1. 为什么要做多数据中心(Multi-DC)
- 就近访问、降低时延:应用只连本地 Kafka,避免跨地域 RTT。
- 站点自治:专线/公网抖动时,本地业务不受影响,跨 DC 镜像“落后但可追”。
- 集中治理跨 DC 复制:把跨站复制的带宽、限速、话题过滤统一到镜像层治理。
2. 推荐拓扑:每个 DC 一个本地集群 + 跨 DC 镜像
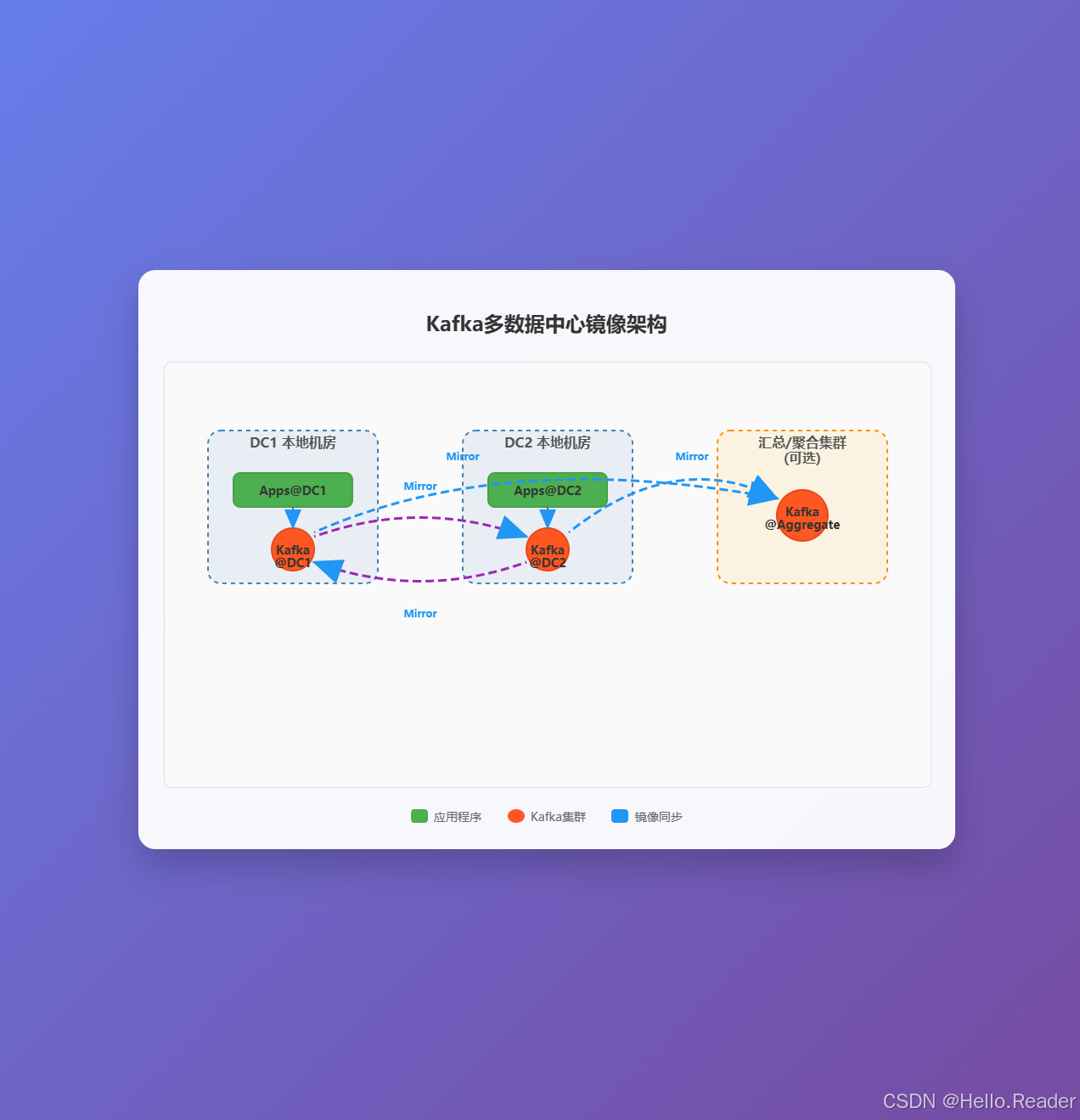
- 本地读写本地集群(K1/K2)。
- 镜像(Mirroring)在后台异步复制,链路断开时落后,恢复后追赶。
- 汇总集群(Aggregate,选):把各地数据聚合用于全量只读(报表、离线分析)。
非推荐:单个 Kafka 集群跨多 DC。高延迟链路会显著拉高复制时延、放大不可用面。
3. 什么时候需要“汇总集群(Aggregate)”
- 需要全局视图(跨 DC 的完整数据集)且读取为主。
- BI/OLAP/离线特征生成、全局风控/画像等。
- 按业务域拆多个汇总集群,避免一个“超级聚合集群”成为瓶颈。
4. 备选模式对比
| 模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| A. 本地集群 + 双向镜像(推荐) | 低时延、本地自治、断链可运行 | 最终一致、镜像治理复杂度 | 主交易链路、敏捷扩展 |
| B. 直接跨 WAN 读写远端集群 | 架构简单 | 受 RTT 影响大,抖动放大 | 小流量、短期联调 |
| C. 单集群跨 DC(不建议) | 统一管控 | 高复制时延、可用性脆弱 | 仅限低延迟专线、极少数特例 |
5. 跨 DC 镜像的落地配置(MirrorMaker 2 / Kafka Connect)
5.1 基本属性(mm2.properties 示例)
# 集群别名(用于路由与规则)
clusters = dc1, dc2, agg
# 各集群 bootstrap
dc1.bootstrap.servers=dc1-kafka-1:9092,dc1-kafka-2:9092
dc2.bootstrap.servers=dc2-kafka-1:9092,dc2-kafka-2:9092
agg.bootstrap.servers=agg-kafka-1:9092,agg-kafka-2:9092
# 认证/加密(如需)
# dc1.security.protocol=SASL_SSL
# dc1.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required ...
# dc1.sasl.mechanism=SCRAM-SHA-512
# 复制策略:保留源主题名(默认),或自定义加前缀
replication.policy.class=org.apache.kafka.connect.mirror.DefaultReplicationPolicy
# 自定义示例:
# replication.policy.class=org.apache.kafka.connect.mirror.IdentityReplicationPolicy
# 启用复制方向
dc1->dc2.enabled=true
dc2->dc1.enabled=true
dc1->agg.enabled=true
dc2->agg.enabled=true
# 复制范围(正则)
dc1->dc2.topics=.*
dc2->dc1.topics=.*
dc1->agg.topics=.*
dc2->agg.topics=.*
# 元数据与权限同步
dc1->dc2.sync.topic.acls.enabled=true
dc1->dc2.sync.topic.configs.enabled=true
dc1->dc2.refresh.topics.enabled=true
dc1->dc2.emit.checkpoints.enabled=true
dc1->dc2.emit.heartbeats.enabled=true
# 限速与并发(酌情调优)
replication.factor=3
tasks.max=8
启动:
bin/connect-distributed.sh config/mm2.properties
生产务必:
1)明确复制话题白/黑名单;2)开启心跳/检查点;3)配合ACL 同步或在目标侧预置 ACL;4)规划任务并发与限速。
5.2 主题与消费组复制要点
- 主题:保留分区数/保留策略一致性(必要时在目标集群预创建对齐配置)。
- 消费组位点:通常不跨 DC 写回生产消费位点;跨 DC 消费建议独立组,避免位点相互影响。
- 有序性:镜像是最终一致、按分区顺序复制;跨分区全序无法保证。
6. 高延迟链路下的吞吐调优
Kafka 的生产者/消费者天然批处理,配合更大的缓冲与批量参数,可在高 RTT 下获得较高吞吐。
6.1 生产者关键参数(示例)
# TCP 缓冲(系统内核与 JVM 同步调大)
socket.send.buffer.bytes=1048576 # 1MB 起步,按带宽×RTT 推算
# 批处理
linger.ms=20 # 等待更多消息进同一批
batch.size=131072 # 128KB 起步
compression.type=lz4 # 或 zstd(看 CPU/延迟预算)
acks=all # 与可靠性策略匹配
retries=2147483647
max.in.flight.requests.per.connection=1 # 需要严格有序时
6.2 消费者关键参数(示例)
socket.receive.buffer.bytes=1048576
fetch.min.bytes=131072
fetch.max.wait.ms=50
max.partition.fetch.bytes=1048576
6.3 Broker 侧(示例)
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
replica.fetch.max.bytes=10485760
replica.fetch.wait.max.ms=50
经验法则:缓冲大小 ≈ 带宽(Bytes/s)× RTT(s)× 安全系数。
例:专线 200 Mb/s、RTT 50 ms,单向飞行中的数据量 ≈ 25 MB/s × 0.05 ≈ 1.25 MB,缓冲取 2–4×。
7. 容量与 SLO 估算(停链可追赶)
背压/积压估算:
- 积压字节
B = 写入速率(Bytes/s) × 中断时长(s) - 追赶时间
T = B / 复制吞吐(Bytes/s)(若复制吞吐 > 正常入流量,可边追边清)
示例:入流 80 MB/s,链路中断 30 min → 积压 ≈ 144 GB。镜像链路稳态 200 MB/s → T ≈ 12 min。
SLO 建议:为关键话题设置 RPO/RTO 目标(如 RPO≤15 min,RTO≤30 min),反推链路带宽与镜像并发。
8. 不要跨 DC 拉一套“单集群”的技术原因
- 复制路径跨高 RTT → ISR 同步成本高,写入延迟抖动显著。
- 可用性外部化 → 任一 DC 故障/链路抖动都会波及全集群领导者选举与复制。
- 故障域过大 → 维护/变更窗口影响全域。
极少数专线超低 RTT、强一致强需求场景除外,总体不建议。
9. 监控与告警(运维最小集)
- 镜像健康:
MirrorSourceConnector/MirrorCheckpointConnector/MirrorHeartbeatConnector任务状态 - 复制滞后:目标侧每话题/分区的最新 offset 与镜像 offset 差
- 链路与带宽:吞吐、重传、TCP 队列、丢包
- 端到端时延:生产→目标消费的延迟分位(P50/P95)
- 容量:主题磁盘占用、保留策略、清理速率
- 安全:跨 DC ACL 同步异常、证书/密钥过期
10. 变更与演练 Runbook(最短路径)
变更前:
- 评审话题白/黑名单、ACL、限速策略;
- 压测镜像吞吐(限速开/关两档);
- 记录当前分配与配置用于回滚。
灰度:
- 先同步低风险话题,观察滞后曲线与端到端时延。
放量:
- 分批放开关键话题复制,并设置Lag 告警门限。
故障演练:
- 主动断链 5–10 min,验证积压与追赶 SLO;
- 模拟单 DC 故障,验证本地自治。
日常巡检:
- 任务状态、滞后告警、带宽利用、磁盘与保留策略漂移。
11. 安全与合规
- 传输加密:SASL/SCRAM + TLS(双向)
- 最小权限:源/目标两端独立 ACL,必要时同步 Topic ACL
- 数据主权:按地域合规选择哪些话题可以跨境/跨区复制
- 密钥轮换:Connect/MM2 与 Broker 证书到期前告警与演练
12. 常见问题(FAQ)
Q1:镜像能保证强一致吗?
A:跨 DC 镜像是异步、最终一致,同分区内顺序保持;跨分区全序不保证。
Q2:消费组位点要一起镜像吗?
A:通常不建议。跨 DC 消费建议独立组,避免位点/重平衡相互影响。
Q3:链路波动导致滞后大,怎么办?
A:适当调大缓冲/批量/并发,必要时提速或扩并发;对关键话题设置独立限速与优先级。
Q4:如何防止镜像把“脏配置”带过去?
A:目标侧预创建受控 Topic 模板(分区、保留、压缩),并限制可同步的配置项。
13. 上线检查清单(Checklist)
- 每 DC 本地 Kafka 集群与应用连通性
- MM2/Connect 高可用部署(多 Worker,存储偏移在 Kafka)
- 复制话题清单(白/黑名单)与 ACL 策略
- 限速策略(按业务峰值与小流量拉齐)
- 监控仪表与告警(滞后、吞吐、任务状态、容量、证书)
- 故障演练记录(断链/拥塞/单 DC 故障)
- SLO 文档:RPO/RTO 与回退方案
14. 总结
正确的跨 DC 姿势是:本地集群承载本地业务,跨 DC 用镜像做最终一致复制;需要全局视图时,建立聚合只读集群。用带宽×RTT反推缓冲与批量,用滞后与追赶时间约束 SLO;把镜像治理(限速、过滤、权限、监控)当成平台能力建设的第一公民。这样既能稳住实时链路,又能在断链后快速追平,实现“可用、可观测、可演练”的多机房数据管道。