1. 论文信息
FedASMU: Efficient Asynchronous Federated Learning with Dynamic Staleness-Aware Model Update,Proceedings of the AAAI Conference on Artificial Intelligence,2024-03-24(23年10月挂在 arXiv),ccfa
2. introduction
2.1. 背景:FL 训练中存在 统计异质性(non-IID) 与 系统异质性(计算与通信能力差异) 问题
2.2. 解决的问题:
- non-IID 数据-> 将最新的全局模型整合到局部模型进行知识共享-> 聚合的时间点需要权衡(
- 如果请求发送得太早,服务器可能只进行了少量更新,导致最终更新的本地模型仍然过时,影响性能。
- 如果请求发送得太晚,本地更新可能无法充分利用最新全局模型的信息,导致准确性下降。
) -> 考虑(历史数据和当前的模型状态),利用 RL 实现申请全局模型的最佳时间点的选择 -> 提升模型的准确率,减少训练时间
- 系统异构 -> 模型陈旧 -> 动态调整聚合时的模型权重(
- 本地模型聚合时最新全局模型的权重 (考虑全局模型的过时程度、本地模型的损失大小)
- 全局模型聚合时本地设备的权重(考虑本地模型的过时程度、全局模型的损失大小)
) -> 提升模型的准确率,减少训练时间
3. 问题描述:
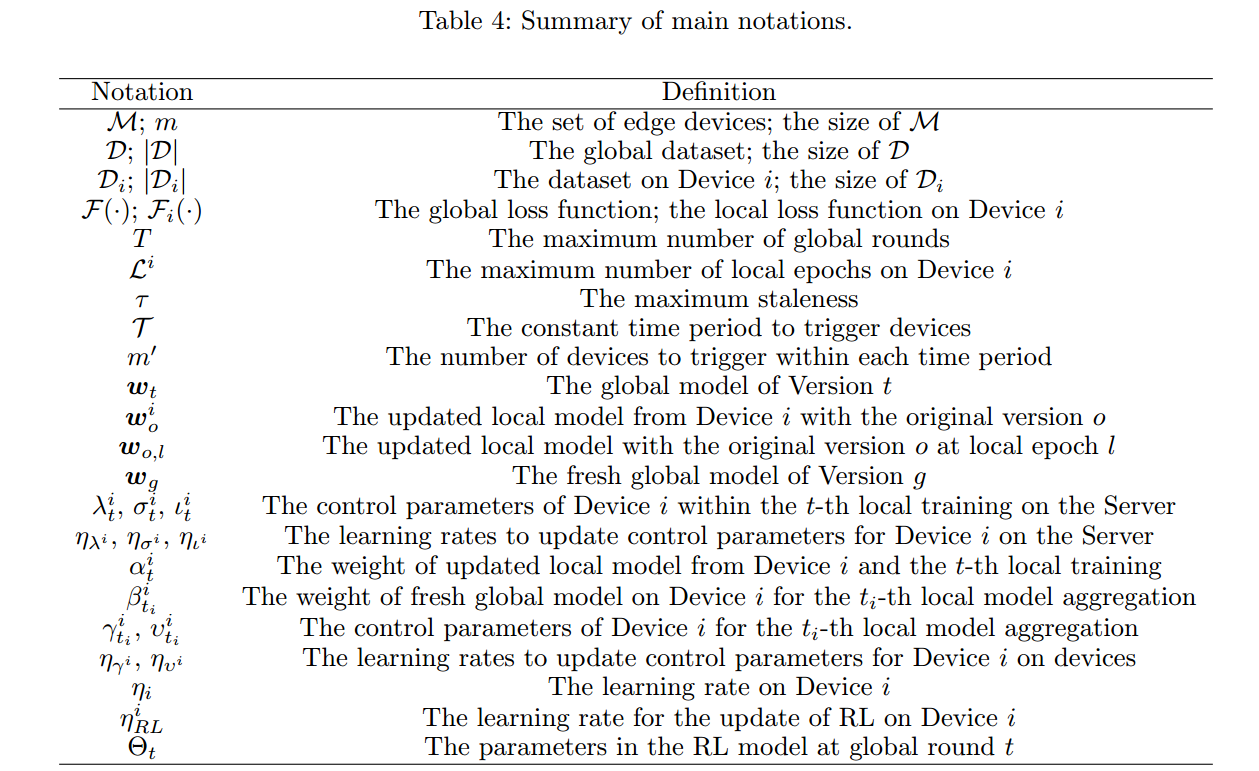
3.1. 对问题的形式化描述

最小化所有设备上本地损失函数 Fi(w) 平均值,得到最优的全局模型w
3.2. System model
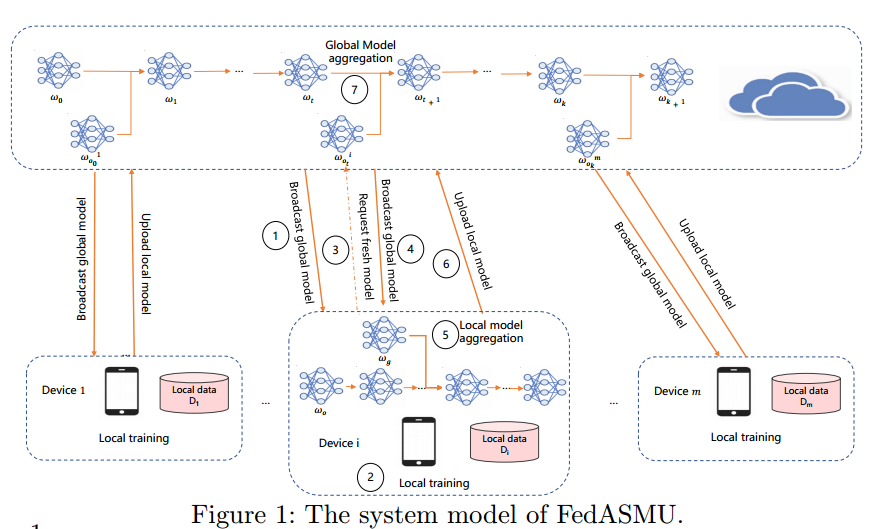
Server 以恒定的时间周期 T 触发 m 个设备进行局部训练。初始的全局模型版本为 0 ,在每个全局轮次完成之后,版本加 1:
- Server 随机选择 m' (m’≤ m )个可用设备,向选定的设备广播全局模型
- 在 m' 个设备上利用本地数据集进行训练
- 设备进行本地训练的同时,全局模型可能进行更新,为了减少模型陈旧度,设备 i 向Server 请求新的全局模型
- 如果wg 比wo 新的话( g > o ),就广播新的全局模型
- 设备接到新的全局模型后,将全局模型和最新的本地模型聚合为一个新模型,并继续使用新模型进行局部训练。
- 本地训练完成,设备 i 将本地模型上传到 Server
- Server 将本地模型 wio 和最新的全局模型 wt 聚合为新的模型,其中涉及 陈旧度 Ti= t-o+1,当陈旧度达到设定的阈值就舍弃上传的本地模型
4. 解决方法
4.1. 动态更新全局模型(步骤 7)
将
问题拆解成双层优化问题:
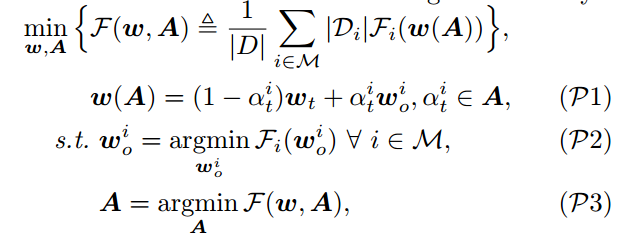
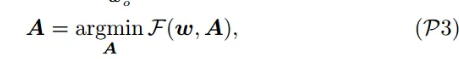
全局优化目标:通过动态调整每个客户端上传模型的重要性权重,找到一组能够使全局损失函数 𝐹(𝑤,𝐴) 最小化的权重集合
![]()

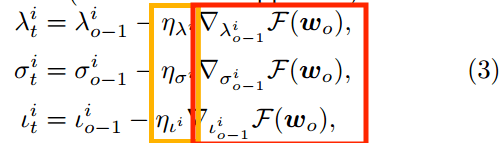
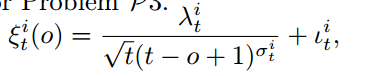

控制每个客户端在联邦学习中的模型更新对全局模型更新的贡献度:
- 考虑客户端模型的过时程度,如果客户端上传模型较为陈旧,在聚合时具有更低的权重,减少陈旧性带来的影响
- 考虑全局模型的损失大小(
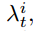
),如果全局模型在当前状态下损失较大,需要更多地客户端模型的信息来改进
![]()
4.2. 动态更新本地模型(步骤 3、5)

最小化本地损失函数
![]()
迭代
![]()
次可实现
o 为全局模型的版本,l 为局部 epoch 个数,ηi 为设备 i 上的学习率,∇Fi(·) 为基于 Di 中无偏采样的小批 ζl−1 的梯度
关键:确定 发送请求的时隙
![]()
4.2.1. RL 实现最佳时隙选择
确定 发送请求的时隙
- 当请求提前发送时,服务器执行的更新很少,最终更新的本地模型可能仍然严重过时
- 当请求发送较晚时,本地更新无法利用新的全局模型,准确性较低
The intelligent time slot selector 由 Server 的 元模型 和 每个设备上的本地模型 组成,元模型为每个设备生成初始时隙决策,并在设备执行第一次局部训练时更新。本地模型使用初始时隙完成初始化,并在随后的局部训练期间在设备内进行更新,为新的全局模型请求生成个性化的适当时隙。利用基于长短期记忆(LSTM)的网络,为元模型提供一个完全连接层,并为每个本地模型使用 q -学习方法。
元模型和局部模型都会生成每个时隙的概率。利用ϵ-greedy策略进行选择。

状态:推测可能包括本地模型的当前参数(模型、版本信息)、本地损失、训练时间、其他可能影响聚合效果的因素(控制参数
![]()
)
R 奖励:本地设备模型与新的全局模型聚合前后的损失值之差,如果 R 为正数,说明新的全局模型对模型性能有正面影响
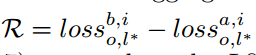
策略:
- 初始的时隙由
进行选择
θt 元模型更新:
表示元模型第 t 次更新后元模型中的参数,ηRL表示 RL 训练过程的学习率,L 表示本地 epoch 的最大次数,∫L 对应第 L 个本地 epoch 后发送请求(1) 或 不发送请求(0) 的决定,bt 是减少模型偏差的基值
- 后续的时隙由
选择
Hi 本地模型更新:历史值和奖励的加权平均值
动作空间:ati−1 ∈ {add, stay, minus},
add
stay
应该是保持不变
,推测是写错了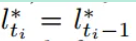
minus
目标:最大化奖励函数 R,R 越大说明新的全局模型对本地模型性能的提升越高
4.2.2. 动态更新本地模型权重
确定本地模型聚合时新全局模型的权重


![]()
将当前的局部模型 𝑤𝑏 与最新全局模型 𝑤𝑔 进行聚合
- 考虑全局模型的过时程度,如果全局模型陈旧度高,在聚合时具有更低的权重,减少陈旧性带来的影响
- 考虑本地模型的损失大小,如果局部模型在当前状态下损失较大,需要更多地全局模型的信息来改进

![]()
5. 效果:
5.1. 实验设置
取 1 个 Server 和 100 个设备
9种 sota

5个 公共数据集
6个 模型
5.2. 对比实验
考虑别的指标,计算、通信量
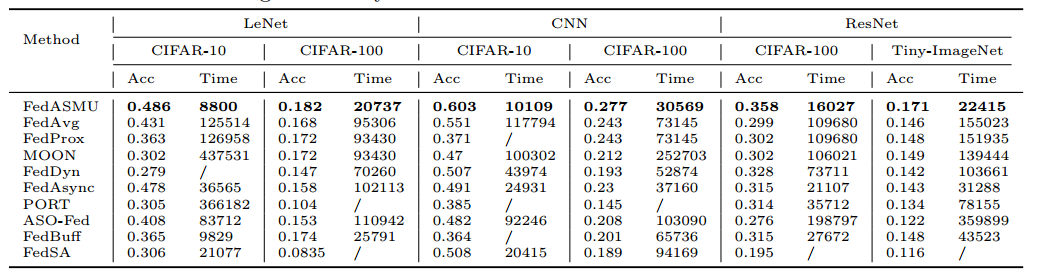

FedASMU始终对应着最高的收敛精度和训练速度。
- FedASMU的精度优势:服务器和设备上的模型聚合过程中权值的动态调整
- 训练速度快:异步机制、局部训练过程中局部模型和最新全局模型的聚合
FedASMU的额外通信开销主要体现在:从服务器到设备的下行通道中下载全局模型的过程。由于下行通道具有高带宽,因此会产生可接受的额外成本,但会带来显著的好处(更高的精度和更短的训练时间)。
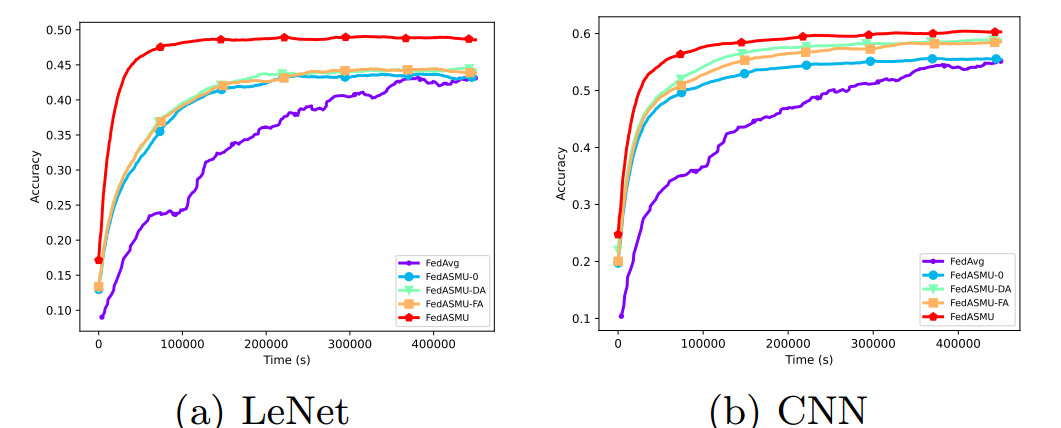
FedASMU 有最高的收敛精度和最快的训练速度
5.3. 超参数确定实验
超参对实验结果的影响不大,很容易进行微调
5.4. 智能时隙选择器消融实验
- H1:设备在第一个本地历元之后发送请求
- H2:设备在训练中间阶段发送请求
- H3:设备在最后一个本地历元发送请求
RL方法的准确率显著高于H1(2.4%)、H2(2.2%)和H3(2.8%)。
6. (备选)自己的思考
论文对你的启发,包括但不限于解决某个问题的技术、该论文方法的优缺点、实验设计、源码积累等。
- AAAI 的文章是属于已有的角度深耕
6.1. 元学习模型是先训练好直接拿到 FL 训练中使用,还是在 FL 训练中进行训练
FedASMU 框架中的模型是在 FL 过程中进行训练和更新的,而不是在 FL 过程之前就已经完全训练好。模型利用历史数据进行预训练,预训练提供了一个起点,但模型的优化和调整是在整个FL过程中不断进行的。
7. 师姐问题
7.1. 这篇论文的通信量和计算量
考虑增加额外的通信开销:本地设备向服务器下载最新的全局模型
计算代价:
- 本地设备:本地模型损失、控制参数的更新、全局模型的权重、本地模型
- 服务器:全局模型损失、控制参数的更新、本地模型的权重、全局模型
7.2. 如果所有用户都在训练的时候请求新的全局模型,是不是和在指定轮次强制同步全局模型是一个效果?而且还没有用户本地的计算量
同步更新要求所有用户在特定时间点统一更新,可能会导致服务器负载高峰和通信瓶颈
自适应请求允许用户根据自己的训练进度和数据特性来选择更新时机,减少不必要的通信和计算量。但如果所有用户都在训练的时候请求新的全局模型,如果是同时申请,这样的状况,本文相当于只在本地聚合时多加了按权分配的策略,缓解了模型陈旧。
用户根据自己的训练进度和数据特性来选择更新时机是本文的一个创新点
7.3. 丰富思维导图
主要思路是
- 问题列的尽量细致(个人感觉可以参考背景)
- 厘清问题和现象
- 按照文章最终的效果去再捋一个思维导图(个人想法,抽空整理)