面试准备【面试准备】
前言
2023-08-30 17:07:19
公开发布于
2024-5-22 00:08:06
面试准备
自我介绍:
面试官,你好
项目介绍:
论坛项目 是软件工程实验的一个项目
使用了Springboot、Mybatis、MySQL、Redis、Kafka等工具。
主要实现了用户的注册、登录、发帖、点赞、系统通知、按热度排序、搜索等功能。
引入了redis、mysql来提升网站的整体性能,实现了用户凭证的存取、点赞关注的功能。
基于Kafka实现了系统通知:当用户获得点赞、评论后得到通知。
利用定时任务定期计算帖子的分数,并在页面上展现热帖排行榜。
秒杀项目 模仿京东实现的一个秒杀项目
实现了用户注册和登录,显示商品列表和详情,用户下单
使用Reids缓存商品与用户,做了简单的削峰限流
采用异步化扣减库存,使用rocketmq消息队列解决超卖问题

论坛项目功能总结
主要使用了Springboot、Mybatis、MySQL、Redis、Kafka、等工具。
主要实现了用户的注册、登录、发帖、点赞、系统通知、按热度排序、搜索等功能。
另外引入了redis数据库来提升网站的整体性能,实现了用户凭证的存取、点赞关注的功能。
基于 Kafka 实现了系统通知:当用户获得点赞、评论后得到通知。
利用定时任务定期计算帖子的分数,并在页面上展现热帖排行榜。
数据库表设计
user
#id Iusername password salt Iemail type status activation_code header_url create_time
discuss_post
#id Iuser_id title content type status create_time comment_count score
comment
#id primary key Iuser_id entity_type Ientity_id target_id content status create_time
message
#id Ifrom_id Ito_id Iconversation_id content status create_time timestamp null
login_ticket
#id user_id Iticket status expired
注册功能
前端输入:用户名,密码,和邮箱
通过表单提交数据(账号、密码、邮箱)
服务端处理register()
调用service层
空值处理 验证账号 验证邮箱
/*虽然说账号和邮箱是普通索引,但是在应用层保证了其唯一性*/
注册用户
密码使用md5盐值加密
/*
md5 王小云团队破解了,sha-1
“彩虹表”(Rainbow Table)是一种预先计算的表格,用于加速哈希函数的逆向破解过程。
通过预先计算大量的输入和对应的哈希值,将它们存储在表格中。
当需要破解某个哈希值时,可以在预先计算好的表格中查找对应的输入值。
*/
激活码UUID
// http://localhost:8080/community/activation/101/code
发送激活邮件
返回操作(注册)-结果(成功)页面|返回注册页面
用户点击激活邮件
服务端调用activation()
调用service层
用户状态==1:重复激活
激活码相同:设置状态为1,激活成功
激活失败
跳转到操作(激活)-结果页面
登录功能
用户进入登录页面,就会请求后端,获取验证码
原来是把验证码存入session中
后面是存入cookie中,进而存入redis中
/*
给每一个访客生成一个UUID,存入到cookie中
redis使用uuid作为键,验证码结果作为值
可以作访客匿名登录方式来浏览网站,再进行其他操作,再使用账密登录
这个功能好像没有实现
*/
cookie(kaptchaOwner,UUID) (KaptchaKey_redisKey,验证码结果,60s)
用户填写信息:账号、密码、验证码
提交表单
后端就调用login方法
取出验证码的答案
原来是session中取出
后来是Cookie-->kaptchaOwner-->(Redis)kaptcha
验证码正确:下一步 ;否则返回错误信息
验证:用户名,密码
调用Service层
空值处理 验证账号 验证状态(用户的激活状态) 验证密码
如果都正确就生成登录凭证(userId ticket status )
原来的登录凭证是插入到一个数据库表中
后来是存入到redis中
通过Map返回错误信息,或者登录凭证
如果有登录凭证,就跳转到首页
并且把ticket存入到cookie中
如果没有,就返回错误信息
显示登录信息功能
编写一个拦截器:LoginTicketInterceptor
preHandle()
//Controller执行之前,拿到登录用户
在Cookie中获取凭证
//数据库查询登录凭证的状态
后来使用redis存凭证
本次请求持有用户 https://www.nowcoder.com/study/live/246/2/27 38::48
存入HostHolder(ThreadLocal) 多线程存储代替Session存储
postHandle()
//Controller执行之后:把loginUser返回mav
从HostHolder中拿到用户
存入mav中
afterCompletion()
//请求处理完毕
清理HostHolder
配置WebMvcConfig:登录拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(loginTicketInterceptor)
.excludePathPatterns("/**/*.css", "/**/*.js", "/**/*.png",
"/**/*.jpg", "/**/*.jpeg");
}
发布帖子
在MySQL中保存帖子
调用service层
转义HTML标记 过滤敏感词
触发发帖事件来进行系统通知,并且同步es中的数据
记录帖子分数
存入id到redis中,
定时任务查看需要刷新的帖子
计算帖子分数,更新到数据库中
order by来进行排序
评论
存储评论
调用service层
事务
添加评论 转义HTML标记 过滤敏感词
更新帖子评论数量
如果是回复的话(评论评论)
触发评论事件
如果是评论的话(评论帖子)
触发发帖事件
计算帖子分数
存入id到redis中,来进行排行
重定向到帖子详情
私信
构建消息对象
ConversationId(小id_大id)
status:0是未读,1是已读,2是删除
调用service层
转义HTML标记 过滤敏感词
设置已读:把所有未读的消息都设置为已读
点赞功能
点赞
点赞使用set存储用户id
判断是否点赞过可以在set中取到不?isMember()
redis事务
isMember()//需要先查
multi()
添加|移除 用户
增加|减少 点赞数量
exec()
数量
状态
返回的结果(数量和状态)
触发点赞事件
如果是对帖子点赞
计算帖子分数
关注功能
关注
调用service层
redis事务
multi()
add关注列表
add粉丝列表
exec()
触发关注事件
取关
调用service层
redis事务
multi()
remove关注列表
remove粉丝列表
exec()
通知
kafka
通知表没有单独设计,而是复用了私信表
| id | from_id | to_id | conversation_id | content | status | create_time |
|---|---|---|---|---|---|---|
| 39 | 111 | 131 | 111_131 | 嘎嘎嘎 | 0 | 2022-08-23 15:27:06 |
| 92 | 1 | 111 | like | {“entityType”:1,“entityId”:237,“postId”:237,“userId”:112} | 1 | 2022-08-23 15:27:06 |
| 主键 | 发 | 收 | 交流id:小_大 | 内容 | ‘0-未读;1-已读;2-删除;’ | 时间 |
| 主键 | 1是系统发通知 | 收 | 主题 | 信息 | ‘0-未读;1-已读;2-删除;’ | 时间 |
搜索
es
搜索帖子
聚合数据 (帖子 作者 点赞数量)
分页信息
使用kafka保证数据库和es的一致性
发布帖子和删除帖子,都会利用kafka来在es中保存和删除
网站数据统计
统计网站UV getUV()
调用service层
整理该日期范围内的key
合并这些数据
union()
返回统计的结果
统计活跃用户DAU getDAU()
调用service层
整理该日期范围内的key
进行OR运算
OR bitCount
返回统计的结果
使用Redis的高级数据结构:
HyperLogLog:超级日志,统计独立整数个数。统计UA(独立访问)时,以日期为 rediskey ,将客户端IP add 到HyperLogLog中(redisTemplate.opsForHyperLogLog().add(redisKey, i);)
Bitmap:位图,比如365天的签到,只需要365/8个字节的大小。统计DAU(日活跃用户)时,以日期为 rediskey ,以用户ID作为位(在数据中的位置),用 or 操作,既可以方便的统计一段时间内的注册用户访问人数。
热帖排行
mysql order by
执行刷新的方法
判断Redis中没有需要刷新的帖子id
执行刷新方法
刷新帖子分数 refresh()
是否精华
评论数量
点赞数量
计算权重=精华分+评论数×10 +点赞数×2
分数 = log10(max(帖子权重,1) + 距离天数
更新帖子分数
同步搜索数据
缓存
缓存帖子
本地缓存
redis缓存
mysql中
缓存用户
查询用户的时候,
1.优先在缓存中取
2.取不到,初始化缓存
3.数据变更时清除缓存数据
更新数据的数据库与缓存的一致性:
先更新数据库,再删除缓存
论坛项目技术总结
Http的无状态
HTTP(Hypertext Transfer Protocol)是一种无状态协议。这意味着每个HTTP请求都是独立的,服务器不会保留之前的请求信息或状态。
当客户端发送HTTP请求到服务器时,服务器会根据请求的内容做出响应,但服务器不会记住之前的请求或客户端的状态。每个请求都是相互独立的,服务器不会在请求之间建立连接或保持会话。
这种无状态的设计使得HTTP具有一些优势,包括简单、高效和可扩展。无状态的HTTP允许服务器处理大量的并发请求,并且不需要为每个请求维护额外的状态信息。这降低了服务器的负担,并使得系统更具可伸缩性。
然而,由于HTTP是无状态的,它限制了服务器在处理多个请求时共享和存储用户状态的能力。为了解决这个问题,通常会使用Session、Cookie或其他机制来实现状态的跟踪和管理。
cookie和session的区别
Cookie和Session是两种常见的用于在Web应用中跟踪用户状态和存储用户相关数据的机制。它们的主要区别如下:
存储位置:
Cookie:Cookie是存储在用户浏览器中的小型文本文件。服务器通过响应头将Cookie发送给客户端浏览器,并由浏览器保存在本地。当浏览器再次请求同一网站时,会在请求头中自动将相应的Cookie发送给服务器。
Session:Session是存储在服务器端的一种数据结构。每个Session都有一个唯一的会话ID,服务器将会话ID通过Cookie或URL参数发送给客户端,客户端在后续请求中通过会话ID来标识自己。
数据存储:
Cookie:Cookie可以存储少量的键值对数据。每个Cookie的大小通常有限制(如4KB),因此适合保存较小的数据。
Session:Session可以存储更大、更复杂的数据结构,如对象和数组。因为Session数据存储在服务器端,所以没有明确的大小限制。
安全性:
Cookie:Cookie是存储在客户端的,容易受到安全攻击。为了增加安全性,可以使用加密和签名等机制来保护Cookie的内容。
Session:Session存储在服务器端,相对而言更安全。然而,Session ID 可能会受到会话劫持和会话固定攻击等安全威胁,因此需要采取相应的防护措施,如使用HTTPS协议和生成随机的会话ID。
生命周期:
Cookie:Cookie可以设置过期时间,可以是会话Cookie(存储在内存中,关闭浏览器即失效)或持久Cookie(存储在硬盘上,过期时间之前有效)。
Session:Session通常在用户第一次访问网站时创建,并在用户关闭浏览器或超过一定时间(如30分钟)无活动时过期。
综上所述,Cookie适用于需要在客户端存储少量简单数据的场景,而Session适用于需要在服务器端存储较大复杂数据且需要一定安全性的场景。在实际应用中,Cookie和Session通常是结合使用的,Cookie用于存储会话ID,而Session用于存储用户的具体数据。
为什么要使用多线程本地存储,代替Session?
使用多线程本地存储代替Session的主要原因是解决在多线程环境下使用Session可能出现的线程安全问题。
Session是一个服务器端的存储机制,用于保存用户的会话信息。在多线程环境下,如果不进行额外的处理,每个线程都会共享同一个Session对象,这可能导致以下问题:
线程安全问题:多个线程同时访问和修改同一个Session对象时,可能会引发竞争条件和并发访问问题。这可能导致数据不一致、数据丢失或者系统崩溃。
性能问题:由于Session是服务器端存储,多个线程同时对Session进行读写操作时,可能会引起性能瓶颈。尤其在高并发场景下,频繁的Session读写操作可能成为系统的瓶颈。
为了解决这些问题,可以使用多线程本地存储来代替Session。多线程本地存储是指为每个线程维护一个独立的存储空间,使得每个线程都可以独立操作自己的存储空间,从而避免了线程安全问题和性能问题。
多线程本地存储可以使用ThreadLocal来实现。ThreadLocal是一个线程本地变量,每个线程都有自己独立的ThreadLocal变量副本,并且每个线程可以独立修改自己的副本,而不会影响其他线程的副本。这样就可以在多线程环境下,为每个线程维护独立的存储空间,避免线程安全问题和性能问题。
综上所述,使用多线程本地存储代替Session可以提供更好的线程安全性和性能,在多线程环境下更加可靠和高效。
CSRF
跨站请求伪造(Cross-Site Request Forgery,CSRF)是一种恶意攻击,攻击者通过伪装合法用户的请求来执行非法操作。CSRF攻击利用了Web应用程序对用户发出的请求缺乏验证机制的漏洞。
攻击者通常会利用用户已经登录的状态来进行CSRF攻击。攻击者会在恶意网站上嵌入特制的代码,当用户访问这个网站时,恶意代码会发送伪造的请求到目标网站上。目标网站会将这个请求当作是合法用户的请求,并且执行对应的操作,从而达到攻击者的目的。
为了防止CSRF攻击,可以采取以下措施:
验证来源(Referer):在服务器端验证请求的来源,确保请求来自于合法的网站。这种方法依赖于浏览器发送请求时自动添加的Referer头,但是这个头可能被篡改或者被禁用。
添加随机令牌(Token):在每个表单中添加一个随机生成的令牌,该令牌会在服务器端进行验证。攻击者无法获取到合法用户的令牌,因此无法伪造合法的请求。
同源策略(Same-Origin Policy):浏览器的同源策略会阻止网页从一个不同源的网址获取或发送数据。这种策略可以防止恶意网站获取到用户的登录状态,从而防止CSRF攻击。
使用验证码:在一些敏感操作上使用验证码,要求用户输入验证码才能执行操作。这可以有效防止CSRF攻击,因为攻击者无法获取到正确的验证码。
综合使用以上多种防护措施可以提高系统的安全性,防止CSRF攻击。在开发Web应用程序时,应该注意对用户请求的验证和防护措施的实施,确保应用程序的安全性。
JWT
JWT(JSON Web Token)是一种用于在网络应用之间传递信息的开放标准(RFC 7519)。它是基于JSON的轻量级认证机制,用于在客户端和服务器之间安全地传递信息。
JWT由三个部分组成:头部(Header)、载荷(Payload)和签名(Signature)。
头部(Header):包含了两个部分,分别是令牌的类型和采用的加密算法(例如HMACSHA256、RSA等)。头部通常是Base64编码的JSON字符串。
载荷(Payload):包含了一些声明和数据。声明是一些有关实体(用户)和其他数据的声明,可以包括用户ID、角色、过期时间等。载荷也是Base64编码的JSON字符串。
签名(Signature):使用私钥对头部和载荷进行加密生成签名。签名用于验证JWT的真实性和完整性,确保JWT在传输过程中没有被篡改。签名通常由头部、载荷、密钥和指定的加密算法生成。
使用JWT进行身份验证的流程如下:
用户提供用户名和密码进行登录。
服务器验证用户的身份信息,如果验证成功,生成JWT并返回给客户端。
客户端将JWT保存在本地,以后的请求中都会携带该JWT。
服务器收到请求后,会验证JWT的签名和有效期,如果验证通过,处理请求。
JWT的优点是轻巧、可扩展和易于传递。由于JWT包含了自身的认证信息,减少了对服务器存储状态的需求,使得跨多个服务的分布式应用变得更加容易。但需要注意的是,由于JWT的所有信息都是可见的,因此不应将敏感信息存储在JWT中,以防止信息泄露的安全风险。

#1.认证流程
- 首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。
- 后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT。形成的JWT就是一个形同111.zzz.xxx的字符串。 token head.payload.singurater
- 后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。
- 前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)
- 后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。
- 验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。
#2.jwt优势
- 简洁(Compact):可以通过URL,POST参数或者在HTTP header发送,因为数据量小,传输速度也很快
- 自包含(Self-contained)︰负载中包含了所有用户所需要的信息,避免了多次查询数据库
- 因为Token是以JSON加密的形式保存在客户端的,所以JWT是跨语言的,原则上任何web形式都支持。
- 不需要在服务端保存会话信息,特别适用于分布式微服务。
redis的使用
五种数据结构
string hash list set zset
string
存储登录验证码结果
做缓存 缓存用户信息
先更新数据库再删除缓存
1.优先从缓存中取值
2.取不到初始化缓存数据
3.数据变更时清除缓存数据
set
存储点赞
点赞和取赞是根据redis是否赞列表存储过该用户
无:点赞;存:取赞
事务:添加用户 add() 点赞increment()
事务:移除用户 remove移除 取赞decrement()
查询某实体点赞的数量 size()
查询某人对某实体的点赞状态 isMember()
查询某个用户获得的赞 get()
存储需要书刷新帖子分数的帖子id
key:帖子分数
value:discussPostId
用来定时刷新帖子分数的
zset
存储关注列表、粉丝列表
score 日期 按时间降序排列
事务:关注 add添加 关注列表 粉丝列表
事务:取消关注 remove移除 关注列表 粉丝列表
查询关注|粉丝数量 zCard()
查询当前用户是否已关注该实体 score()
查询某用户关注的人 reverseRange() 取出id再到User表中查询
查询某用户的粉丝 reverseRange() 取出id再到User表中查询
hyperLogLog
统计uv
存储ip add()
指定日期统计union()
bitmap
统计dau
存储userId setBit()
统计指定日期范围内的DAU OR运算 bitCount()
Kafka的使用
系统通知事件:发送系统消息(关注、点赞、评论)
发帖或删帖事件:es数据和MySQL中的同步
es的使用
搜索帖子
与mysql的一致性是通过kafka来实现的
什么是ElasticSearch,存储原理,功能,特点
概念:ES是一个基于lucene构建的,分布式的,RESTful的开源全文搜索引擎。
存储原理:数据按照Index – Type – Document – 字段四级存储,其中Index对应数据库,Type对应表,Document为搜索的原子单位,包含一个或多个容器,基于JSON表示。字段是指JSON中的每一项组成,类似于数据库中的行/列。Mapping是文档分析过滤后的结果,根据用户自定义,将某些文字过滤掉,类似于表结构定义DDL??。同时ES也和分布式数据库一样,支持shard的replication。
功能:
1、分布式的搜索引擎和数据分析引擎
2、全文检索,结构化检索,数据分析。
3、对海量数据进行近实时的处理
特点:
1、可以作为分布式集群处理PB级别的数据,也可单机使用。
2、不是特有技术,而是将分布式+全文搜索(lucene) + 数据分析合并在一起。
3、操作简单,作为传统数据库的补充,提供了数据库所不具备的很多功能。
Quartz的使用
redis存储需要刷新的帖子id
定时任务刷新帖子分数
到mysql中
什么是Quartz,特点,专业术语,项目应用
概念:quartz是一个开源项目,完全基于java实现。是一个优秀的开源调度框架。
特点:
1,强大的调度功能,例如支持丰富多样的调度方法
2,灵活的应用方式,例如支持任务和调度的多种组合方式
3,分布式和集群能力
专业术语:
scheduler:任务调度器 , scheduler是一个计划调度器容器,容器里面有众多的JobDetail和trigger,当容器启动后,里面的每个JobDetail都会根据trigger按部就班自动去执行
trigger:触发器,用于定义任务调度时间规则
job:任务,即被调度的任务, 主要有两种类型的 job:无状态的(stateless)和有状态的(stateful)。一个 job 可以被多个 trigger 关联,但是一个 trigger 只能关联一个 job
misfire:本来应该被执行但实际没有被执行的任务调度
项目应用:定时的统计帖子分数(如何设置定时任务和trigger)
什么是Caffeine,如何缓存,项目应用
概念:Caffeine 是一个基于Java 8的高性能本地缓存框架
初始化cache:缓存保存的对象,使用Caffeine.newBuilder()创建,创建时设置缓存大小,过期时间,缓存未命中时的加载方式。
为什么只缓存热度帖子?答:因为不会经常变。
秒杀项目
1数据设计
用户 user_info
#id Uphone password密码 nickname昵称 gender性别 age年龄
商品 item
#id title price sales image_url description
商品库存表 item_stock
#id Uitem_id stock
商品活动 promotion
#id name start_time end_time U:item_id promotion_price
订单表 order_info
#id user_id item_id promotion_id order_price order_amount order_total order_time
序列号表 serial_number
#U name具体业务 value值 step步长
库存流水表 item_stock_log
#id UUID item_id哪个商品 amount购买数量 status状态 '0-default; 1-success; 2-failure;'
2用户注册
用户:
- 点击个人注册
- 输入手机号
- 点击获取验证码
前端请求后端:获取验证码
// 生成OTP
UUID:4位的随机数(0~9)
// 绑定OTP
2用户注册与登录:后端:把验证码存入到session中
6分布式状态管理:存入到redis中的<phone,otp,5mins>
// 发送OTP
输出到控制台里
改为短信发送
短信验证码【java提高】
用户填写信息(手机号和密码),点击立即注册
前端请求后端:注册
UserController:调用register()
// 验证OTP
2用户注册与登录:session.getAttribute()
6分布式状态管理:取到phone对应的otp
// 加密处理
// 注册用户
2用户登录
用户输入手机号和密码
前端请求后端:登录
后端调用login()
校验用户名和密码
2用户注册与登录:存入loginUser到session中
6分布式状态管理:存入到redis中的<token,loginUser>中 返回token给前端
前端:把返回的token存入到浏览器sessionStorage
每次ajax异步请求都会带上token,为了得到当前登录用户
前端请求时,把token放入到请求头的Authorization字段中
后端获取token,在redis中查询用户返回JSON
3商品列表和详情
商品列表
除了数据库表设计的范式
之外还考虑到了库存和商品信息的一个锁的粒度
商品
dao层不需要商品,库存,活动三表的连接
在业务层中拼接ValueObject
//查询出来所有的商品
public List<Item> findItemsOnPromotion() {
List<Item> items = itemMapper.selectOnPromotion();
return items.stream().map(item -> {
// 查库存
ItemStock stock = itemStockMapper.selectByItemId(item.getId());
item.setItemStock(stock);
// 查活动
Promotion promotion = promotionMapper.selectByItemId(item.getId());
if (promotion != null && promotion.getStatus() == 0) {
item.setPromotion(promotion);
}
return item;
}).collect(Collectors.toList());
}
商品详情
查询本地缓存 guava 初始10 最大100 过期1分种
查询redis缓存 3分种
查询mysql
7缓存商品与用户
缓存商品信息
先找本地guava缓存guava 初始10 最大100 过期1分种
在找redis缓存 3分种
在查找商品信息中添加缓存
在显示商品信息时访问缓存
缓存用户信息
没有使用本地缓存,不适合
本地缓存应缓存最重要最频繁的数据,数据量不应该太大
在查找用户时添加缓存
获取redis秒杀令牌的检查用户的时候
在创建订单中访问缓存
再次校验用户
8异步化扣减库存
rocketmq的事务型消息
两阶段提交
保证消息的一致性
保证本地事务和消息的消费者的一致性
提交–消费
回滚–不消费

步骤
1-4 :第一阶段
5,7 很长时间仍没结果得不到正确的执行,把半成品消息放到死信队列中,人工介入
- 生产者 send MQ Server 发送半成品消息
- ok 不会让消费者先消费这条消息
- 访问mysql执行本地事务
- 成功就commit,失败就rollback 是否允许消费者消费这条消息 第4步没有传递 Server,半成品消息一直消费不了
- 加入回查机制check 时间递增
- 服务器去check数据库
- 反馈结果给MQ
- 半成品消息转为正式消息,让消费者消费
代码需要体现1 3 6 步
异步扣减缓存的实现

步骤
- 生成流水,在发送消息之前。 流水为了更好的判断库存状态用于check
- 发送消息
- 预减库存(在缓存中),创建订单
- 更新流水
- check 检查流水
- 检查库存流水 锁的粒度比库存较小
- 最后扣减库存
9削峰限流与防刷
Java项目笔记之秒杀接口防刷限流
https://www.shangyexinzhi.com/article/2741037.html
验证码:秒杀请验证是否是人
秒杀大闸:需要拿令牌,才能进行秒杀
队列泄洪:单机限流器,线程池taskExecutor
private RateLimiter rateLimiter = RateLimiter.create(1000);
# ThreadPool
spring.task.execution.pool.core-size=5
spring.task.execution.pool.queue-capacity=10
spring.task.execution.pool.max-size=30
秒杀下单完整操作的流程
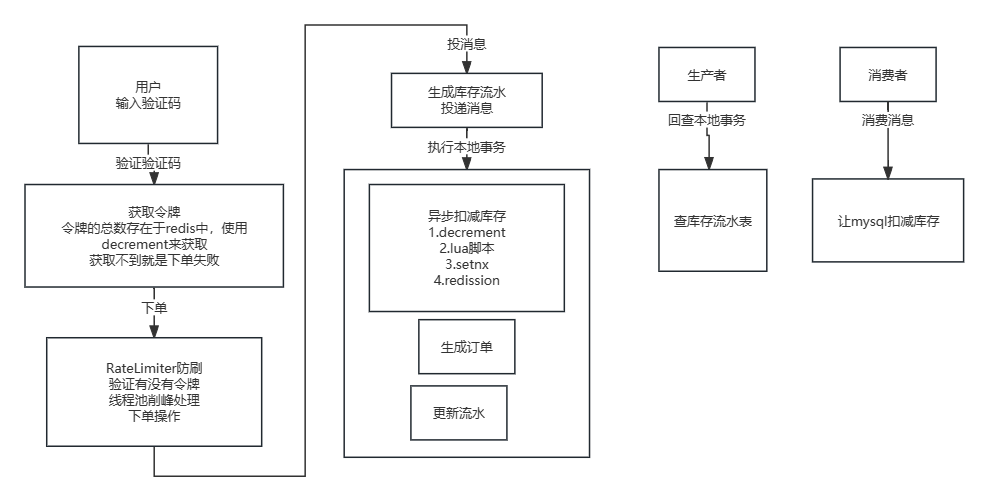
验证码
输入验证码正确之后
获取凭证
会先判断商品是不是售罄了,商品售罄是会在redis中添加标识
// 校验用户 缓存中 redis 30 mins MySQL
// 校验商品 缓存中 guava 1 min redis 3 mins mysql
cache = CacheBuilder.newBuilder()
.initialCapacity(10)
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build();
// 校验活动
秒杀大闸,decrement
redis中存入凭证
RateLimter.create(1000);//每秒最多允许请求数1000
//限制单机流量 例如限制API调用的速率,确保系统不会被过多的请求压垮。
rateLimiter.tryAcquire(1,TimeUnit.SECONDS)
尝试从速率限制器中获取一个许可,速率限制器的最大速率为每秒1个许可。
//验证活动凭证
从redis中取凭证
队列泄洪
线程池处理任务,异步下单扣减库存
检查售罄标识
生成库存流水 status:0
发送事务消息,扣减库存
生成者:
执行本地事务:
预减库存:redis中,售罄表示
创建订单:事务 @Transactional
订单号的生成:日期+流水号 序号表中(获取流水号+更新流水号)
事务 @Transactional(propagation = Propagation.REQUIRES_NEW)
外部事务回滚,本地事务不回滚
spring事务的传播机制
更新流水:status:1
回查本地事务:检查流水表
0:unknow 1:commit rollback
消费者:
扣减库存
如何解决超卖
- 使用redis的原子命令:decrement,先decrement(stock,amount),判断返回值<0,然后就回补库存increment(stock,amount)
但是是两个操作,没有原子性 - 使用lua脚本实现,先查询库存,再判断扣减库存
- 改为redis分布式锁,setnx,加锁来保证原子性,解锁时,先判断锁的归属,解锁(Lua脚本)
锁的过期时间和业务时间不好把控 - 使用redission分布式锁,锁的自动续期
使用redis的原子命令:decrement
//预扣库存
//redisTemplate.opsForValue().decrement(key, amount);
//售罄标识
//redisTemplate.opsForValue().set("item:stock:over:" + itemId, 1);
@Override
public boolean decreaseStockInCache(int itemId, int amount) {
if (itemId <= 0 || amount <= 0) {
throw new BusinessException(PARAMETER_ERROR, "参数不合法!");
}
String key = "item:stock:" + itemId;
long result = redisTemplate.opsForValue().decrement(key, amount);
if (result < 0) {
// 回补库存
this.increaseStockInCache(itemId, amount);
logger.debug("回补库存完成 [" + itemId + "]");
} else if (result == 0) {
// 售罄标识
redisTemplate.opsForValue().set("item:stock:over:" + itemId, 1);
logger.debug("售罄标识完成 [" + itemId + "]");
}
return result >= 0;
}
在上述代码中,使用Redis的decrement操作来预扣库存。如果库存数量减为负数(result < 0),则说明库存不足,需要回补库存。如果库存数量减至0(result == 0),则设置售罄标识。
这段代码可以一定程度上缓解超卖问题,但并不能完全解决。在高并发场景下,多个线程可能会同时进行decrement操作,导致库存数量减为负数。
可以通过以下方式来进一步解决超卖问题:
使用悲观锁或乐观锁来保证同一时间只有一个线程能够进行decrement操作,避免超卖问题。
在decrement操作前,通过GET命令获取当前库存数量,然后进行判断。如果库存数量小于等于请求的数量,则不进行decrement操作,避免超卖问题。
使用Lua脚本来确保decrement操作的原子性,同时进行判断和减少库存数量,避免并发问题。
综上所述,单纯使用Redis的decrement操作无法完全解决超卖问题,需要结合其他策略来确保库存的准确性和一致性。
改成一个Lua脚本
//使用Lua脚本
//得到stock
//判断stock>amount
//DECRBY stockKey, amount
//SET stockOverKey, 1
@Override
public boolean decreaseStockInCache(int itemId, int amount) {
if (itemId <= 0 || amount <= 0) {
throw new BusinessException(PARAMETER_ERROR, "参数不合法!");
}
String script = "local itemId = ARGV[1]\n" +
"local amount = tonumber(ARGV[2])\n" +
"local stockKey = \"item:stock:\" .. itemId\n" +
"local stockOverKey = \"item:stock:over:\" .. itemId\n" +
"local stock = tonumber(redis.call(\"GET\", stockKey))\n" +
"if stock == nil or stock < amount then\n" +
" return 0\n" +
"else\n" +
" local result = redis.call(\"DECRBY\", stockKey, amount)\n" +
" if result == 0 then\n" +
" redis.call(\"SET\", stockOverKey, 1)\n" +
" end\n" +
" return 1\n" +
"end";
List<String> keys = new ArrayList<>();
keys.add("item:stock:" + itemId);
keys.add("item:stock:over:" + itemId);
Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, itemId, amount);
return result != null && (Long) result == 1;
}
使用Lua脚本可以解决一些并发操作的问题,特别是在Redis中。由于Redis的单线程特性,执行Lua脚本可以保证原子性操作,并避免了多个命令的竞态条件。
在预扣库存的场景中,使用Lua脚本可以确保以下几点:
原子性操作:Lua脚本在Redis中被作为一个整体进行执行,中间不会被其他操作打断,从而保证了预扣库存操作的原子性。
避免超卖:通过在Lua脚本中检查库存数量,并在预扣成功后减少库存,可以避免超卖问题的发生。
但是需要注意的是,即使使用Lua脚本也不能完全解决所有并发问题。在高并发场景下,可能仍然存在一些问题,比如竞争条件和网络延迟等。因此,在实际应用中,还需要结合其他技术和策略来提高系统的并发性和可靠性,例如分布式锁、分布式事务等。
上述代码是一个使用Lua脚本来实现分布式锁和解决超卖问题的例子。具体步骤如下:
首先,定义了一个Lua脚本,脚本中包含了获取库存、检查库存是否足够、扣减库存和标记库存是否售罄的逻辑。
在Java代码中,通过RedisTemplate的execute方法来执行Lua脚本。在执行过程中,需要传入脚本、键列表和参数。
脚本:使用DefaultRedisScript指定脚本和返回值类型。
键列表:包含了需要操作的键,这里是"item:stock:“+itemId和"item:stock:over:”+itemId。
参数:itemId和amount,即商品ID和购买数量。
执行结果返回一个Object对象,需要根据具体业务逻辑进行判断。这里判断如果返回的结果不为空,且结果等于1,表示扣减库存成功;否则表示库存不足或者其他错误。
需要注意的是,在实际应用中,还需要考虑到异常处理、分布式锁的释放、并发情况下的处理等问题。此处的代码只是一个简化的示例,具体的实现方式需要根据具体业务需求和实际情况进行调整和完善。
redis分布式锁实现
//1.定义一个公共的方法来获取分布式锁。
private boolean acquireLock(String lockKey, String requestId, int expireTime) {
boolean lockAcquired = false;
try {
lockAcquired = redisTemplate.opsForValue().setIfAbsent(lockKey, requestId, expireTime, TimeUnit.MILLISECONDS);
logger.info("获取分布式锁成功");
} catch (Exception e) {
// 锁获取失败的处理逻辑
logger.info("获取分布式锁失败");
return false;
}
return lockAcquired;
}
//2.在方法中添加获取分布式锁的逻辑。
@Override
public boolean decreaseStockInCache(int itemId, int amount) {
if (itemId <= 0 || amount <= 0) {
throw new BusinessException(PARAMETER_ERROR, "参数不合法!");
}
String lockKey = "item:lock:" + itemId;
String requestId = UUID.randomUUID().toString();
int expireTime = 10000; // 锁的过期时间,单位为毫秒
boolean lockAcquired = acquireLock(lockKey, requestId, expireTime);
if (!lockAcquired) {
// 获取锁失败的处理逻辑
logger.info("获取分布式锁失败");
return false;
}
try {
// 执行库存扣减的逻辑
String script = "local itemId = ARGV[1]\n" +
"local amount = tonumber(ARGV[2])\n" +
"local stockKey = \"item:stock:\" .. itemId\n" +
"local stockOverKey = \"item:stock:over:\" .. itemId\n" +
"local stock = tonumber(redis.call(\"GET\", stockKey))\n" +
"if stock == nil or stock < amount then\n" +
" return 0\n" +
"else\n" +
" local result = redis.call(\"DECRBY\", stockKey, amount)\n" +
" if result == 0 then\n" +
" redis.call(\"SET\", stockOverKey, 1)\n" +
" end\n" +
" return 1\n" +
"end";
List<String> keys = new ArrayList<>();
keys.add("item:stock:" + itemId);
keys.add("item:stock:over:" + itemId);
Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, itemId, amount);
return result != null && (Long) result == 1;
} finally {
// 释放锁
boolean releaseLock = releaseLock(lockKey, requestId);
if (releaseLock){
logger.info("释放分布式锁成功");
}else {
logger.info("释放分布式锁失败");
}
}
}
//3.定义一个公共的方法来释放分布式锁。
private boolean releaseLock(String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 1 " +
"end";
List<String> keys = new ArrayList<>();
keys.add(lockKey);
Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, requestId);
return result != null && (Long) result == 1;
}
怎么合理地设置分布式锁的过期时间
上面设置了10s
需要确保RedisLock过期时间大于业务执行时间的问题
设置分布式锁的过期时间是否合理取决于你的具体需求和业务场景。一般来说,过期时间需要根据以下因素进行考虑:
业务处理时间:你需要根据业务处理的预估时间来设置过期时间。如果你的业务处理时间通常在几秒钟内完成,可以设置一个稍微长一点的过期时间,以免在处理期间锁已经过期失效。
并发访问量:如果同时对某个资源进行大量的并发操作,你可能需要更短的过期时间,以便尽快释放锁,让其他请求能够获得锁。
锁争用频率:如果对某个资源的锁争用频率很高,建议设置较短的过期时间,以便其他请求能够更快地获取到锁。
根据你的描述,如果你的业务处理时间在几秒钟内,而且对资源的锁争用频率不是特别高,10秒的过期时间可能是一个合理的选择。但请注意,在实际应用中,你可能需要根据实际情况进行调试和优化,以找到最适合你的业务场景的过期时间设置。
Redisson
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
@Configuration
@PropertySource("classpath:application.properties")
public class RedisConfiguration {
@Autowired
private Environment env;
@Bean
public Redisson redisson() {
Config config = new Config();
String redisHost = env.getProperty("spring.redis.host");
String redisPort = env.getProperty("spring.redis.port");
String redisPassword = env.getProperty("spring.redis.password");
int redisDatabaseNumber = env.getProperty("spring.redis.database", Integer.class, 0);
String redisAddress = "redis://" + redisHost + ":" + redisPort;
config.useSingleServer().setAddress(redisAddress).setPassword(redisPassword).setDatabase(redisDatabaseNumber);
return (Redisson)Redisson.create(config);
}
}
@Override
public boolean decreaseStockInCache(int itemId, int amount) {
if (itemId <= 0 || amount <= 0) {
throw new BusinessException(PARAMETER_ERROR, "参数不合法!");
}
String lockKey = "item:lock:" + itemId;
String REDIS_LOCK = lockKey+":"+UUID.randomUUID().toString();
RLock redissonLock = redisson.getLock(REDIS_LOCK);
redissonLock.lock();
logger.debug("redissonLock加锁成功");
try {
// 执行库存扣减的逻辑
String script = "local itemId = ARGV[1]\n" +
"local amount = tonumber(ARGV[2])\n" +
"local stockKey = \"item:stock:\" .. itemId\n" +
"local stockOverKey = \"item:stock:over:\" .. itemId\n" +
"local stock = tonumber(redis.call(\"GET\", stockKey))\n" +
"if stock == nil or stock < amount then\n" +
" return 0\n" +
"else\n" +
" local result = redis.call(\"DECRBY\", stockKey, amount)\n" +
" if result == 0 then\n" +
" redis.call(\"SET\", stockOverKey, 1)\n" +
" end\n" +
" return 1\n" +
"end";
List<String> keys = new ArrayList<>();
keys.add("item:stock:" + itemId);
keys.add("item:stock:over:" + itemId);
Object result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), keys, itemId, amount);
logger.debug("执行库存扣减的逻辑成功");
return result != null && (Long) result == 1;
} finally {
// 释放锁
//避免IllegalMonitorStateException: attempt to unlock lock,not locked by current thread by node id
if (redissonLock.isLocked()){
if (redissonLock.isHeldByCurrentThread()){
redissonLock.unlock();
logger.debug("redissonLock释放成功");
}
}
}
}
在上述代码中,通过使用分布式锁确保了库存扣减的原子性操作,从而避免了多线程环境下的超卖问题。当多个线程同时执行库存扣减操作时,只有一个线程能够获取到锁,其他线程会在redissonLock.lock()处阻塞等待。
在获取到锁后,通过Lua脚本执行库存扣减的逻辑,并且使用DECRBY命令原子性地减少库存数量。如果库存不足,返回0表示扣减失败,否则返回1表示扣减成功。在扣减成功后,通过SET命令将标识库存已售罄的键设置为1。
这种方式可以有效地解决超卖问题。但是需要注意的是,使用分布式锁会增加系统的复杂性和延迟,并且需要保证Redis服务器的可用性和性能。因此,在设计系统时需要权衡分布式锁的使用场景和影响,确保在高并发环境下依然能够保持系统的稳定性和性能。
另外,除了使用分布式锁来解决超卖问题,还可以考虑其他方案,如使用乐观锁或悲观锁、使用消息队列等。具体选择哪种方案取决于系统的需求和特点。
2023-8-17 17:14:14
redisson分布式锁的原理
Redisson是一个基于Redis的分布式Java对象和服务库,它提供了多种分布式功能,包括分布式锁。Redisson的分布式锁机制主要基于Redis的特性和命令实现。
Redisson分布式锁的原理如下:
客户端通过Redisson框架的API请求获取锁。
Redisson将客户端的请求转化为Lua脚本,并通过eval命令发送给Redis服务器。
Redis服务器在单线程下执行Lua脚本,保证了脚本的原子性和线程安全性。
Lua脚本在Redis服务器中执行以下操作:
- 首先,通过SET命令尝试将锁对应的键设置为指定值(通常是一个唯一标识符)。
- 如果设置成功,则表示获取锁成功,返回成功标识。
- 如果设置失败,则表示锁已被其他客户端占用,返回失败标识。
- 同时,设置锁的过期时间,防止锁无限占用。
- Redisson客户端接收到Redis服务器返回的结果,根据结果判断锁的获取是否成功,如果成功则继续执行业务逻辑,否则等待或进行其他处理。
- Redisson的分布式锁实现利用了Redis的原子操作,通过设置指定的值来实现锁的获取和释放。同时,使用Lua脚本可以保证获取锁的操作是原子的,避免了竞争条件和并发问题。
需要注意的是,Redisson的分布式锁还具备可重入性和红锁特性,使得锁的使用更加灵活和可靠。
redisson分布式锁比setnx有什么优势?
Redisson分布式锁相对于直接使用SETNX命令实现分布式锁具有以下几个优势:
可重入性:Redisson分布式锁支持可重入,也就是同一线程可以多次获取同一个锁而不会被阻塞。这种可重入性能够解决一些特定场景下的并发问题。
锁的自动续期:Redisson分布式锁支持锁的自动续期,即在获取锁后,锁的过期时间会不断更新,防止持有锁的客户端在执行业务逻辑时由于各种原因导致锁过期而被其他客户端抢占。
防止死锁的解锁机制:Redisson分布式锁通过监听锁的失效事件来实现解锁操作,避免了因为客户端崩溃或其他原因导致的锁无法释放的情况。
红锁特性:Redisson分布式锁支持红锁特性,即在多个Redis节点之间实现锁的互斥。当多个Redis节点之间进行通信时,可以使用分布式锁的红锁特性保证在大多数节点上加锁成功才算真正获取到锁,避免了分布式环境下的数据不一致问题。
强大的扩展性:Redisson分布式锁是基于Redisson框架的分布式Java对象和服务库实现的,提供了很多其他功能和特性,如分布式服务、分布式集合等。使用Redisson分布式锁可以很方便地与其他分布式功能进行集成和扩展。
综上所述,Redisson分布式锁相比于直接使用SETNX命令实现分布式锁,具有更多的功能和特性,可以更方便地应对分布式环境中的并发和竞争问题。
其他问题
分布式ID
我的订单ID 的设计
数据库生成的,
8位的日期+12位的序号
序号的获取是有一个序号表
记录它的业务名,值,以及步长
另外可以多加几列字段,(服务器流水号、用户尾号)
事务:@Transactional(propagation = Propagation.REQUIRES_NEW)
先获取流水号
再更新流水号
select for update保证ID
事务:@Transactional
生成订单的时候
如果回滚了,就会浪费一个订单号
UUID
类snowflake方案
数据库生成
自增主键
Leaf方案实现
Leaf-segment数据库方案
第一种Leaf-segment方案,在使用数据库的方案上,做了如下改变: - 原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。 - 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
缓存相关的问题
缓存和数据库的一致性
先更新数据库再删除缓存
库存的一致性是mq实现事务消息
缓存穿透
场景:
场景查询根本不存在的数据,使得请求直达存储层
导致其负载过大,甚至宕机。
解决方案:
1.缓存空对象存储层未命中后,仍然将空值存入缓存层。再次访问该数据时,缓存层会直接返回空值。
2.布隆过滤器将所有存在的key提前存入布隆过滤器,在访问缓存层之前,先通过过滤器拦截,若请求的是不存在的key,则直接返回空值。
缓存击穿
场景:
一份热点数据,它的访问量非常大。在其缓存失效瞬间,大量请求直达存储层,导致服务崩溃。
解决方案:
1.加互斥锁对数据的访问加互斥锁,当一个线程访问该数据时,其他线程只能等待。这个线程访问过后,缓存中的数据将被重建,届时其他线程就可以直接从缓存取值。
2.永不过期不设置过期时间,所以不会出现上述问题,这是“物理”上的不过期。为每个value设置逻辑过期时间,当发现该值逻辑过期时,使用单独的线程重建缓存。
缓存雪崩
场景:
由于某些原因,缓存层不能提供服务,导致所有的请求直达存储层,造成存储层宕机。
解决方案:
1.避免同时过期设置过期时间时,附加一个随机数,避免大量的key同时过期。
2.构建高可用的Redis缓存部署多个Redis实例,个别节点宕机,依然可以保持服务的整体可用。
3.构建多级缓存增加本地缓存,在存储层前面多加一级屏障,降低请求直达存储层的几率。
4.启用限流和降级措施对存储层增加限流措施,当请求超出限制时,对其提供降级服务。
3种缓存更新策略是怎样的?
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。

Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
下面是 Read Through/Write Through 策略的示意图:

Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
实际上,Write Back(写回)策略也不能应用到我们常用的数据库和缓存的场景中,因为 Redis 并没有异步更新数据库的功能。

redis的高级数据结构
拦截器:记录uv,dau访问过一次判断其为活跃
hyperLogLog
统计uv
key:uv_日期
value:ip
add()
指定日期范围统计union()之后再size返回
bitmap
统计dau
key:dau_日期
value:userId
setBit()
统计指定日期范围内的DAU OR运算 bitCount()
hyperloglog
HyperLogLog是一种基数估计算法,它可以在只使用很少的内存空间的情况下,近似地估计一个集合中不重复元素的数量。
在Redis中,HyperLogLog是通过一个专门的命令来实现的,这个命令的名称是PFADD,它可以用来添加元素到HyperLogLog中,还有一个命令PFCOUNT,可以用来获取HyperLogLog中不重复元素的数量。
为什么使用mq
解耦 异步 削峰
比如:论坛项目中的,关注,点赞或评论帖子,做系统通知
如果写出一个方法的话,还需要保证事务,设置事务的传播行为
但是别人点赞了,和你收到系统通知,其实是两个业务
别人点赞了,系统通知的业务执行失败,你也不能回滚
这两个操作也是异步的
削峰,秒杀项目的扣减库存
倒排索引的理解:
倒排索引(Inverted Index)是一种用于快速定位文档的索引结构。在倒排索引中,每个关键词都维护了一个包含包含该关键词的文档列表。通过倒排索引,可以快速地找到包含特定关键词的文档,而无需遍历所有文档。
倒排索引的构建过程包括以下几个步骤:
文档分词:将每个文档拆分为一个个的词语(或称为术语,terms),这通常是通过分词器(tokenizer)来实现的。分词器可以根据各种规则和算法将文本切分为合适的词语。
构建倒排索引:对于每个词语,将它出现的文档ID记录到倒排索引中。倒排索引的数据结构通常是一个关联数组(Associative Array),其中词语作为键,文档ID的列表作为值。
优化倒排索引:为了提高查询性能和减少索引的大小,通常还会对倒排索引进行优化。例如,可以使用压缩算法对文档ID列表进行压缩,或者使用数据结构如跳表(Skip List)来加速查找过程。
通过倒排索引,可以在搜索时快速定位包含特定关键词的文档。比如,当用户在搜索引擎中输入一个关键词时,搜索引擎可以通过倒排索引找到包含该关键词的文档,并返回给用户相关的搜索结果。倒排索引是大部分搜索引擎(包括Elasticsearch)的核心组成部分,它能够提供快速、灵活和准确的搜索功能。
数据结构
二叉树
树的表示方法:
双亲表示法
孩子表示法
孩子兄弟表示法
完全二叉树
编号1~n
满二叉树
最后一层都满了
层数:1…k
结点数量和为2^k-1
BST 二叉排序树|二叉搜索树
中序遍历是有序的
4
2 6
1 3 5 7
AVL 平衡二叉树
平衡因子的绝对值不超过1
左右子树深度差
B树 多路平衡查找树
多路:不只二叉
平衡:平衡
查找:查找
B+树
信息只存储在叶子节点上
红黑树
特殊的二叉树
- 每个结点不是红色就是黑色
- 根节点是黑色的
- 每个叶子结点都是黑色的 ( 此处的叶子结点指的是空结点 )
- 如果一个节点是红色的,则它的两个孩子结点是黑色的
- 对于每个结点,从该结点到其所有后代叶结点的简单路径上,均包含相同数目的黑色结点
哈夫曼树
变长编码
前缀编码:任何符号的编码不能是其他编码的前缀
构造过程:
计算频度
找出最小的两项结点,合并为新结点
继续找
散列
开放定址法
线性探测再散列:F=i+k
二次探测再散列:F=-12 12 -22 22,…
链地址法
HashMap
再散列
布隆过滤器
计算平均查找长度
操作系统面试题
并行和并发
并发:单核CPU宏观上同时执行多个任务,微观上是分时交替执行多个任务;类似于时间片轮转算法
并行:多核CPU同时执行多个任务
什么是进程?进程和程序的区别?
进程是程序的一次执行
进程是动态的,程序是静态的
进程创建需要CPU的资源,分配内存,进程控制块
进程的基本状态
就绪,执行,阻塞
创建,终止
什么是线程?线程和进程的区别?
进程是操场系统资源拥有的最小单位
线程是操作系统调度的最小单位
进程控制块:PCB
线程控制块:TCB
TCB比PCB小
有程序计数器…等等线程私有的东西
哪些是线程的私有资源
在一个进程中,线程之间可以共享以下资源:
内存空间:线程共享相同的地址空间,也就是说它们可以访问相同的全局变量和静态变量。
文件描述符:每个线程都可以访问进程打开的文件。
代码段:所有线程都可以访问进程的代码段,也就是说它们执行相同的指令。
而线程有一些私有的资源,包括:
栈空间:每个线程都有自己的栈空间,用于存储局部变量、函数调用信息和返回地址等。
寄存器:每个线程有自己的寄存器集,用于存储正在执行的指令和相关的数据。
线程上下文:线程上下文包括线程的状态信息,例如程序计数器、寄存器值和栈指针等。
栈指针:每个线程都有自己的栈指针,指向线程的栈顶。
需要注意的是,线程共享的资源需要进行同步和互斥操作,以避免数据竞争和并发访问的问题。常用的同步机制包括互斥锁、条件变量和信号量等。
操作系统中线程的状态
三个基本状态:执行、就绪、阻塞
创建,终止
Java中线程的状态
新建状态(New): 线程对象被创建后,就进入了新建状态。例如,Thread thread = new Thread()。
就绪状态(Runnable): 也被称为“可执行状态”。线程对象被创建后,其它线程调用了该对象的start()方法,从而来启动该线程。例如,thread.start()。处于就绪状态的线程,随时可能被CPU调度执行。
运行状态(Running): 线程获取CPU权限进行执行。需要注意的是,线程只能从就绪状态进入到运行状态。
阻塞状态(Blocked): 阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
- (01) 等待阻塞 – 通过调用线程的wait()方法,让线程等待某工作的完成。
- (02) 同步阻塞 – 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态。
- (03) 其他阻塞 – 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead): 线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
进程的同步
信号量进制
整型信号量
记录型信号量
AND型信号量
信号量集
管程机制
线程通信
共享内存机制和消息传递机制两种
- 共享存储器系统
基于共享数据结构的通信方式 基于共享存储区的通信方式 - 消息传递系统
直接通信方式 间接通信方式
消息 邮箱 - 管道通信系统
连接一个读进程和一个写进程以实现它们之间通信的一个共享文件,又名pipe文件。 - 客户机—服务器系统
套接字、远程过程调用和远程方法调用
三种调度
低级调度:进程调度
中级调度:页面置换
高级调度:作业调度
进程调度算法
- 先来先服务调度算法
- 最短作业优先调度算法
- 高响应比优先调度算法
- 时间片轮转调度算法
- 最高优先级调度算法
- 多级反馈队列调度算法
什么是死锁
如果一组进程中的每一个进程都在等待仅由该组进程中的其它进程才能引发的事件,那么该组进程就是死锁的(Deadlock)。
产生死锁的原因
竞争资源
进程间推进顺序非法
死锁的必要条件
(1) 互斥条件
(2) 请求和保持条件
(3) 不可抢占条件
(4) 循环等待条件
怎么处理死锁
3理死锁的方法
(1) 预防死锁
破坏死锁的必要条件:
1.摒弃“请求和保持条件”:进程在开始运行之前,都必须一次性的申请其在整个过程中所需的全部资源
2.摒弃“不可剥夺”条件:当一个已经保持资源的进程,提出新的资源申请而没有得到满足时,必须释放它已经保持了的所有资源,待以后再重新申请
3.摒弃“环路等待”条件:为所有资源按类型进行线性排队,并赋予不同序号,所有进程对资源的请求必须严格按照资源序号递增的次序提出。
(2) 避免死锁
1银行家算法
2安全性算法
(3) 检测死锁
1资源分配图
2死锁定理
资源分配图是不可完全简化的
(4) 解除死锁
1剥夺资源
2撤销进程
Mysql的死锁检测:超时 检测
解除:回滚执行花费少的事务
动态分区分配算法
基于顺序搜索的动态分区分配算法
顺序搜索,是指依次搜索空闲分区链上的空闲分区,去寻找一个其大小能满足要求的分区。
碎片:内存空间不断被划分,会留下许多难以利用的、很小的空闲分区。
1.首次适应(first fit,FF)算法
2.循环首次适应(next fit,NF)算法
3.最佳适应(best fit,BF)算法
4.最坏适应(worst fit,WF)算法
基于索引搜索的动态分区分配算法
1.快速适应算法
2.伙伴系统
3.哈希算法
虚拟存储
物理上扩容很简单,加内存条
逻辑上扩容,采用虚拟存储
实现方式:页面的调入调出
目的是:用磁盘来代替内存,降低成本
页面置换算法
- 最佳页面置换算法(OPT)
- 先进先出置换算法(FIFO)
- 最近最久未使用的置换算法(LRU)
- 时钟页面置换算法(Lock)
简单Clock置换算法,为每一页设置一位访问位A,内存中所有页面构成循环队列,
被访问时访问为置为1。淘汰时,检查访问位,为0直接换出,
为1,重新将它置0,暂不换出,而给该页第二次驻留内存的机会。
检查到最后时仍为1,再返回队首重新检查
也称为最近未用NRU算法
改进型Clock置换算法:还有考虑M置换代价
A=0,M=0 最佳淘汰页
1)从指针所指示的当前位置开始,扫描循环队列,寻找 A=0 且 M=0 的第一类页面,
将所遇到的第一个页面作为所选中的淘汰页。在第一次扫描期间不改变访问位 A。
2)如果第一步失败,即查找一周后未遇到第一类页面,则开始第二轮扫描,
寻找 A=0 且 M=1 的第二类页面,将所遇到的第一个这类页面作为淘汰页。
在第二轮扫描期间,将所有扫描过的页面的访问位都置 0。
3)如果第二步也失败,亦即未找到第二类页面,则将指针返回到开始的位置,
并已将所有的访问位复 0。然后重复第一步,如果仍失败,必要时再重复第二步,
此时就一定能找到被淘汰的页。
该算法与简单 Clock 算法比较,
可减少磁盘的 I/O 操作次数。但为了找到一个可置换的页,
可能须经过几轮扫描。换言之,实现该算法本身的开销将有所增加。
- 最少使用置换算法(LFU)
对I/O设备的控制方式
使用轮询的可编程I/O方式
使用中断的可编程I/O方式
直接存储器(DMA)访问方式
I/O通道控制方式
磁盘调度算法
第六章 输入输出系统【操作系统】:6.8 磁盘存储器的性能和调度
- 先来先服务算法
- 最短寻道时间优先算法
- 扫描算法
- 循环扫描算法
- LOOK 与 C-LOOK 算法
计算机组成原理
CPU缓存:L1 L2 L3
主从与cache的地址映射
1.全相连映射方式
这种方法可使主存的一个块直接拷贝到cache中的任意一行上,非常灵活。
它的主要缺点是比较器电路难于设计和实现,因此只适合于小容量cache采用。
2.直接映射方式
直接相连映射方式的优点是硬件简单,成本低。缺点是每个主存块只有一个固定的行位置可存放,容易产生冲突。因此适合大容量cache采用。
3.组相连映射方式
组相联映射方式中的每组行数v一般取值较小,这种规模的v路比较器容易设计和实现。而块在组中的排放又有一定的灵活性,冲突减少。
I型 R型 J型指令设计
计算机系统结构
系统加速比
Amdahl定律
加速比=1/[(1-可改进比例)+可改进比例/部件加速比]
Cache
映像规则
全相联映像
主存中的任一块可以被放置到Cache中的任意一个位置。
特点:空间利用率最高,冲突概率最低,实现最复杂直接映像
主存中的每一个块只能被放到Cache中唯一一个位置。
特点:空间利用率最低,冲突概率最高,实现最简单组相联映像
Cache被等分成若干组,每组由若干个块构成。主存中的每一块可被放到Cache中唯一一个组的任何一个位置。组的选择常采用位选择算法:
Cache性能分析
平均访存时间=命中时间+不命中率×不命中开销
所以可以从三个方面来改进Cache的性能:降低不命中率、减少不命中开销、减少命中时间
降低Cache不命中率
三种不命中:强制性不命中 容量不命中 冲突不命中
增加Cache块的大小
增加Cache块的容量
提高相联度
伪相联Cache
硬件预取
编译器控制的预取
编译优化
牺牲Cache
减少Cache不命中开销
采用两级Cache
让读不命中优先于写
写缓冲合并
请求字处理技术
非阻塞Cache技术
减少命中时间
容量小、结构简单的Cache
虚拟Cache
Cache访问流水化
踪迹Cache
Cache优化技术总结
计算机网络
计算机网络的层次划分
OSI七层网络:物理层、数据链路层、网络层、运输层、会话层、表示层、应用层
TCP\IP四层网络:网络接口层、网际层IP、运输层、应用层
教学原理五层网络:物理层、数据链路层、网络层、运输层、应用层
输入URI的一个过程
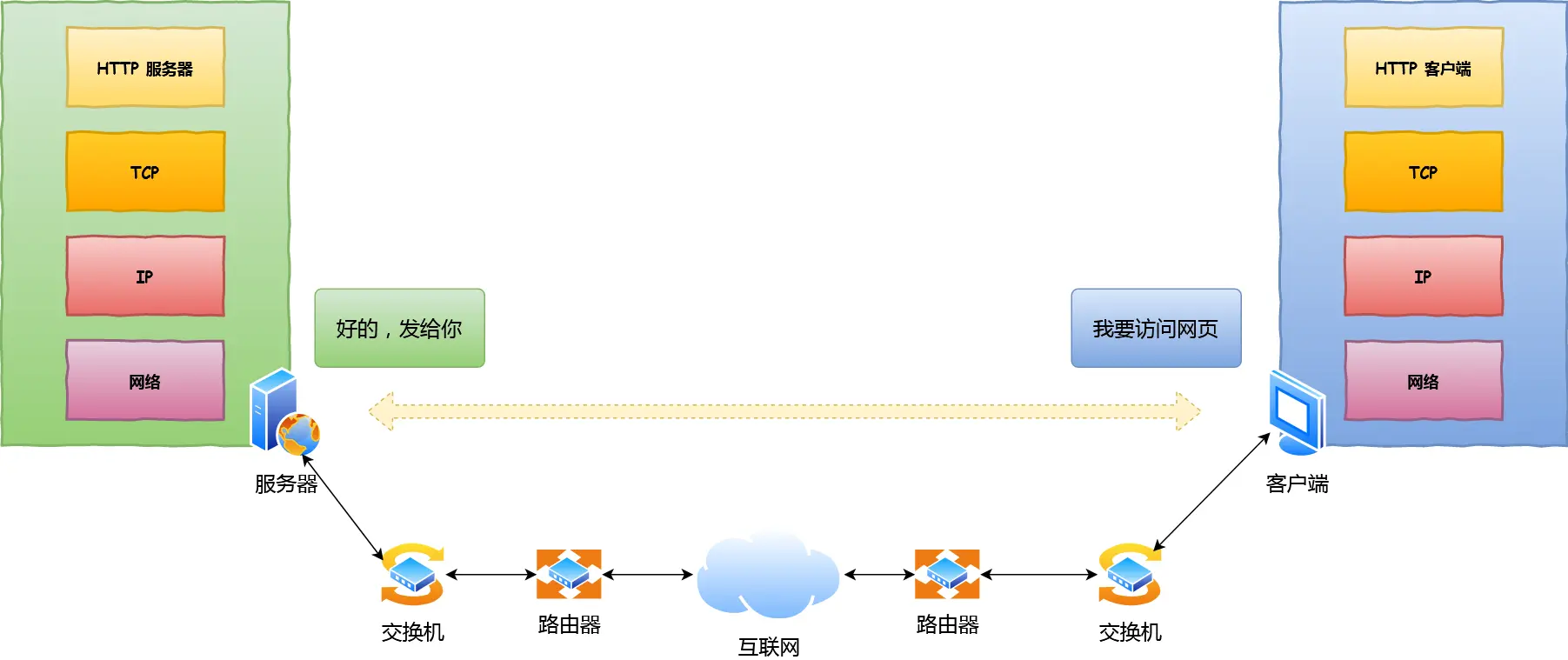
应用层 从应用到应用
没有连接到网络:ERR_INTERNET_DISCONNECTED
连接到:DHCP 分配IP地址
HTTP(TCP)
DNS(UDP)
访问默认的DNS服务器:8.8.8.8|114.114.114.114
域名->IP
运输层 从端到端
TCP
连接管理 流量控制 拥塞控制
网络层 从路由器到路由器
IP
ICMP:ping traceroute
ARP:IP转为MAC地址
目的IP和本机IP是否在同一网络:目的IP&掩码==网络前缀
不在就是间接交付,访问默认网关
路由器的配置:RIP BGP
数据链路层 从交换机到交换机
封装成帧 透明传输 差错检测
MAC地址 交换机逆向学习源地址
转发异网帧 过滤本网帧 广播未知帧
物理层 从线路到线路
传输bit流
UDP
UPD是用户数据报协议
报文格式:UDP首部+数据
UDP首部(8):目的端口(2)、源端口(2)、长度(2)、校验和(2),单位是字节
特点:
无连接 尽最大努力交付 面向报文 没有拥塞控制 支持一对多,多对一,多对多 首部开销小
应用场景:
对实时要求高的,不允许丢失要求不高的
语音、视频通话 游戏
DHCP DNS都是基于UDP的
TCP
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。
报文格式:TCP首部+数据
TCP首部格式目的端口、源端口、序号、确认号、标志位(SYN ACK FIN)、选项(窗口扩大 时间戳 选择确认)、填充、等等
固定20字节,最大60字节
特点:
面向连接的运输层协议 一对一(端到端) 可靠交付 全双工 面向字节流
应用场景:
对实时要求不高的,不允许丢失要求高的
文件传输
HTTP FTP就是基于TCP的
TCP的流量控制
用滑动窗口来实现流量控制的
发送窗口,不能大于接受方的接受窗口
防止上一次发送方接受到0窗口通知,但是后续的窗口扩大了,因为网络问题,接收不到
造成死锁,发送方发送不了数据,接收方有在等待发送数据
设置持续计时器,当收到零窗口通知时,启动计时
发送零窗口探测报文(仅携带1字节数据),如果后续还接收到0窗口通知就不发送,否则就开始发送,不超过其接受窗口
问题:如何控制发送报文段的时机:
不是收到一个确认,就发送下一个报文段
Nagle(纳格尔)算法:
先发送一个数据字节,然后把后续到来的数据字节缓存起来,收到确认,就把缓存中的全部发送出去,继续缓存后续字节
问题:糊涂窗口综合征
应用进程每次在接受缓存中处理一个字节,导致每一次发送的接受窗口大小都是1字节
解决:可以让接收方等待一段时间,使得或者接收缓存已有足够空间容纳一个最长的报文段,或者等到接收缓存已有一半空闲的空间。只要出现这两种情况之一,接收方就发送确认报文,和通知接受窗口的大小
上述两种方法可配合使用。使得在发送方不发送很小的报文段的同时,接收方也不要在缓存刚刚有了一点小的空间扰急忙把这个很小的窗口大小信息通知给发送方。
TCP的拥塞控制
慢开始:从1开始,每收到一个确认,拥塞窗口(cwnd)就加一(每一个RTT就加倍),直到门限值
拥塞避免:门限值之后,每一个传输轮次(RTT)加一,到超时0,就把新门限值设置为当前的拥塞窗口的一办,重新慢开始
快重传:当收到三个ack相同的报文,发送方就会快速发送这个序号的数据包
快回复:当收到三个ack相同的报文,引起的网络阻塞,不是进行慢开始,而是直接开始拥塞避免,从新门限开始
加法增大、乘法减小(AIMD)
TCP的连接管理
三次握手
客户端A主动打开连接,服务端B被动打开连接
开始时,服务端开启端口,接受请求,进入接听(Listen)状态
A:发送[SYN]包,SYN=1,seq=x,进入 SYN-SEND(同步已发送)状态
B:发送[SYN,ACK]包,SYN=1,ACK=1,seq=y,ack=x+1,进入SYN-RCVD(同步收到)状态
A:发送[ACK]包,ACK=1,sqq=x+1,ack=y+1,进入已建立连接(ESTABLISHED)状态;B收到后也进入已建立连接(ESTABLISHED)状态
为什么是三次握手,而不是两次或四次
四次的话,就是原先第二次握手,SYN ACK分开发送,但是有点浪费资源,能一次发送的
两次的话,就是删掉第三次握手。可能会已失效的连接请求报文段,重新建立连接
比如:A第一次发送SYN包,但是被网络拥塞了;之后又发送了SYN包,建立了链接,然后又释放了。
但是这是A第一次发送SYN包,又到了B,B接受了,处于连接状态了,但是A是不会给其发送数据的,使得B在苦等
四次挥手
客户端,服务器都可以先发送
A:发送[FIN]包,FIN=1,seq=u,主动关闭,进入FIN-WAIT-1(终止等待1)状态
B:发送[ACK]包,ACK=1,ack=u+1,被动关闭,进入CLOSE-WAIT(关闭等待)状态;A收到了进入FIN-WAIT-2(终止等待2)状态
此时,已关闭A->B的数据连接,TCP连接处于半关闭状态。
B->A,B仍可以发送数据,A依然接受
TCP是全双工的
B:发送[FIN]包,FIN=1,seq=v,进入LAST-ACK(最后确认)状态
A:发送[ACK]包,ACK=1,seq=v+1,进入TIME-WAIT(时间等待)状态,等待2MSL之后,如果没有再次接受,就CLOSE状态;B收到就进入CLOSE状态
MSL:最长报文寿命,2分种
问题:为什么,要等待2MSL?
为了保证A最后一次ACK达到B,使得B正确关闭;如果B没有收到此报文,将快速重传,让A发送。
问题:为什么是四次挥手,而不是三次
三次挥手,就是把第四次挥手删掉;
放在已失效的连接再次建立
保活计时器:没收到一个数据,就重新计时;当客户端意外故障关闭了,在2小时之后发送10个探测报文,没有响应就关闭连接
协议
ARP协议:
根据IP地址出MAC地址
ARP请求,广播发送
ARP响应,单播发送
ICMP协议
ping:ICMP询问报文
tracerouter:ICMP差错报告报文
DNS
域名解析协议
域名换成IP地址
递归查询:
主机->本地域名服务器->根域名服务器->顶级域名服务器->权限域名服务器;
权限域名服务器->顶级域名服务器->根域名服务器->本地域名服务器;
本地域名服务器->主机
迭代查询:(指路不带路)
主机->本地域名服务器;
本地域名服务器->根域名服务器;
本地域名服务器->顶级域名服务器;
本地域名服务器->权限域名服务器
本地域名服务器->主机;
DHCP(客户端68 服务器67)
动态获取IP地址,有租期的
dhcp release,主动解约
dhcp renew,主动解约
补充
tcp三次握手为什么不是两次
TCP三次握手是为了建立可靠的通信连接,确保双方都能够正常收发数据。三次握手的过程如下:
- 客户端向服务器发送一个连接请求报文段(SYN)。
- 服务器收到请求后,如果同意连接,则会发送一个确认报文段(SYN+ACK)作为回应。
- 客户端收到服务器的确认后,再次向服务器发送一个确认报文段(ACK)。
为什么不是两次握手呢?主要有以下两个原因:
可靠性:通过三次握手,可以确保客户端和服务器都确认了对方的存在和能力,避免了因为网络延迟或其他原因引起的错误连接。
- 在两次握手的情况下,如果客户端的连接请求报文段丢失,服务器将无法确认客户端的请求,从而无法建立连接。
- 在三次握手的情况下,即使客户端的连接请求报文段丢失,服务器能够发送自己的确认报文段,客户端收到后也能够确认服务器的存在。
防止已失效的连接请求报文段重复发送导致的问题:考虑这样一种情况,客户端发送了一个连接请求报文段,但是由于网络问题或其他原因导致客户端没有收到服务器的回应。如果客户端再次发送一个连接请求报文段,但是第一个连接请求报文段在网络中延迟到达,这时服务器就会误认为客户端新发送的连接请求,从而建立了两个连接。为了避免这种情况,引入了第三次握手,确保服务器收到客户端的确认报文段后,才正式建立连接。
综上所述,通过三次握手可以更好地保证通信连接的可靠性和防止错误连接的发生。
如果TCP是两次握手应该怎么发送两次握手包
如果TCP只进行两次握手,发送两次握手包的过程可以这样描述:
- 客户端发送一个连接请求报文段(SYN)给服务器。
- 服务器收到请求后,如果同意连接,则立即发送一个确认报文段(SYN+ACK)给客户端。
- 客户端收到服务器的确认后,建立连接,此时连接已建立。
在这种情况下,没有第三次握手,建立连接的过程相对简单。然而,这样的连接建立方式存在一些问题:
- 不可靠性:在两次握手的情况下,如果客户端的连接请求报文段丢失,服务器将无法确认客户端的请求,从而无法建立连接。
- 安全性问题:由于没有第三次握手,可能会有恶意主机发送大量的伪造连接请求,导致服务器资源被耗尽,也称为SYN洪泛攻击。
因此,为了确保连接的可靠性和安全性,TCP采用三次握手来建立连接。第三次握手是为了确保服务器收到客户端的确认报文段,从而避免了错误连接和资源浪费的问题。
TCP三次握手,怎么解决历史重复连接的
TCP三次握手可以解决历史重复连接的问题。具体过程如下:
- 客户端发送连接请求报文段(SYN)给服务器。
- 服务器收到请求后,如果同意连接,则发送确认报文段(SYN+ACK)给客户端,并为该连接分配资源。
- 客户端收到服务器的确认后,发送确认报文段(ACK)给服务器,建立连接。
- 连接建立后,双方可以开始进行数据传输。
在三次握手的过程中,服务器会为每个连接分配一个唯一的标识符,称为序列号(Sequence Number)。客户端发送的连接请求报文段中会包含一个初始的序列号,服务器在确认报文段中会回复一个确认序列号。
历史重复连接指的是客户端发送的连接请求报文段在网络中滞留,导致服务器延迟收到该请求,而客户端认为连接已建立,重新发送了连接请求。这样就会出现服务器收到重复的连接请求。
TCP通过使用序列号来解决历史重复连接的问题。服务器在收到重复的连接请求后,会检查该连接请求的序列号和已分配的序列号进行比较。如果两者一致,则说明该连接请求是历史重复连接,服务器会忽略该请求。如果不一致,则说明该连接请求是新的请求,服务器会重新处理并建立连接。
通过使用序列号来识别和处理历史重复连接,TCP确保了连接的可靠性和可用性。
Http
HTTP2.0的优化,HTTP3.0的优化 ,HTTP3.0前向纠错,HTTP3.0如何保证可靠性
https://juejin.cn/post/6995109407545622542
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
HTTP/1.1 相比 HTTP/1.0 性能上的改进:
使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出
去,可以减少整体的响应时间。
但 HTTP/1.1 还是有性能瓶颈:
请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分;
发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻
塞;
没有请求优先级控制;
请求只能从客户端开始,服务器只能被动响应。
HTTP/2 做了什么优化?
TTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。
那 HTTP/2 相比 HTTP/1.1 性能上的改进:
头部压缩
二进制格式
并发传输
服务器主动推送资源
HTTP/2 有什么缺陷?
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2
还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/3 做了哪些优化?
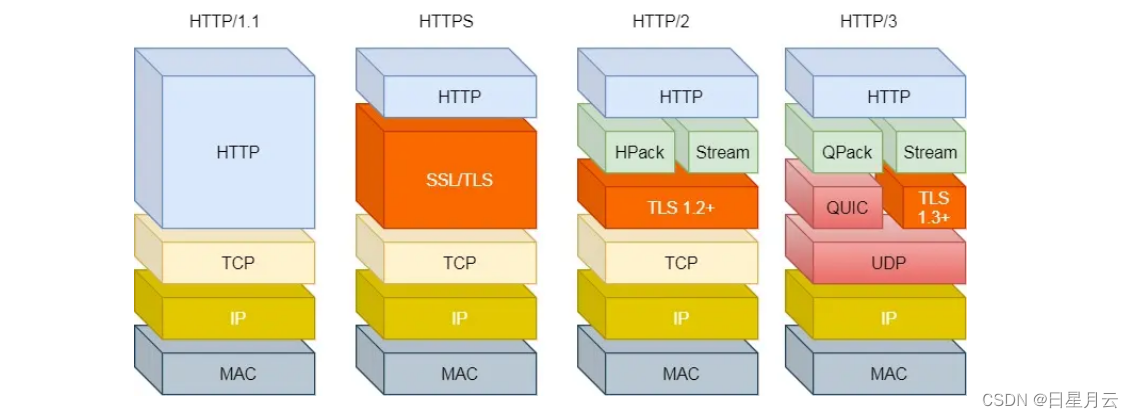
QUIC 有以下 3 个特点。
无队头阻塞
更快的连接建立
连接迁移
计算机网络安全
安全攻击
被动攻击:
消息内容泄露攻击和流量分析攻击
主动攻击:
假冒、重放、改写消息和拒绝服务。
被动攻击:窃听
主动攻击:篡改、恶意程序、拒绝服务
对称加密
明文:这是原始消息或数据,作为算法的输入。
加密算法:加密算法对明文进行各种替换和转换。
秘密密钥:秘密密钥也是算法的输入。算法进行的具体替换和转换取决于这个密钥。
密文:这是产生的已被打乱的消息输出。它取决于明文和秘密密钥。对于一个给定的消息,两个不同的密钥会产生两个不同的密文。
解密算法:本质上是加密算法的反向执行。它使用密文和同一密钥产生原始明文。
DES、3DES、AES
安全散列函数
散列函数的目的是为文件、消息或其他数据块产生“指纹”。为满足在消息认证中的应用,散列函数H必须具有下列性质:
(1)H可适用于任意长度的数据块。
(2)H能生成固定长度的输出。
(3)对于任意给定的x,计算H(x)相对容易,并且可以用软/硬件方式实现。
(4)对于任意给定值h,找到满足H(x)=h的x在计算上不可行。满足这一特性的散列函数称为具有单向性,或具有抗原像攻击性。
(5)对于任意给定的数据块x,找到满足H(y)=H(x)的y≠x在计算上是不可行的。满足这一特性的散列函数被称为具有抗第二原像攻击性,有时也称为具有抗弱碰撞攻击性。
(6)找到满足Hx)= H(y)的任意一对(x,y)在计算上是不可行的。满足这一特性的散列函数被称为抗碰撞性,有时也被称为抗强碰撞性。
前三个性质是使用散列函数进行消息认证的实际可行要求。第四个属性,抗原像攻击性,是单向性:给定消息容易产生它的散列码,但是给定散列码几乎不可能恢复出消息。如果认证技术中使用了秘密值(见图3.2(c)),则单向性很重要。秘密值本身并不会传输;然而,假如散列函数不是单向的,而攻击者能够分析或截获消息M和散列码C=H(SABlIM),则攻击者很容易发现秘密值。攻击者对散列函数取逆得到SAB||M=H1( C)。因为这时攻击者拥有M和SABllM,所以他们可以轻而易举地恢复SAB。
抗第二原像攻击性质保证了对于给定的消息,不可能找到具有相同散列值的可替换消息。利用加密的散列码可防止消息被伪造(见图3.2(a)和图3.2(b))。如果该性质非真,则攻击者可以进行如下操作:第一,分析或截获消息及其加密的散列码;第二,根据消息产生没有加密的散列码;第三,生成具有相同散列码的可替换消息。
满足上面前5个性质的散列函数称为弱散列函数。如果还能满足第6个性质则称其为强散列函数。第6个性质可以防止像生日攻击这种类型的复杂攻击。生日攻击的细节超出了本书的范围。这种攻击把m比特的散列函数的强度从2m简化到2m/2。详细内容可参考[STAL11]。
除提供认证之外,消息摘要还能验证数据的完整性。它与帧检测序列具有相同的功能:如果在传输过程中,意外地篡改任意比特,消息摘要则会出错。
SHA
非对称加密
公钥密码方案由6个部分组成(见图3.9(a)):
- 明文:算法的输入,它是可读的消息或数据。
- 加密算法:加密算法对明文进行各种形式的变换。
- 公钥和私钥:算法的输入,这对密钥如果一个密钥用于加密,则另一个密钥就用于解密。加密算法所执行的具体变换取决于输入端提供的公钥或私钥。
- 密文:算法的输出,取决于明文和密钥。对于给定的消息,两个不同的密钥将产生两个不同的密文。
- 解密算法:该算法接收密文和匹配的密钥,生成原始的明文。
公钥密码系统的应用
在广义上可以把公钥密码系统分为如下三类。
- 加密/解密:发送方用接收方的公钥加密消息。
- 数字签名:发送方用自己的私钥“签名”消息。签名可以通过对整条消息加密或者对消息的一个小的数据块加密来产生,其中该小数据块是整条消息的函数。
- 密钥交换:通信双方交换会话密钥。这可以使用几种不同的方法,且需要用到通信一方或双方的私钥。
RSA算法
基本的RSA加解密 对于某明文块M和密文块C加密和解密有如下的形式:
C=Memod n
M=Cd mod n=(Me)d mod n = Med mod n
发送方和按牧方那必须知道和e的值,并且只有接收方知道d的值。RSA公钥密码算法的公钥KU={e,u}私钥KR={d,n}。为使该算法能够用于公钥加密,它必须满足下列要求:
(1)可以找到e、d、n的值, 使得对所有的M<n,Medmod n=M成立。
(2)对所有满足M<n的值, 计算Me和Cd相对容易。
(3)给定e和n,不可能推出d。
前两个要求很容易得到满足。当e和n取很大的值时,第三个要求也能够得到满足。
要计算n的欧拉函数值Φ(n)。Φ(n)表示小于n且与n互素的正整数的个数。然后选择与Φ(n)互素的整数e(即e和Φ(n)的最大公约数为1)。最后,计算e关于模d(n)的乘法逆元d,d和e具有所期望的属性。

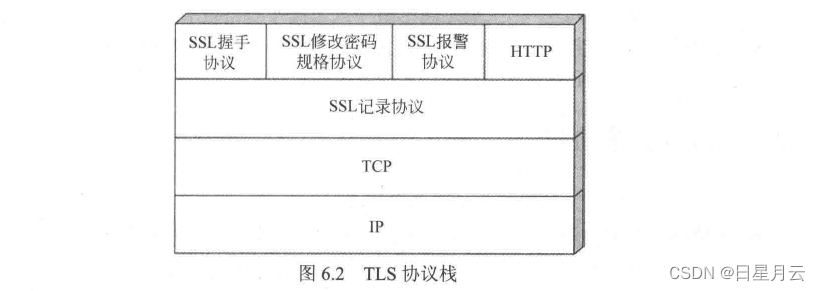
TLS 传输层安全
TLS体系结构



TLS记录协议
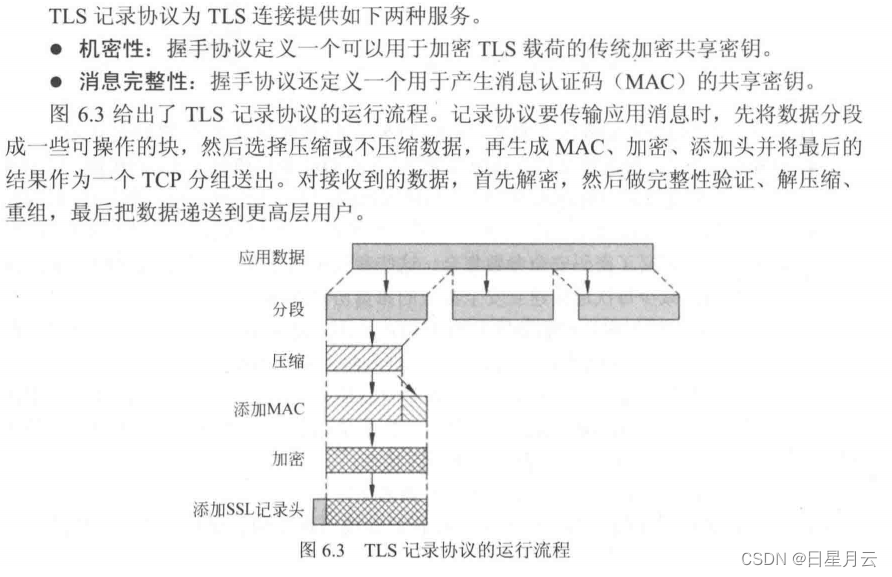
TLS握手协议
- 第一阶段:客户端发起建立连接请求.建立安全连接请求.包括协议版本、会话ID、密码套件、压缩方法和初始随机数
- 第二阶段:服务器认证和密钥交换。服务器发送证书、密钥交换数据和证书请求.最后发送hello消息阶段的结束信号
- 第三阶段:客户端认证和密钥交换。如果有证书请求,客户端发送证书。之后客户端发送密钥交换数据,也可以发送证书验证消息
- 第四阶段:完成。变更密码套件和结束握手协议
HTTPS RSA 握手解析
TLS 握手过程
HTTP 由于是明文传输,所谓的明文,就是说客户端与服务端通信的信息都是肉眼可见的,随意使用一个抓包工具都可以截获通信的内容。
所以安全上存在以下三个风险:
窃听风险,比如通信链路上可以获取通信内容,用户号容易没。
篡改风险,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
冒充风险,比如冒充淘宝网站,用户钱容易没。
HTTPS 在 HTTP 与 TCP 层之间加入了 TLS 协议,来解决上述的风险。

TLS 协议是如何解决 HTTP 的风险的呢?
信息加密: HTTP 交互信息是被加密的,第三方就无法被窃取;
校验机制:校验信息传输过程中是否有被第三方篡改过,如果被篡改过,则会有警告提示;
身份证书:证明淘宝是真的淘宝网;
可见,有了 TLS 协议,能保证 HTTP 通信是安全的了,那么在进行 HTTP 通信前,需要先进行 TLS 握手。TLS 的握手过程,如下图:
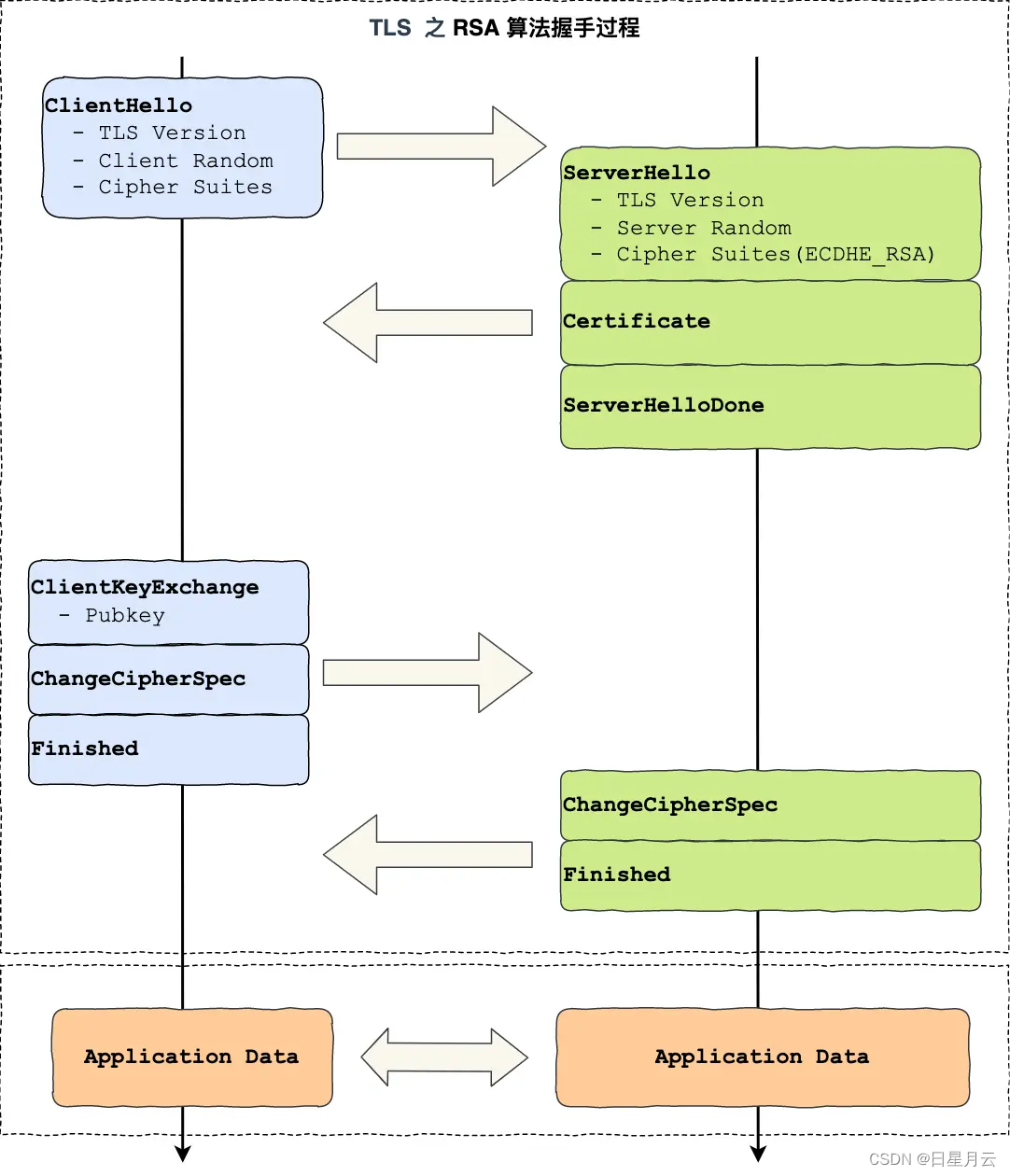
上图简要概述了 TLS 的握手过程,其中每一个「框」都是一个记录(record),记录是 TLS 收发数据的基本单位,类似于 TCP 里的 segment。多个记录可以组合成一个 TCP 包发送,所以通常经过「四个消息」就可以完成 TLS 握手,也就是需要 2个 RTT 的时延,然后就可以在安全的通信环境里发送 HTTP 报文,实现 HTTPS 协议。
所以可以发现,HTTPS 是应用层协议,需要先完成 TCP 连接建立,然后走 TLS 握手过程后,才能建立通信安全的连接。
事实上,不同的密钥交换算法,TLS 的握手过程可能会有一些区别。
这里先简单介绍下密钥交换算法,因为考虑到性能的问题,所以双方在加密应用信息时使用的是对称加密密钥,而对称加密密钥是不能被泄漏的,为了保证对称加密密钥的安全性,所以使用非对称加密的方式来保护对称加密密钥的协商,这个工作就是密钥交换算法负责的。
接下来,我们就以最简单的 RSA 密钥交换算法,来看看它的 TLS 握手过程。
RSA 握手过程
请看RSA 握手过程
Java基础
解决hash冲突的方法
数据结构中介绍的两种方法:
1.开放定址法
开放定址法也被称为“再散列法”。其基本思想是,当关键字key的初始散列地址h0=H(key)出现冲突时,以h0为基础查找下一个地址h1,如果h1仍然冲突,再以h0为基础,产生另一个散列地址h2…直到找出一个不冲突的地址hi,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
hi=(H(key)+di)%m i=1,2,…,n
其中,H(key)为哈希函数,h,=H(key),m为表长,di为增量序列。增量序列的取值方式不同,对应有不同的再散列方式,主要有以下三种。
(1)线性探测再散列
di=c×i 最简单的情况c=1
这种方法的特点是,冲突发生时,顺序查看表中下一个单元,直到找到一个空单元或查遍全表。值得注意的是,由于这里使用的是%运算,因而整个表成为一个首尾连接的循环表,在查找时类似于循环队列,表尾的后边是表头,表头的前边是表尾。
(2)二次探测再散列
di=12,-12,22,-22,…k2,-k2(k≤m/2)
这种方法的特点是,冲突发生时分别在表的右、左进行跳跃式探测,较为灵话,不易产生聚集,但缺点是不能探查到整个散列地址空间。
(3)随机探测再散列
di=伪随机数
这种方法需要建立一个随机数发生器,并给定一个随机数作为起始点。
2.链地址法
链地址法解决冲突的基本思想是,把所有具有地址冲突的关键字链在同一个单链表中: 若哈希表的长度为m,则可将哈希表定义为一个由m个头指针组成的指针数组。散列地址为i的记录均插入以指针数组第i个单元为头指针的单链表。
Java面试复习发现有第3种方法
3.再哈希法
再哈希:又叫双哈希法,有多个不同的Hash函数.当发生冲突时,使用第二个,第三个….等哈希函数计算地址,直到无冲突
网上又搜了一下发现有第4种方法
hash冲突的4种解决方案
4.建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
try catch finally
//下面是个测试程序
public class FinallyTest
{
public static void main(String[] args) {
System.out.println(new FinallyTest().test());;
}
static int test()
{
int x = 1;
try
{
x++;
return x;
}
finally
{
++x;
}
}
}
结果是2。
分析:
在try语句中,在执行return语句时,要返回的结果已经准备好了,就在此时,程序转到finally执行了。
在转去之前,try中先把要返回的结果存放到不同于x的局部变量中去,执行完finally之后,在从中取出返回结果,
因此,即使finally中对变量x进行了改变,但是不会影响返回结果。
它应该使用栈保存返回值。
Exception与Error的包结构
Java可抛出(Throwable)的结构分为三种类型:被检查的异常(CheckedException),运行时异常(RuntimeException),错误(Error)。
1、运行时异常
定义:RuntimeException及其子类都被称为运行时异常。
特点:Java编译器不会检查它。也就是说,当程序中可能出现这类异常时,倘若既"没有通过throws声明抛出它",也"没有用try-catch语句捕获它",还是会编译通过。
例如:除数为零时产生的ArithmeticException异常,数组越界时产生的IndexOutOfBoundsException异常,fail-fast机制产生的ConcurrentModificationException异常
常见的五种运行时异常:
ClassCastException(类转换异常)
IndexOutOfBoundsException(数组越界)
NullPointerException(空指针异常)
ArrayStoreException(数据存储异常,操作数组是类型不一致)
BufferOverflowException(文件流Buffer需要clear)
2、被检查异常
定义:Exception类本身,以及Exception的子类中除了"运行时异常"之外的其它子类都属于被检查异常。
特点 : Java编译器会检查它。 此类异常,要么通过throws进行声明抛出,要么通过try-catch进行捕获处理,否则不能通过编译。
例如,CloneNotSupportedException就属于被检查异常。当通过clone()接口去克隆一个对象,而该对象对应的类没有实现Cloneable接口,就会抛出CloneNotSupportedException异常。被检查异常通常都是可以恢复的。
如:
IOException
FileNotFoundException
SQLException
被检查的异常适用于那些不是因程序引起的错误情况,比如:读取文件时文件不存在引发的FileNotFoundException 。
然而,不被检查的异常通常都是由于糟糕的编程引起的,比如:在对象引用时没有确保对象非空而引起的 NullPointerException 。
3、错误
定义 : Error类及其子类。
特点 : 和运行时异常一样,编译器也不会对错误进行检查。
当资源不足、约束失败、或是其它程序无法继续运行的条件发生时,就产生错误。程序本身无法修复这些错误的。例如,VirtualMachineError就属于错误。出现这种错误会导致程序终止运行。
OutOfMemoryError、ThreadDeath。
Java虚拟机规范规定JVM的内存分为了好几块,比如堆,栈,程序计数器,方法区等
OOM你遇到过哪些情况,SOF你遇到过哪些情况
OOM:
1,OutOfMemoryError异常
除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(OOM)异常的可能。
Java Heap 溢出:
一般的异常信息:java.lang.OutOfMemoryError:Java heap spacess。java堆用于存储对象实例,我们只要不断的创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,就会在对象数量达到最大堆容量限制后产生内存溢出异常。
出现这种异常,一般手段是先通过内存映像分析工具(如Eclipse Memory Analyzer)对dump出来的堆转存快照进行分析,重点是确认内存中的对象是否是必要的,先分清是因为内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
如果是内存泄漏,可进一步通过工具查看泄漏对象到GCRoots的引用链。于是就能找到泄漏对象是通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收。
如果不存在泄漏,那就应该检查虚拟机的参数(-Xmx与-Xms)的设置是否适当。
2,虚拟机栈和本地方法栈溢出
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常
意思是没有到达最大深度,但是因内存空间不足二申请不到了
这里需要注意当栈的大小越大可分配的线程数就越少。
3,运行时常量池溢出
异常信息:java.lang.OutOfMemoryError:PermGenspace
如果要向运行时常量池中添加内容,最简单的做法就是使用String.intern()这个Native方法。该方法的作用是:如果池中已经包含一个等于此String的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。由于常量池分配在方法区内,我们可以通过-XX:PermSize和-XX:MaxPermSize限制方法区的大小,从而间接限制其中常量池的容量。
4,方法区溢出
方法区用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。也有可能是方法区中保存的class对象没有被及时回收掉或者class信息占用的内存超过了我们配置。
异常信息:java.lang.OutOfMemoryError:PermGenspace
方法区溢出也是一种常见的内存溢出异常,一个类如果要被垃圾收集器回收,判定条件是很苛刻的。在经常动态生成大量Class的应用中,要特别注意这点。
SOF(堆栈溢出StackOverflow):
StackOverflowError 的定义:当应用程序递归太深而发生堆栈溢出时,抛出该错误。
因为栈一般默认为1-2m,一旦出现死循环或者是大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。
栈溢出的原因:递归调用,大量循环或死循环,全局变量是否过多,数组、List、map数据过大。
线程有哪些基本状态?
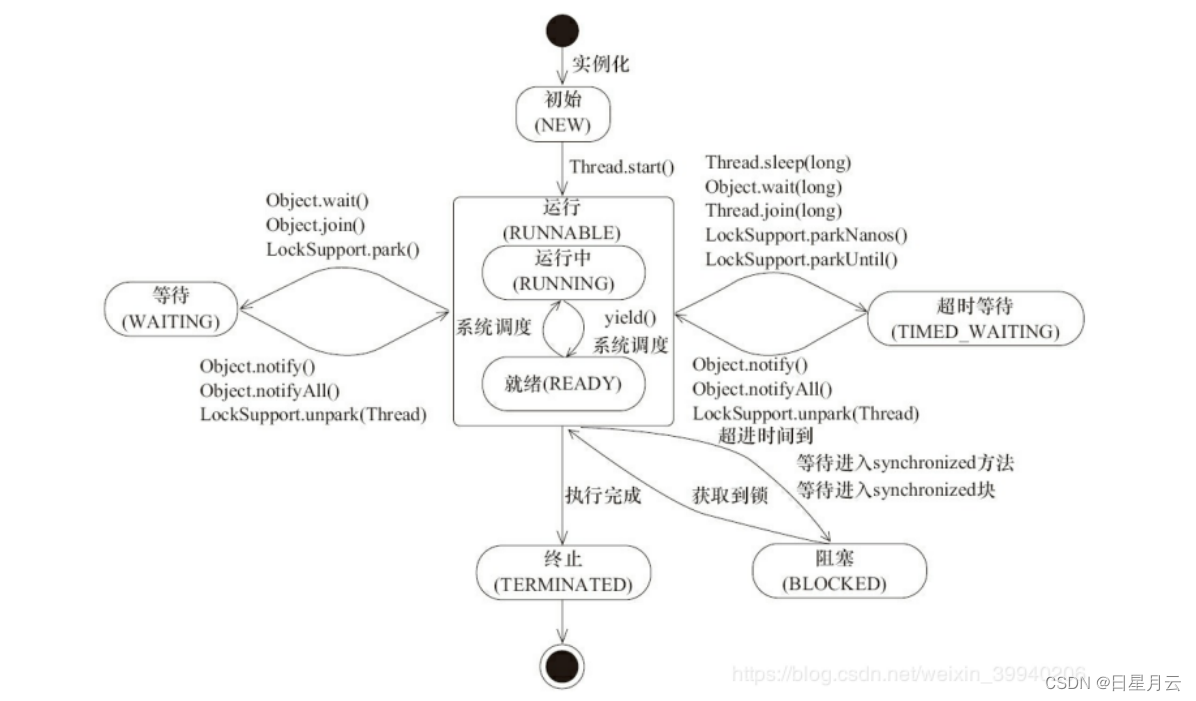
操作系统隐藏 Java虚拟机(JVM)中的 RUNNABLE 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:HowToDoInJava:Java Thread Life Cycle and Thread States),所以 Java 系统一般将这两个状态统称为 RUNNABLE(运行中) 状态 。
Java IO与 NIO的区别
推荐阅读:
什么是NIO?NIO的原理是什么机制?
堆和栈的区别
栈是运行时单位,代表着逻辑,内含基本数据类型和堆中对象引用,所在区域连续,没有碎片;
堆是存储单位,代表着数据,可被多个栈共享(包括成员中基本数据类型、引用和引用对象),所在区域不连续,会有碎片。
1、功能不同
栈内存用来存储局部变量和方法调用,而堆内存用来存储Java中的对象。无论是成员变量,局部变量,还是类变量,它们指向的对象都存储在堆内存中。
2、共享性不同
Young Generation 即图中的Eden + From Space(s0) + To Space(s1)
Eden 存放新生的对象
Survivor Space 有两个,存放每次垃圾回收后存活的对象(s0+s1)
Old Generation Tenured Generation 即图中的Old Space
主要存放应用程序中生命周期长的存活对象
栈内存是线程私有的。
堆内存是所有线程共有的。
3、异常错误不同
如果栈内存或者堆内存不足都会抛出异常。
栈空间不足:java.lang.StackOverFlowError。
堆空间不足:java.lang.OutOfMemoryError。
4、空间大小
栈的空间大小远远小于堆的
对象分配规则
- 对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC。
- 大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
- 长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor区,之后每经过一次Minor GC那么对象的年龄加1,知道达到阀值对象进入老年区。
- 动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
- 空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC。
notify()和notifyAll()有什么区别?
notify可能会导致死锁,而notifyAll则不会
任何时候只有一个线程可以获得锁,也就是说只有一个线程可以运行synchronized 中的代码
使用notifyall,可以唤醒所有处于wait状态的线程,使其重新进入锁的争夺队列中,而notify只能唤醒一个
举例:如果是生产者-消费者模型,生产者.notify了一个生产者,就会产生死锁
sleep()和wait() 有什么区别?
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。在调用sleep()方法的过程中,线程不会释放对象锁。
当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备,获取对象锁进入运行状态。
为什么wait, notify 和 notifyAll这些方法不在thread类里面?
明显的原因是JAVA提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需
要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在
等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们
定义在Object类中因为锁属于对象。
Java中synchronized 和 ReentrantLock 有什么不同?
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一
个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行
线程阻塞和唤醒的代价是比较高的.
区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需
要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配
合try/finally语句块来完成。
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指
令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经
拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计
算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释
放为止。
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,
ReentrantLock类提供了一些高级功能,主要有以下3项:
1.等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于
Synchronized来说可以避免出现死锁的情况。
2.公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,
ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性
能不是很好。
3.锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
常用的线程池有哪些?
newSingleThreadExecutor:创建一个单线程的线程池,此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
newFixedThreadPool:创建固定大小的线程池,每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。
newCachedThreadPool:创建一个可缓存的线程池,此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
newScheduledThreadPool:创建一个大小无限的线程池,此线程池支持定时以及周期性执行任务的需求。
newSingleThreadExecutor:创建一个单线程的线程池。此线程池支持定时以及周期性执行任务的需求。
简述一下你对线程池的理解
(如果问到了这样的问题,可以展开的说一下线程池如何用、线程池的好处、线程池的启动策略)合理利用线程池能够带来三个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
反射
在ArrayList中的构造器中
有个构造包含指定集合的元素的列表
使用到getClass()方法

Java集合
ArrayList
get查找
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
set修改
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
add添加
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
remove删除
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
elementData 下标获取
E elementData(int index) {
return (E) elementData[index];
}
grow扩容
计算所需的最小长度
例如:add(),minCapacity=size+1
grow():
得到旧容量:oldCapacity=elementData.length;
计算新容量:newCapacity=oldCapacity + (oldCapacity >> 1);
如果新容量<所需最小长度
新容量=最小长度
如果minCapacity大于MAX_ARRAY_SIZE,
则新容量则为Interger.MAX_VALUE,
否则,新容量大小则为 MAX_ARRAY_SIZE。
elementData=Arrays.copyof(elementData,newCapacity)
测试代码:
测试1:默认构造器
private static void extracted1() throws NoSuchFieldException {
//测试默认构造器第一次add,扩容机制
ArrayList<Integer> arrayList=new ArrayList<>();
//this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
//第一次强制进入Integer.valueOf()
//第二次强制进入ArrayList.add()
// arrayList.add(1);
//直接进入add()
arrayList.add(new Integer(1));
/*
add(E e){
ensureCapacityInternal(size + 1); // Increments modCount!!{
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//10
}
ensureExplicitCapacity(minCapacity=10);{
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity=10);{
int oldCapacity = elementData.length;//0
int newCapacity = oldCapacity + (oldCapacity >> 1);//0
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;//10
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//10
}
}
}
elementData[size++] = e;
}
*/
}
测试2:传入initialCapacity=0
private static void extracted2() {
// ArrayList<Integer> arrayList0=new ArrayList<>(-1);
// throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
ArrayList<Integer> arrayList = new ArrayList<>(0);
// this.elementData = EMPTY_ELEMENTDATA;
arrayList.add(new Integer(1));
/*
add(E e){
ensureCapacityInternal(minCapacity=size+1){
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);{
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);{
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
}
elementData[size++] = e;
}
*/
}
测试3:传入initialCapacity=1
private static void extracted3() {
ArrayList<Integer> arrayList1=new ArrayList<>(1);
// this.elementData = new Object[initialCapacity];
arrayList1.add(new Integer(1));
arrayList1.add(new Integer(2));
// elementData = Arrays.copyOf(elementData, newCapacity);//传入newCapacity=2
}
LinkedList
get查找
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
set修改
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
node通过下标获取结点
Node<E> node(int index) {
// assert isElementIndex(index);
//如果小于一半,使用next
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//如果大于一半,使用prev
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
add添加
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
remove删除
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
linkBefore前插
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
unlink移除
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//更改next指针
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//更改prev指针
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
ArrayList和LinkedList对比
数组和链表的区别
数组:查找更新快(下标获取),插入删除慢(复制数组)
链表:查找更新慢(从前往后,或从后往前),插入删除快(两个指针前驱和后继的操作)
//ArrayList
查找更新---下标获取
get---elementData[index]
set---elementData[index]
插入删除(复制数组)
add---arraycopy
remove---arraycopy
//LinkedList
查找更新----从前到后或从后到前来查
get---node
set---node
插入删除----两个指针前驱和后继操作
add---linkBefore
remove--unlink
HashMap
get查找
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//---------------------------------------------------------
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//先检查数组是否为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//再检查头部
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//再检查后续结点
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
remove
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
//-----------------------------------------------------------------------------------
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//判断数组是否为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
//先找到,放到node
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//删除node
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
put插入|修改

put
putVal
如果table为空或长度为0 resize()扩容
根据hash&len-1找到槽位
如果为空,直接插入
否则,hash冲突
判断第一个元素是否相等,更新
否则,得到node结点
判断是否是红黑树TreeNode,红黑树插入
遍历链表,相等更新,否则插入到最后
1.7的put
- 我们的put方法会去判断这个hashmap是否为null或者长度是否为0,如果是则调用inflateTable()方法对该hashmap数组初始化;
- 判断key是否为null,为null则遍历以table[0]为首的链表,寻找是否存在key==null对应的键值对,若存在,则覆盖旧value;同时返回旧的value值,否则调用addEntry()完成插入;
- key不为null.根据key计算数组索引值,循环链表,判断该key是否存在,存在,则覆盖旧value,并返回旧value;
- addEntry()先判断是否需要扩容,如果要扩容就进行扩容,如果不用扩容就生成Entry对象,并使用头插法添加到当前位置的链表中;
1.8的put
- 我们的put方法会去判断这个hashmap是否为null或者长度是否为0,如果是则对该hashmap数组进行resize()扩容;
- put方法根据key通过hash算法与运算得到数组下标;
- 如果数组下标元素为空,则将key和value封装成Node<K,V>并放入该位置
- 如果数组下标元素不为空:
- a.判断数组上该位置key是否相同,相同则执行覆盖操作,返回老的value值
- b.不相同,则判断该节点上Node的类型,判断是是红黑树或者是链表.
- i.如果是红黑树Node,则将key和value封装为一个红黑树节点并添加到红黑树中去,在这个过程中会判断红黑树中是否存在当前key,如果存在则更新value
- ii.如果是链表节点,则将key和value封装为一个链表Node并通过尾插法插入到链表的最后位置去,因为是尾插法,所以需要遍历链表,在遍历链表的过程中会判断是否存在当前key,如果存在则更新value,当遍历完链表后,将新链表Node插入到链表中,插入到链表后,会看当前链表的节点个数,如果大于等于8,(数组长度大于64)那么则会将该链表转成红黑树





resize扩容
resize()
两个作用
初始化数组,扩容
/**
* resize() 有两个模式,1.初始化数组,2.扩容。
* 整体氛围两大步骤:
* 1)计算新数组大小,然后创建新数组
* 初始化 指定容量构造,newCap=threshold
* 未指定容量构造,newCap=16 扩容:newCap=oldCap * 2
*
* 2) 执行扩容策略:逐个遍历所有槽点,根据具体情况进行迁移
* 情况一:当前槽点只有一个node,直接重新分配到新数组即可newTab[e.hash & (newCap - 1)]
* 情况二:当前槽点下是红黑树
* 情况三:当前槽点下是链表:因为链表中所有node的hash和key相同,而现在数组扩容了两倍,所以现在的想法是将当前链等分成两部分
* 怎么等分成两部分?分成high链与low链,两链关系可近似理解为单双数节点 (e.hash & oldCap) == 0
* 怎么实现?hiHead、loHead 用来标识高低链,hiTail、loTail用来尾插新节点
* 两链放在新数组哪里?:low 链置于newTab[ j ],high 链置于newTab[ j + oldCap ]( j 表示在原来数组位置)
*/
当size大于threshold
执行模式有三种:初始化 扩容
扩容策略有三种:单点 红黑树 链表
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// threshold > 0 有两种情况
// 1.指定容量的初始化值,此时 oldCap = 0
// 2.扩容阈值,此时 oldCap != 0
int oldThr = threshold;
int newCap, newThr = 0;
// 模式一:oldCap>0表示要扩容
if (oldCap > 0) {
// 当老数组容量已达最大值时无法再扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// Cap * 2 , Thr * 2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 模式二:初始化,且已指定初始化容量
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 模式三:初始化,未指定初始化容量
else {
// 以默认初始化容量16进行初始化
newCap = DEFAULT_INITIAL_CAPACITY;
// 16 * 0.75 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 用指定容量初始化后,更新其扩容阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新扩容阈值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 执行初始化,建立新数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 将新数组附给table
table = newTab;
//-------------------------------扩容策略-----------------------------------------------
// 若是执行的初始化,old=null,就不用走这里的扩容策略了,而是直接返回赋值去了
if (oldTab != null) {
// 遍历原数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 当原数组的当前槽点有值时,将其赋给e
if ((e = oldTab[j]) != null) {
// 释放原数组当前节点内存,帮助GC
oldTab[j] = null;
// 情况一:若当前槽点只有一个值,直接找到新数组相应位置并赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 情况二:若当前节点下是红黑树
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//当做链表处理,最后判断是否退化链表 小于6 否则树化
// 情况三:当前节点下是链表
else { // preserve order
// 将该链表分成两条链,low低位链 和 high高位链
// Head标识链头,Tail用来连接
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// do while((e = next) != null)
do {
next = e.next;
// 低位链连接
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 高位链连接
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 将低位链放置于老链同一下标
// eg.原来当前节点位于oldTab[2],则现在低位链还置于newTab[2]
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 将高位链放置于老链下标+oldCap
// eg.原来当前节点位于oldTab[2],则现在高位链置于newTab[2+8=10]
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
AQS
说说你对AQS的理解
它是抽象的队列同步器,
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配
AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。
AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
状态信息通过 protected 类型的 getState , setState , compareAndSetState 进行操作
模板方法模式实现架构
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;
正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。

以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独
占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即
释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的
(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state
是能回到零态的。
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个
数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会
CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然
后主调用线程就会从 await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现 tryAcquiretryRelease 、 tryAcquireShared-tryReleaseShared 中的一种即可。但 AQS 也支持自定义同步器同
时实现独占和共享两种方式,如 ReentrantReadWriteLock 。
Semaphore与CountDownLatch一样,也是共享锁的一种实现。它默认构造AQS的state为
permits。当执行任务的线程数量超出permits,那么多余的线程将会被放入阻塞队列Park,并自旋判断
state是否大于0。只有当state大于0的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执
行release方法,release方法使得state的变量会加1,那么自旋的线程便会判断成功。
如此,每次只有最多不超过permits数量的线程能自旋成功,便限制了执行任务线程的数量。
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到
达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障
拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties) ,其参数
表示屏障拦截的线程数量,每个线程调用 await 方法告诉 CyclicBarrier 我已经到达了屏障,然后当前
线程被阻塞。
再来看一下它的构造函数:
其中,parties 就代表了有拦截的线程的数量,当拦截的线程数量达到这个值的时候就打开栅栏,让所
有线程通过。
总结:CyclicBarrier 内部通过一个 count 变量作为计数器,cout 的初始值为 parties 属性的初始化
值,每当一个线程到了栅栏这里了,那么就将计数器减一。如果 count 值为 0 了,表示这是这一代最后
一个线程到达栅栏,就尝试执行我们构造方法中输入的任务。
ReentrantReadWtiteLock
实现
state使用高低位区分读锁 写锁的状态
//因为读锁和写锁使用的是同一个Sync,但是只有一个state,所以应该如何区分
//高16位存读锁 低16位存写锁
//统计读锁的个数 无符号右移16位 取出state高16位
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
//统计写锁的个数 按位与16个1 取出state低16位
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
static final int SHARED_SHIFT = 16; //16位划分读锁和写锁的状态
static final int SHARED_UNIT = (1 << SHARED_SHIFT); //读锁的单位 状态+-
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;//锁最大的数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;//取写锁的数量
ReentrantLock的特性:
绑定多个条件:newCondition
举例:ArrayBlockingQueue源码
目标:生产者通知消费者,消费者通知生产者。
避免:生产者通知生产者,消费者通知消费者。
//两个队列 两个Condition
private final Condition notEmpty;
private final Condition notFull;
如果是传统的synchronize,必须signalAll()
2023-7-26 09:27:15
CopyOnWriteArrayList
读读
读写使用COW
写写使用锁
读不加锁
写加锁,并且CopyOnWrite进行复制到新数组,替换引用,
底层数组是volatile修饰,触发volatile语义,使得其他多的线程立即可见
高频面试题-Java 集合【java面试】:01 / CopyOnWriteArrayList
对于CopyOnWriteArrayList集合,正如它的名字所暗示的,它采用复制底层数组的方式来实现写操作。当线程对CopyOnWriteArrayList集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。**当线程对CopyOnWriteArrayList集合执行写入操作时,该集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。**由于对CopyOnWriteArrayList集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。
需要指出的是,由于CopyOnWriteArrayList执行写入操作时需要频繁地复制数组,性能比较差,但由于读操作与写操作不是操作同一个数组,而且读操作也不需要加锁,因此读操作就很快、很安全。由此可见,CopyOnWriteArrayList适合用在读取操作远远大于写入操作的场景中,例如缓存等。
COW技术的举例:
Redis的hash,渐进式rehash
Redis的RDB持久化:bgsave
子进程在写RDB文件时,父进程COW修改数据页
写时复制技术
改数据在复制数组中
读数据在旧数组中
读多写少场景:避免老是复制数组
读写是通过COW规避
读快照,写新数组
写写是通过加锁规避
package java.util.concurrent;
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
//可重入锁
final transient ReentrantLock lock = new ReentrantLock();
//底层是[]
private transient volatile Object[] array;
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));//复制的数组
}
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
//--------------------------------------------------------------------------------
//读的时候不加锁
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
//--------------------------------------------------------------------------------
//写的时候加锁
//加锁为了拷贝数组
//之后添加数据
//最后修改引用 触发volatile
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
//--------------------------------------------------------------------------------
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
static final class COWIterator<E> implements ListIterator<E> {
/** Snapshot of the array */
private final Object[] snapshot;//快照 迭代时
/** Index of element to be returned by subsequent call to next. */
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
public boolean hasPrevious() {
return cursor > 0;
}
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
@SuppressWarnings("unchecked")
public E previous() {
if (! hasPrevious())
throw new NoSuchElementException();
return (E) snapshot[--cursor];
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code remove}
* is not supported by this iterator.
*/
public void remove() {
throw new UnsupportedOperationException();
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code set}
* is not supported by this iterator.
*/
public void set(E e) {
throw new UnsupportedOperationException();
}
/**
* Not supported. Always throws UnsupportedOperationException.
* @throws UnsupportedOperationException always; {@code add}
* is not supported by this iterator.
*/
public void add(E e) {
throw new UnsupportedOperationException();
}
@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
Object[] elements = snapshot;
final int size = elements.length;
for (int i = cursor; i < size; i++) {
@SuppressWarnings("unchecked") E e = (E) elements[i];
action.accept(e);
}
cursor = size;
}
}
}
ConcurrentHashMap
1.7是一个HashMap拆为几个子HashMap,称为一个段
并发的就是初始的段的数量
1.8引入红黑树
每一个数组槽位是一个单位
高频面试题-Java 集合【java面试】:02 / ConcurrentHashMap
JDK 7中的实现方式:
为了提高并发度,在JDK7中,一个HashMap被拆分为多个子HashMap。每一个子HashMap称作一个Segment,多个线程操作多个Segment相互独立。在JDK 7中的分段锁,有三个好处:
- 减少Hash冲突,避免一个槽里有太多元素。
- 提高读和写的并发度,段与段之间相互独立。
- 提高了扩容的并发度,它不是整个ConcurrentHashMap一起扩容,而是每个Segment独立扩容。
分而治之思想

- 使用红黑树,当一个槽里有很多元素时,其查询和更新速度会比链表快很多,Hash冲突的问题由此得到较好的解决。
- 加锁的粒度,并非整个ConcurrentHashMap,而是对每个头节点分别加锁,即并发度,就是Node数组的长度,初始长度为16,和在JDK 7中初始Segment的个数相同。
- 并发扩容,这是难度最大的。在JDK 7中,一旦Segment的个数在初始化的时候确立,不能再更改,并发度被固定。之后只是在每个Segment内部扩容,这意味着每个Segment独立扩容,互不影响,不存在并发扩容的问题。但在JDK 8中,相当于只有1个Segment,当一个线程要扩容Node数组的时候,其他线程还要读写,因此处理过程很复杂。

初始化时
容量 cap=tableSizeFor(传入参数的1.5倍+1)
sizeCtl = cap;
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));//1.5倍 2的n次方
this.sizeCtl = cap;
}
sizeCtl的两个作用
调整控件
扩容的阈值:sizeCtl = (n << 1) - (n >>> 1)
//控制信号量
//阈值
/**
*表初始化和调整大小控件。
当为负值时表正在初始化或调整大小:
-1用于初始化,
else-(1+活动的调整大小线程的数量)。
否则
* 当table为null时,保留要使用的初始表大小创建,或默认为0。
初始化后,保持用于调整表大小的下一个元素计数值。
*/
private transient volatile int sizeCtl;
//transfer() 中
//sizeCtl = (n << 1) - (n >>> 1);
ConcurrentHashMap机制小结:
- 初始操作:以CAS方式初始化数组和头节点;
- 插入节点:在某位置插入节点时做加锁处理;
- 扩容操作:每个线程负责扩容一部分数据,扩容时做加锁处理。并且扩容时依然支持读写操作,若该位置的节点不是fwd则直接读写,否则就访问访问新数组进行读写。
JUC
多线程
单个进程中同时运行多个线程
好处:提高CPU利用率,避免等待网络IO或磁盘IO
举例:Tomcat并行处理多个请求
局限:太多的线程导致CPU上下文切换的开销增大
线程安全性问题:操作临界资源,数据不一致;涉及到锁可能会引起死锁。
Java语言中的线程安全
不可变类:String、Integer
绝对线程安全
相对线程安全
线程兼容
线程对立
ThreadLocal保证原子性的方式,是不让多线程去操作临界资源,让每个线程去操作属于自己的数据,Map<Thread,资源>
线程安全的实现方法
互斥同步:
synchronize,ReentrantLock
非阻塞同步:
CAS
争用共享资源,成功;失败就不停重试;
避免了线程的阻塞和唤醒带来的开销
无同步方案:
可重入代码
线程本地存储
线程的创建
继承Thread,重写run()方法
实现Runnable,重写run()方法
实现Callable,重写call()方法
Thread FutureTask Callable
线程池创建:submit、execute
线程的状态
操作系统中:
NEW Ready Running BLOCKED TERMINATED
新建 就绪 运行 阻塞 结束
Java中:
NEW RUNNABLE WAIT TIME-WAIT BLOCKED TERMINATED
新建 运行 无限期等待 限期等待 阻塞 结束
wait和sleep的区别
wait是Object类中的方法,sleep是Thread类中的静态方法
sleep属于TIMED_WAITING,自动被唤醒、wait属于WAITING,需要手动唤醒。
wait会放弃锁资源,sleep仍占用锁锁资源
sleep可以在持有锁或者不持有锁时,执行。 wait方法必须在持有锁时(同步代码块中|临界区)才可以执行。
抛出llegalMonitorStateException
wait方法会将持有锁的线程从owner扔到WaitSet集合中,这个操作是在修改ObjectMonitor对象,如果没有持有synchronized锁的话,是无法操作ObjectMonitor对象的。
ThreadLocal
Java中的四种引用类型
Java中的使用引用类型分别是强,软,弱,虚。
User user = new User();
在 Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它始终处于可达状态,它是不可能被垃圾回收机制回收的,即使该对象以后永远都不会被用到 JVM 也不会回收。因此强引用是造成 Java 内存泄漏的主要原因之一。
SoftReference
其次是软引用,对于只有软引用的对象来说,当系统内存足够时它不会被回收,当系统内存空间不足时它会被回收。软引用通常用在对内存敏感的程序中,作为缓存使用。
然后是弱引用,它比软引用的生存期更短,对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存。可以解决内存泄漏问题,ThreadLocal就是基于弱引用解决内存泄漏的问题。
最后是虚引用,它不能单独使用,必须和引用队列联合使用。虚引用的主要作用是跟踪对象被垃圾回收的状态。不过在开发中,我们用的更多的还是强引用。
ThreadLocal保证原子性的方式,是不让多线程去操作临界资源,让每个线程去操作属于自己的数据
代码实现
static ThreadLocal tl1 = new ThreadLocal();
static ThreadLocal tl2 = new ThreadLocal();
public static void main(String[] args) {
tl1.set("123");
tl2.set("456");
Thread t1 = new Thread(() -> {
System.out.println("t1:" + tl1.get());
System.out.println("t1:" + tl2.get());
});
t1.start();
System.out.println("main:" + tl1.get());
System.out.println("main:" + tl2.get());
}
ThreadLocal实现原理:
- 每个Thread中都存储着一个成员变量,ThreadLocalMap
- ThreadLocal本身不存储数据,像是一个工具类,基于ThreadLocal去操作ThreadLocalMap
- ThreadLocalMap本身就是基于Entry[]实现的,因为一个线程可以绑定多个ThreadLocal,这样一来,可能需要存储多个数据,所以采用Entry[]的形式实现。
- 每一个现有都自己独立的ThreadLocalMap,再基于ThreadLocal对象本身作为key,对value进行存取
- ThreadLocalMap的key是一个弱引用,弱引用的特点是,即便有弱引用,在GC时,也必须被回收。这里是为了在ThreadLocal对象失去引用后,如果key的引用是强引用,会导致ThreadLocal对象无法被回收
ThreadLocal内存泄漏问题:
- 如果ThreadLocal引用丢失,key因为弱引用会被GC回收掉,如果同时线程还没有被回收,就会导致内存泄漏,内存中的value无法被回收,同时也无法被获取到。
- 只需要在使用完毕ThreadLocal对象之后,及时的调用remove方法,移除Entry即可

synchronize的优化
锁消除:没有操作临界资源
锁膨胀:循环内获取锁->循环外获取锁
锁升级:无锁->偏向锁->轻量级锁->重量级锁
- 无锁、匿名偏向:当前对象没有作为锁存在。
- 偏向锁:如果当前锁资源,只有一个线程在频繁的获取和释放,那么这个线程过来,只需要判断,当前指向的线程是否是当前线程 。
- 如果是,直接拿着锁资源走。
- 如果当前线程不是我,基于CAS的方式,尝试将偏向锁指向当前线程。如果获取不到,触发锁升级,升级为轻量级锁。(偏向锁状态出现了锁竞争的情况)
- 轻量级锁:会采用自旋锁的方式去频繁的以CAS的形式获取锁资源(采用的是自适应自旋锁)
- 如果成功获取到,拿着锁资源走
- 如果自旋了一定次数,没拿到锁资源,锁升级。
- 重量级锁:就是最传统的synchronized方式,拿不到锁资源,就挂起当前线程。(用户态&内核态)
synchronize和Reentrant的对比
JVM语义,API层面
monitorenter monitorexit
基于AQS实现,有一个基于CAS维护的state变量来实现锁的操作。
都是可重入锁
1.6优化synchronize,可以锁升级
额外功能
等待可中断:ReentrantLock可以指定等待锁资源的时间。
public boolean tryLock(long timeout, TimeUnit unit)
公平锁:ReentrantLock支持公平锁和非公平锁
public ReentrantLock(boolean fair)
锁绑定多个条件
public Condition newCondition()
ReentrantLock和synchronized的区别
废话区别:单词不一样。。。
核心区别:
- ReentrantLock是个类,synchronized是关键字,当然都是在JVM层面实现互斥锁的方式
效率区别:
- 如果竞争比较激烈,推荐ReentrantLock去实现,不存在锁升级概念。而synchronized是存在锁升级概念的,如果升级到重量级锁,是不存在锁降级的。
底层实现区别:
- 实现原理是不一样,ReentrantLock基于AQS实现的,synchronized是基于ObjectMonitor
功能向的区别:
- ReentrantLock的功能比synchronized更全面。
- ReentrantLock支持公平锁和非公平锁
- ReentrantLock可以指定等待锁资源的时间。
选择哪个:如果你对并发编程特别熟练,推荐使用ReentrantLock,功能更丰富。如果掌握的一般般,使用synchronized会更好
AQS
说说你对AQS的理解
它是抽象的队列同步器,
AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且
将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒
时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实
例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的
一个结点(Node)来实现锁的分配
AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。
AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
状态信息通过 protected 类型的 getState , setState , compareAndSetState 进行操作
模板方法模式实现架构
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;
正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独
占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即
释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的
(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state
是能回到零态的。
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个
数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会
CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然
后主调用线程就会从 await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现 tryAcquiretryRelease 、 tryAcquireShared-tryReleaseShared 中的一种即可。但 AQS 也支持自定义同步器同
时实现独占和共享两种方式,如 ReentrantReadWriteLock 。
Semaphore与CountDownLatch一样,也是共享锁的一种实现。它默认构造AQS的state为
permits。当执行任务的线程数量超出permits,那么多余的线程将会被放入阻塞队列Park,并自旋判断
state是否大于0。只有当state大于0的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执
行release方法,release方法使得state的变量会加1,那么自旋的线程便会判断成功。
如此,每次只有最多不超过permits数量的线程能自旋成功,便限制了执行任务线程的数量。
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到
达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障
拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties) ,其参数
表示屏障拦截的线程数量,每个线程调用 await 方法告诉 CyclicBarrier 我已经到达了屏障,然后当前
线程被阻塞。
再来看一下它的构造函数:
其中,parties 就代表了有拦截的线程的数量,当拦截的线程数量达到这个值的时候就打开栅栏,让所
有线程通过。
总结:CyclicBarrier 内部通过一个 count 变量作为计数器,cout 的初始值为 parties 属性的初始化
值,每当一个线程到了栅栏这里了,那么就将计数器减一。如果 count 值为 0 了,表示这是这一代最后
一个线程到达栅栏,就尝试执行我们构造方法中输入的任务。
ReentrantReadWtiteLock
实现
state使用高低位区分读锁 写锁的状态
//因为读锁和写锁使用的是同一个Sync,但是只有一个state,所以应该如何区分
//高16位存读锁 低16位存写锁
//统计读锁的个数 无符号右移16位 取出state高16位
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
//统计写锁的个数 按位与16个1 取出state低16位
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }
static final int SHARED_SHIFT = 16; //16位划分读锁和写锁的状态
static final int SHARED_UNIT = (1 << SHARED_SHIFT); //读锁的单位 状态+-
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;//锁最大的数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;//取写锁的数量
ReentrantLock的特性:
绑定多个条件:newCondition
举例:ArrayBlockingQueue源码
目标:生产者通知消费者,消费者通知生产者。
避免:生产者通知生产者,消费者通知消费者。
//两个队列 两个Condition
private final Condition notEmpty;
private final Condition notFull;
如果是传统的synchronize,必须signalAll()
2023-7-26 09:27:15
线程池
固定线程池 n,n
单例线程池 1,1
可缓存线程池:0 max
定时任务线程池:DelayQueue
ThreadPoolExecutor
查看一下ThreadPoolExecutor提供的七个核心参数
public ThreadPoolExecutor(
int corePoolSize, // 核心工作线程(当前任务执行结束后,不会被销毁)
int maximumPoolSize, // 最大工作线程(代表当前线程池中,一共可以有多少个工作线程)
long keepAliveTime, // 非核心工作线程在阻塞队列位置等待的时间
TimeUnit unit, // 非核心工作线程在阻塞队列位置等待时间的单位
BlockingQueue<Runnable> workQueue, // 任务在没有核心工作线程处理时,任务先扔到阻塞队列中
ThreadFactory threadFactory, // 构建线程的线程工作,可以设置thread的一些信息
RejectedExecutionHandler handler) { // 当线程池无法处理投递过来的任务时,执行当前的拒绝策略
// 初始化线程池的操作
}
JDK提供的几种拒绝策略:
- AbortPolicy:当前拒绝策略会在无法处理任务时,直接抛出一个异常
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
- CallerRunsPolicy:当前拒绝策略会在线程池无法处理任务时,将任务交给调用者处理
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
- DiscardPolicy:当前拒绝策略会在线程池无法处理任务时,直接将任务丢弃掉
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
- DiscardOldestPolicy:当前拒绝策略会在线程池无法处理任务时,将队列中最早的任务丢弃掉,将当前任务再次尝试交给线程池处理
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
- 自定义Policy:根据自己的业务,可以将任务扔到数据库,也可以做其他操作。
private static class MyRejectedExecution implements RejectedExecutionHandler{
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("根据自己的业务情况,决定编写的代码!");
}
}
ThreadPoolExecutor源码
ctl变量
高三位:代表线程池的5种状态
低29位:工作线程的个数
ConcurrentHashMap
ConcurrentHashMap是线程安全的HashMap
ConcurrentHashMap在JDK1.8中是以CAS+synchronized实现的线程安全
CAS:在没有hash冲突时(Node要放在数组上时)
synchronized:在出现hash冲突时(Node存放的位置已经有数据了)
存储的结构:数组+链表+红黑树
sizeCtl:是数组在初始化和扩容操作时的一个控制变量
-1:代表当前数组正在初始化
小于-1:低16位代表当前数组正在扩容的线程个数(如果1个线程扩容,值为-2,如果2个线程扩容,值为-3)
0:代表数组还没初始化
大于0:代表当前数组的扩容阈值,或者是当前数组的初始化大小
CopyOnWriteArrayList
CopyOnWriteArrayList是一个线程安全的ArrayList。
CopyOnWriteArrayList是基于lock锁和数组副本的形式去保证线程安全。
在写数据时,需要先获取lock锁,需要复制一个副本数组,将数据插入到副本数组中,将副本数组赋值给CopyOnWriteArrayList中的array。
因为CopyOnWriteArrayList每次写数据都要构建一个副本,如果你的业务是写多,并且数组中的数据量比较大,尽量避免去使用CopyOnWriteArrayList,因为这里会构建大量的数组副本,比较占用内存资源。
CopyOnWriteArrayList是弱一致性的,写操作先执行,但是副本还有落到CopyOnWriteArrayList的array属性中,此时读操作是无法查询到的。
Mysql
Mysql常见面试题
Mysql索引
物理实现:B+树和Hash
类型:聚簇索引和非聚簇索引
最左前缀法则
底层的B+树结构
当一个列的左列的值全部相等时,该列才有序
Mysql事务
事务:就是一组操作要么同时成功,要么同时失败
ACID四个特性
原子性:一组操作同时成功,同时失败
保证:redo日志
一致性:从一个一致性状态到达下一个一致性状态
保证:
约束一致性:创建表结构时所指定的外键、唯一索引等约束。
数据一致性:其他三个保证,一般都是程序员进行处理的
隔离性:两个事务不会互相影响
保证:MVCC和锁
脏写 脏读 可重复读 幻读
持久性:持久化到磁盘上
保证:undo日志
Mysql日志
redo log:重做日志
undo log:回滚日志
binlog:二进制日志
relay log:中继日志
Mysql锁
第15章 锁:3. 锁的不同角度分类:3.2 从数据操作的粒度划分:表级锁、页级锁、行锁
表锁:
① 表级别的S锁、X锁
InnoDB不会对其主动加该锁
LOCK TABLES t READ | LOCK TABLES t WRITE
② 意向锁 (intention lock)
多粒度:加行锁之前先加意向锁,标志位的思想
③ 自增锁(AUTO-INC锁)
插入自增主键的时候,不需赋值
④ 元数据锁(MDL锁)
当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。
行锁:
① 记录锁(Record Locks)
记录锁也就是仅仅把一条记录锁上,官方的类型名称为: LOCK_REC_NOT_GAP 。
② 间隙锁(Gap Locks)
gap锁的提出仅仅是为了防止插入幻影记录而提出的
③ 临键锁(Next-Key Locks)
记录锁+间隙锁
Next-Key Locks是在存储引擎 innodb 、事务级别在 可重复读 的情况下使用的数据库锁,
innodb默认的锁就是Next-Key locks。
④ 插入意向锁(Insert Intention Locks)
插入意向锁是在插入一条记录行前,由 INSERT 操作产生的一种间隙锁
事实上插入意向锁并不会阻止别的事务继续获取该记录上任何类型的锁。
死锁
元数据锁导致死锁
间隙锁导致死锁
互相申请对方所占有的资源导致死锁
where列没加索引,导致全表扫描,进而锁住全表
①超时等待,但是阈值时间不好确定
②死锁检测
死锁检测的原理是构建一个以事务为顶点、锁为边的有向图,判断有向图是否存在环,存在即有死锁
Mysql MVCC
MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC是通过数据行的多个版本管理来实现数据库的并发控制。这项技术使得在InnoDB的事务隔离级别下执行一致性读操作有了保证。换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。
MVCC在MySQL InnoDB中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读,而这个读指的就是快照读,而非当前读。当前读实际上是一种加锁的操作,是悲观锁的实现。而MVCC本质是采用乐观锁思想的一种方式。
快照读(一致性读)和 当前读(最新)
MVCC 的实现依赖于:隐藏字段、Undo Log、Read View
隐藏字段:row_id、tx_id、roll_pointer
undo log版本链
Read View
ReadView就是事务A在使用MVCC机制进行快照读操作时产生的读视图。当事务启动时,会生成数据库系统当前的一个快照,InnoDB为每个事务构造了一个数组,用来记录并维护系统当前活跃事务的ID(“活跃"指的就是,启动了但还没提交)

READ COMMITTED :每次读取数据前都生成一个ReadView
REPEATABLE READ 隔离级别的事务来说,只会在第一次执行查询语句时生成一个 ReadView ,之后的查询就不会重复生成了。

Mysql中的Buffer
Buffer Pool
因为不想每次修改,就得把数据页持久到磁盘中
所以设置Buffer Pool
只要适用于普通非唯一索引,因为没有唯一性约束
所以对其的修改,不需要判断
先修改到Buffer Pool中,直到它调入内存中,再进行合并
change buffer
对于非唯一索引的一个优化
log buffer
redo log的分为内存中的redo log buffer
和文件中的redo log
doublewrite buffer
因为Mysql中的页大小和操作系统的页大小不一致
数据库的三范式是什么
/* 建表规范 */ ------------------
-- Normal Format, NF
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF, 第一范式
字段不能再分,就满足第一范式。
-- 2NF, 第二范式
满足第一范式的前提下,不能出现部分依赖。
消除复合主键就可以避免部分依赖。增加单列关键字。
只能完全依赖主键,而不能依赖主键的一部分
-- 3NF, 第三范式
满足第二范式的前提下,不能出现传递依赖。
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
将一个实体信息的数据放在一个表内实现。
只能直接依赖于主键,不能依赖于其他属性
反范式化
MySQL对于LRU的优化
普通LRU算法
LRU = Least Recently Used(最近最少使用): 就是末尾淘汰法,新数据从链表头部加入,释放空间时从末尾淘汰.

- 当要访问某个页时,如果不在Buffer Pool,需要把该页加载到缓冲池,并且把该缓冲页对应的控制块作为节点添加到LRU链表的头部。
- 当要访问某个页时,如果在Buffer Pool中,则直接把该页对应的控制块移动到LRU链表的头部
- 当需要释放空间时,从最末尾淘汰
普通LRU链表的优缺点
优点
- 所有最近使用的数据都在链表表头,最近未使用的数据都在链表表尾,保证热数据能最快被获取到。
缺点
- 如果发生全表扫描(比如:没有建立合适的索引 or 查询时使用select * 等),则有很大可能将真正的热数据淘汰掉.
- 由于MySQL中存在预读机制,很多预读的页都会被放到LRU链表的表头。如果这些预读的页都没有用到的话,这样,会导致很多尾部的缓冲页很快就会被淘汰。

改进型LRU算法
改进型LRU:将链表分为new和old两个部分,加入元素时并不是从表头插入,而是从中间midpoint位置插入(就是说从磁盘中新读出的数据会放在冷数据区的头部),如果数据很快被访问,那么page就会向new列表头部移动,如果数据没有被访问,会逐步向old尾部移动,等待淘汰。

冷数据区的数据页什么时候会被转到到热数据区呢 ?
- 如果该数据页在LRU链表中存在时间超过1s,就将其移动到链表头部 ( 链表指的是整个LRU链表)
- 如果该数据页在LRU链表中存在的时间短于1s,其位置不变(由于全表扫描有一个特点,就是它对某个页的频繁访问总耗时会很短)
- 1s这个时间是由参数
innodb_old_blocks_time控制的
InnoDB三大特性
自适应哈希索引(Adaptive Hash Index)
当一个数据频繁的搜索时,将为其创建hash
那什么情况下才会使用自适应Hash索引呢?如果某个数据经常会访问到,当满足一定条件的时候,就会将这个数据页的地址存放到Hash表中。这样下次查询的时候,就可以直接找到这个页面的所在位置。
需要说明的是:
1)自适应哈希索引只保存热数据(经常被使用到的数据),并非全表数据。因此数据量并不会很大,可以让自适应Hash放到缓冲池中,也就是InnoDB buffer pool,进一步提升查找效率。
2)InnoDB中的自适应Hash相当于是“索引的索引”,采用Hash索引存储的是B+树索引中的页面的地址。这也就是为什么可以称自适应Hash为索引的索引。 采用自适应Hash索引目的是可以根据SQL的查询条件加速定位到叶子节点,特别是当B+树比较深的时候,通过自适应Hash索引可以提高数据的检索效率。
3)自适应Hash采用Hash函数映射到一个哈希表中,所以对于字典类型的数据查找非常方便 哈希表是数组+链表的形式。通过Hash函数可以计算索引键值所对应的bucket(桶)的位置,如果产生Hash冲突,如果产生哈希冲突,就需要遍历链表来解决。
4)是否开启了自适应Hash,可以通过innodb_adaptive_hash_index变量来查看,比如:mysql> show variables like '%adaptive_hash_index'; 所以,总结下InnoDB本身不支持Hash,但是提供自适应Hash索引,不需要用户来操作,而是存储引擎自动完成的。
插入缓存(insert buffer) 或写缓存(Change Buffer)
因为要减少磁盘IO,所以加入Buffer Pool,
InnoDB使用了一种缓冲池的技术,也就是把磁盘读到的页放到一块内存区域里面。这个内存区域就叫Buffer Pool。
缓冲的加入一般都是内存和磁盘的处理速度不匹配
思考一个问题:当需要更新一个数据页时,如果数据页在Buffe rPool中存在,那么就直接更新好了。否则的话就需要从磁盘加载到内存,再对内存的数据页进行操作。也就是说,如果没有命中缓冲池,至少要产生一次磁盘IO,有没有优化的方式呢?向下看…
对于非唯一索引,因为其不要把索引页调入内存,进行唯一性检查
所以可以先写到insert buffer中,
当其数据页调入到内存中,再进行合并数据,merge操作
Change Buffer 默认占 Buffer Pool的25%
两次写(double write)
Mysql数据页大小是16K,操作系统的页大小为4K(1K)
要刷脏页的时候,
先写到共享表空间,顺序的
再写到各自的独立表空间,分散的
Mysql8.0索引新特性
第08章 索引的创建与设计原则【2.索引及调优篇】【MySQL高级】:2. Mysql8.0索引新特性
支持降序索引
CREATE TABLE ts1(a int,b int,index idx_a_b(a asc,b desc));
支持隐藏索引
为了避免删除索引之后,又想加回来
所有有了隐藏索引
先隐藏索引,之后看起影响,考虑是否删除索引
1.创建表时直接创建
CREATE TABLE tablename(
propname1 type1[CONSTRAINT1],
propname2 type2[CONSTRAINT2],
……
propnamen typen,
INDEX [indexname](propname1 [(length)]) INVISIBLE
);
2.在已有表上创建
CREATE INDEX indexname
ON tablename(propname[(length)]) INVISIBLE;
3.修改ALTER TABLE语句创建
ALTER TABLE tablename
ADD INDEX indexname (propname [(length)]) INVISIBLE;
4.切换可视状态:
ALTER TABLE tablename ALTER INDEX index_name INVISIBLE; #切换成隐藏索引
ALTER TABLE tablename ALTER INDEX index_name VISIBLE; #切换成非隐藏索引
5.使隐藏索引对查询优化器可见
set session optimizer_switch="use_invisible_indexes=on";
set session optimizer_switch="use_invisible_indexes=off";
数据库服务器优化步骤
第09章 性能分析工具的使用【2.索引及调优篇】【MySQL高级】
SQL调优的三个步骤:慢查询、EXPLAIN和SHOW PROFILING
1.优化步骤

2.查询系统参数
3.查询执行成本 last_query_cost,单位是需要查询的页的数量
4.定位执行慢的 SQL:慢查询日志 long_query_time
4.1开启慢查询日志参数
1.开启slow_query_log
set global slow_query_log='ON';
再来查看下慢查询日志是否开启,以及慢查询日志文件的位置:
show variables like '%slow_query_log_file';
如果不指定存储路径,慢查询日志将默认存储到MySQL数据库的数据文件夹下。如果不指定文件名,默认文件名为hostname-slow.log
2.修改long_query_time阈值
set global long_query_time = 1;
4.2 查看慢查询数目
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
有多少条
补充:是否慢查询sql还有个参数
min_examined_row_limit(查询扫描过的最少记录数),默认是0
4.5 慢查询日志分析工具:mysqldumpslow
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
4.6 关闭慢查询日志
4.7 删除慢查询日志
5.查看 SQL 执行成本:SHOW PROFILE
6.分析查询语句:EXPLAIN
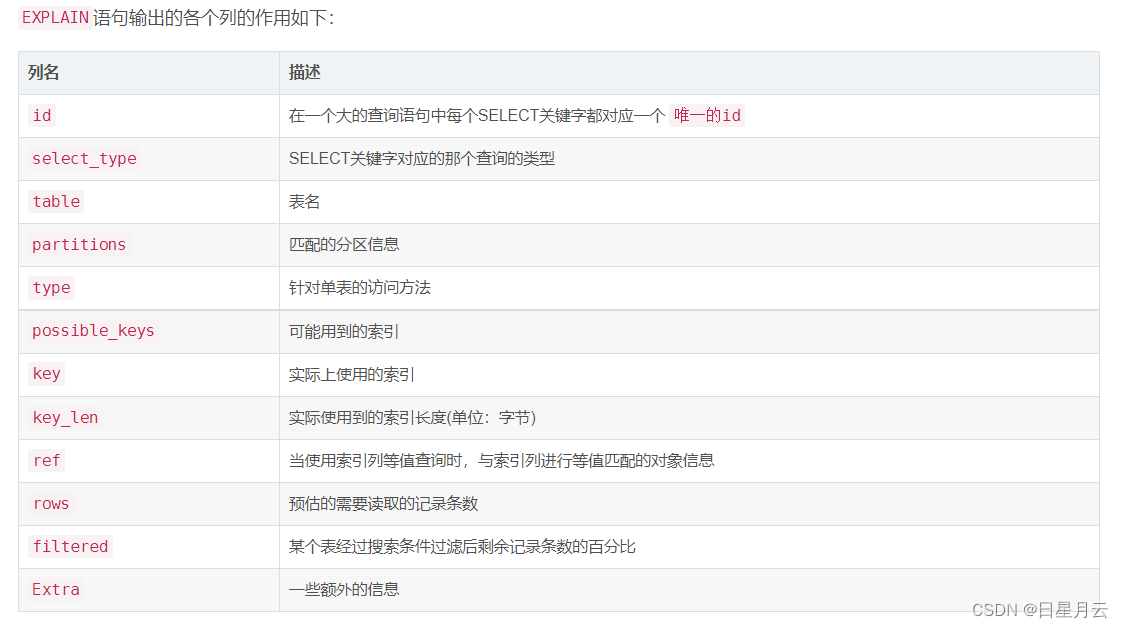
8. 分析优化器执行计划:trace
select * from information_schema.optimizer_trace\G
9.MySQL监控分析视图-sys schema
索引优化
防止索引失效
全值匹配
最左前缀法则
索引覆盖
索引条件下推
锁
间隙锁加锁规则(共11个案例)
间隙锁是在可重复读隔离级别下才会生效的: next-key lock 实际上是由间隙锁加行锁实现的,如果切换到读提交隔离级别 (read-committed) 的话,就好理解了,过程中去掉间隙锁的部分,也就是只剩下行锁的部分。而在读提交隔离级别下间隙锁就没有了,为了解决可能出现的数据和日志不一致问题,需要把binlog 格式设置为 row 。也就是说,许多公司的配置为:读提交隔离级别加 binlog_format=row。业务不需要可重复读的保证,这样考虑到读提交下操作数据的锁范围更小(没有间隙锁),这个选择是合理的。
next-key lock的加锁规则
总结的加锁规则里面,包含了两个 “ “ 原则 ” ” 、两个 “ “ 优化 ” ” 和一个 “bug” 。
- 原则 1 :加锁的基本单位是 next-key lock 。 next-key lock 是前开后闭区间。
- 原则 2 :查找过程中访问到的对象才会加锁。任何辅助索引上的锁,或者非索引列上的锁,最终都要回溯到主键上,在主键上也要加一把锁。
- 优化 1 :索引上的等值查询,给唯一索引加锁的时候, next-key lock 退化为行锁。也就是说如果InnoDB扫描的是一个主键、或是一个唯一索引的话,那InnoDB只会采用行锁方式来加锁
- 优化 2 :索引上(不一定是唯一索引)的等值查询,向右遍历时且最后一个值不满足等值条件的时候, next-keylock 退化为间隙锁。
- 一个 bug :唯一索引上的范围查询会访问到不满足条件的第一个值为止。
再谈二进制日志(binlog)
第17章 其他数据库日志:6. 再谈二进制日志(binlog)
两阶段提交
为了解决两份日志之间的逻辑一致问题,InnoDB存储引擎使用两阶段提交方案。原理很简单,将redo log的写入拆成了两个步骤prepare和commit,这就是两阶段提交。

还有缓存与数据库的一致性
mq订阅binlog
主从复制
2.1 原理剖析
三个线程
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程 来操作,一个主库线程,两个从库线程。

二进制日志转储线程 (Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上 加锁 ,读取完成之后,再将锁释放掉。–>二进制日志转储线程负责将数据发送出去。
从库 I/O 线程 会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程 会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
Mysql8的新特性
第01章 Linux下MySQL的安装与使用:3.登录:3.3 设置远程登录:4. Linux下修改配置
对密码进行加密
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
第05章 存储引擎:4. 引擎介绍:4.1 InnoDB 引擎:具备外键支持功能的事务存储引擎
默认的InnoDB存储引擎:支持事务,行锁,外键
第08章 索引的创建与设计原则:2. Mysql8.0索引新特性
降序索引和隐藏索引
第10章 索引优化与查询优化:10. 索引下推:10.1 使用前后的对比
Index Condition Pushdown(ICP)是MySQL 5.6中新特性,
是一种在存储引擎层使用索引过滤数据的一种优化方式。
第12章 数据库其它调优策略:5. 其它调优策略:5.3 MySQL 8.0新特性:隐藏索引对调优的帮助
隐藏索引对调优的帮助
第15章 锁:3. 锁的不同角度分类:3.1从数据操作的类型划分:读锁、写锁:1.锁定读
MySQL8.0新特性:
在5.7及之前的版本,SELECT …FOR UPDATE,如果获取不到锁,
会一直等待,直到`innodb_lock_wait_timeout`超时。
在8.0版本中,在SELECT …FOR UPDATE,SELECT …FOR SHARE后
添加`NOWAIT`、`SKIP LOCKED`语法,跳过锁等待,或者跳过锁定。
- 通过添加NOWAIT、SKIP LOCKED语法,能够立即返回。如果查询的行已经加锁:
- 那么NOWAIT会立即报错返回
- 而SKIP LOCKED也会立即返回,只是返回的结果中不包含被锁定的行。
第17章 其他数据库日志:4. 错误日志(error log):4.4 MySQL8.0新特性
错误日志的改进
Redis
redis为什么快
1.纯内存KV操作
Redis的操作都是基于内存的,CPU不是 Redis性能瓶颈,,Redis的瓶颈是机器内存和网络带宽。
在计算机的世界中,CPU的速度是远大于内存的速度的,同时内存的速度也是远大于硬盘的速度。redis的操作都是基于内存的,绝大部分请求是纯粹的内存操作,非常迅速。
2.单线程操作
使用单线程可以省去多线程时CPU上下文会切换的时间,也不用去考虑各种锁的问题,不存在加锁释放锁操作,没有死锁问题导致的性能消耗。对于内存系统来说,多次读写都是在一个CPU上,没有上下文切换效率就是最高的!既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章的采用单线程的方案了
Redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块该使用多线程,仍会使用了多个线程。
3.I/O 多路复用
为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的
4.Reactor 设计模式
Redis基于Reactor模式开发了自己的网络事件处理器,称之为文件事件处理器(File Event Hanlder)。
自己补充:
高效的操作:渐进式rehash、缓存时间戳
KV键-全局hash表 两张哈希表
把一次性大量拷贝的开销,分摊到了多次处理请求的过程中
计算机组成原理的DARM的刷新操作:集中 分步 异步
使用系统时间戳的时候,要使用系统调用获取系统的毫秒时间戳
每一次都是系统调用,有CPU的上下文切换。redis由一个定时任务,每毫米更新一次时间缓存的,获取时间都是从缓存中直接拿。
什么是bigkey?会有什么影响?
bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value可以最大存到512MB,一个列表类型的value最多可以存储23-1个元素。
如果按照数据结构来细分的话,一般分为字符串类型bigkey和非字符串类型bigkey。
字符串类型:体现在单个value值很大,一般认为超过10KB就是bigkey,但这个值和具体的OPS相关。
非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。
bigkey无论是空间复杂度和时间复杂度都不太友好,下面我们将介绍它的危害。
bigkey的危害
bigkey的危害体现在三个方面:
1、内存空间不均匀.(平衡):例如在Redis Cluster中,bigkey 会造成节点的内存空间使用不均匀。
2、超时阻塞:由于Redis单线程的特性,操作bigkey比较耗时,也就意味着阻塞Redis可能性增大。
3、网络拥塞:每次获取bigkey产生的网络流量较大
假设一个bigkey为1MB,每秒访问量为1000,那么每秒产生1000MB 的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例造成影响,其后果不堪设想。
Redis的数据结构
string
list
hash
set
zset
hash的渐进式resize
zset的使用
redis中的zset
2023/7/28 16:37:28
Redis中的ZSet(有序集合)是一种特殊的数据结构,它是一种有序的字符串集合。每个成员都与一个分数(score)相关联,该分数用于对成员进行排序。在ZSet中,成员是唯一的,但是分数可以重复。
ZSet的主要特点是可以高效地插入、删除和查找成员,同时可以根据分数范围或成员来进行范围查找和排名操作。这使得ZSet在许多应用场景下非常有用,例如排行榜、计数器、优先级队列等。
常见的ZSet操作包括:
ZADD:向有序集合中添加一个成员及其对应的分数。
ZREM:从有序集合中删除一个成员。
ZSCORE:获取成员的分数。
ZRANK:获取成员在有序集合中的排名(按分数从低到高)。
ZREVRANK:获取成员在有序集合中的排名(按分数从高到低)。
ZRANGE:根据分数范围获取有序集合中的成员列表(按分数从低到高)。
ZREVRANGE:根据分数范围获取有序集合中的成员列表(按分数从高到低)。
下面是一个使用Redis的CLI(命令行界面)示例,演示如何创建和操作一个ZSet:
# 添加成员及其分数到有序集合"my_zset"
127.0.0.1:6379> ZADD my_zset 90 "Alice"
(integer) 1
127.0.0.1:6379> ZADD my_zset 85 "Bob"
(integer) 1
127.0.0.1:6379> ZADD my_zset 95 "Charlie"
(integer) 1
# 获取成员的分数
127.0.0.1:6379> ZSCORE my_zset "Alice"
"90.0"
# 获取成员在有序集合中的排名(按分数从低到高)
127.0.0.1:6379> ZRANK my_zset "Charlie"
(integer) 2
# 获取成员在有序集合中的排名(按分数从高到低)
127.0.0.1:6379> ZREVRANK my_zset "Bob"
(integer) 1
# 根据分数范围获取有序集合中的成员列表(按分数从低到高)
127.0.0.1:6379> ZRANGE my_zset 0 -1
1) "Bob"
2) "Alice"
3) "Charlie"
请注意,以上示例中使用的是默认情况下的升序排序。如果你想要降序排序,则可以使用ZREVRANGE等命令。
ZSet在Redis中是一个非常强大的数据结构,允许你进行高效的有序数据存储和检索。
zset为什么使用跳表
2023/7/28 16:38:44
ZSet在Redis中使用跳表(Skip List)的数据结构是因为跳表在有序集合这种场景下具有很好的性能特性。
跳表是一种随机化数据结构,它是有序链表的扩展,通过添加多级索引(跳跃)来提高查询效率。跳表允许在O(log n)的时间复杂度内进行插入、删除和查找操作,其中n是跳表中元素的数量。
对于有序集合(ZSet),要求元素按照分数进行排序,同时又需要高效地进行插入和删除操作。在这种情况下,传统的数据结构如红黑树虽然能够满足有序性的要求,但插入和删除操作的时间复杂度是O(log n),不如跳表高效。
跳表的优点包括:
查询高效:跳表允许通过多级索引快速定位元素,使得查询的时间复杂度较低。
插入和删除高效:跳表对插入和删除操作进行随机化优化,平均情况下时间复杂度为O(log n)。
简单易实现:相对于平衡二叉树等复杂数据结构,跳表的实现相对简单。
Redis中的ZSet使用跳表的结构来满足上述需求,使得ZSet在插入、删除和范围查询等操作上具有较高的性能。然而,值得注意的是,跳表也会带来一定的额外空间开销,因为它需要维护多级索引,但在Redis这种内存数据库中,通常更注重性能而不是空间的绝对节省。因此,跳表是Redis中实现有序集合的一个理想选择。
redis的事务
https://blog.csdn.net/Severn_Zhou/article/details/95235667
Redis的事务是一种将多个命令打包执行的机制,它允许一系列的命令按照顺序依次执行,同时保证这些命令在执行过程中不会被其他客户端的命令所中断。事务在Redis中通过MULTI、EXEC、WATCH、DISCARD等命令来实现。
以下是事务执行的基本过程:
- MULTI:在事务开始前,使用MULTI命令来标记事务的开始。
- 依次执行多个命令:在MULTI和EXEC之间,可以依次执行多个Redis命令,这些命令会被放入一个队列中,而不是立即执行。
- EXEC:执行EXEC命令来执行之前放入队列中的所有命令。Redis会依次执行队列中的命令,如果在执行过程中没有发生错误,那么所有命令都会被执行成功。否则,如果出现错误,比如其中一个命令失败,那么整个事务将会回滚,之前执行的命令都不会生效。
- WATCH:使用WATCH命令可以监视一个或多个键,如果在事务执行之前有其他客户端对这些键进行了修改,事务将会被中断。这可以用于乐观锁机制,保证事务的原子性。
- DISCARD:在事务执行之前,使用DISCARD命令可以取消当前事务,清空事务队列中的所有命令。
事务的特点:
- 事务保证了一系列命令的原子性,要么全部执行成功,要么全部不执行。
- 事务的执行是单线程的,不会被其他客户端的操作中断。
- 事务不支持回滚点,一旦执行EXEC,整个事务会被执行,无法在执行过程中中途取消或回滚。
需要注意的是,虽然事务提供了原子性,但是在并发写入的情况下,使用WATCH命令时要小心竞态条件(race condition)。WATCH可以用于乐观锁控制,但是在实际使用中要根据具体场景谨慎使用,以避免潜在的问题。
另外,Redis的事务是一种逻辑上的事务,并非传统数据库中的ACID事务。在Redis中,没有像ROLLBACK这样的回滚操作,因为事务不会中途取消或回滚。事务更多地用于将多个命令打包执行,保证一系列操作的原子性。
使用redis如何设计分布式锁?
基于 Redis 实现的分布式锁,一个严谨的的流程如下:
1、加锁
SET lock_key $unique_id EX $expire_time NX
2、操作共享资源
3、释放锁:Lua 脚本,先 GET 判断锁是否归属自己,再DEL 释放锁
redis的持久化
Redis支持两种方式的持久化,分别是RDB(Redis Database File)和AOF(Append-Only File)。
RDB持久化: RDB持久化是将Redis在某个时间点上的数据快照(snapshot)保存到磁盘上的持久化方式。这个快照包含了Redis在生成快照时刻的所有数据,是一个二进制文件。RDB持久化适用于备份和数据恢复的场景。
RDB持久化的优点:
- 对于数据恢复来说,RDB文件较小,加载速度较快。
- RDB持久化是生成全量备份,适合用于灾难恢复。
RDB持久化的缺点:
- 如果Redis意外宕机,会丢失最后一次快照之后的所有数据。
- 生成快照时,Redis可能会阻塞客户端请求。
AOF持久化: AOF持久化是通过记录Redis服务器所执行的写命令来保证数据的持久性。AOF文件是一个追加写入的日志文件,它包含了Redis服务器执行的所有写操作指令。当Redis重启时,会重新执行AOF文件中的指令,从而将数据还原到原来的状态。
AOF持久化的优点:
AOF文件是一个追加写入的日志文件,不会导致像RDB那样的阻塞现象。
AOF持久化相对于RDB来说,数据丢失的风险更小,因为AOF记录的是每个写操作,所以在故障发生时,最多只会丢失最后一条写指令之后的数据。
AOF文件以纯文本方式记录,易于阅读和理解。
AOF持久化的缺点:
- AOF文件通常比RDB文件大,因为它记录了每个写操作指令。
- AOF文件的恢复速度可能比RDB慢,特别是当AOF文件很大时。
在Redis中,可以同时启用RDB和AOF持久化,以提供更高的数据安全性。也可以根据实际需求选择只启用其中一种持久化方式。同时,还可以根据配置选项来控制持久化的频率和策略,以平衡性能和数据持久化的要求。
如何保证缓存与数据库双写时的数据一致性
第一种方案:采用延时双删策略
具体的步骤就是:
先删除缓存;
再写数据库;
休眠500毫秒;
再次删除缓存。
第二种方案:异步更新缓存(基于订阅binlog的同步机制)
技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
Redis常见性能问题和解决方案有哪些?
一、缓存穿透:就是查询一个压根就不存在的数据,即缓存中没有,数据库中也没有
解决方案:使用布隆过滤器,把数据先加载到布隆过滤器中,访问前先判断是否存在于布隆过滤器中,不存在代表这笔数据压根就不存在。
缺点:布隆过滤器是不可变的,可能一开始过滤器和数据库数据时一致的,后面数据库数据变了,或变多或变少,而对应的布隆过滤器的数据也要改变,这时会比较麻烦。
二、缓存击穿:数据库中有,缓存中没有。缓存击穿实际就是一个并发问题,一般来说查询数据,先查询缓存,有直接返回,没有再查询数据库并放到缓存中之后返回,但这种场景在并发情况下就会有问题,假设同时又100个请求执行上面
逻辑的代码,则可能会出现多个请求都查询数据库,因为大家同时执行,都查到了缓存中没有数据。
解决方案:加锁。如果是单机部署,则可以使用JVM级别的锁,如lock、synchronized。如果是集群部署,则需要使用分布式锁,如基于redis、zookeeper、mysql等实现的分布式锁。
三、缓存雪崩:大部分数据同时失效、过期,新的缓存又没来,导致大量的请求都去访问数据库而导致的服务器压力过大、宕机、系统崩溃。
解决方案:搭建高可用的redis集群,避免压力集中于一个节点;缓存失效时间错开,避免缓存同时失效而都去请求数据库。
Redis过期策略都有哪些?LRU算法知道吗?
1.noeviction:返回错误当内存限制达到,并且客户端尝试执行会让更多内存被使用的命令。
2.allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
3.volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
4.allkeys-random: 回收随机的键使得新添加的数据有空间存放。
5.volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
6.volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
redis的集群
redis的主从复制
slaveof 127.0.0.1 6379
info replication
slaveof no one
redis的哨兵模式
sentinel monitor myredis 127.0.0.1 6379 1
Spring
IOC
控制反转(IoC)是Spring的核心思想之一,它的主要作用是将对象的创建过程交给Spring容器来完成,这样可以更加灵活地管理和组装对象,降低了组件之间的耦合度。
AOP
AOP则是另一个核心思想,它主要是通过在程序运行过程中动态地横向切入特定方法来实现对应用程序的功能增强,例如日志记录、事务处理等。
循环依赖
首先我们要明确一点就是如果这个对象A还没创建成功,在创建的过程中要依赖另一个对象B,而另一个对象B也是在创建中要依赖对象A,这种肯定是无解的,这时我们就要转换思路,我们先把A创建出来,但是还没有完成初始化操作,也就是这是一个半成品的对象,然后在赋值的时候先把A暴露出来,然后创建B,让B创建完成后找到暴露的A完成整体的实例化,这时再把B交给A完成A的后续操作,从而揭开了循环依赖的密码。也就是如下图:
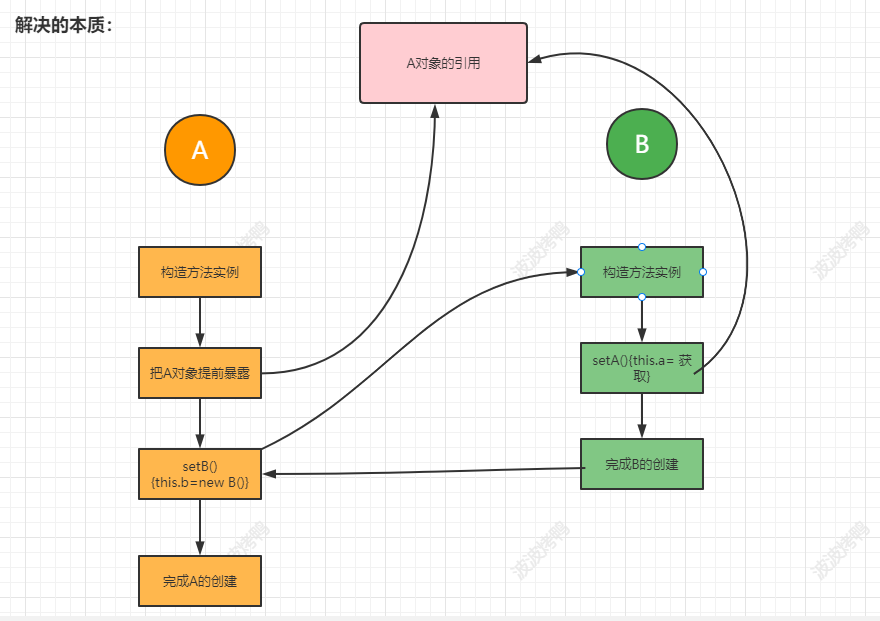
springboot如果要对属性文件中的账号密码加密如何实现?
SpringBoot的优点
Spring Boot 优点非常多,如:
一、独立运行
Spring Boot而且内嵌了各种servlet容器,Tomcat、Jetty等,现在不再需要打成war包部署到容器
中,Spring Boot只要打成一个可执行的jar包就能独立运行,所有的依赖包都在一个jar包内。
二、简化配置
spring-boot-starter-web启动器自动依赖其他组件,简少了maven的配置。
三、自动配置
Spring Boot能根据当前类路径下的类、jar包来自动配置bean,如添加一个spring-boot-starter
web启动器就能拥有web的功能,无需其他配置。
四、无代码生成和XML配置
Spring Boot配置过程中无代码生成,也无需XML配置文件就能完成所有配置工作,这一切都是借助
于条件注解完成的,这也是Spring4.x的核心功能之一。
五、应用监控
Spring Boot提供一系列端点可以监控服务及应用,做健康检测
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
● @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
● @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,
如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
● @ComponentScan:Spring组件扫描
最后
我们都有光明的未来
祝大家考研上岸
祝大家工作顺利
祝大家得偿所愿
祝大家如愿以偿
点赞收藏关注哦