目录
U-Net: Convolutional Networks for Biomedical Image Segmentation
论文链接:U-Net: Convolutional Networks for Biomedical Image Segmentation(MICCAI 2015)
摘要
(1)本文提出了一种网络和训练策略,它依赖于大量使用数据增强来更有效地使用可用的带注释样本。
(2)网络架构由一条用于捕获上下文信息的路径(contracting path)和一条用于实现精确定位的路径(expanding path)组成。
(3)这种网络可以从很少的图像中进行端到端训练,并且在当时达到很好的效果。此外,该网络速度在当时分割 512x512 图像只需不到一秒钟。
U-net网络结构
U-net网络结构图如下
左侧为contracting path,主要作用是进行特征提取以及下采样,通常被视为encoder。
右侧则为expansive path,通常被视为decoder。
图中的条形矩阵代表特征层,箭头代表操作(如图中右下红框所示)。
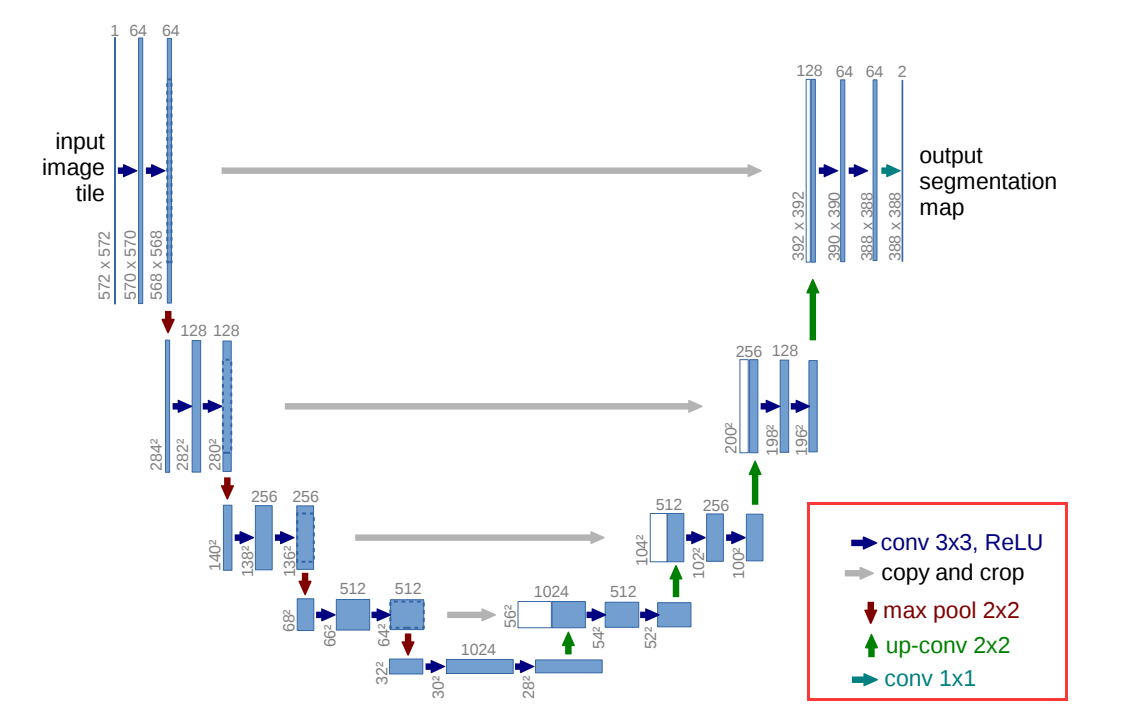
在U-net的卷积操作中stride = 1,padding = 0,因此卷积后图像宽和高都会变小。
当时BN层还没发展起来,所以还没使用BN模块。
执行流程:
contracting path:
首先,输入的是单通道的572 × 572图像。
下采样不改变通道数,但是每次下采样之后经过的第一个卷积层都会使通道数翻倍。
expansive path:
上采样使用的是转置卷积,宽和高都放大两倍,同时通道数减半。
灰色箭头(copy and crop)主要执行的是concat操作,但是由于宽高不同,因此会对左侧的特征图进行中心裁剪再执行concat操作。
右侧通道数减半的操作在上采样和上采样后的第一个卷积层中都会执行,因为在上采样减半后concat会恢复原来的维度,然后再通过卷积层降维。
最后输出部分,墨绿色的1 × 1卷积层的卷积核个数和分类的类别个数一样,并且没有经过relu层。因为论文中只有前景和背景两个类别,因此最后的特征图是388 × 388 × 2。
注意:
论文中输入为572 × 572,但是输出为388 × 388,因此只是得到原图中间部分的分割结果。
实际实现通常在左侧的卷积层中加入padding,不会改变宽和高,这样在concat的时候就不用使用中心裁剪,并且最终结果特征图宽高和输入是一致的。同时,现在实现还会在conv 3 × 3 和Relu中间加入 BN层。
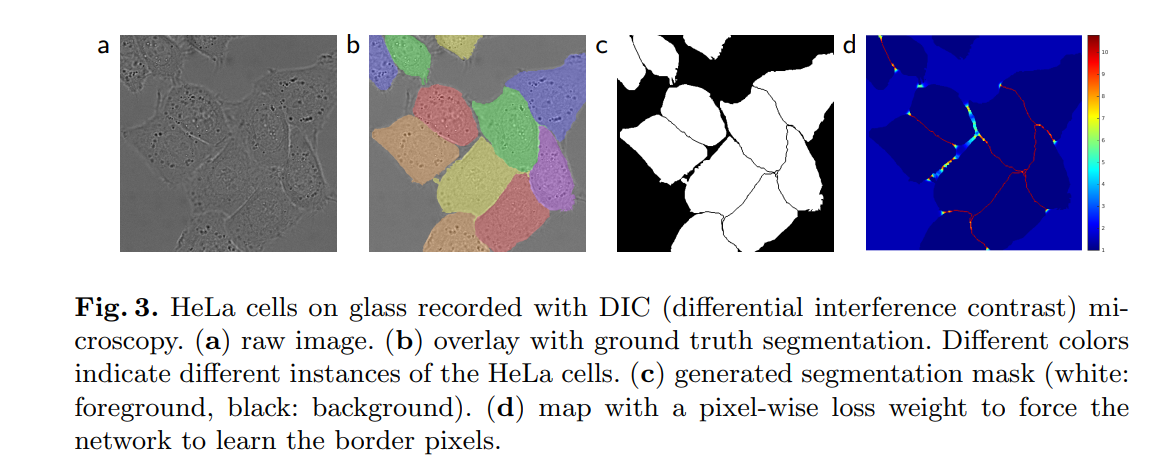
pixel-wise loss weight
图中c是当作ground truth用来计算损失,而实际做细胞分割的过程,对于细胞和细胞间的间隙(图中相邻白色区域的黑色间隙)进行分割是很困难的,而图c中大面积黑色区域则是很容易区分的,因此提出了pixel-wise loss weight方案。
对于细胞的间隙在计算损失的时候给予更大的权重,而大片的背景区域施加比较小的权重,图中d热力图所示就是权重分布,蓝色(0)到红色(10)权重逐渐增大,但是该方法在论文中并没有进行消融实验,而只是提到了对模型训练会有帮助。
U²-Net: Going Deeper with Nested U-Structure for Salient Object Detection
论文链接:U²-Net: Going Deeper with Nested U-Structure for Salient Object Detection(CVPR 2020)
U²-Net是针对Salient Object Detetion(SOD)即显著性目标检测任务提出的。该任务虽然是检测任务,但是和语义分割十分类似,它的任务是将图片中最吸引人的目标或区域分割出来,故只有前景和背景两个类别。
摘要
(1)本文设计了一个简单但功能强大的深度网络架构U²-Net,用于显著物体检测(SOD)。
(2)网络架构由两级嵌套的U型结构组成,其设计具有以下优点:
- ReSidual Block(RSU)中具有不同大小的感受野,它能够从不同尺度捕获更多上下文信息;
- RSU块中使用了池化操作,增加了整个架构的深度,但却不会显著增加计算成本;
- 这种架构能够从头开始训练深度网络,而无需使用来自图像分类任务的主干。
网络结构详解
整体结构
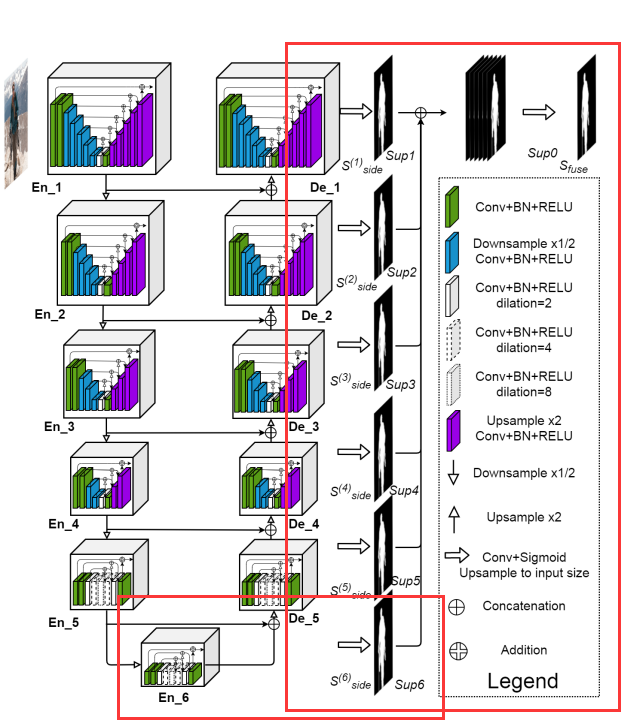
下图展示U²-Net的整体结构。主体是一个类似U-Net的结构,而网络中的每个block(无论是Encoder还是Decoder模块)内部也是类似U-Net结构,因此该网络也取名为U²-Net。
总体介绍:
在encoder中每经过一个block后都要进行下采样,下采样2×通过maxpool实现。
在decoder中每经过一个block前都要进行上采样,通过双线性插值(bilinear)实现。
每个阶段的预测输出进行融合,得到融合之后的预测概率图。
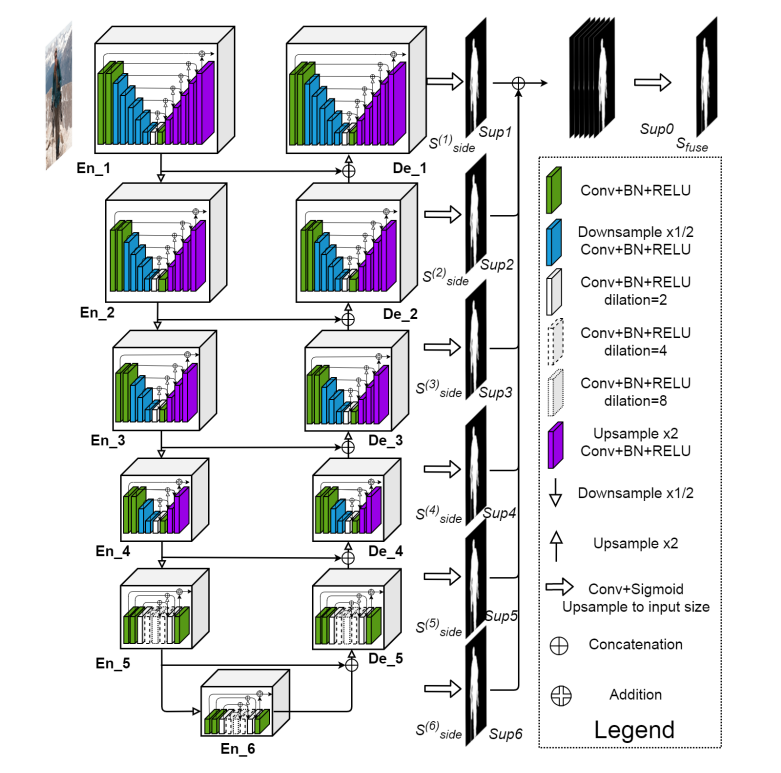
通过上图可以看出,En_1、En_2、En_3、En_4、De_1、De_2、De_3、De_4采用的是同一种Block,只不过深度不同。该Block就是论文中提出的ReSidual U-block简称RSU。
RSU-n结构
下图是RSU-7结构,其中7代表深度,注意最下面的3 x 3卷积采用的是膨胀卷积,膨胀因子为2。
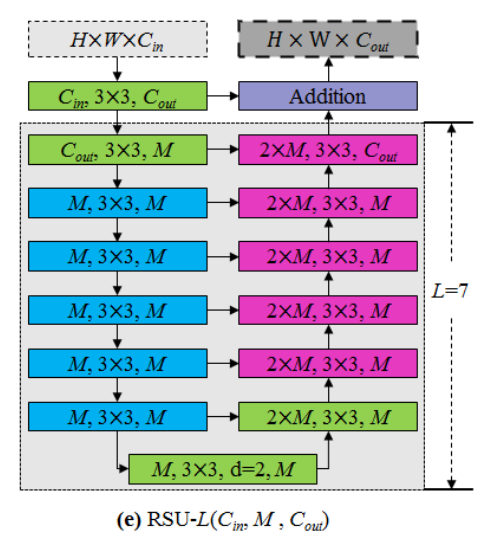

其中En_1和De_1采用的是RSU-7,En_2和De_2采用的是RSU-6,En_3和De_3采用的是RSU-5,En_4和De_4采用的是RSU-4,区别就是下采样的倍率不同,RSU-7最多下采样32×,RSU-6最多下采样16×,以此类推。
而En_5、En_6和De_5三个模块采用的是RSU-4F,RSU-4F和RSU-4两者结构并不相同。
RSU-4F结构
下图是RSU-4F的结构图,在RSU-4F中并没有进行下采样或上采样,而是将采样层全部替换成了膨胀卷积,下图中带参数d的卷积层全部是膨胀卷积,d为膨胀系数。
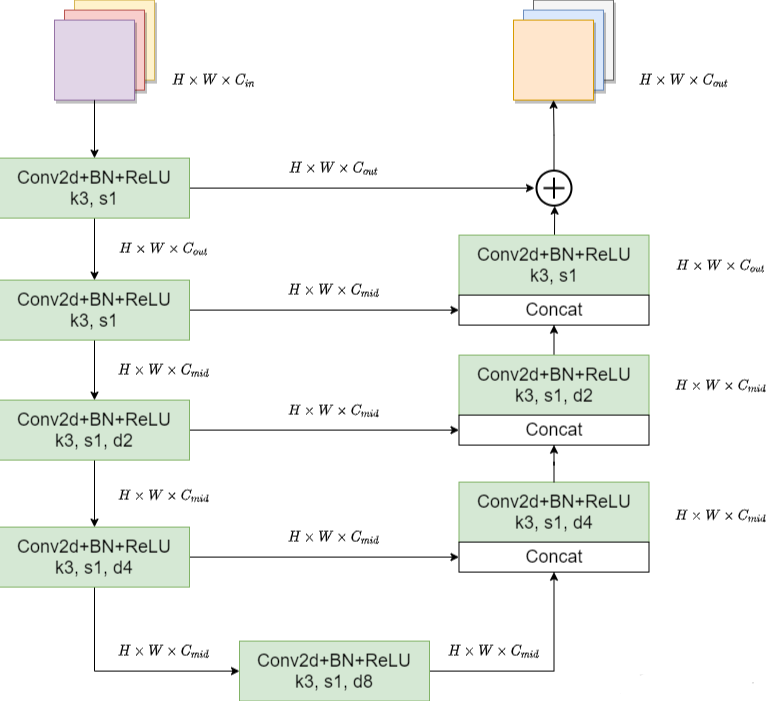
注意:在En_5、En_6和De_5三个block内部的操作中,通过控制膨胀系数d,特征图的宽和高是没有发生变化的。
为什么在在En_5、En_6和De_5中不进行采样?
通过Encoder_4这个block之后特征图的尺寸就已经比较小了,如果再进行下采样会丢失很多上下文信息,所以在En_5、En_6和De_5这三个block中就不再进行下采样了,而是将采样层(上采样和下采样)全部替换成了膨胀卷积。
saliency map fusion module – 显著特征融合模块
通过该模块将不同阶段得到的不同尺度的saliency map进行融合并得到最终预测概率图。
执行流程:
- 首先收集De_1、De_2、De_3、De_4、De_5以及En_6的输出,然后分别通过一个3 x 3的卷积层(图中白色箭头),这些卷积层的卷积核个数都为1,因此得到的特征图channel都为1;
- 然后通过双线性插值进行缩放,把feature map的大小还原成输入图片大小,得到Sup1、Sup2、Sup3、Sup4、Sup5和Sup6;
- 接着将这6个特征图进行Concat拼接,得到channel = 6的特征图;
- 最后经过一个1 x 1的卷积层以及Sigmiod激活函数得到最终的预测概率图。
损失计算
下面是原论文中给出的损失函数,l代表二值交叉熵损失,w代表每个损失的权重。
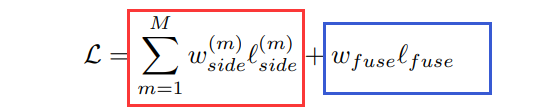
该损失函数可以看成两部分,红色框中通过上面提到的Sup1、Sup2、Sup3、Sup4、Sup5和Sup6计算。首先要将Sup1、Sup2、Sup3、Sup4、Sup5和Sup6通过Sigmoid激活函数得到对应的预测概率图,然后与手工标注的ground truth计算l,M=6即Sup1至Sup6。。
蓝色框表示最终融合得到的预测概率图S_fuse与ground truth之间的损失,在源码中红色框中的六个w以及蓝色框中的w全部都等于1。
评价准则
F-measure
F-measure是结合了Precision和Recall的综合指标,计算公式如下

最终结果在0-1之间,其中F_β越大,表示网络的分割效果越好。
注意:对于不同的阈值,会得到不同的precision和recall,因此实际得到的F_β是一个数组,而最终报告的指标就是max(F_β),即取数组中的最大值作为评价指标,在源码中β² = 0.3。
MAE(mean absolute error)-- 平均绝对误差
MAE计算公式如下:

最终结果在0-1之间,MAE越接近0表示网络性能越好。
其中P(r,c)代表网络预测的概率图,G(r,c)代表真实的GT,H和W分别代表图片的高和宽。对于输入图中的每个像素点,用网络预测的概率图和ground truth进行相减得到绝对值,然后求得全图像素的平均损失。
实验结果
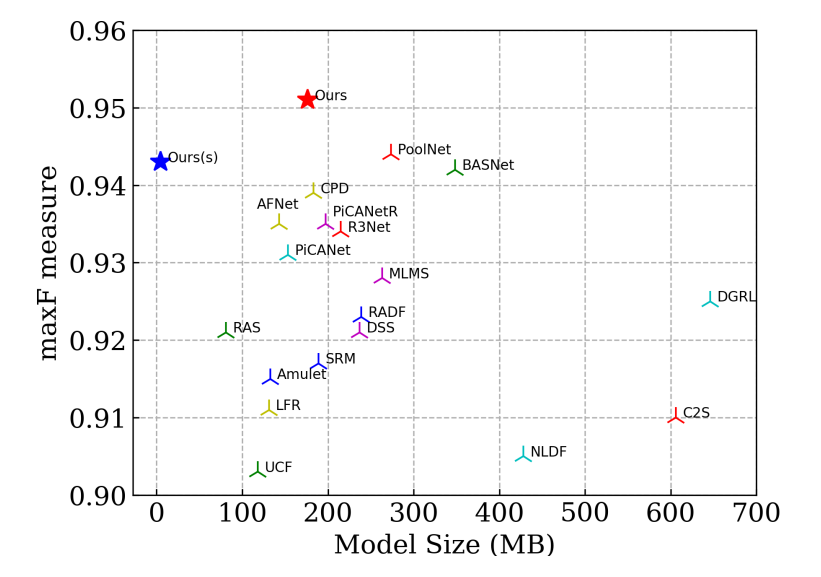
下图展示了当年SOD任务中最先进的一些公开网络在ECSSD数据集上的max{F_β}性能指标。通过对比,U²-Net无论是在模型size上还是max{F_β}指标上都优于其他网络。
图中红色的五角星代表的是标准的U²-Net(176.3 MB),蓝色的五角星代表轻量级的U²-Net(4.7 MB),效果都十分显著。
下图是具体结果对比。
- 第一列为原图;
- 第二列为人工标注的ground truth;
- 第三列为U²-net标准版的预测结果;
- 第四列为轻量级U²-net的预测结果;
- 第五列及其之后的就是当年其他显著性目标检测网络的预测结果。
从图中可以明显看出U²-net的分割精细程度更高,效果很好。
