户端,保证了一定的数据一致性,但是仍无法数据一致性要求高的场景,例如金融领域。MySQL在5.7.17中推出了一种高可用与高扩展的复制方案,将原有的GTID复制功能进行了增强,实现了基于paxos协议的状态机复制,即组复制(Mysql GroupReplication 简称MGR) 。
组复制的工作原理
- Paxos协议:MySQL组复制使用Paxos协议来实现分布式一致性。Paxos协议是一种用于解决分布式系统中一致性问题的协议,它通过多轮投票来达成共识(粗略理解即为需要组内超过一半的成员同意提交,才可进行读写事务的提交,对于只读事务,直接commit即可,不需要经过组内同意)。
- 组成员管理:组复制通过组成员管理模块来维护集群中的节点列表。当节点加入或离开集群时,组成员管理模块会更新集群的配置。
- 数据复制:组复制使用MySQL的二进制日志(binlog)来复制数据变更(GTID复制)。每个节点都会将本地的binlog事件发送给其他节点,以确保所有节点的数据保持一致。
- 单点故障转移:当一个节点发生故障时,组复制会自动将其从集群中移除,并由其他节点接管其工作。这个过程不需要人工干预,可以自动完成。
- 冲突检测与解决:在多主模式下,如果多个节点同时尝试修改同一行数据,可能会发生冲突。组复制提供了多种冲突解决策略,包括:
- 版本号:为每个数据行添加一个版本号,当冲突发生时,选择版本号最高的数据。
- 时间戳:为每个数据行添加一个时间戳,当冲突发生时,选择时间戳最新的数据。
- 自定义:允许用户定义自己的冲突解决逻辑。
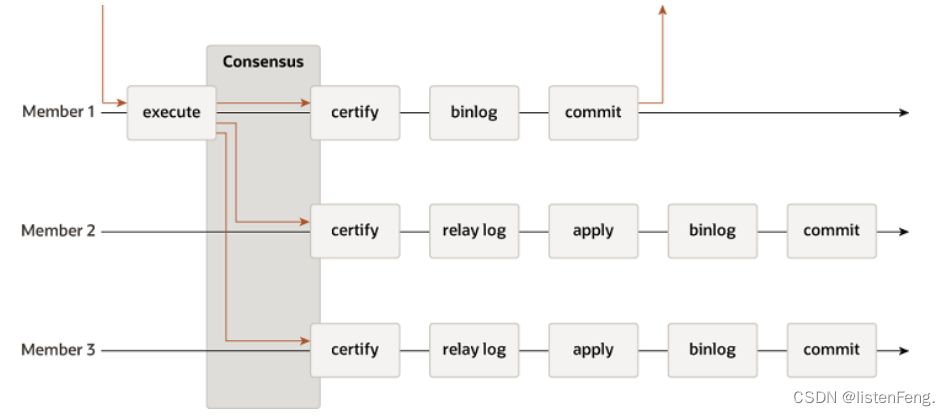
组复制提供了单主模式和多主模式两种
- 单主模式:只有主节点可以读写,从节点都是只读,为部署组复制的推荐模式,主节点宕机会进行单点故障转移,步骤如下:
- 组内的每个成员都会维护自己的状态信息,包括是否在线和配置信息
- 当单主模式下的主节点宕机时,组内剩余的成员会先根据配置的权重来选择新的主节点
- 如果配置的权重相同则根据组内成员的服务器UUID进行排序然后选择第一个作为主节点(所以最好给每个节点配置不同的权重,以避免权重相同的情况,确保选举过程的明确性)
- 多主模式:每个节点都可以进行读写,不存在故障转移,因为每个节点都可以独立的完成事务,但是多个节点同时尝试修改同一行数据,可能会发生冲突,需要进行处理
InnoDB cluster
组复制提供了强数据一致性和单点故障转移,保证了数据库的连续可用,却无法处理如下问题:当一个组成员变为不可用时,连接到它的客户端必须被重定向或故障转移到其他组成员,但是MySQL不会主动通知客户端去重定向。基于此,MySQL提供了InnoDB Cluster。
InnoDB Cluster是MySQL官方实现高可用+读写分离的架构方案,其中包含以下组件:
- MySQL Group Replication,简称MGR,是MySQL的主从同步高可用方案,包括数据同步及角色选举
- Mysql Shell 是InnoDB Cluster的管理工具,用来创建和管理集群
- Mysql Router 是业务流量入口,支持对MGR的主从角色判断,可以配置不同的端口分别对外提供读写服务,实现读写分离
MySQL Router与组复制和MySQL Shell高度整合,只有将其与组复制和MySQL Shell共同使用,才能
够称为InnoDB Cluster。
注:需要注意的是上述所有方案,每个MySQL节点都是全量数据